Timeline at Scale in Twitter
https://www.infoq.com/presentations/Real-Time-Delivery-Twitter @ 2013
twitter timeline 整体架构如下图:
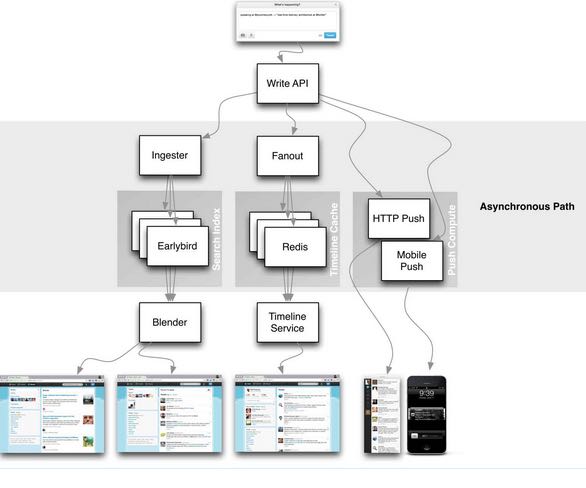
按照功能分成了很多services, 每个service由不同的service group来管理:Timeline Service, Tweet Service, User Service, Social Graph Service, 这些service可以说是见名知意。
这些服务基本和对外提供的没有太大差别,每个service之间会相互调用,之间不需要考虑扩展性问题,但是需要做好容量规划。
这篇文章是在2013年写的,但是我觉得基本架构上没有太多变化,可能的变化最多是集中在social graph管理上,使用机器学习来更加精准地为用户提供信息。
twitter已经远不是将自己定位成为一个web app, 而是想通过一些系列的API集合,可以服务于全球移动客户端,将自己打造成为最大的实时消息平台。当时twitter timeline 指标如下:
- 150M DAU
- 300K QPS. 主要集中在read上,只有6k QPS是write
- 400M 每天需要处理的tweets数量
- 22MB/sec 经过firehose的推送流量
- 800 entries per user. 只能看到最近800个tweets(trade off on memory)
在实时性上,tweet从发出到所有followers收到,整个过程大部分在5s以内。这个时间和followers的数量相关,对Lady Gaga这种东西31M粉丝来说,延迟会到5m.
我理解对于twitter当前系统最大的挑战性,一方面在于是否可以更加地快速信息流动,另外一方面是否可以更好地观测和监控每个services以及整个系统。我记得Raffi在talk里面讲到了,他们会做一个bot不断地发送信息以及接受消息,一旦出现问题就会报警。
Push Me Pull Me
我记得在talk的slide里面将timeline分为4个维度
| pull | push | |
|---|---|---|
| targeted | timeline/twiter.com | user/site streams, mobile push |
| queried | search api | track/follow streams |
主要有两个类型的timeline, 一个是用户自己发的,一个是自己关注的。
- A user timeline is all the tweets a particular user has sent.
- A home timeline is a temporal merge of all the user timelines of the people are you are following.
- Business rules are applied. @replies of people that you don’t follow are stripped out. Retweets from a user can be filtered out.
- Doing this at the scale of Twitter is challenging.
push是通过http长连接来实现的,延迟大约在150ms, 1m个socket connections.
- user/site streams. 比如tweetdeck, twitter for mac这类应用会自动收到更新,不是靠pull来更新
- mobile push.
- track/follow stream. 通过query来定义connection.
High Level For Pull Based Timelines
tweet一旦写入queue之后就ack, 这个过程是同步行为。从queue到剩余的系统就是异步行为包括:创建索引用于检索,放入redis用于user timeline, 写入firehose用于推送
- user timeline
- Immediately the fanout process occurs. Tweets that come in are placed into a massive Redis cluster. Each tweet is replicated 3 times on 3 different machines. At Twitter scale many machines fail a day. By replicating 3 times if a machine has a problem then they won’t have to recreate the timelines for all the timelines on that machine per datacenter.(Redis集群是3备份的,这样如果user timeline挂掉的话不用去重建)
- Fanout queries the social graph service that is based on Flock. Flock maintains the follower and followings lists.(查询flock来了解social graph)
- The Redis cluster has a couple of terabytes of RAM.(Redis集群内存整体大小在TB级别)
- Pipelined 4k destinations at a time(每次写入4K个tweets,包括fanout)
- Native list structure are used inside Redis.(Redis就是使用列表结构)
- Your home timeline sits in a Redis cluster and is 800 entries long. If you page back long enough you’ll hit the limit. RAM is the limiting resource determining how long your current tweet set can be.(每个用户最多保持800 entries)
- What is being stored is the tweet ID of the generated tweet, the user ID of the originator of the tweet, and 4 bytes of bits used to mark if it’s a retweet or a reply or something else.(Redis存储结构上非常精简,user id + tweet id + 4bytes)
- Every active user is stored in RAM to keep latencies down. Active user is someone who has logged into Twitter within 30 days, which can change depending on cache capacity or Twitter’s usage. If you fall out of the Redis cluster then you go through a process called reconstruction. (只是为acitve user缓存timeline,如果没有在cache里面的话,那么就需要使用计算资源来重建这个user timeline)
- home timeline
- Only your home timelines hit disk.(对于home timeline会动用缓存而是直接访问数据库,这个上面应该也有一定的缓存。home timeline会存储3份,哪份响应快就使用哪份)
- Effectively running 3 different hash rings because your timeline is in 3 different places.
