The Chubby lock service for loosely-coupled distributed systems
Table of Contents
http://research.google.com/archive/chubby.html @ 2006
1. Abstract
- lock service to allow its clients to sync activities and agree on basic information about their environment.
- coarse-grained locking
- for loosely-coupled distributed system
- interface like distributed file system
- with advisory lock
- emphasis on availability and reliability to a moderately large set of clients.
- opposed to high performance
- handling a few tens of thousands of clients concurrently.
2. Introduction
- loosely-coupled dist system consisting of moderately large numbers of small machines connected by a high-speed network.
- a chubby instance aka. a chubby cell serve ten thousand 4-processor machines connected by 1Gbps Ethernet.
- most cells confined to a single machine room or data centre, but some whose replicas are seperated by thousands km.
- reliability, availibity, and easy-to-understand semantics considered as primary.
- throughput and storage capacity considered as secondary.
- perform whole-file reads and writes.
- with notification events such as file modification.
- mainly usage in GFS and BigTable
- to elect a master
- to allow the master to discover the servers it controls
- to permit clients to find the master
- to store a small amount of meta-data in a well-known and available location.
- to use locks to partition work between several servers.
- distributed asynchronous consensus solved by Paxos protocol without timeing assumptions.
- introduce clocks to ensure liveness(overcomes impossibility result of Fischer).
- not research, no new algorithms and techniques, but just what we did and why.
3. Design
对于Abstracr以及Introduction这两节来说的话,使用原文list item的方式就可以有比较好的总结了。而对于其他部分的话,使用这种描述方法似乎就有点不太适合。因为相对Abstracr以及Introduction来说的话,其他section信息量会相对较大。合适的方式应该任然是list item,但是不能够使用原文而应该自己总结。并且这些list item可能会比较长,因为需要将一些聚合性的内容放在一个item内部。当然可以在list item内部引述一些原文信息。
3.1. Rationale
- library vs. service(库和服务之间的选择对比)
- a client Paxos library is independent and easier for programmers to develop on it. Indeed, we provide such a client library that is independent of Chubby.
- As the service matures and gains clients, availability becomes more important; replication and primary election are then added to an existing design. While this could be done with a library that provides distributed consensus, a lock server makes it easier to maintain existing program structure and communication patterns.(开始程序员可能不太注意可用性这个东西,然而当项目逐渐成熟的时候可用性则必须考虑。使用lock server相对于library来说可以更容易地完成这件事情)
- many of our services that elect a primary or that partition data between their components need a mechanism for advertising the results. This could be done with a name service, but our experience has been that the lock service itself is well-suited for this task, both because this reduces the number of servers on which a client depends, and because the consistency features of the protocol are shared.(对于大部分服务需要广播其数据,虽然可以通过轮询名字服务来完成,但是如果通过lock service来完成的话可以节省服务器数目并且保持一致性。分布式一致性算法虽然可以用来实现名字服务但是对于这个问题解决并不高效)
- a lock-based interface is more familiar to our programmers, the apparent familiarity of locks overcomes a hurdle in persuading programmers to use a reliable mechanism for distributed decision making.(锁编程界面对于程序员来说心智负担更小,而从分布一致性算法从头完成锁的开发对于程序员负担更大)
- distributed-consensus algorithms use quorums to make decisions, so they use several replicas to achieve high availability. For example, Chubby itself usually has five replicas in each cell, of which three must be run-ning for the cell to be up. comparing to consensus service, lock service is much general and more capable.(分布式一致算法需要多台机器才能完成决策,我们可以使用多台机器来做到高可用性)
- choose a lock service as opposed to a library or service for consensus.
- choose serve small-files to permit elected primaries to advertise themselves and their parameters rather than build and maintain a second service.
- a service advertising its primary via a Chubby file may have thousands of clients.
- client and replicas of a replicated service may wish to know when service's master changes. an event notification mechanism would be useful to avoid polling.
- even if clients need not poll files periodically, many will do. so cacheing of files is desirable.
- we prefer consistent caching to avoid confusing developers.
- security mechanisms including access control is necessary.
coarse-grained vs. find-grained.(粗粒度锁和细粒度锁之间的选择对比)
- different lock duration. find-grained lasts seconds or less. coarse-grained lasts hours or days.
- Coarse-grained locks impose far less load on the lock server.(粗粒度锁的负载通常比较低)
- In particular, the lock-acquisition rate is usually only weakly related to the transaction rate of the client applications. Coarse-grained locks are acquired only rarely, so temporary lock server unavailability delays clients less.(相对于客户端的操作来说,获取锁这个比率相对来说还是比较低的。因此如果lock server临时不可用的话,对于客户端造成的延迟更小)
- On the other hand, the transfer of a lock from client to client may require costly recovery proce-dures, so one would not wish a fail-over of a lock server to cause locks to be lost.(这里不太理解client-client锁传递的意思。我理解作者可能是要说正是因为锁的丢失需要非常繁琐的恢复过程,因此lock server如果failover的话,锁是不允许丢失的)
- Even brief unavailability of the lock server may cause many clients to stall.(对于细粒度锁来说的话,服务的负载比较高。并且任何时候的unavailability的话都会造成许多client停滞不前)
- Performance and the ability to add new servers at will are of great concern because the trans-action rate at the lock service grows with the combined transaction rate of clients.(细粒度锁负责通常比较高,而且通常是和client的操作数量成比率增长的)
- It can be advantageous to re-duce the overhead of locking by not maintaining locks across lock server failure, and the time penalty for drop-ping locks every so often is not severe because locks are held for short periods. (Clients must be prepared to lose locks during network partitions, so the loss of locks on lock server fail-over introduces no new recovery paths.)(但是可以通过一些取巧的方法来减少overhead或者是放宽一些条件,但是这些都需要client的配合)
- #todo: 如何将粗粒度锁转换成为细粒度锁
3.2. System structure
- Chubby has two main components that communicate via RPC: a server, and a library that client applications.(chubby主要提供的就是service以及访问service所需要的protocol实现)
- a chubby cell consists of a small set of servers(typically five) known as replicas to reduce the likelihood of correlated failure.
- replicas use dist consensus protocol to elect a master who obtain votes from a majority of the replicas(replicas之间通过分布一致性协议选择出master,这个master必须是获得大部分投票的)
- replicas will not elect a different master for an interval of a few seconds known as the master lease.(一旦master选举出来之后的话那么master会持续一段时间成为租期)
- The master lease is periodically renewed by the replicas provided the master continues to win a majority of the vote.(租期可能会不断地延长只要新选举出来的master没有发生变化)
- The replicas maintain copies of a simple database, but only the master initiates reads and writes of this database. All other replicas simply copy updates from the master, sent using the consensus protocol.(所有读写操作都在master上面,replicas之间的同步是通过一致性协议来完成的)
- Clients find the master by sending master location requests to the replicas listed in the DNS. Non-master replicas respond to such requests by returning the identity of the master.(client如果询问的是non-master的话,那么返回的就是master的位置,然后client在与master进行通信。所有的replicas位置都是记录在DNS里面的)
- Once a client has located the master, the client directs all requests to it either until it ceases to respond, or until it indicates that it is no longer the master. (只要master继续repsond并且告诉client自己是master的话,那么client之后都会持续和这个master交互)
- Write requests are propagated via the consensus protocol to all replicas; such requests are acknowledged when the write has reached a majority of the replicas in the cell. (对于master上面的write操作都会通过一致性协议写到各个replicas上面并且需要得到大部分replicas的ack)
- Read requests are satisfied by the master alone; this is safe provided the master lease has not expired, as no other master can possibly exist.
