Spanner: Google's Globally-Distributed Database
Table of Contents
- http://research.google.com/archive/spanner.html @ 2012
- Spanner笔记 http://www.cnblogs.com/sunyongyue/archive/2012/09/20/spanner_note.html
- Google Spanner原理 http://qing.weibo.com/2294942122/88ca09aa3300221n.html
- Google Spanner (中文版) http://dblab.xmu.edu.cn/node/230
1. Abstract
- Spanner is Google’s scalable, multi-version, globally-distributed, and synchronously-replicated database. It is the first system to distribute data at global scale and sup-port externally-consistent distributed transactions. (可扩展,多版本,全局分布式,同步复制的数据库系统,扩展性到全球级别,并且支持外部一致性的分布式事务)
- This paper describes how Spanner is structured, its feature set, the rationale underlying various design decisions, and a novel time API that exposes clock uncertainty. (主要分为两个方面,一个方面是组织结构以及关键特性还有各种设计上的权衡,另外一个就是支持时钟不确定性的时间API)
- This API and its implementation are critical to supporting exter-nal consistency and a variety of powerful features: non-blocking reads in the past, lock-free read-only transac-tions, and atomic schema changes, across all of Spanner.(主要是使用这个API才能够保证外部一致性以及一些非常强大的功能,non-blocking read历史数据,lock-free read-only事务,以及原子schema变化)
2. Introduction
- At the high-est level of abstraction, it is a database that shards data across many sets of Paxos state machines in data- centers spread all over the world. Replication is used for global availability and geographic locality; clients auto-matically failover between replicas. (数据是进行shard的,每个shard实例之间的同步都是通过paxos状态机来完成的,实例可能散步于世界的各个地方。replication主要是为了提供全球可用性以及地理位置上的局部性,client能够自动地在replicas之间做failover切换)
- Spanner automati-cally reshards data across machines as the amount of data or the number of servers changes, and it automatically migrates data across machines (even across datacenters) to balance load and in response to failures. (spanner对于data shard是自动完成的,当server数量变化的时候会reshard然后重新做balance)
- Spanner is designed to scale up to millions of machines across hun-dreds of datacenters and trillions of database rows.(扩展到百万机器,上百个数据中心,10^12 rows)
- Spanner’s main focus is managing cross-datacenter replicated data, but we have also spent a great deal of time in designing and implementing important database features on top of our distributed-systems infrastructure(虽然spanner主要focus是在跨机房的数据replication上,但是也花了相当多的时间来在分布式结构上设计和实现很多database特性,
- Bigtable不能够支持复杂并且变化的schema,并且对于wide-area下面不能够很好地实现强一致性
- Megastore可以解决Bigtable这个问题但是write throughput太差(使用MVCC方式造成的冲突)
- Spanner has evolved from a Bigtable-like versioned key-value store into a temporal multi-version database.
- Data is stored in schematized semi-relational tables; 数据存放在schema化的半关系表里面
- data is versioned, and each version is automati-cally timestamped with its commit time; old versions of data are subject to configurable garbage-collection poli-cies; and applications can read data at old timestamps. (data都通过timestamp进行version,这样允许application读取历史数据,而old version数据能够被GC清除)
- Spanner supports general-purpose transactions, and pro-vides a SQL-based query language.(支持ACID事务,上层提供查询语言)
- As a globally-distributed database, Spanner provides several interesting features.(在扩展性和并发方面还提供了下面几个特性)
- First, the replication con-figurations for data can be dynamically controlled at a fine grain by applications. (application能够精确控制data方式位置以及replication方式)
- which datacenters contain which data
- how far data is from its users (to control read latency)
- how far replicas are from each other (to control write la-tency)
- how many replicas are maintained (to con-trol durability, availability, and read performance).
