F1: The Fault-Tolerant Distributed RDBMS Supporting Google's Ad Business
Table of Contents
http://research.google.com/pubs/pub38125.html @ 2012
1. Today's Talk
- F1 - A Hybrid Database combining the
- Scalability of Bigtable
- Usability and functionality of SQL databases
- Key Ideas
- Scalability: Auto-sharded storage
- Availability & Consistency: Synchronous
- High commit latency: Can be hidden
- Hierarchical schema (spanner提供层级schema)
- Protocol buffer column types
- Efficient client code
- Can you have a scalable database without going NoSQL? Yes.
- High commit latency: Can be hidden
2. Our Legacy DB: Sharded MySQL
- Sharding Strategy
- Sharded by customer
- Apps optimized using shard awareness
- Limitations
- Availability
- Master / slave replication -> downtime during failover
- Schema changes -> downtime for table locking
- Scaling
- Grow by adding shards
- Rebalancing shards is extremely difficult and risky
- Therefore, limit size and growth of data stored in database
- Functionality
- Can't do cross-shard transactions or joins
- Availability
3. Our Solution: F1
- A new database
- built from scratch,
- designed to operate at Google scale,
- without compromising on RDBMS features.
- Co-developed with new lower-level storage system, Spanner
- Underlying Storage - Spanner
- Descendant of Bigtable, Successor to Megastore
- Properties
- Globally distributed
- Synchronous cross-datacenter replication (with Paxos)
- Transparent sharding, data movement
- General transactions
- Multiple reads followed by a single atomic write
- Local or cross-machine (using 2PC)
- Snapshot reads
- Hierarchical Schema
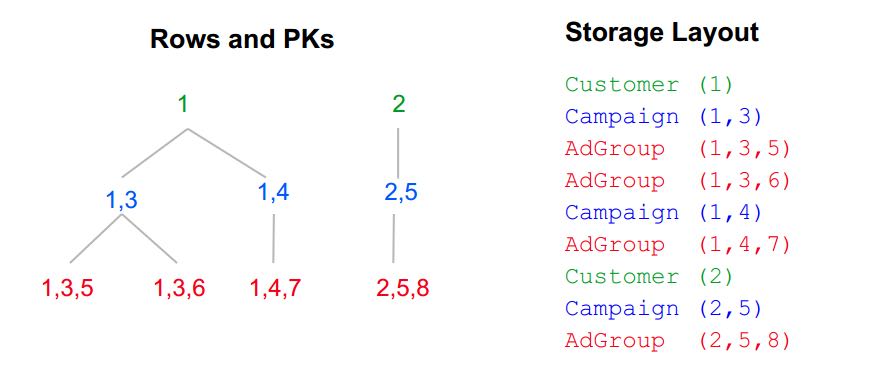
- Explicit table hierarchies. Example:
- Customer (root table): PK (CustomerId)
- Campaign (child): PK (CustomerId, CampaignId)
- AdGroup (child): PK (CustomerId, CampaignId, AdGroupId)
- Clustered Storage
- Child rows under one root row form a cluster (属于同一个root的数据形成一个cluster)
- Cluster stored on one machine (unless huge) (然后这个cluster通常会存放在一个机器上面)
- Transactions within one cluster are most efficient
- Very efficient joins inside clusters (can merge with no sorting)
- Protocol Buffer Column Types (这个应该有很多好处,能够在很大程度上减少表的数量以及减少阻抗)

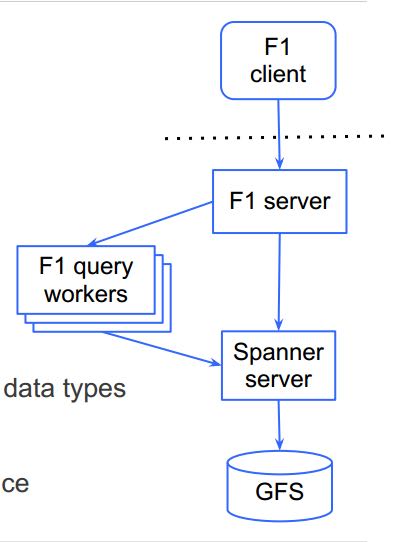
- Architecture
- Sharded Spanner servers
- data on GFS and in memory
- Stateless F1 server
- Pool of workers for query execution
- Sharded Spanner servers
- Features
- Relational schema
- Extensions for hierarchy and rich data types
- Non-blocking schema changes
- Consistent indexes
- Parallel reads with SQL or Map-Reduce
- Relational schema
4. How We Deploy
- Five replicas needed for high availability
- Why not three?
- Assume one datacenter down
- Then one more machine crash => partial outage
- Replicas spread across the country to survive regional disasters
- Up to 100ms apart(传输距离达到了100ms以上?)
- Why not three?
- Performance
- Very high commit latency - 50-100ms(因为写需要跨越几个机房)
- Reads take 5-10ms - much slower than MySQL(如果单次读取在5-10ms算是比较快的了)
- High throughput
- Coping with High Latency
- Preferred transaction structure
- One read phase: No serial reads
- Read in batches
- Read asynchronously in parallel
- Buffer writes in client, send as one RPC
- Use coarse schema and hierarchy(通过提供protobuf column type来提供粗粒度的schema)
- Fewer tables and columns
- Fewer joins
- For bulk operations
- Use small transactions in parallel - high throughput
- Preferred transaction structure