ZooKeeper: Wait-free coordination for Internet-scale systems
Table of Contents
http://research.yahoo.com/pub/3280 @ 2010
https://pdos.csail.mit.edu/6.824/notes/l-zookeeper.txt
https://pdos.csail.mit.edu/6.824/papers/zookeeper-faq.txt
这篇文章主要介绍了Zookeeper系统提供的原语(primitives), 使用这些原语可以帮助构建分布式系统,底层的一致性协议是zab.
我印象比较深刻的是:
- 所有操作都是wait-free/asynchronous的,可以达到很高的性能
- 写操作保证linearizaibility, 读操作则是可选(+sync)
- 从一个client上面发起的操作是FIFO的
- 提供了watch机制来减少polling. watch是基于session的,可以在机器之间迁移
1. Abstract
It incorporates elements from group messaging, shared registers, and distributed lock services in a replicated, centralized service. The interface exposed by Zoo-Keeper has the wait-free aspects of shared registers with an event-driven mechanism similar to cache invalidations of distributed file systems to provide a simple, yet powerful coordination service.
2. Introduction
In particular, we have found that guaranteeing both FIFO client ordering of all operations and linearizable writes enables an efficient implementation of the service and it is sufficient to implement coordination primitives of interest to our applications.
We were able to implement ZooKeeper using a simple pipelined architecture that allows us to have hundreds or thousands of requests outstanding while still achieving low latency. Such a pipeline naturally enables the execution of operations from a single client in FIFO order. Guaranteeing FIFO client order enables clients to submit operations asynchronously. With asynchronous operations, a client is able to have multiple outstanding operations at a time.
To guarantee that update operations satisfy linearizability, we implement a leader-based atomic broadcast protocol, called Zab. A typical workload of a ZooKeeper application, however, is dominated by read operations and it becomes desirable to scale read throughput. In ZooKeeper, servers process read operations locally, and we do not use Zab to totally order them.
在管理缓存上,Chubby和ZK使用了不同的方法。ZK使用watching机制来通知client数据可能发生变化,client可以选择性地读取,但是并不阻碍update. 而Chubby的update则要求所有的client都刷新缓存,否则update没有办法进行。这样Chubby容易受到slow/faulty的client影响,保证能够完成的机制就是lease,只能等待
Chubby manages the client cache directly. It blocks updates to invalidate the caches of all clients caching the data being changed. Under this design, if any of these clients is slow or faulty, the update is delayed. Chubby uses leases to prevent a faulty client from blocking the system indefinitely. Leases, however, only bound the impact of slow or faulty clients, whereas ZooKeeper watches avoid the problem altogether.
3. The ZooKeeper service
znode
zookeeper上的数据组织成为一个类似于文件系统的树(但是实际上不区分目录和文件的). 节点称为znode, 节点上有数据, 所有节点下面都可以挂子节点. znode分为两种类型: 1) regular 2) ephemeral. 如果创建ephemeral节点的client session结束的话, 那么这个节点会自动删除. 在创建znode时候还可以指定一个sequential标记, 使用这个标记创建znode时候会在znode name之后添加一个id. 这个id是在此节点的父节点下面自增的.
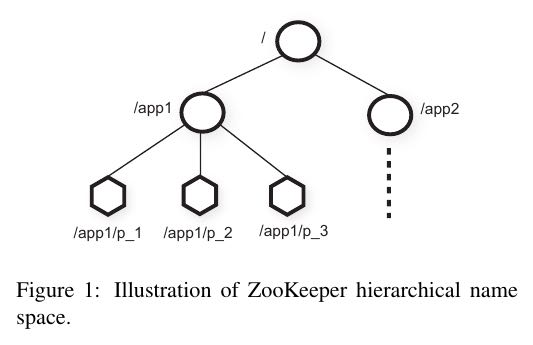
client在读取znode的时候可以设置watch标记. 那么如果这个znode发生变化的话(znode event), client会被通知到. 通知不会携带任何数据, 并且只会触发一次. 如果session关闭的话那么watch会被自动删除. zookeeper也提供了session event用来通知client和zookeeper连接失效. 结合后面来看"session连接失效"应该有两个意思: 1) session失效那么需要重新连接(比如长时间没有心跳) 2) 和原来server断开切换到另外一个server. 对于情况1) client需要重新发起连接. 情况2) client可以自动处理. 但是无论如何所有watch标记都会失效.
session
A client connects to ZooKeeper and initiates a session. Sessions have an associated timeout. Zoo-Keeper considers a client faulty if it does not receive any-thing from its session for more than that timeout. A ses-sion ends when clients explicitly close a session handle or ZooKeeper detects that a clients is faulty. Within a ses-sion, a client observes a succession of state changes that reflect the execution of its operations. Sessions enable client to move transparently from one server to another within a ZooKeeper ensemble, and hence persist across ZooKeeper servers.
session通过心跳来维持,如果在超时时间内没有收到client响应的话就认为client出现错误。如果zk认为client出错或者是client主动关闭, 那么session就此结束。但是如果是zookeeper本身节点出现故障的话, session可以自动完成切换.
client API
All methods have both a synchronous and an asyn-chronous version available through the API.