- Second, Spanner has two features that are difficult to implement in a distributed database:
- provides externally consistent reads and writes, (读写外部一致性)
- and globally-consistent reads across the database at a time-stamp.(全局一致性地读取历史数据)
- First, the replication con-figurations for data can be dynamically controlled at a fine grain by applications. (application能够精确控制data方式位置以及replication方式)
- These features are enabled by the fact that Spanner as-signs globally-meaningful commit timestamps to trans-actions, even though transactions may be distributed. The timestamps reflect serialization order.(上面这些特性主要是因为spanner为事务提供了全局的提交时间戳,时间戳的顺序决定了串行顺序)
- The key enabler of these properties is a new TrueTime API and its implementation. The API directly exposes clock uncertainty, and the guarantees on Spanner’s times-tamps depend on the bounds that the implementation pro- vides. (提供全局时间戳关键就是TrueTime API,API实现上暴露了时钟的不确定性,提供当前时钟的范围)
- If the uncertainty is large, Spanner slows down to wait out that uncertainty. Google’s cluster-management software provides an implementation of the TrueTime API. 如果这个不确定性太大的话,那么spanner就需要slowdown等待这个uncertainty降下来
- This implementation keeps uncertainty small (gen-erally less than 10ms) by using multiple modern clock references (GPS and atomic clocks). 通过GPS和原子钟来keep uncertainty small
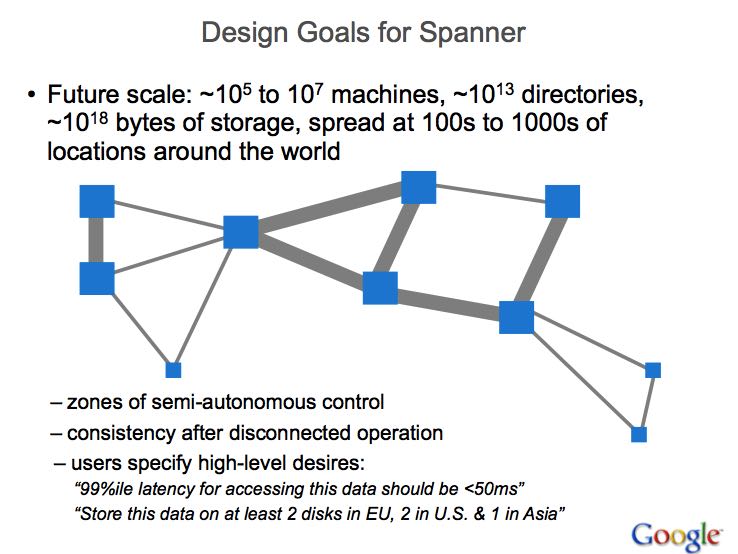
3. Implementation
- A Spanner deployment is called a universe. Given that Spanner manages data globally, there will be only a handful of running universes. We currently run a test/playground universe, a development/production uni-verse, and a production-only universe.(一个spanner实例称为universe)
- Spanner is organized as a set of zones, where each zone is the rough analog of a deployment of Bigtable servers(spanner由多个zones组成,每个zone可以认为是一个bigtable servers的部署实例)
- Zones are the unit of administrative deploy-ment. The set of zones is also the set of locations across which data can be replicated. (zone是用管理和部署的单元,可以认为数据的每个replication在一个zone里面最多存在一份)
- Zones can be added to or removed from a running system as new datacenters are brought into service and old ones are turned off, respec-tively. (zone能够自由地进入和从数据中心移除)
- Zones are also the unit of physical isolation: there may be one or more zones in a datacenter, for example, if different applications’ data must be partitioned across different sets of servers in the same datacenter.(zone也是物理隔离的单元,可以在一个datacenter里面存在几个zone实例,这样在一个datacenter就可以存在同一个数据的replication多份)
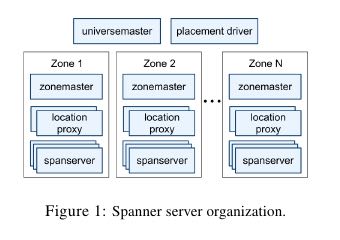
- zonemaster 选择spanserver来serve data
- spanserver serve data
- location proxy 用来定位spanserver location
- universe master和plaecment driver都是单例
- The universe master is primarily a console that displays status information about all the zones for inter-active debugging. (汇总信息)
- The placement driver handles auto-mated movement of data across zones on the timescale of minutes. (在zone之间进行分钟级别自动balance)
- The placement driver periodically commu-nicates with the spanservers to find data that needs to be moved, either to meet updated replication constraints or to balance load.(直接和spanserver通信)
3.1. Spanserver Software Stack
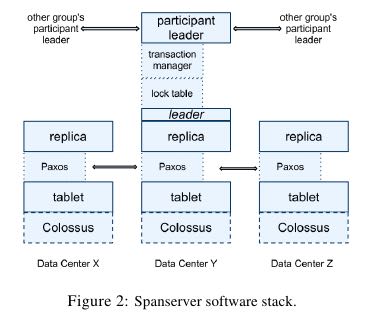
- At the bottom, each spanserver is responsible for between 100 and 1000 instances of a data structure called a tablet.(每个spanserver管理100-1000个tablet实例)
- tablet和bigtable tablet概念非常类似,也是map数据结构并且value存储了多个版本
- tablet’s state is stored in set of B-tree-like files and a write-ahead log, all on a distributed file system called Colossus (the successor to the Google File System) 状态保存在文件以及log上面存储在GFS2
- To support replication, each spanserver implements a single Paxos state machine on top of each tablet. Each state machine stores its metadata and log in its corresponding tablet. (每个tablet上面实现paxos实例,状态机的实例将metadata以及operation log保存在管理的tablet里面)