- If a master fails, the other replicas run the election protocol when their master leases expire; a new master will typically be elected in a few seconds.(这点非常重要,如果master挂掉的话那么replicas时间是不会进行选举的直到确定master租期已经过期)
- If a replica fails and does not recover for a few hours, a simple replacement system selects a fresh machine from a free pool and starts the lock server binary on it. It then updates the DNS tables, replacing the IP address of the
failed replica with that of the new one. The current mas-ter polls the DNS periodically and eventually notices the change. It then updates the list of the cell's members in the cell's database; this list is kept consistent across all the members via the normal replication protocol. In the meantime, the new replica obtains a recent copy of the database from a combination of backups stored on file servers and updates from active replicas. Once the new replica has processed a request that the current master is waiting to commit, the replica is permitted to vote in the elections for new master.(如果replica挂掉的话那么可以人工重启一个机器,将这个机器IP加入DNS将原来down的replica IP从DNS删除。当前master会定期地查询这些变化,并且通过普通协议将发生的变化同步到所有的members里面。同时replica会从databases里面选取一个备份进行数据恢复。一旦完成之后这个new replica就可以参与到election里面来了)
3.3. Files, directories and handles
- interface simliar to unix file system but simpler. consists of a strict tree of files and directories in the usual way with name components separated by slashes.
- take '/ls/foo/wombat/pouch' as exmplale. 'ls' is chubby cell prefix, 'foo' is name of chubby cell, '/wombat/pouch' is interpreted within the named chubby cell.
- each di-rectory contains a list of child files and directories, while each file contains a sequence of uninterpreted bytes.
- not support move files, not maintain directory modified times, avoid path-dependent permission semantics(access to a file is controlled by the permissions on the file itself rather than on directories on the path leading to the file), not reveal last-access times to make it easier to cache file meta-data.(不支持文件移动,没有维护目录的修改时间,避免了路径依赖的权限语义,并且为了更方便地cache文件的元信息没有提供文件最近访问时间)
- files and directories collectively called nodes. no symbolic or hard links. maybe either permanent or ephemeral. Any node may be deleted explicitly, but ephemeral nodes are also deleted if no client has them open (and, for directo-ries, they are empty). Ephemeral files are used as tempo-rary files, and as indicators to others that a client is alive. Any node can act as an advisory reader/writer lock;(文件和目录都被称为nodes.不支持软硬链接。对于节点来来说可以是永久的也可以是临时的。永久的节点删除需要显示完成,而临时节点在没有任何client持有它的时候也会删除,对于目录来说的话还必须保证目录为空。任何node都可以用来提供读写锁机制)
- Each node has various meta-data, including three names of access control lists (ACLs) used to control reading, writing and changing the ACL names for the node.(每个节点都会有元数据,ACL也属于元数据控制文件权限)
- 文件ACL非常简单类似于Plan 9里面的groups,也是通过类似于文件管理的方式来完成的。ACL文件单独作为一个目录存放。如果文件F的写权限ACL文件是foo,而foo下面包含bar的话,那么表明user bar这个用户对F有写权限。如果用户没有设置文件ACL的话,那么文件的ACL自动从上面所在的目录继承下来。
- 每一个文件节点的元信息包含了下面4个自增的数字(id)(uint64)来使得用户可以容易地检测变化:
- instance number. 同名节点不同实例的id.如果某个name被删除然后重新创建的话,那么id是不同的。#note: 但是我觉得完全可以使用节点实例id来区分的而不必同名。
- content generation number. 每次节点内容的改写都会增加这个数字。
- lock generation number. 节点提供的lock每次从free转换为held就会增加这个数字。
- ACL generation number. 节点对应ACL文件每次修改就会增加这个数字。
- 文件节点还提供了64bit文件checksum也可以帮助检测变化。
- chubby提供的文件handle包含下面几个部分:
- check digits.可以认为是和session相关的数字,这个数字仅仅是为了放置用户做恶意构造handle.(当然也可以在一定程度上面做到防御式编程)
- sequence number.master own id.可以区分这个handle是不是属于其他session的。(比如master重新发生选举)
- mode information.如果old handle提供的话那么可以通过old handle里面的mode information,当前master可以重新构造一些状态。
3.4. Locks and sequencers
- Each Chubby file and directory can act as a reader-writer lock.
- Like the mutexes known to most programmers, locks are advisory.
- advisory vs. mandatory lock
- Chubby locks often protect resources implemented by other services, rather than just the file associated with the lock.(chubby实现的锁保护的并不是锁文件本身,而是锁相关的资源)
- We did not wish to force users to shut down appli-cations when they needed to access locked files for debugging or administrative purposes.(如果锁是强制的话并且我们如果需要访问,那么我们必须将持有锁的应用程序关闭。这点在很多个人桌面上可以很容易地操作,但是在复杂系统中这么做的话并不现实)
- Our developers perform error checking in the conven-tional way, by writing assertions such as "lock X is held", so they benefit little from mandatory checks. Buggy or malicious processes have many opportuni-ties to corrupt data when locks are not held, so we find the extra guards provided by mandatory locking to be of no significant value.(强制锁带来的保护作用并不大)
- In Chubby, acquiring a lock in either mode requires write permission so that an unprivileged reader cannot prevent a writer from making progress.(无论采用何种模式都必须对节点有写权限)
- Locking is complex in distributed systems because communication is typically uncertain, and processes may fail independently. (锁在分布式系统中比较复杂主要是因为通讯的不确定性,并且进程可能会在任何时候挂掉)
- 文章中给出了一个例子来解释这个问题,主要就是因为我们没有办法确保request到达顺序。The problem of receiving messages out of order has been well studied; solutions include virtual time, and vir-tual synchrony, which avoids the problem by ensuring that messages are processed in an order consistent with the observations of every participant. 这些方式都相当于在系统内部引入了sequence number这样的机制。
- It is costly to introduce sequence numbers into all the interactions in an existing complex system. Instead, Chubby provides a means by which sequence numbers can be introduced into only those interactions that make use of locks.(在已有的系统中引入sequence mumber代价非常大,所有chubby仅仅是在使用lock的地方考虑使用sequence number)
- chubby通过引入sequencer机制来完成的。lock holder在第一次获得锁之后会得到一个lock generation number.然后组织成为一个字符串(name, permission, lock generation number).
