Procella: Unifying serving and analytical data at YouTube
Procella的需要包括下面这几个(我觉得可以说是对一个数据分析系统几乎所有的需求了)
- Reporting and Dashboarding. 报表,模式比较固定,数据量(100B rows per day)和请求量(10K QPS, 10~100ms)都比较大,但是velocity要求不高。我觉得这部分Google Mesa + BIgTable可以搞定。
- Embedded statstics. 统计数字,模式比较固定,数据量不大,请求量比较大(1M QPS, 10-100ms), 但是velocity要求比较高,需要得到实时的结果。论文里面说这个部分Google Vitess(MySQL集群)可以搞定。
- Monitoring. 监控,和报表很像,数据量可以通过聚合和采样来减少,请求量因为都是内部的所以也不多,当做一个时序数据库来使用。论文里面说这个部分Google Monarch可以搞定。
- Ad-hoc analysis. 人工查询,数据量比较大,请求量不大,估计对于velocity的要求也不高,但是里面复杂查询比较多,通常都是离线任务。这个部分Google Dremel可以搞定。
每个需求都有专门的系统可以搞定,问题是这些系统之间相互倒腾数据比较麻烦,每个系统的提供的查询接口也不同,最后数据一致性也是个头疼的问题。Procella想通过一个系统解决所有问题,难度还是比较大的,所以感觉这篇文章也挺值得看看,如何同时解决在线和离线数据统计分析的。
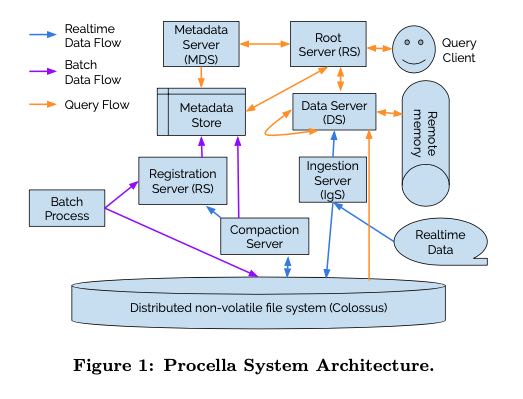
下面是Procella的结构图,对外接口是扩展的SQL并且增加了许多UDF,采用的也是计算(Borg)和存储(Colossus)分离的结构。
- Data Server 从Colossus上拿到Data File进行计算分析,支持两种Format(Artus and Capacitor), 其中Artus更加适合数据分析。Data Server这层也会进行各种cache.
- Metadata Store 存储各种metadata数据,放在BigTable/Spanner上面。
- metadata包括schema, table to files, stats(用于查询优化),seconary structure, aggregation strategy, aging out strategy等信息。
- 我理解这里的secondary structure是指某些在创建Data Files并没有直接存储在其中的结构,比如Bloom Filter. 这些文件当被DS读取出来之后,DS可以构建这些secondary structure被存储到metadata store中(通过RS?)
- Registration Server(RgS) 负责将table schema(DDL), table to files等信息写到Metadata Store上面
- 可以看到Batch Process(将Data Files批量放到Colossus上)以及Compactiion Process都会改变table to files信息,所以会和RgS进行通信
- 同时RS也会将抽取secondary structure存储到metadata store中。
- Ingestion Server(IgS) 则负责接收实时数据,将数据以WAL的形式写入到Colossus上,同时写到Remote Memory
- 不知道Memory里面是不是某种in-memory table. 我的理解是如果是解决embedded stats的话完全可以使用类似key-value memory store.