- create(path, data, flags)
- delete(path, version) # only when version matches. set version = -1 to match any.
- exists(path, watch)
- getData(path, watch)
- setData(path, data, version)
- getChildren(path, watch)
- sync(path) # flush, 可以认为一个no-op的写操作。
guarantees
ZooKeeper has two basic ordering guarantees:
- Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect prece-dence; # writes是全局有序的.
- FIFO client order: all requests from a given client are executed in the order that they were sent by the client. # client操作顺序是FIFO.
notification order: if a client is watching for a change, the client will see the notification event before it sees the new state of the system after the change is made. # client关注节点A, 而另外一个节点先修改A然后修改B. 那么client是先被通知A然后才能读取到B的最新内容.
Examples of primitives
In this section, we show how to use the ZooKeeper API to implement more powerful primitives. The ZooKeeper service knows nothing about these more powerful primitives since they are entirely implemented at the client using the ZooKeeper client API. Some common primitives such as group membership and configuration management are also wait-free. For others, such as rendezvous, clients need to wait for an event. Even though ZooKeeper is wait-free, we can implement efficient blocking primitives with ZooKeeper. ZooKeeper’s ordering guarantees allow efficient reasoning about system state, and watches allow for efficient waiting.
- Configuration Management 配置管理,这个就是要确保原子性和读写顺序
- Rendezvous 等待某个znode的创建和删除
- Group Membership 树结构的好处就体现出来了,我们可以watch parent节点
- Simple Locks. 两个问题herd effect以及read/write lock. 都可以通过 SEQUENTIAL 这个特性来解决
- Double Barrier. 我理解就是Java里面的CountDownLatch.
4. Zookeeper Applications
5. ZooKeeper Implementation
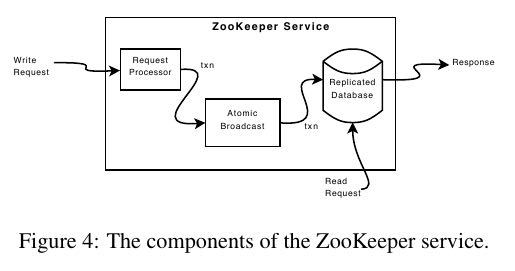
- 写操作(trx)经过atomic_broadcast广播到所有节点并且定序, 然后作用在replicated_database上. 读操作直接读取本地replicated_database.
- replicated_database是in memory的数据库系统, 所有trx在作用到database之前都会被记录到WAL.
- trx满足幂等性(idempotent). 满足幂等性不仅仅是因为通信中存在重发的问题,在recovery阶段也会用到这个特性。
- replicated_database定期会做snapshot. 但是这种snapshot并不精确, 所以成为fuzzy snapshots, 因为这个snapshot生成并不是一个atomic操作. 这里好理解为什么在recovery阶段会有重复trx发送或者是作用.
- server只会管理连接上自己的clients的notification. 并且执行read/write操作都是单线程的,这样可以确保收到notification的顺序。 When a server processes a write request, it also sends out and clears notifications relative to any watch that corre-sponds to that update. Servers process writes in order and do not process other writes or reads concurrently. This ensures strict succession of notifications. Note that servers handle notifications locally. Only the server that a client is connected to tracks and triggers notifications for that client.
- client每次和zookeeper交互返回都会得到一个zxid反应当前client所获取的数据. 如果在连接时候server发现自己的zxid比client zxid小的话那么就会拒绝连接, 直到这个server追上或者是client连接其他server.
- 为了保持session, 假设session timeout是x ms的话, 那么在session idle之后的x/3ms会发送一个心跳, 如果在2x/3 ms没有收到这个心跳的返回的话, 那么就会尝试切换到另外一个server发送心跳.
During normal operation Zab does deliver all messages in order and exactly once, but since Zab does notpersistently record the id of every message delivered, Zab may redeliver a message during recovery. Because we use idempotent transactions, multiple delivery is acceptable as long as they are delivered in order. In fact, ZooKeeper requires Zab to redeliver at least all messages that were delivered after the start of the last snapshot.