- 之后每次请求的话都会带上这个字符串。服务器端可以通过得到这个字符串来当前lock是否有效,并且也可以根据lock generation number来进行排序。如果无效的话那么会直接拒绝client.
- The validity of a sequencer can be checked against the server's Chubby cache or, if the server does not wish to maintain a ses-sion with Chubby, against the most recent sequencer that the server has observed.
- chubby对于legacy system并没有使用sequencer方式,而是使用imperfect but easier mechanism方式来减少乱序的风险。对于正常的锁之间转移的话没有任何问题,但是如果lock holder中途挂掉的话那么会在master端有一个lease timeout.在这段时间内是不允许其他client来获取这个锁的。这样只要在lease timeout这段时间将这个lock上的操作处理完成那么就没有问题。
3.5. Events
- Chubby clients may subscribe to a range of events when they create a handle. These events are delivered to the client asynchronously via an up-call from the Chubby li-brary.(client可以在handle上面订阅一系列的事件,而这些事件的通知是通过异步方式完成的). 允许订阅的事件包括下面这些:
- 文件内容发生修改,可以用来检测name service变化.
- 节点发生变化,可以用来实现mirroring.
- master failed over. failover时间发生事件会丢失,那么client需要针对数据重新rescan.
- lock acquired. 某个文件的锁被持有到了。通常意味着primary被选举出来。
- conflicting lock request from another client. 可以用来在client做一些数据cache.
- Events are delivered after the corresponding action has taken place. Thus, if a client is informed that file contents have changed, it is guaranteed to see the new data (or data that is yet more recent) if it subsequently reads the file.(event是在动作发生之后才会触发的。如果文件发生修改的话,那么在回调中读取的必然是最新的数据)
- 对于最后面两个action来说的话其实完全是不需要的。对于lock acquired来说的话,我们通常不是为了知道这个primary被选举出来了,而是要知道哪个是primary并且与之通信。这点完全可以通过name service来触发。conflicting lock request可以用来辅助client进行数据cache.但是很少人使用这种用法。
- #note: 我猜想应该是自己释放了cache lock同时cache住了原来的数据,只要没有新的write lock申请的话,原来的数据就还是可以使用的。
- #note: 关于这个信息可以在cache最后部分看到,chubby也对lock进行了cache.
3.6. API
API似乎和zookeeper有点不太相同。zookeeper API连接上server之后可以按照node name进行操作。对于不同的handle来说,server可以认为是不同的client.
- Open. takes a node name and return an opaque structured handle.(不允许使用current directory,在多线程中会存在问题).
- Close. never fails并且释放内存.后续操作都是失败的。
- Posion. 和Close非常像但是并不会释放内存。其他线程如果继续操作的话那么会失败但是却不会访问无效内存。
- GetContentsAndStat. node的内容和文件元信息 in a atomic way.
- GetStat. node元信息
- ReadDir. 目录下面所有的children和每个node的元信息
- SetContents. 写入content.可以带上content generation number来做CAS操作
- SetACL. 设置文件ACL.
- Delete. 删除节点必须确保没有children.
- Acquire/TryAcquire/Release. 锁操作.
- GetSequencer. 获得任意一个lock held by handle的sequencer.
- SetSequencer. 给handler设置一个sequencer.如果这个sequencer无效的话那么后续操作都是失败的。
- CheckSequencer. 检查Sequencer是否合法
- handle创建之后如果这个节点删除的话,那么后面的调用都会失败,即使这个节点重新被创建。回想文件元信息包含instance number,handle会判断instance number是否发生变化。
- 得到handle之后可能部分的call会调用权限检查,而在Open时候始终都会检查access control.
- 对于每一个调用都会带一些附加的参数:
- 异步模式的话提供callback参数
- 获得一些扩展或者是诊断信息
- client可以使用下面API来进行primary选举:
- 所有replicas打开同一个文件并且尝试lock
- primary成功返回而其他secondaries因为lock失败返回
- primary将自己的信息写入文件。可以通过event来回调通知到。
- 之后primary所有的操作都通过带上GetSequencer()来做操作。
- 而对于legacy system的话还是通过lock-delay方式来解决。
3.7. Caching
对于cache这件事情来说非常神奇,因为我们很少会去定义一个时序。假设AB两个节点,A在t1时刻发起操作F=1,B在t2时刻读取到F=1并且cache,C在t3时刻发起操作F=2的话, B在t4如果继续读取F的,不管是读取到1还是2通常我们都是可以接受的。因为对于这种分布式系统来说,是没有一个统一时间的。t4在绝对时间上>t3,但是如果考虑时间误差的话,我们也可以认为t4<=t3的。 所谓cache所约定的语义,应该是类似自己的cache存在一定的超时时间(这个时间久可以认为是各个机器的时间误差).超过这么多时间之后的话,可以从server上面重新读取数据。所以chubby提到了对待cache两种做法:
- invalidation cache
- cache lease expire
一种是强制cache失效,一种是按照cache lease自动超时.
- To reduce read traffic, Chubby clients cache file data and node meta-data (including file absence) in a consis-tent, write-through cache held in memory.(为了减少读压力做cache)
- The cache is maintained by a lease mechanism described below, and kept consistent by invalidations sent by the master, which keeps a list of what each client may be caching. The pro-tocol ensures that clients see either a consistent view of Chubby state, or an error.(cache使用下面描述的租期机制来完成的,master通过保存哪些client持有cache,如果需要失效的话那么通过master触发invalidation.这样从用户角度来说cache和实际内容是一致的)
- When file data or meta-data is to be changed, the mod-ification is blocked while the master sends invalidations for the data to every client that may have cached it;
- The modi-fication proceeds only after the server knows that each client has invalidated its cache, either because the client acknowledged the invalidation, or because the client al-lowed its cache lease to expire.(修改会阻塞住直到通知到了所有的client cache失效。或者是client恢复已经让其cache失效,或者是client让其cache lease过期)
- Only one round of invalidations is needed because the master treats the node as uncachable while cache inval-idations remain unacknowledged. This approach allows reads always to be processed without delay; this is useful because reads greatly outnumber writes.(对于在invalidation期间不会阻塞读操作,但是发起的节点是uncacheable的。这样可以非常好地优化读性能)
- An alternative would be to block calls that access the node during in-validation; this would make it less likely that over-eager clients will bombard the master with uncached accesses during invalidation, at the cost of occasional delays.(另外一种办法就是堵塞所有的读操作直到invalidation完成,这样可以放置一些激进的client在invalidation期间不断地访问未命中数据来压垮服务器,但是会带来一定的延迟).
