Bigtable: A Distributed Storage System for Structured Data
Table of Contents
- http://research.google.com/archive/bigtable.html @ 2006
- Google Bigtable (中文版) http://dblab.xmu.edu.cn/node/121
1. Abstract
- Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers. (针对千台机器管理PB级别数据)
- both in terms of data size (from URLs to web pages to satellite imagery) and latency requirements (from backend bulk processing to real-time data serving).(同时考虑了数据集大小以及响应延迟)
2. Introduction
- Bigtable does not support a full relational data model; instead, it provides clients with a simple data model that supports dynamic control over data layout and format, and al-lows clients to reason about the locality properties of the data represented in the underlying storage.(不支持完全的数据库关系模型。提供的是半结构化数据模型,支持动态控制数据布局和格式,允许用户通知数据用于底层存储的locality信息)
- Data is in-dexed using row and column names that can be arbitrary strings.(通过行列来进行索引)
- Bigtable also treats data as uninterpreted strings, although clients often serialize various forms of struc-tured and semi-structured data into these strings. (数据可以是半结构化也可以是结构化的)
- Clients can control the locality of their data through careful choices in their schemas. (通过设计schema来控制locality信息)
- Bigtable schema pa-rameters let clients dynamically control whether to serve data out of memory or from disk.(schema参数可以让用户动态控制是否使用超过内存大小数据)
3. Data Model
- A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.(本质上是稀疏的,分布式,可持久化的多维sorted-map。通过row-key和column-key找到对应的cell,在这个cell上面通过timestamp来从多维数据中取出一维) (row:string, column:string, time:int64) => string
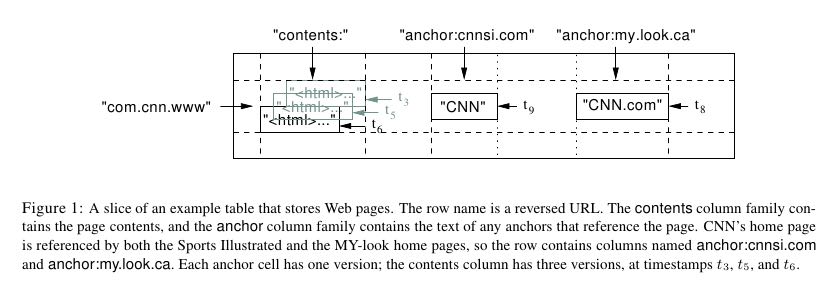
3.1. Rows
- The row keys in a table are arbitrary strings (currently up to 64KB in size, although 10-100 bytes is a typical size for most of our users). (rowkey范围限制在64KB,但是10-100bytes是一个典型值)
- Every read or write of data under a single row key is atomic (regardless of the number of different columns being read or written in the row), a design decision that makes it easier for clients to reason about the system’s behavior in the presence of concurrent updates to the same row.(对于每一行的读写都是原子操作的,这样对于concurrent更新的话比较好reason)
- Bigtable maintains data in lexicographic order by row key. The row range for a table is dynamically partitioned. Each row range is called a tablet, which is the unit of dis-tribution and load balancing.(对于row-key都是按照字典序排列的,并且每个row range都会动态划分。划分出来的row range对应的数据成为tablet,其实就是table里面一个连续的小部分,非常类似于chunk,作为分布以及负载均衡的最小单元)
3.2. Column Families
- Column keys are grouped into sets called column fami-lies, which form the basic unit of access control (所有的column都放在某一个column family下面进行管理)
- All data stored in a column family is usually of the same type (we compress data in the same column family together).(通常在一个column family下面的column都是相同类型的,这样方便进行压缩)
- A column family must be created before data can be stored under any column key in that family; after a family has been created, any column key within the family can be used. (首先需要创建cf,之后可以在cf下面创建任意的column)
- It is our intent that the number of distinct column families in a table be small (in the hundreds at most), and that families rarely change during operation. In contrast, a table may have an unbounded number of columns.(设计假设cf非常少最多100个左右,并且不会经常变化。而对于里面的column来说没有上限)
- Access control and both disk and memory account-ing are performed at the column-family level(底层访问操作通常都是针对cf进行的。使用cf聚合的话,一方面可以减少访问多个字段的代价,另外在存储方面也可以进行压缩)
3.3. Timestamps
