Earlybird: Real-Time Search at Twitter
twitter检索系统:
- 准实时. 现有系统可以做到10s延迟, 查询时间控制在~50ms
- 支持concurrent reads & writes.
- 在相关性上没有太多复杂算法, 主要是按照时间排序. 复杂的相关性和个性化紧密相关.
整个系统架构如下, 使用sharding方法来提高负载, 最后具体检索落到每个单机earlybird上面.
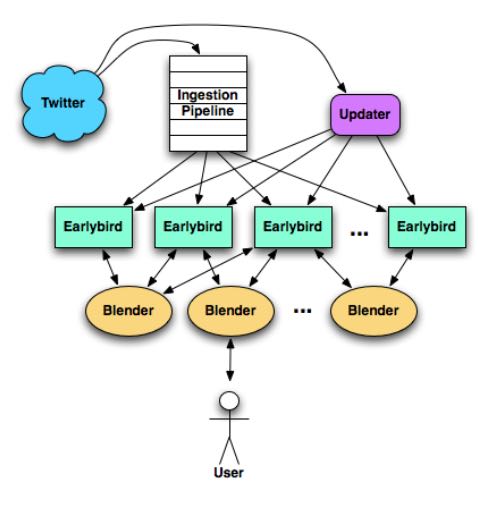
文章主要介绍单机earlybird实现上两个问题: 1. indexes 2. concurrent reads & writes.
index是由多个segments组成的, 任何时候只有一个segment是可写的. 单个segment有tweets数量上限(2^23 ∼ 8.4 million tweets), 当超过这个数量之后会flush到磁盘上形成read-friendly格式文件. 因为按照时间倒序作为相关性, 所以segment上面的inverted index是按照时间逆序的tweets的链表. 通常一个instance上面有~12 segments. 为了提高内存分配效率, 使用slab分配slice, slice可以链表方式串联起来. slab的大小有2^1, 2^4, 2^7和2^11. slices链表方式只用于内存表示, 没有进行压缩. 但是当flush到磁盘时候会使用连续内存块存储并且压缩, 可以省去大约55%的内存.
concurrent reads & writes里面最重要的问题是, reader希望以一致方式读取索引. 实现机制类似snapshot version: 引入maxDoc变量, 表示当前index中最大docId是多少. 当reader读取索引时候, 首先读取maxDoc, 之后只访问那些docid < maxDoc的文档. maxDoc没有使用atomic类型, 而是使用volatile然后通过java memory model来保证原子性. (what a trick!) 正好这里顺便了解释一下java memory model.
- Program order rule. Each action in a thread happens-before every action in that thread that comes later in the program order.
- Volatile variable rule. A write to a volatile field happens-before every subsequent read of that same field.
- Transitivity. If A happens-before B, and B happens-before C, then A happens-before C.
也就是说如果一个变量是volatile的话, 那么写入这个变量之后是有一个隐含的write memory barrier (以及读取这个变量之后有一个隐含的read memory barrier ? 不太确定)

wmb只能保证reader能够读取到tweet{i}, 但是不能保证不会读取到tweet{i+1}. 这个问题是write "leak through". 但是这个问题很容易解决, 只要在reader里面只读取那些tweet id <= maxDoc的tweet即可.
比较有意思的是, 在earlybird使用(2011年)之前, twitter的检索系统使用的是Summize公司的, 这个公司在2008年被twitter收购. 原先的检索系统架构是ROR做front-end, MySQL做backend, 效果也还不错. 在2010年被替换到earlybird之前, 处理性能是1000TPS+12000QPS.