- The caching protocol is simple: it invalidates cached data on a change, and never updates it. It would be just as simple to update rather than to invalidate, but update-only protocols can be arbitrarily inefficient; a client that
accessed a file might receive updates indefinitely, caus-ing an unbounded number of unnecessary updates.(cache protocol非常简单仅仅是使cache失效而不进行更新)
- Despite the overheads of providing strict consistency, we rejected weaker models because we felt that program-mers would find them harder to use. Similarly, mecha-nisms such as virtual synchrony that require clients to
exchange sequence numbers in all messages were con-sidered inappropriate in an environment with diverse pre-existing communication protocols. (cache主要还是从程序员使用方便角度出发的,所以拒绝使用weaker模型并且也没有暴露复杂使用方法) #todo: 何谓弱模型
- In addition to caching data and meta-data, Chubby clients cache open handles. This caching is re-stricted in minor ways so that it never affects the seman-tics observed by the client. handles on ephemeral files cannot be held open if the application has closed them; and handles that permit locking can be reused, but can-not be used concurrently by multiple application handles. This last restriction exists because the client may use Close() or Poison() for their side-effect of cancelling outstanding Acquire() calls to the master.(chubby也会对文件句柄缓存,但是缓存非常局限确保不会影响到client.比如对于临时文件上的handle在Close之后是不允许缓存的,
- Chubby's protocol permits clients to cache locks - that is, to hold locks longer than strictly necessary in the hope that they can be used again by the same client. An event informs a lock holder if another client has requested a
conflicting lock, allowing the holder to release the lock just when it is needed elsewhere.(chubby会将锁也进行缓存,期待原来这个锁后面会被同样的client锁使用。如果其他client尝试进行锁的话,那么就会有事件通知client.
3.8. Sessions and KeepAlives
- A Chubby session is a relationship between a Chubby cell and a Chubby client; it exists for some interval of time, and is maintained by periodic handshakes called KeepAlives.(cell和client之间的关系称为session.session通常会持续一段时间,session会通过KeepAlives这种周期性的握手协议来保持)
- Unless a Chubby client informs the master otherwise, the client's handles, locks, and cached data all remain valid provided its session remains valid. How-ever, the protocol for session maintenance may require the client to acknowledge a cache invalidation in order to maintain its session(除非chubby client通知master,或者是master会通过要求client ack来维持session,否则在session期间内的话client所持有的handle,lock以及cache data都是有效的)
- A client requests a new session on first contacting the master of a Chubby cell. It ends the session explicitly either when it terminates, or if the session has been idle (with no open handles and no calls for a minute).(初始时候会创建session.在结束时候会显示终止,或者是session长期保持idle没有任何操作通常持续在60s的话,sesision会终止)
- Each session has an associated lease - an interval of time extending into the future during which the master guarantees not to terminate the session unilaterally. The end of this interval is called the session lease timeout. The master is free to advance this timeout further into the future, but may not move it backwards in time.(每个session都会配备一个lease.master不能够单方将session timeout提前,但是可以通过协商将lease时间延长).下面三种情况会延长:
- on create of session.
- master fail-over.
- client respond to a KeepAlive RPC.(master得到RPC之后的话,block住直到client大约lease超时然后返回,通知lease的延长时间,一般设置为12s.如果master负载比较高的话那么可以设置长时间。client得到RPC返回之后的话,立刻回发起一个新的KeepAlive RPC.这里注意到RPC始终是block住在master上面的
- RPC除了用来延长client lease之外,可能还会比通常要更早返回。这种情况通常是出现在事件通知以及cache invalidation ack.使用这种piggyback的方式可以将连接发起方限制在一端透过防火墙。
- The client maintains a local lease timeout that is a con-servative approximation of the master's lease timeout.It differs from the master's lease timeout because the client must make conservative assumptions both of the time its
KeepAlive reply spent in flight, and the rate at which the master's clock is advancing; to maintain consistency, we require that the server's clock advance no faster than a known constant factor faster than the client's.(客户端也会维护一个本地的lease时间,这个时间可以认为是master分配lease timeout的一个大致保守估计因为需要考虑到KeepAlive传输时间以及master时间提前。为了维持一致性,服务器时间不能够比client时间提前超过某个常数比率).
- 在KeepAlive回来之前的话,如果client local lease timeout的话,client没有办法确认当前session是否已经终,那么client首先清空并且disable其cache,这个时候我们成为session in jeopardy.然后有一个grace period(默认45s).如果在grace period之间如果有KeepAlive通信的话,那么session重新开始进行cache,否则就认为这个session expired. 这样做的好处就是可以防止调用被block住。这里需要注意的就是在session in jeopardy的时候所有操作都会block住,因为这个时候很可能是因为master fail-over并且触发election.
- 对于上面出现的三个状态可以通过event通知到 #1.jeopardy event #2.safe event #3.expired event. 三个事件可以通知client是否应该重新查询状态,如果问题是瞬间的话那么就不用重启了。这种方式可以避免如果service outages的话,如果client没有判断状态全部重新发起连接的话,对于service造成的影响。
- If a client holds a handle H on a node and any oper-ation on H fails because the associated session has ex-pired, all subsequent operations on H (except Close() andPoison()) will fail in the same way. Clients can use this to guarantee that network and server outages cause only a suffix of a sequence of operations to be lost, rather than an arbitrary subsequence, thus allowing complex changes to be marked as committed with a final write.
3.9. Fail-overs
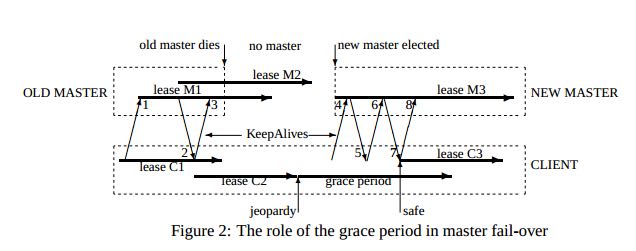
- When a master fails or otherwise loses mastership, it dis-cards its in-memory state about sessions, handles, and locks. The authoritative timer for session leases runs at the master, so until a new master is elected the session lease timer is stopped; this is legal because it is equiva-lent to extending the client’s leas.(如果master fail的话那么会丢弃内存内部的状态,其lease也会停止计时)
- If a master election occurs quickly, clients can contact the new master before their local (approximate) lease timers expire. If the elec-tion takes a long time, clients flush their caches and wait for the grace period while trying to find the new master. Thus the grace period allows sessions to be maintained across fail-overs that exceed the normal lease timeout.(如果master在grace period之前选举出来的话,那么client就可以在session断开之前连接上master.但是如果选举使用了很长时间的话,那么session就断开了,对于client来说的话就需要重新进行连接。因此引入grace period的意图就是为能够在master failover期间依然保持session).
- 论文给出了一个master出现failover的时序图。这里对于时序图最不能够理解的一点就是为什么需要引入master lease M3.这里的M3是一个conservative assumption.
- Once a client has contacted the new master, the client library and master co-operate to provide the illusion to the application that no failure has occurred. To achieve this, the new master must reconstruct a conservative ap-proximation of the in-memory state that the previous master had. It does this partly by reading data stored stably on disc (replicated via the normal database repli-cation protocol), partly by obtaining state from clients, and partly by conservative assumptions. The database records each session, held lock, and ephemeral file.(对于client如果在grace period之间连接上新的master的话,比如给client提供一个假象好像master没有出现failover,因此这个过程必须足够平滑并且进行一些状态的恢复。master会使用各种方式构造原来的in-memory状态,包括从磁盘读取(之前master保存的状态,包括session,lock以及临时文件),根据client状态(client之前是出于什么状态),以及conservative assumption.