- Each cell in a Bigtable can contain multiple versions of the same data; these versions are indexed by timestamp. Bigtable timestamps are 64-bit integers. They can be as-signed by Bigtable, in which case they represent “real time” in microseconds, or be explicitly assigned by client applications. Applications that need to avoid collisions must generate unique timestamps themselves. Different versions of a cell are stored in decreasing timestamp or-der, so that the most recent versions can be read first.(timestamp用来区分多个版本,timestamp是一个64bit整数,这个可以由bigtable产生也可以用户指定。主要功能就是为了区分版本。所有的版本都是存放在一起并且按照降序排列,因为首先读取是最新的版本)
- To make the management of versioned data less oner-ous, we support two per-column-family settings that tell Bigtable to garbage-collect cell versions automatically. The client can specify either that only the last n versions of a cell be kept, or that only new-enough versions be kept (e.g., only keep values that were written in the last seven days).(支持针对每个cf设置使用最近几个版本)
4. API
5. Building Blocks
- 使用GFS作为文件系统(参考gfs)
- 使用SSTable来管理数据(参考leveldb)
- 使用Chubby来管理调度(参考chubby)
- to ensure that there is at most one active master at any time; (确保只有一个master在运行)
- to store the bootstrap location of Bigtable data(保存初始化bigtable数据的位置)
- to discover tablet servers and finalize tablet server deaths (检测tablet server的上下线)
- to store Bigtable schema information (the column family information for each ta-ble); (存储schema信息,每个table里面的cf信息)
- to store access control lists.(访问控制列表)
- If Chubby becomes unavailable for an extended period of time, Bigtable be-comes unavailable.(如果chubby不可用那么整个集群不可用)
- 但是影响效果非常小。集群数据不可用因为chubby不可用的平均比率在0.0047%,但个集群受影响最高比率在0.0326%
6. Implementation
- The Bigtable implementation has three major compo- nents: a library that is linked into every client, one mas- ter server, and many tablet servers. (library,master server以及tablet server三个部分组成) Tablet servers can be dynamically added (or removed) from a cluster to acco-modate changes in workloads.(对于所有的tablet server都可以动态添加并且移除来适应workload)
- master负责包括下面这些事情:
- assigning tablets to tablet servers, (assign tablet到ts上)
- detecting the addition and expiration of tablet servers, (检测是否有tablet server挂掉)
- balancing tablet-server load, and (对tablet server做负载均衡)
- garbage col-lection of files in GFS. (对GFS进行GC)
- In addition, it handles schema changes such as table and column family creations.(处理schema变化以及cf的创建)
- tablet server负责下面这些事情:
- Each tablet server manages a set of tablets (typically we have somewhere between ten to a thousand tablets per tablet server). (每个tablet server分配到10-1k左右的tablet)
- The tablet server handles read and write requests to the tablets that it has loaded, (每个tablet server负责其管理的tablet操作)
- and also splits tablets that have grown too large.(如果tablet过大的话那么主动进行分裂,默认每个tablet在100-200MB左右) #note: 现在HBase的一个region在2G
- client直接和tablet server进行交互。因为client并不依赖于master来进行location定位,所以大部分时候不需要和master交互,因此master负载非常轻。
6.1. Tablet Location
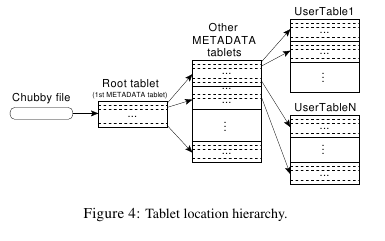
- root tablet是比较特殊的METADATA tablet从来不进行分裂
- METADATA tablet是kv结构并且是有序的。其中k是table identifier+end row key,v则是对应志向的位置(位置信息应该都是GFS的地址)
- 查找的时候首先在root tablet上面做二分查找,找到对应的METADATA tablet。
- 然后在METADATA tablet上面做二分找着,找到对应的user tablet。
- 然后在user tablet上面找到对应的值。
- meta tablet server每行存储大概1KB数据,一个大约使用128MB内存,这样对于三级结构来说允许存储大约我2^34个tablets。
- client会cache tablet位置,但是如果位置信息错误的话,那么需要逐层向上查询。因为对于cache empty情况需要3个roundtrip,而对于stale情况需要6个roundtrip
- Although tablet locations are stored in memory, so no GFS accesses are required, we further reduce this cost in the common case by having the client library prefetch tablet locations: it reads the metadata for more than one tablet whenever it reads the METADATA table. #todo: 预取可以减少什么开销呢?