- Our Paxos implementation supports long-lived leaders with time-based leader leases, whose length defaults to 10 seconds. paxos实现支持长期存在的leader,使用time lease来进行控制,默认是10s
- Our implementation of Paxos is pipelined, so as to improve Spanner’s throughput in the presence of WAN latencies; but writes are applied by Paxos in order 当前的paxos的write是pipeline的来降低WAN的延迟,但是对于每个write都是in order的。
- Writes must initiate the Paxos protocol at the leader; reads access state directly from the underlying tablet at any replica that is sufficiently up-to-date. The set of replicas is collectively a Paxos group.(所有对于tablet的write都是通过paxos leader来发起的,读取可以在任意的replicas上面,replicas组成一个paxos group)
- At every replica that is a leader, each spanserver im-plements a lock table to implement concurrency control. The lock table contains the state for two-phase lock-ing: it maps ranges of keys to lock states. Operations that require synchronization, such as transactional reads, acquire locks in the lock table; other operations bypass the lock table. (在leader上面实现了一个lock table来实现并发控制,使用了2PC的方式来控制提交,存放了key->lock state的映射。对于那些需要同步的操作比如事务读的话那么需要去尝试锁表,否则其他的操作都可以绕过lock table。可以认为lock table只管理一个paxos group/tablet里面的事务读操作)
- At every replica that is a leader, each spanserver also implements a transaction manager to support distributed transactions. The transaction manager is used to imple-ment a participant leader. the other replicas in the group will be referred to as participant slaves (多个paxos group会选举出一个leader来做分布式事务,和paxos group内部的leader作用相同,主要是解决跨tablet的事务)
- If a transac-tion involves only one Paxos group (as is the case for most transactions), it can bypass the transaction manager, since the lock table and Paxos together provide transac- tionality. (如果操作只是发生在一个paxos group上面的话,那么可以绕过transaction manager)
- If a transaction involves more than one Paxos group, those groups’ leaders coordinate to perform two-phase commit.(如果涉及到多个paxos group的话,那么就需要leader来发起2PC)
- The state of each trans-action manager is stored in the underlying Paxos group (and therefore is replicated).(transaction manager的log记录在底层的paxos group)
<大规模分布式存储系统>: 通过Paxos协议实现了跨数据中心的多个副本之间的一致性。另外每个主副本所在的spanserver还会实现一个锁表用于并发控制,读写事务操作某个子表上的目录时需要通过锁表避免多个事务之间相互干扰。除了锁表每个主副本上还有一个事务管理器,如果事务在一个Paxos组里可以绕过事务管理器,但是一旦事务跨多个Paxos组,就需要事务管理器来协调。
3.2. Directories and Placement
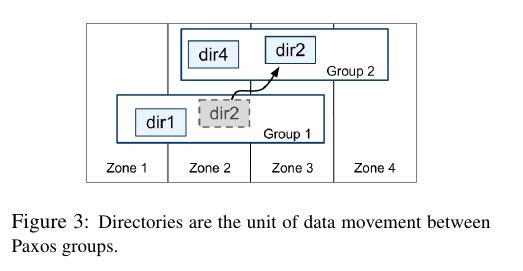
- On top of the bag of key-value mappings, the Spanner implementation supports a bucketing abstraction called a directory, which is a set of contiguous keys that share a common prefix.(directory定义为连续key的集合,对应到directory就可以认为是一个region,但是一个tablet可以包含多个directory)
- A directory is the unit of data placement. All data in a directory has the same replication configuration. When data is moved between Paxos groups, it is moved direc-tory by directory (directory是data placement的最小单元,一个directory里面的data有相同的replication configuration.在paxos group之间移动的话也是按照directory作为单位移动的)
- Spanner might move a directory to shed load from a Paxos group; 将dir移动到低负载的paxos group上面
- to put directories that are frequently accessed together into the same group; 将经常一起访问的dir放在一个group上面
- or to move a directory into a group that is closer to its accessors. 将dir放在离accessor近的位置
- Directories can be moved while client operations are ongoing. 在dir迁移的时候不会影响client访问
- One could expect that 50MB directory can be moved in a few seconds. 传输50MB的目录大概需要几秒钟就可以完成
- The fact that a Paxos group may contain multiple di-rectories implies that a Spanner tablet is different from a Bigtable tablet: the former is not necessarily a single lexicographically contiguous partition of the row space. Instead, a Spanner tablet is a container that may encap-sulate multiple partitions of the row space. We made this decision so that it would be possible to colocate multiple directories that are frequently accessed together.(一个tablet可包含多个directory可以让多个频繁访问的directories聚集在一起提高访问效率)