- 对于一个新选举出来的master需要经过下面几个步骤:
- It first picks a new client epoch number, which clients are required to present on every call. The master rejects calls from clients using older epoch numbers, and provides the new epoch number. This ensures that the new master will not respond to a very old packet that was sent to a previous master, even one running on the same machine(首先挑选一个新epoch number.client每次和master交互都需要带上这个epoch number.因为原来client持有的epoch number和当前是不同的,因此会被拒绝掉而下次以正确的epoch number来进行发送。文中说可以过滤发给原来master的请求。这点对于TCP来说应该是不会存在这个问题的,因为重新更换了一次连接,但是对于UDP可能存在这个问题。另外引入这个原因我猜想是希望client library能够意识到master已经发生改变,需要做相应调整。)
- The new master may respond to master-location equests, but does not at first process incoming session-related operations.(可以相应master-location的相应但是不能够影响任何session相关的操作)
- It builds in-memory data structures for sessions and locks that are recorded in the database. Session leases are extended to the maximum that the pre-vious master may have been using.(从database中恢复各个session以及locks,然后为每个session分配最大的session lease.这个session lease就是conservative assumption.
- The master now lets clients perform KeepAlives, but no other session-related operations.(然后master允许接收KeepAlive请求但是依然不允许接收session相关请求)
- It emits a fail-over event to each session; this causes clients to flush their caches (because they may have missed invalidations), and to warn applications that other events may have been lost.(对于每个session都会触发一个fail over event.对于事件里面就是master fail over事件。然后client需要清空其cache因为这些client可能之前错过了cache invalidation.然后会通知app可能会造成一些事件丢失,需要用户重新对状态做scan)
- The master waits until each session acknowledges the fail-over event or lets its session expire.(master等待session返回invalidation ack或者是等待cache lease超时时间)
- The master allows all operations to proceed.
- If a client uses a handle created prior to the fail-over (determined from the value of a sequence number in the handle), the master recreates the in-memory representation of the handle and honours the call. If such a recreated handle is closed, the master records it in memory so that it cannot be recreated in this master epoch; this ensures that a delayed or dupli-cated network packet cannot accidentally recreate a closed handle. A faulty client can recreate a closed handle in a future epoch, but this is harmless given that the client is already faulty.
- After some interval (a minute, say), the master deletes ephemeral files that have no open file han-dles. Clients should refresh handles on ephemeral files during this interval after a fail-over. This mech-anism has the unfortunate effect that ephemeral files may not disappear promptly if the last client on such a file loses its session during a fail-over.(过一段时间间隔之后比如1分钟,master会检查所有的临时文件是否有client所持有,如果没有的话那么就会删除。这种情况发生在如果存在client创建一个临时文件,之后master挂掉,client没有在指定时间内将session维持上,导致会存在临时文件没有立刻删除)
- Readers will be unsurprised to learn that the fail-over code, which is exercised far less often than other parts of the system, has been a rich source of interesting bugs.(这个过程比较麻烦,而且也比较少发生所以bugs可能会非常多)
- 这里存在grace peirod好处就是可以在这段时间内可以让master进行选举,同时让client library自动进行这些重连操作,这些对于app来说的话都将影响减少到最少(会有一些事件通知发生).但是这个grace period不能够无限长。在这个grace period时间内所有的操作都是block住的,一旦grace peirod over之后对于这些操作都会返回错误。如果grace period无限长的话那么所有操作都会block住,虽然可能超过grace period之后master就会选举出来,这也算是设计上的折衷吧,所以grace period时间选定需要考虑master election以及master recovery的时间。论文里面提到默认是45s.
3.10. Database implementation
- The first version of Chubby used the replicated version of Berkeley DB as its database. Berkeley DB pro-vides B-trees that map byte-string keys to arbitrary byte-string values.(第一版使用BDB来做底层存储)
- sorts first by the number of components in a path name; this allows nodes to by keyed by their path name, while keeping sibling nodes adjacent in the sort order.(按照各个不同的component部分进行排序这样路径相似的节点就排在非常近的地方。其实这点对于读也是很有好处的,我们肯定是通常得到一个directory之后就希望访问其children).
- BDB使用分布式一致性协议来在各个server之间进行同步,在上面添加master lease还是相对比较简单的。
- 虽然BDB的Btree代码非常成熟,但是BDB的replicate code相对来说还不是很成熟,G工程师认为我风险还是比较大的。
- As a re-sult, we have written a simple database using write ahead logging and snapshotting similar to the design of Birrell et al. As before, the database log is distributed among the replicas using a distributed consensus proto-col. Chubby used few of the features of Berkeley DB, and so this rewrite allowed significant simplification of the system as a whole; for example, while we needed atomic operations, we did not need general transactions.(内部编写了一个简单的数据库使用writeahead log以及snapshot.同时使用分布式一致性协议来进行同步。相对于BDB来说的话,chubby裁剪了一些特性比如通用的事务处理只保留了一些需要的特性比如原子操作)
3.11. Backup
chubby cell定期会使用snapshot将数据库全部dump到GFS上面进行备份。对于GFS而言的话,building A下面的GFS只会使用building A下面的chubby cell. 这样building A下面的chubby cell会将snapshot dump到buidling B下面的GFS, building B chubby cell则dump到building A的GFS下面,交叉备份。 使用Backup一方面是为了灾备,另外一方是为了能够方便地添加新的replicas(Backups provide both disaster recovery and a means for initializing the database of a newly replaced replica without placing load on replicas that are in service.
3.12. Mirroring
- Chubby allows a collection of files to be mirrored from one cell to another.
- Mirroring is fast because the files are small and the event mechanism informs the mirroring code immediately if a file is added, deleted, or modified. Provided there are no network problems, changes are reflected in dozens of mirrors world-wide in well under a second.(因为文件相对较小而且镜像通常都是增量变化,因此如果网络没有问题的话,在广域网内同步到dozens个镜像通常在秒级上)
- Mirroring is used most commonly to copy config-uration files to various computing clusters distributed around the world.(镜像主要用来做配置文件的发送)
- /ls/global/master是一个特殊的cell,下面所有的文件都会同步到/ls/<cell>/slave下面.
- 对于global cell的部署是在world-wide范围部署five replicas.基本上在各个地方都可以访问到。
- 对于镜像的cell来说文件的ACL是自己控制而非global cell的ACL.
4. Mechanism for scaling
- we have seen 90,000 clients communicating directly with a Chubby master - far more than the number of machines involved. Because there is just one master per cell, and its machine is identical to those of the clients, the clients can overwhelm the master by a huge margin.(对于一个chubby cell可以处理9w个clients.并且因为master机器和client机器基本是相同的,对于master来说负担还是比较重的)
- Thus, the most effective scaling techniques reduce communication with the master by a significant factor.(最主要的开销主要还是集中在减少communication上面)
- Assuming the master has no serious performance bug, minor improve-ments in request processing at the master have little ef-fect. We use several approaches:(不考虑master一些严重的性能问题,下面是一些小改进):
- 部署上创建很多chubby cell,使用上的话选择一个nearyby cell.