6.2. Tablet Assignment
assignment这个信息应该是维护在master上面的,且没有必要进行持久化。
如何处理tablet server挂掉:
- 所有的tablet server都在chubby上面注册节点并且加锁。如果和chubby节点断开的话,那么重新连接并且获取锁。如果文件已经删除的话,那么就自动退出。
- master会定时询问tablet server是否存活。如果没有查询到存活的话,那么会尝试lock tablet server创建的节点。如果lock成功的话,那么删除这个文件。这样确保tablet server之后不会继续服务。
- 如果master认为某个ts挂掉的话,那么会重新assign原来分配所有的tablet出去。
- 如果master和chubby断开的话,那么也会自己直接退出。
master启动时候需要重新获得assignment信息:
- master重启的话不会影响assignment
- master在chubby上面创建一个文件并且lock
- 和当前所有的tablet server进行通信,获得所有的tablet server。
- 如果METADATA tablet server没有被assign的话,那么assign META ts
- 扫描所有的META ts,看哪些tablet server没有被assign出去,如果没有assign的话那么发起assign
如果tablet server上面的tablet发起变化的话,那么也会有assign行为:
- table创建删除
- 两个tablet进行merge成为一个大的tablet(这个master才能够看到)
- tablet split(这个单个tablet server就能够感知到自己的tablet过大从而需要split)
对于前面两个行为的话是master发起的话能够追踪所有的变化。
对于tablet server发起操作导致tablet变化的话,完成之后写入METADATA tablet,通知master。
In case the split notification is lost (either because the tablet server or the master died), the master detects the new tablet when it asks a tablet server to load the tablet that has now split. The tablet server will notify the master of the split, because the tablet entry it finds in the METADATA table will specify only a portion of the tablet that the master asked it to load.
6.3. Tablet Serving
6.4. Compactions
compaction分为三种:
- minor compaction. memtable -> sstable
- merging compaction. sstable + memtable -> sstable(s)
- major compaction. sstable -> one sstable
其中leveldb里面实现只有前面两种。merging compaction就是几个sstable合并(合并的sstable里面没有deletion),而major compaction回将所有的sstable合并成为一个sstable(里面没有任何deletion)
7. Refinements
7.1. Locality groups
通过将多个cf合并成为一个locality group,然后为这个locality group分配单独的一个sstable。通过将不同属性的cf区分开,并且将相同属性的cf进行聚合,这样可以提高读效率。允许指定参数来说明那些locality group需要放在memory里面。
7.2. Compression
- The first pass uses Bentley and McIlroy’s scheme , which compresses long common strings across a large window.
- The second pass uses a fast compression algorithm that looks for repetitions in a small 16 KB window of the data.
- Both compression passes are very fast—they encode at 100–200 MB/s, and decode at 400–1000 MB/s on modern machines.
7.3. Caching for read performance
- Scan Cache在高层缓存读取到的k/v。比较适合重复读取相同数据(相对与Block Cache效率更好)
- Block Cache在底层缓存读取到的block。比较适合遍历或者是反复读取附近数据。(leveldb实现里面只是提供了block cache)
7.4. Bloom filters
新版本的leveldb里面也实现了bloom filter,可以屏蔽掉很多无用的disk seek
7.5. Commit-log implementation
如果每个tablet的操作都写单独的redo文件的话,那么会对gfs造成很大的压力。因此解决办法就是,对于一个tablet server上面所有的tablet的commit log,都记录在同一个文件里面。
但是这样会对recovery造成一定的问题:假设这个tablet server上面有100 tablet的话,如果down掉,那么100 tablet重新assign之后每个tablet server都需要读取这个文件, 然后根据log里面的内容判断除外哪些log是自己需要的。
这个问题的解决是通过将这个log进行排序。如果有一个tablet server需要读取这个log的话,那么会通知master,master发起排序操作。按照 (table, row name, log sequence number ) 这个复合键进行排序。排序之后每个tablet server只需要找到相应的偏移就可以开始顺序读取了。
另外写gfs的时候也可能因为很多原因造成perfor-mance hiccups(e.g., a GFS server machine involved in the write crashes, or the network paths traversed to reach the particular set of three GFS servers is suffering network congestion, or is heavily loaded).,为了减少latency spike,对于tablet server写commit log是采用两个线程完成的,但是只有一个线程在执行。如果一个线程写入比较慢的话,那么就会切换到另外一个线程写入。因为log里面都带了sequence number,所以在读取的时候可以进行判重避免读取重复数据。
7.6. Speeding up tablet recovery
这个主要发生在tablet主动迁移的时候。因为迁移的时候memtable内容没有存放到gfs上面,因此如果直接unload的话,那么在另外一台机器上面就需要重新从gfs读取log并且进行recovery。 为了加快这个过程,source tablet server在主动迁移时候发生如下行为:
- 将memtable使用minor compaction将内容写入sstable
- 停止对这个tablet的服务
- 将上面时间内所有的memtable操作重新做一个minor compaction(very fast)
这样另外一台机器load tablet的时候就可以直接使用了。