We call Zoo-Keeper snapshots fuzzy snapshots since we do not lock the ZooKeeper state to take the snapshot; instead, we do a depth first scan of the tree atomically reading each znode’s data and meta-data and writing them to disk. Since the resulting fuzzy snapshot may have applied some subset of the state changes delivered during the generation of the snapshot, the result may not correspond to the state of ZooKeeper at any point in time. However, since state changes are idempotent, we can apply them twice as long as we apply the state changes in order.
ZooKeeper servers process requests from clients in FIFO order. Responses include the zxid that the response is relative to. Even heartbeat messages during intervals of no activity include the last zxid seen by the server that the client is connected to. If the client connects to a new server, that new server ensures that its view of the Zoo- Keeper data is at least as recent as the view of the client by checking the last zxid of the client against its last zxid. If the client has a more recent view than the server, the server does not reestablish the session with the client until the server has caught up. The client is guaranteed to be able to find another server that has a recent view of the system since the client only sees changes that have been replicated to a majority of the ZooKeeper servers. This behavior is important to guarantee durability.
In our implementation, we do not need to atomically broadcast sync as we use a leader-based algorithm, and we simply place the sync operation at the end of the queue of requests between the leader and the server executing the call to sync. In order for this to work, the follower must be sure that the leader is still the leader. If there are pending transactions that commit, then the server does not suspect the leader. If the pending queue is empty, the leader needs to issue a null transaction to commit and orders the sync after that transaction. This has the nice property that when the leader is under load, no extra broadcast traffic is generated. In our implementation, timeouts are set such that leaders realize they are not leaders before followers abandon them, so we do not issue the null transaction.
6. Evaluation
7. Related work
However, ZooKeeper is not a lock service. It can be used by clients to implement locks, but there are no lock operations in its API. Unlike Chubby, ZooKeeper allows clients to connect to any ZooKeeper server, not just the leader. ZooKeeper clients can use their local replicas to serve data and manage watches since its consistency model is much more relaxed than Chubby. This enables ZooKeeper to provide higher performance than Chubby, allowing applications to make more extensive use of ZooKeeper.
可以在不修改代码的情况下适应fully byzantine的环境,但是不知道性能如何。如果从生产环境上面来看,这种适应fully byzantine的处理并不能避免线上事故。
ZooKeeper does not assume that servers can be Byzantine, but we do employ mechanisms such as checksums and sanity checks to catch non-malicious Byzantine faults. Clement et al. discuss an approach to make ZooKeeper fully Byzantine fault-tolerant without modifying the current server code base. To date, we have not observed faults in production that would have been prevented using a fully Byzantine fault-tolerant protocol.
8. Conclusions
9. Q&A
关于zxid
Linearizable writes
clients send writes to the leader
the leader chooses an order, numbered by "zxid"
sends to replicas, which all execute in zxid order
A few consequences:
Leader must preserve client write order across leader failure.
Replicas must enforce "a client's reads never go backwards in zxid order"
despite replica failure.
Client must track highest zxid it has read
to help ensure next read doesn't go backwards
even if sent to a different replica
关于API设计
ZooKeeper API well tuned to synchronization:
+ exclusive file creation; exactly one concurrent create returns success
+ getData()/setData(x, version) supports mini-transactions
+ sessions automate actions when clients fail (e.g. release lock on failure)
+ sequential files create order among multiple clients
+ watches -- avoid polling
ZooKeeper is a successful design.
see ZooKeeper's Wikipedia page for a list of projects that use it
Rarely eliminates all the complexity from distribution.
e.g. GFS master still needs to replicate file meta-data.
e.g. GFS primary has its own plan for replicating chunks.
But does bite off a bunch of common cases:
Master election.
Persistent master state (if state is small).
Who is the current master? (name service).
Worker registration.
Work queues.
关于性能似乎也不错
Is the resulting performance good?
Table 1
High read throughput -- and goes up with number of servers!
Lower write throughput -- and goes down with number of servers!
21,000 writes/second is pretty good!
Maybe limited by time to persist log to hard drives.
But still MUCH higher than 10 milliseconds per disk write -- batching.
Q: How does Zookeeper's performance compare to other systems
such as Paxos?
A: It has impressive performance (in particular throughput); Zookeeper
would beat the pants of your implementation of Raft. 3 zookeeper
servers process 21,000 writes per second. Your raft with 3 servers
commits on the order of tens of operations per second (assuming a
magnetic disk for storage) and maybe hundreds per second with
SSDs.