- master将lease time从12s延长到60s左右,尤其是当master overload时候。因为从统计上看处理KeepAlive RPC是性能开销比较大的地方,而增加lease time可以减少这个KeepAlive RPC交互。
- client进行cache,包括data cache,meta cache,name node cache以及handle cache.
- We use protocol-conversion servers that translate the Chubby protocol into less-complex protocols such as DNS and others.(使用协议转换将chubby protocol转换成为不那么复杂的DNS协议)
- 为了能够将chubby scale further,设计了proxy以及parititioning方法来提高扩展性,虽然在实际系统中还没有使用。这个后面会讲到。
- We have no present need to consider scaling beyond a factor of five.我们不需要考虑扩展到超过5倍以上的问题:
- 一方面未来不会用一个server来为过多的client进行服务。
- 另一方面server和client使用的机器本身就是相似的。
- 因此对于scalability来说的话,考虑scale规模不用太大。
4.1. Proxy
- Chubby's protocol can be proxied (using the same pro-tocol on both sides) by trusted processes that pass re-quests from other clients to a Chubby cell.A proxy can reduce server load by handling both KeepAlive and read requests; it cannot reduce write traffic, which passes through the proxy's cache.(proxy在client和server之间做一个代理。通过处理KeepAlive以及读请求来减少服务端的压力。proxy不会减少写压力,所有写操作都是直接转发给server).
- But even with aggressive client caching, write traffic constitutes much less than one percent of Chubby's normal workload, so proxies allow a significant increase in the number of clients.(使用激进的缓存策略的话可以让写压力保持在1%一下,因此使用proxy可以在很大程度上面提高并发数)
- If a proxy handles N proxy clients, KeepAlive traffic is reduced by a factor of N proxy , which might be 10 thousand or more. A proxy cache can reduce read traffic by at most the mean amount of read-sharing - a factor of around 10. But because reads constitute under 10% of Chubby's load at present, the saving inKeepAlive traffic is by far the more important effect.(如果一个proxy可以handle住N个clients的话,那么KeepAliveRPC就可以减少N.通常N在1w左右。虽然proxy也可以通过读共享来减少读的代价,但是因为读操作仅仅占据了chubby负载的10%,因此对于proxy来说更多的节省来自于KeepAlive流量上面的节省。
- Proxies add an additional RPC to writes and first-time reads. One might expect proxies to make the cell tem-porarily unavailable at least twice as often as before, be-cause each proxied client depends on two machines that may fail: its proxy and the Chubby master.(proxy对于系统来说在write以及第一次读的时候有一次多余的RPC.并且对于系统来说,故障率是原来的两倍,因为需要考虑master以及proxy fail的情况)
- 另外就是对于proxy fail-over和之前讨论的fail-over方式是不同的。这个会在后面的Problems with fail-over部分提到.
4.2. Parititioning
- 通过对path component进行hash然后再paritition number进行取模来进行parititioning
- Partitioning is intended to enable large Chubby cells with little communication between the partitions. Al-though Chubby lacks hard links, directory modified-times, and cross-directory rename operations, a few op-erations still require cross-partition communication(partitioning设计上需要让不同区域之间尽可能低少地进行通信。虽然chubby没有支持硬链接,目录修改时间,以及跨目录文件移动等操作,但是依然存在一些操作需要区域通信)
- ACL check.F文件的ACL也是一个文件,虽然可以针对ACL进行缓存,但是包括Open以及Delete操作的话还是可能需要读取不同part.
- 目录删除。目录删除需要检查其子目录是否还有文件。
- Because each partition handles most calls independently of the others, we expect this communication to have only a modest impact on performance or availability.(大部分part之间的通信都是相互独立的,因为这种通信对于系统的可用性以及性能来说影响不会太大)
- Unless the number of partitions N is large, one would expect that each client would contact the majority of the partitions.(对于分区数来说除非足够大,否则对于每个client可能还是需要和大部分的part进行通信)
- Thus, partitioning reduces read and write traf-fic on any given partition by a factor of N but does not necessarily reduce KeepAlive traffic. (虽然partitioing可以将读写压力分摊到N个分区上面,但是却没有办法减少KeepAlive交互。每个client还是需要和大部分part进行通信,整个系统的KeepAlive通信却并没有减少)
- Should it be nec-essary for Chubby to handle more clients, our strategy involves a combination of proxies and partitioning.(因此如果需要处理更多的client的话,我们策略还是使用proxy以及partitioning结合的方式来处理)
5. Use, surprises and design errors
5.1. Use and behaviour
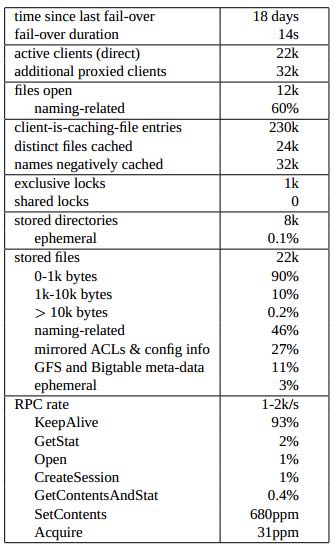
- The following table gives statistics taken as a snapshot of a Chubby cell; the RPC rate was a seen over a ten-minute period. The numbers are typical of cells in Google. Several things can be seen:(论文中给出了一个cell使用统计情况,RPC一段时间内观察的数据):
- 大部分文件都用来做name service.
- configuration, ACL, 元文件(类似于文件系统superblock)使用也比较多
- 无效cache影响比较大
- 平均每个文件大约被10个client进行缓存
- 持有exclusive lock非常少,shared lock使用也非常少。这点和用来做主从选举表现是一致的。
- RPC通信主要集中在KeepAlive上面,相对来说read/write以及acquire lock都比较少。
- If we assume (optimistically) that a cell is "up" if it has a master that is willing to serve, on a sam-ple of our cells we recorded 61 outages over a period of a few weeks, amounting to 700 cell-days of data in to-tal. We excluded outages due to maintenance that shutdown the data centre. All other causes are included:(在几周内统计大约700 cell-days共计61次服务挂掉。排除掉因为维护而关闭数据中心这种情况的话,其他原因包括下面这些):
- network congestion.
- network maintenance.
- overload.
- errors due to operators
- errors due to hardware
- errors due to software.
- 大部分fail时间在15s以内,其中52次在30s以内。对于30s以内服务停止的话对于大部分应用程序没有影响。剩余的9次超过30s包括
- network maintenance.(4)
- suspected network connectivity problems(2)
- software errors(2)
- ooverload(1)
- In a few dozen cell-years of operation, we have lost data on six occasions(出现过6次数据丢失)
- database software errors(4)
- operator error(2)
- 比较讽刺的是两次oprator error都是想避免databse software errors造成的。
- 因为chubby所有数据都是放在内存里面操作的,请求平均延迟都是在毫秒级别上面的。当系统过载时候的话会导致延迟急剧下降。系统过载通常是在活跃session超过90k.另外一种可能会出发系统过载情况就是,client如果同时发起million requests而对于library来说没有进行缓存或者是禁止缓存的话,那么server需要处理10k requests/s.