- They find the first one they can get to fastest and return it as fast as they can.
- The tradeoff is fanout takes a little longer, but the read process is fast. About 2 seconds from a cold cache to the browser. For an API call it’s about 400 msec.
- id to tweet
- Since the timeline only contains tweet IDs they must “hydrate” those tweets, that is find the text of the tweets. Given an array of IDs they can do a multiget and get the tweets in parallel from T-bird.(T-bird是id到tweet的数据库)
- Gizmoduck is the user service and Tweetypie is the tweet object service. Each service has their own caches. The user cache is a memcache cluster that has the entire user base in cache. Tweetypie has about the last month and half of tweets stored in its memcache cluster. These are exposed to internal customers.(Gizmoduck是上层服务,Tweetypie则是映射服务,之间有memcache做的缓存集群,差不多有最近1个半月的tweets放在了memcache集群里面)
- Some read time filtering happens at the edge. For example, filtering out Nazi content in France, so there’s read time stripping of the content before it is sent out.(实时关键词过滤系统)
High Level For Search
另外一篇 文章(earlybird) 里面谈到了twitter search system. 这里再补充一些细节:
- Opposite of pull. All computed on the read path which makes the write path simple. (Search和Pull完全相反,写入很简单但是读取很复杂)
- As a tweet comes in, the Ingester tokenizes and figures out everything they want to index against and stuffs it into a single Early Bird machine. Early Bird is a modified version of Lucene. The index is stored in RAM.(EarlyBird基于Lucence修改的,索引全部存放在内存里面)
- Blender creates the search timeline. It has to scatter-gather across the datacenter. It queries every Early Bird shard and asks do you have content that matches this query? If you ask for “New York Times” all shards are queried, the results are returned, sorted, merged, and reranked. Rerank is by social proof, which means looking at the number of retweets, favorites, and replies.(Blender会去所有的EarlyBird分分片上检索某个query,然后在上层排序合并重新rank)
- Discovery is a customized search based on what they know about you. And they know a lot because you follow a lot of people, click on links, that information is used in the discovery search. It reranks based on the information it has gleaned about you.(发现服务本质上还是一个搜索服务,可能根据你的行为来总结某些关键词)
Search And Pull Are Inverses
Raffi在talk里面花了一点时间来讨论两者的差异性和相似性,算是架构上的总结吧。这个总结可以用来解决high fanout的问题。
high fanout是因为名人产生的,他们有很多的粉丝。这个问题的后果有两个:1. 延迟 2. 乱序。可以看看当时fanout有多大量,当然这些名人已经不止这个量级了。
Problem is for large cardinality graphs. @ladygaga has 31 million followers. @katyperry has 28 million followers. @justinbieber has 28 million followers. @barackobama has 23 million followers.
根据上面一节的分析,Search/Pull可以认为是逆操作,所以对于high fanout tweet, 可以使用search不是pull模型。这样taylor swift发推就不是问题了。
Trying to figure out how to merge the read and write paths. Not fanning out the high value users anymore. For people like Taylor Swift don’t bother with fanout anymore, instead merge in her timeline at read time. Balances read and write paths. Saves 10s of percents of computational resources.
Monitoring
- If you have 1 million followers it takes a couple of seconds to fanout all the tweets. (1M粉丝需要几秒钟fanout tweet)
- Tweet input statistics: 400m tweets per day; 5K/sec daily average; 7K/sec daily peak; >12K/sec during large events.
- Timeline delivery statistics: 30b deliveries / day (~21m / min); 3.5 seconds @ p50 (50th percentile) to deliver to 1m; 300k deliveries /sec; @ p99 it could take up to 5 minutes
- A system called VIZ monitors every cluster. Median request time to the Timeline Service to get data out of Scala cluster is 5msec. @ p99 it’s 100msec. And @ p99.9 is where they hit disk, so it takes a couple hundred of milliseconds.