- Movedir is the background task used to move direc-tories between Paxos groups. Movedir is also used to add or remove replicas to Paxos groups. Movedir is not implemented as a single transaction, so as to avoid blocking ongoing reads and writes on a bulky data move. Instead, movedir registers the fact that it is starting to move data and moves the data in the background. When it has moved all but a nominal amount of the data, it uses a transaction to atomically move that nominal amount and update the metadata for the two Paxos groups.(
- A directory is also the smallest unit whose geographic-replication properties (or placement, for short) can be specified by an application. The design of our placement-specification language separates responsibil-ities for managing replication configurations. Adminis-trators control two dimensions: the number and types of replicas, and the geographic placement of those replicas.(directory也是能够制定replication方案的最小单元,replication方案包括两个维度replicas的数目以及replicas的地理位置)
- For expository clarity we have over-simplified. In fact, Spanner will shard a directory into multiple fragments if it grows too large. Fragments may be served from different Paxos groups (and therefore different servers). Movedir actually moves fragments, and not whole direc-tories, between groups.
3.3. Data Model
- Spanner exposes the following set of data features to applications: a data model based on schematized semi-relational tables, a query language, and general-purpose transactions(数据模型基于schema化的半关系表结构,有query语言,并且支持通用事务)
- schematized semi-relational tables 并且支持强一致性的replication是因为大部分服务都使用了megastore,而megastore是提供这些特性的。
- query language 则是因为dremel提供了这个特性。
- general purpose transaction 则是因为很多application都需要cross row的事务而bigtable没有提供,这也是为什么后面有percolator的原因。
- Some authors have claimed that general two-phase commit is too ex-pensive to support, because of the performance or avail-ability problems that it brings (一些作者宣称使用2PC代价太高,因为其引入的性能和availability)
- We believe it is better to have application programmers deal with per-formance problems due to overuse of transactions as bot-tlenecks arise, rather than always coding around the lack of transactions. (让程序员了解事务的代价然后来选择性地使用事务,总比没有提供事务要好)
- Running two-phase commit over Paxos mitigates the availability problems(而使用paxos实现的2PC能够缓解availability的问题)
- An application creates one or more databases in a universe. Each database can contain an unlimited number of schematized tables. Tables look like relational-database tables, with rows, columns, and versioned values.(应用在universe里面创建一个或者是多个databases,每个databases包含了无限制个数的table,这些table都是有schema的。table看上去非常类似关系数据库的table,有row,column,每个value都带上了version number)
- Spanner’s data model is not purely relational, in that rows must have names. More precisely, every table is re-quired to have an ordered set of one or more primary-key columns. This requirement is where Spanner still looks like a key-value store: the primary keys form the name for a row, and each table defines a mapping from the primary-key columns to the non-primary-key columns(但是table却又不完全是纯关系的,非常类似于bigtable的模型,table定义了primary key,每个row都有primary key之能够通过这个key找到,找到之后有很多columns可以访问,所以看上去又有点类似key-value store,因此称为semi-relational tables)
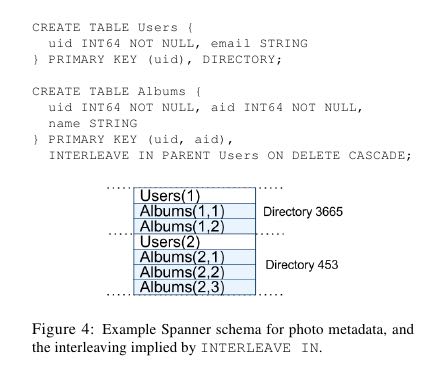
顶层的table标记为"DIRECTORY",所有的subtable primary key都必须以directory table的primary开头,然后subtable都和table放在一起,类似megastore的数据模型。这样顶层的table每行成为一个directory可以任意移动。
4. TrueTime

true time api看上去非常简洁,也非常好理解。就是说请求当前时间点的时候,得到的不是具体的时间点而是一个区间[a,b]. 没有办法准确地告诉这个时间点,但是可以确信这个时间点是在我[a,b]之间,也就是clock uncertainty.