- 对于KeepAlive来说的可以通过增加lease timeout来减少其造成的压力。
- 如果存在write burst的话可以通过group commit减少每次request造成的effective work,但是相对来说这种情况比较少。
- 如果地域上面分布很近的话那么读取延迟通常在1ms左右,但是如果antipodes的话(两极,表示相隔很远的话)会在250ms左右。对于写来说的话考虑到log update会在5-10ms内完成(这个应该也是local cell上面),但是如果有client cache file但是却failed的话,那么需要等待cache lease expire,那么延迟在tens of seconds.
- Clients are fairly insensitive to latency variation pro-vided sessions are not dropped. At one point, we added artificial delays in Open()to curb abusive clients; developers noticed only when delays exceeded ten seconds and were applied repeatedly.(只要session没有断开的话,client对于延迟的变动其实并不敏感)
- We have found that the key to scaling Chubby is not server performance; re-ducing communication to the server can have far greater impact. No significant effort has been applied to tuning read/write server code paths; we checked that no egre-gious bugs were present, then focused on the scaling mechanisms that could be more effective. On the other hand, developers do notice if a performance bug affects the local Chubby cache, which a client may read thou-sands of times per second.
5.2. Java clients
大部分的google inf都是使用C++编写的,但是Java编写系统也逐渐增加。对于chubby来说server,library也都是使用C++编写的,并且协议本身以及client library都比较复杂。Java最通常调用其他语言的库就是使用JNI,但是在G里面大部分程序员不太喜欢,觉得太慢并且蹩脚。因此在G里面他们将很多库都转换成为了Java版本并且维护他们。chubby C++ library大约在7k左右并且协议非常精巧,因此转换成为Java代码就必须非常仔细,如果没有cache实现的话都会加重chubby server的负担。因为他们编写了一个protocol-conversion server更加简单的协议,但是依然保持chubby类似的client API.
5.3. Use as a name service
- Even though Chubby was designed as a lock service, we found that its most popular use was as a name server.(虽然chubby定位为lock service,但是非常流行的用法是用来作为name server)
- DNS是通过TTL来进行更新项目的,如果在TTL时间内没有刷新(#todo: DNS是否会主动去查找刷新呢?)的话那么DNS条目就会被自动丢弃。因此如果某个replicas挂掉但是想切换的话,那么TTL必须设置得足够小。在google里面设置60s.
- 对于jobs而言的话,各个节点都会相互进行通信,这样造成DNS查询是二次式的增长,加上需要DNS更新条目而超时时间很短,一个简单的jobs比如存在3k clients的话会造成DNS 150k lookup requests/s.对于large jobs的话这个问题更加突出。#note: 相对chubby来说的话,DNS缺少的东西就是client cache以及notification机制.
- 而是用chubby的话,client端可以进行缓存,并且配合notification机制的话,名字更新可以非常快。2-CPU 2.6GHz Xeon Chubby master不通过proxy就可以支撑90k clients.
- 如果client访问方式造成load spike的话,master依然是负担不了的。出现过3k process jobs同时启动发起9 million requests造成master压垮的情况。为了解决这个问题可以将多个查询合并进行批量查询。
- DNS cache相对于chubby cache来说的话,仅仅需要timely notification而不需要full consistency.因此可以通过制作单独的protocol-conversion server连接chubby来完成DNS的功能,减轻chubby load.Had we foreseen the use of Chubby as a name service, we might have chosen to implement full proxies sooner than we did in order to avoid the need for this simple, but nevertheless additional server.One further protocol-conversion server exists: the Chubby DNS server.
5.4. Problem with fail-over
- The original design for master fail-over requires the master to write new sessions to the database as they are created.(原始设计里面对于创建所有的session都是立刻保存到db的)
- In the Berkeley DB version of the lock server, the overhead of creating sessions became a prob-lem when many processes were started at once.(使用BDB来作为db的时候入如果大量进程同时启动的话会创建非常多的回话,对于db会有相当大的压力)
- To avoid overload, the server was modified to store a session in the database not when it was first created, but instead when it attempted its first modification, lock acquisition, or open of an ephemeral file. In addition, active sessions were recorded in the database with some probability on each KeepAlive. Thus, the writes for read-only sessions were spread out in time.(为了减少压力,server并不在创建session的时候就保存到db,而是在session第一次发起写操作的时候保存到db这样就可以平压力,而对于那些只读的session来说会将写的时刻尽可能地散步开来)
- Though it was necessary to avoid overload, this opti-mization has the undesirable effect that young read-only sessions may not be recorded in the database, and so may be discarded if a fail-over occurs.(尽管这样可以减少压力,但是会存在一些read only session的丢失)。Although such ses-sions hold no locks, this is unsafe; if all the recorded sessions were to check in with the new master before the leases of discarded sessions expired, the discarded ses-sions could then read stale data for a while. This is rare in practice; in a large system it is almost certain that some session will fail to check in, and thus force the new mas-ter to await the maximum lease time anyway.