7.7. Exploiting immutability
对于obsolete tablet sstable的回收过程是这样的:
- 从root里面可以获得所有的tablet对应的sstable(tablet管理的sstable都在METADATA tablet上面注册了)
- master可以查询每个tablet server所管理的sstable
- 对比master就可以发现那些sstable是可以被GC的。
8. Performance Evaluation
9. Real Applications
10. Lessons
- One lesson we learned is that large distributed sys-tems are vulnerable to many types of failures, not just the standard network partitions and fail-stop failures as-sumed in many distributed protocols.(design for failure)
- delay adding new features until it is clear how the new features will be used. 延迟添加新功能直到确实存在必要。之前考虑过是否需要增加general-purpose transaction,但是知道很多真实应用程序使用之后才发现,其实需要的是一个row transaction。而对于distributed transaction的需求,大部分是想维护二级索引。Where people have requested distributed trans-actions, the most important use is for maintaining sec-ondary indices, and we plan to add a specialized mech-anism to satisfy this need. The new mechanism will be less general than distributed transactions, but will be more efficient (especially for updates that span hundreds of rows or more) and will also interact better with our scheme for optimistic cross-data-center replication. 对于维护二级索引方案使用了一个特殊方式来满足这个需求。
- A practical lesson that we learned from supporting Bigtable is the importance of proper system-level mon-itoring (i.e., monitoring both Bigtable itself, as well as the client processes using Bigtable). (监控)
- we ex-tended our RPC system so that for a sample of the RPCs, it keeps a detailed trace of the important actions done on behalf of that RPC. This feature has allowed us to de-tect and fix many problems such as lock contention on tablet data structures, slow writes to GFS while com-mitting Bigtable mutations, and stuck accesses to the METADATA table when METADATA tablets are unavail-able. (lock contention,slow write,stuck access to METADATA)
- Another example of useful monitoring is that ev-ery Bigtable cluster is registered in Chubby. This allows us to track down all clusters, discover how big they are, see which versions of our software they are running, how much traffic they are receiving, and whether or not there are any problems such as unexpectedly large latencies.(cluster注册到chubby上面,收集每个cluster的一些数据)
- The most important lesson we learned is the value of simple designs. (简单设计)
11. Related Work
12. Conclusions
- Bigtable clusters have been in production use since April 2005, (2005.4开始投入产品使用)
- and we spent roughly seven person-years on design and implementa-tion before that date. (耗费7人年)
- As of August 2006, more than sixty projects are using Bigtable.(2006.8 60个项目使用bigtable)
- We are in the process of implementing several addi-tional Bigtable features, such as support for secondary indices and infrastructure for building cross-data-center replicated Bigtables with multiple master replicas.(支持二级索引以及使用multi-master跨机房的解决方案)
- We have also begun deploying Bigtable as a service to prod-uct groups, so that individual groups do not need to main-tain their own clusters. 将bigtable cluster作为service对外。
- As our service clusters scale, we will need to deal with more resource-sharing issues within Bigtable itself 对于service的话,那么就需要考虑资源隔离以及有效利用。
From 《大规模分布式存储系统》
BgigTable架构也存在一些问题:1) 单副本服务。bigtable架构非常适合离线和半线上应用,然而tableserver节点出现故障时部分数据短时间内无法提供读写服务,不适合实时性要求特别高的业务比如交易类型业务。2) SSD使用。google整体架构的设计理念为通过廉价机器构建自动容错的大集群,然而随着SSD等硬件技术到发展,机器宕机概率变得更小,SSD和SAS混合存储也变得非常常见,存储和服务分离的架构有些不太适应。3) 架构的复杂性导致Bug定位很难,bigtable依赖gfs和chubby,这些依赖系统本身比较复杂。另外bigtable多级分布式索引和容错等机制内部实现都非常复杂,工程量巨大,使用的过程中如果发现问题很难定位。