- The underlying time references used by TrueTime are GPS and atomic clocks. TrueTime uses two forms of time reference because they have different failure modes. (TTAPI底层实现上使用了两个计时工具,GPS和atomic clock,之所以使用两种不同的工具是因为他们失效的方式不同)
- GPS reference-source vulnerabilities include an-tenna and receiver failures, local radio interference, cor-related failures (e.g., design faults such as incorrect leap-second handling and spoofing), and GPS system outage (GPS的失效主要是因为参考源抵抗力不好,包括天线或者是接收器的失效,本地电波的干扰,cor-related失效就是说其他错误造成的失败,设计失误比如不正确的闰秒处理,GPS欺骗,还有GPS系统的掉电)
- Atomic clocks can fail in ways uncorrelated to GPS and each other, and over long periods of time can drift signif- icantly due to frequency error.(而atomic block和GPS失效方式没有关系,主要是因为频率错误造成的时间漂移)
- 简单地说就是GPS时间非常精确但是容易受到外部的影响,而atomic可能不非常精确但是不容易受到外部的影响,时钟的参考应该主要着重在GPS,而atomic clock应该只是为了能够应急一些GPS出现问题的情况。
- TrueTime is implemented by a set of time master ma-chines per datacenter and a timeslave daemon per ma-chine. (多个time master机器会部署在一个datacenter,和一个timeslave机器。time master机器用来相互之间校准时间,而timeslave则是同来提供始终查询服务)
- The majority of masters have GPS receivers with dedicated antennas; these masters are separated physi-cally to reduce the effects of antenna failures, radio in-terference, and spoofing.(大部分机器使用GPS来校准时钟)
- The remaining masters (which we refer to as Armageddon masters) are equipped with atomic clocks. An atomic clock is not that expensive: the cost of an Armageddon master is of the same order as that of a GPS master. (剩余的机器使用atomic clock,这些机器相比GPS并没有贵很多)
- All masters’ time references are regularly compared against each other. Each mas-ter also cross-checks the rate at which its reference ad-vances time against its own local clock, and evicts itself if there is substantial divergence. (所有的机器都会相互之间进行交叉校准,如果偏差较大的话那么就停止工作)
- Between synchroniza-tions, Armageddon masters advertise a slowly increasing time uncertainty that is derived from conservatively ap-plied worst-case clock drift. GPS masters advertise un-certainty that is typically close to zero.(在实际同步的过程中,使用atomic clock的机器有缓慢增长的时间偏差区间因为时钟漂移,而GPS的机器的时间偏差基本为0)
- Every daemon polls a variety of masters to re-duce vulnerability to errors from any one master. Some are GPS masters chosen from nearby datacenters; the rest are GPS masters from farther datacenters, as well as some Armageddon masters. (timeslave daemon轮询一系列的master来确定时间以降低因为任何一台master出现错误的风险,一些是从附近的datacenter GPS master,一些是从更远的datacenter GPS master,还有一些是armageddon也就是配备atomic clock master.