- Neverthe-less, we have modified the fail-over design both to avoid this effect, and to avoid a complication that the current scheme introduces to proxies.(因此我们修改了fail-over的设计方案,一方面避免这个问题,另外一方面避免当前这种方案对于proxy来说引入的复杂性)
- Under the new design, we avoid recording sessions in the database at all, and instead recreate them in the same way that the master currently recreates handles. A new master must now wait a full worst-case lease time-out before allowing operations to proceed, since it can-not know whether all sessions have checked in. Again, this has little effect in practice because it is likely that not all sessions will check in.(在新的设计方案里面的话,session都是不保存到db的,而是通过client向server发送RPC来重建handles.在新设计方案下的话,master就必须等待足够client lease timeout以便所有的session都已经check in了。这样可以重建所有的会话。这点非常好理解,对于那些超过lease timeout的session来说的话,超过grace period就会认为和master断开了)
- Once sessions can be recreated without on-disc state, proxy servers can manage sessions that the master is not aware of. An extra operation available only to proxies allows them to change the session that locks are asso-ciated with. This permits one proxy to take over a client from another when a proxy fails. The only further change needed at the master is a guarantee not to relinquish locks or ephemeral file handles associated with proxy sessions until a new proxy has had a chance to claim them.(一旦session不需要从disc上面重建状态的话,那么proxy server可以独自管理回话而不需要让master意识到。必须允许将会话从一个proxy切换到另外一个proxy来,这样如果proxy A fails的话,那么proxy B就会可以直接接管proxy A上所有的会话。对于master唯一需要修改的地方就是,如果原来proxy A fails掉的话,那些临时文件以及锁都不能够回收,直到新的proxy显示地触发这些操作)
将session这类信息不放在磁盘上面,而全部由client自己维护。新的master上来之后所有的client都会和这个master重新recreate handles.master通过超时机制,确保所有的session要不就重新建立(和master成功连上),要不就必然终止(因为超过grace period而client自动终止).感觉整个chubby方案强烈依赖于这种时间窗口机制。
5.5. Abusive clients
- Google's project teams are free to set up their own Chubby cells, but doing so adds to their maintenance bur-den, and consumes additional hardware resources.(允许搭建自己的chubby cell,但是需要自己维护并且耗费额外的硬件资源)
- Many services therefore use shared Chubby cells, which makes it important to isolate clients from the misbehaviour of others.(但是大部分的chubby cell都还是提供公用服务的,因此有必要提供一些隔离措施)
- Chubby is intended to operate within a sin-gle company, and so malicious denial-of-service attacks against it are rare. However, mistakes, misunderstand-ings, and the differing expectations of our developers lead to effects that are similar to attacks.(因为主要在公司内部使用所有没有必要考虑DOS这样的攻击,但是因为一些错误使用以及对于一些理解问题造成开发者编写的代码,会对于service造成类似于攻击效应)
- 现在对于这种问题的解决办法还是通过人工方式来解决。从设计方面进行评审,但是对于开发者很难估计增长速度以及未来使用情况。在评审时候最主要考虑的方面就是,对于chubby load带来影响是否是线性的,任何线性影响都可以通过调整参数来缓解对于chubby带来的压力,但是这种初期评审还远远不够。另外一个问题就是在文档中缺少一些性能建议,这样另外一些项目在直接服用某个项目之后可能会有灾难性的后果。
- Below we list some problem cases we encountered:
- Lack of aggressive caching. 缺少激进cache机制
- Lack of quotas. 缺少配额机制
- Publish/subscribe. 应用尝试使用chubby的event机制比如Zephyr.但是由于chubby需要对cache采用invalidation而不是update来保证一致性,导致pub/sub这种方案非常低效。
6. Lessons learned
- Here we list lessons, and miscellaneous design changes we might make if we have the opportunity:
- Developers rarely consider availability.
- 开发者建立了这么一个系统,每次当master变化的话就会让hundreds machines执行长达10 min恢复过称。事实上这样就让一台机器fail影响了上百台机器。We would prefer developers to plan for short Chubby out-ages, so that such an event has little or no affect on their applications.(我们更希望用户针对这种chubby outages事件不要触发大规模的影响)
- 开发者没有正确认识a service being up, and that service being available to their applications之间的区别。对于service being up来说的话,对于five replicas来说的话很少情况会有超过2台地理位置不同的机器down的情况,只要没有出现这种情况那么服务就依然是available的,这个可用性是对cell本身来说的。但是对于client所观察到的可用性远远低于cell本身的可用性,因为一方面cell如果不可用的话会导致client观察到,另外一方面对于单个client很可能会因为网络原因而与cell断开虽然整个cell依然是available的(相对client来说的话,cell之间partitioned概率相对更低)。
- 开发者对于API认识错误。本来master faile over事件是通知开发者可能存在一些event丢失或者是数据变化没有通知到,但是有开发者直接将自己的service terminate.
- 对于上面三个问题,现在解决方式包括 a.详细设计上评审不要让他们的availibility过多依赖于chubby可用性 b.开发一些库来屏蔽一些细节做一些高层工作 c.对于chubby outages情况进行分析,一方面可以改进chubby本身,另外一方面可以减少其他app对于chubby outages的敏感性。
- Fine-grained locking could be ignored. 事实上大部分细粒度的锁都需要牵扯到频繁的通信,而正是这些通信造成了性能问题。为了优化他们的程序必须移除一些频繁的通信,之后情况就非常合适使用粗粒度的锁了。因此现在google也没有在chubby基础上开发细粒度的锁服务。
- Poor API choices have unexpected affects.
- RPC use affects transport protocols. 当网络出现拥塞KeepAlive RPC的时候TCP会出现指数退避来缓解拥塞,但是这样就会出现client lease timeout和server lease timeout不一致的情况,这样会导致client出现大量的session丢失。We were forced to send KeepAlive RPCs via UDP rather than TCP; UDP has no congestion avoidance mechanisms, so we would prefer to use UDP only when high-level time-bounds must be met. (因此我们更倾向使用UDP而不是TCP来做RPC,因为UDP没有拥塞控制机制)
- Developers rarely consider availability.
7. Comparison with related work
- Chubby differs from a distributed file system such as Echo or AFS in its performance and storage aspira-tions: Clients do not read, write, or store large amounts of data, and they do not expect high throughput or even low-latency unless the data is cached. They do ex-pect consistency, availability, and reliability, but these attributes are easier to achieve when performance is less important.(chubby和文件系统设计差别主要在性能以及存储大小上面。chubby并没有提供向文件系统那样提供读写存储大容量的数据,强调高吞吐和低延迟,虽然chubby在使用cache时候可以达到低延迟。相反chubby主要注重一致性,可用性以及可靠性,而在牺牲性能情况下的话比较容易做到)
- Because Chubby's database is small, we are able to store many copies of it on-line (typically five replicas and a few backups). We take full backups mul-tiple times per day, and via checksums of the database state, we compare replicas with one another every few hours.(5 replicas并且每天备份多次,并且每隔几个小时通过checksum比较一下数据库之间的状态)
- The weakening of the normal file system perfor-mance and storage requirements allows us to serve tens of thousands of clients from a single Chubby master.(正是因为牺牲了文件系统性能以及存储方面的要求,使得单台chubby master可以服务上万clients)
- Chubby was intended for a diverse audience and appli-cation mix; its users range from experts who create new distributed systems, to novices who write administration scripts. For our environment, a large-scale shared ser-vice with a familiar API seemed attractive.(chubby主要是为了不同层次用户以及应用程序混合使用的,可以为构建新的分布式系统专家服务,也可以为那些编写管理脚本的新手服务。在chubby看来,大规模共享的服务提供一个比较熟悉的API似乎更加有吸引力)
8. Summary
- Chubby is a distributed lock service intended for coarse-grained synchronization of activities within Google's distributed systems;
- it has found wider use as a name service and repository for configuration information.(主要用在了名字服务以及配置信息上)
- distributed consensus among a few replicas for fault tolerance, consistent client-side caching to re-duce server load while retaining simple semantics, timely notification of updates, and a familiar file system inter-face.
- We use caching, protocol-conversion servers, and simple load adaptation to allow it scale to tens of thou-sands of client processes per Chubby instance. We ex-pect to scale it further via proxies and partitioning.
- Chubby has become Google's primary internal name service; it is a common rendezvous mechanism for sys-tems such as MapReduce ; the storage systems GFS and Bigtable use Chubby to elect a primary from redun-dant replicas; and it is a standard repository for files that require high availability, such as access control lists.(在MapReduce上面作为汇集点机制使用,在GFS以及BigTable上面的话用来作为选主机制)