- WAL之后会被compaction和base进行合并,此时实时数据才真正进入离线部分。
整个查询流程大致是:1. RS解析SQL生成执行计划 2. 去MDS上查询文件metadata信息进行pruning 3. 将执行计划交给DS执行。执行计划基本是树状结构,发送到DS之后,DS可能还要发送到其他DS做底层的工作,这样不断地fanout出去直到叶子节点。服务器之间使用stubby rpc进行通信,使用RDMA进行shuffle(好像RDMA可以减少数据从内核到用户的拷贝)
因为计算存储分离,所以Caching少不了,而且cache的东西还不少包括:1. colossus metadata caching(chunk -> chunk server) 2. data file header 3. data file 4. metadata caching 另外就是affinity scheduling 确保涉及到某个data file的操作都由一个data server来进行处理。我看他们给的数据比较有意思:虽然只有2%的数据可以fit到内存,但是99%+ file handle cache hit(不知道这个是什么东西)和90%的data cache hit. 如果真的是90%的data cache hit的话,也就是说实际情况通常只需要处理很少的部分数据,大部分数据基本都不会touch的。
搞了个Artus的列式存储结构(同样支持嵌套和重复),里面实现了许多存储和计算优化,相比BigQuery用的Capacitor在大小以及性能上都好不少。Query Engine是个叫做superluminal的东西,没有使用JIT,大量使用了C++模板技术,在cache locality以及vectorization上做了许多优化。MDS上也做了类似affinity scheduling的东西,确保某个metadata都能落在一个MDS上提高缓存命中率,为了有效利用内存,metadata在内存中使用许多中方法做了压缩(prefix, delta, RLE, and other encodings).
分布式Join有下面几种方式:(我估计都是些经典的办法)
- broadcast. 把小表数据发送给大表机器上
- co-partitioned 如果join key在两个表上都是partitioned, 那么就按照partition进行分别作join. [从后面看也是lookup策略]
- shuffle. 按照join key进行shuffle
- pipelined. 同样是小表和大表join, 但是小表运算复杂,所以小表通过pipelined的方式broadcast到大表机器上
- remote lookup. 某个表在join key上做了partition, 然后以query方式查询另外一个表
Virtual Tables就是物化视图,并且这个视图其实是已经做了aggregation的,否则计算类似 SUM(views) where videoId = x 就要挂了。我估计这个Virtual Tables需要用户使用DDL去手动创建,在fact tables上指定那些columns是dimensions, 那些columns是values以及如何进行aggregation. 有了Virtual Tables之后,在进行某些查询的时候Query Engine就可以使用Virtual Tables而不是傻傻地使用fact tables. 合理地选择Virtual Tables可以 1. 更好的pruning (index-aware aggregation selection) 2. 更好的join(join-awareness) .
Query Plan优化上有两件事可以做,一个是join的顺序优化,一个是join/sort的实现优化。顺序优化这件事情Procella还在做,据说是使用动态规划的方法来寻找最优解。Join/Sort实现优化上思路就是使用统计数据(数据分布)信息选择好partition number以及partition point,而传统的思路是使用cost-based optimization(在RDBMS SQL优化的时候常听说)。
在实现Serving Embedded Stats功能上做了下面优化。文中举的是这个例子 SELECT SUM(views) FROM Table WHERE video id = N 这样的查询,强调的是可以迅速地处理新来的数据。我的理解是,一部分这个数据是来自架构图中Remote Memory【比如最近1个小时的views变化】,一个数据是来自Colossus上Bacth Process导入的数据【截止到上个小时的views变化】。为了能快速处理Batch Process导入的最新数据,做了下面几点优化:
- 被RS新注册的Data Files会被通知到负责的DS进行caching(所以RS也需要了解到affinity scheduling的策略,或者通知RS转发到DS好像更好),相当于prefetch data了而不用等待请求来了在从colossus上读取。
- MDS module被嵌入到了RS里面,RS可以直接从metadata store里面拿到数据并且缓存,节省了和MD的RPC交互。我看文章里面应该是针对不同场景使用不用的cluster, 所以serving embedded stats估计是单独的集群,只有在这个集群上MDS module是被嵌入到RS的。Metadata的变化也会被异步地更新到RS上,pull-push两种方法确保最新的metadata可用。
- Query plan cache, disable adaptive joins & shuffle ops, mininize tail latencies etc.