- Daemons apply a variant of Marzullo’s algorithm to detect and reject liars, and synchronize the local machine clocks to the non-liars.(daemon使用marzullo算法来检测liars,并且将本地时钟同步到non-liars) To protect against broken local clocks, machines that exhibit frequency excursions larger than the worst-case bound derived from component specifications and operating environment are evicted.(为了防止错误的本地时钟带来的影响,那些时钟偏差超过worst-case bound的频繁发生的机器会直接下线,具体worst-case bound是根据组件规格和操作环境推算出来的)
- Between synchronizations, a daemon advertises a slowly increasing time uncertainty. e is derived from conservatively applied worst-case local clock drift. also depends on time-master uncertainty and communication delay to the time masters.(在两次同步期间,daemon会反应出缓慢增长的time uncertainty,这个范围可以从本地时钟偏移worst-case保守地计算出来,也取决于time-master uncertainty以及comminucation的延迟)
- In our production environ-ment, is typically a sawtooth function of time, varying from about 1 to 7 ms over each poll interval. is there-fore 4 ms most of the time. (实际生产环境下面这个延迟呈现一个锯齿状的,从1增加到7ms, 平均值在4ms)
- The daemon’s poll interval is currently 30 seconds, and the current applied drift rate is set at 200 microseconds/second, which together account for the sawtooth bounds from 0 to 6 ms. The remain-ing 1 ms comes from the communication delay to the time masters.(上面的计算是这样出来的,平均30s同步一次,估算出来当前偏移是200us / s,因此30s是从0-6ms的偏移,在加上和master通信的1ms的延迟)
- Excursions from this sawtooth are possi-ble in the presence of failures. For example, occasional time-master unavailability can cause datacenter-wide in-creases in . Similarly, overloaded machines and network
links can result in occasional localized spikes.(但是如果出现故障的话那么超过这个锯齿装的还是可能的,比如偶尔的timemaster不可用,或者是机器和网络出现overload的情况会造成延迟加大等)
<大规模分布式存储系统>: 为了实现并发控制,数据库需要给每个事务分配全局唯一的事务id。然而在分布式系统中很难生成全局唯一id。一种方式才哦那个percolator中的做法,专门部署一套Oracle数据库用于生成全局唯一id。虽然Oracle逻辑上是一个单点,但是实现的功能单一,因而能够做得很高效。
我的理解是,整个uncertainity分为3个部分:
- time masters上的,GPS以及atomic clock估计出来的时间偏差。
- local clock上的,200us/s的drift. 这个drift可以认为是有上限保证的。
- network latency, 上限认为是1ms。
5. Concurrency Control
完全看不懂。。。。
6. Evaluation
6.1. Microbenchmarks
6.2. Availability
6.3. TrueTime
- Two questions must be answered with respect to True- Time: is e truly a bound on clock uncertainty, and how bad e does get?(两个关键的问题就是偏移是否可以按照我们估算范围给出上界,另外就是偏移最坏能到什么情况)
- For the former, the most serious prob-lem would be if a local clock’s drift were greater than 200us/sec that would break assumptions made by True-Time (对于第一个问题我们假设clock drift在200us/s, 如果这个假设不能够成立的话那么我们没有办法给出上界)
- Our machine statistics show that bad CPUs are 6 times more likely than bad clocks. (但是机器统计发现坏的CPU数量是clock有问题的CPU数量的6倍)
- That is, clock issues are extremely infrequent, relative to much more serious hardware problems. (因此相对于更加严重的硬件鼓掌来说,clock issume问题非常小)
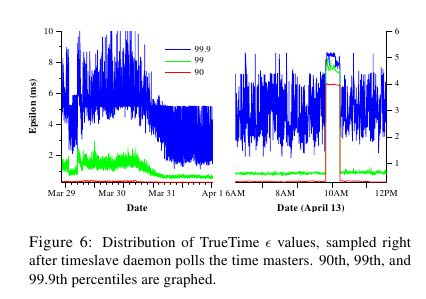
- several thou-sand spanserver machines across datacenters up to 2200 km apart. It plots the 90th, 99th, and 99.9th percentiles of sampled at timeslave daemons immediately after polling the time masters(下面的图统计出了跨越2200km的spanner机器的时间偏移统计,这些时间偏移都是在和timeslave在同步timemaster之后立刻描绘出来的,统计了90%,99%,99.9%的时间偏移,可以看到是非常小的。第一张图里面后半部分的下降是因为改进了网络拥塞,第二张图里面的高峰主要是因为当时下线了几台time masters)
6.4. F1
F1是google广告系统的后端,最开始是基于MySQL做的,按照customer进行sharding. 但是这个东西的扩展性不好,最近一次的resharding花费了2年时间,所以想彻底解决这个问题。F1需要的就是一个强一致性,支持分布式事务,关系型数据库。
Spanner started being experimentally evaluated under production workloads in early 2011, as part of a rewrite of Google’s advertising backend called F1 [35]. This backend was originally based on a MySQL database that was manually sharded many ways. The uncompressed dataset is tens of terabytes, which is small compared to many NoSQL instances, but was large enough to cause difficulties with sharded MySQL. The MySQL sharding scheme assigned each customer and all related data to a fixed shard. This layout enabled the use of indexes and complex query processing on a per-customer basis, but required some knowledge of the sharding in application business logic. Resharding this revenue-critical database as it grew in the number of customers and their data was extremely costly. The last resharding took over two years of intense effort, and involved coordination and testing across dozens of teams to minimize risk. This operation was too complex to do regularly: as a result, the team had to limit growth on the MySQL database by storing some data in external Bigtables, which compromised transactional behavior and the ability to query across all data.