Serving Large-scale Batch Computed Data with Project Voldemort
Table of Contents
- http://www.project-voldemort.com/voldemort/ (Homepage)
- http://static.usenix.org/events/fast/tech/full_papers/Sumbaly.pdf @ 2012
1. Abstract
- Current serving systems lack the ability to bulk load massive immutable data sets without affecting serving performance. The performance degradation is largely due to index creation and modification as CPU and memory resources are shared with request serving.(导入大规模数据主要问题还是这些数据集合的索引创建以及修改会影响到在线服务性能)
- We have ex-tended Project Voldemort, a general-purpose distributed storage and serving system inspired by Amazon’s Dy-namo, to support bulk loading terabytes of read-only data. This extension constructs the index offline, by leveraging the fault tolerance and parallelism of Hadoop. (类似Dynamo的只读分布式数据库系统,通过Hadoop在离线完成index通过)
- Compared to MySQL, our compact storage format and data deploy-ment pipeline scales to twice the request throughput while maintaining sub 5 ms median latency.(和MySQL相比,吞吐量翻倍而访问延迟的中位数保持在5ms一下)
2. Introduction
- Our system leverages a Hadoop elastic batch computing infrastructure to build its index and data files, thereby supporting high throughput for batch refreshes. A custom read-only storage engine plugs into Voldemort’s extensible storage layer. The Voldemort infrastructure then provides excellent live serving perfor-mance for this batch output—even during data refreshes. Our system supports quick rollback, where data can be restored to a clean copy, minimizing the time in error if an algorithm should go awry. This helps support fast, iterative development necessary for new feature improve-ments. The storage data layout also provides the ability to grow horizontally by rebalancing existing data to new nodes without downtime. Our system supports twice the request throughput ver-sus MySQL while serving read requests with a median latency of less than 5 ms.(Hadoop来构建索引和数据文件,只读存储引擎,快速回滚数据,在线扩充存储节点)
- At LinkedIn, this system has been running for over 2 years, with one of our largest clusters loading more than 4 terabytes of new data to the site every day.(运行时间超过2年,每天载入4TB数据)
- The key contributions of this work are:
- A scalable offline index construction, based on MapReduce, which produces partitioned data for online consumption
- Complete data cycle to refresh terabytes of data with minimum effect on existing serving latency
- Custom storage format for static data, which lever-ages the operating system’s page cache for cache management(利用os page cache提升只读存储引擎访问效率)
3. Related Work
- MySQL is a common serving system used in various companies. The two most commonly used MySQL stor-age engines, MyISAM and InnoDB, provide bulk load-ing capabilities into a live system with the LOAD DATA INFILE statement.
- MyISAM provides a compact on-disk structure and the ability to delay recreation of the index after the load.(MyISAM允许数据导入之后延迟创建索引,并且存储占用空间小)
- However, these benefits come at the expense of requiring considerable memory to maintain a special tree-like cache during bulk loading.(但是在载入数据的时候需要消耗大量内存)
- Additionally, the MyISAM storage engine locks the complete table for the duration of the load, resulting in queued requests. (并且在载入数据的时候会锁表不允许其他操作)
- In comparison, InnoDB supports row-level locking, but its on-disk structure requires considerable disk space and its bulk loading is orders of magnitude slower than My-ISAM.(InnoDB使用的是行级别锁表,可能消耗内存不会太大,但是占用磁盘空间以及载入速度都比MyISAM慢很多)
- Our system alleviates this problem by moving the con-struction of the indexes to an offline system. MapRe-duce has been used for this offline construction in various search systems . These search layers trigger builds on Hadoop to generate indexes, and on completion, pull the indexes to serve search requests.
- This approach has also been extended to various databases. Konstantinou et al. and Barbuzzi et al. suggest building HFiles offline in Hadoop, then shipping them to HBase, an open source database modeled af-ter BigTable . These works do not explore the data pipeline, particularly data refreshes and rollback.(HBase bulkload缺少rollback机制)
4. Project Voldemort
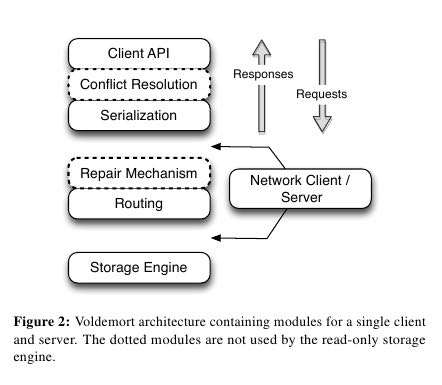
5. Alternative Approaches
Before we started building our own custom storage engine, we decided to evaluate the existing read-write storage engines supported in Voldemort, namely, MySQL and Berkeley DB. Our criteria for success was the ability to bulk load massive data sets with minimal disk space overhead, while still serving live traffic.(MySQL和BDB在作为存储引擎上的问题)
5.1. Shortcomings of Alternative Approaches
- The first approach we tried was to perform multiple put requests. This naive approach is problematic as every request results in an incremental change to the underly-ing index structure (in most cases, a B+ tree), which in turn, results in many disk seeks.(多次操作)
- To solve this problem, MySQL provides a LOAD DATA statement that tries to bulk update the underlying index. (LOAD DATA批量导入数据)
- Unfortunately, using this statement for the MyISAM storage engine locks the entire table.(MyISAM会锁表)
- InnoDB instead executes this statement with row-level locking, but experiences substantial disk space overhead for every tuple. However, to achieve MyISAM-like bulk loading performance, InnoDB prefers data or-dered by primary key.(InnoDB行级别锁表但是占用额外磁盘空间过大,并且如果希望达到MyISAM性能的话,key最好是排序的)
- Achieving fast load times with low space overhead in Berkeley DB requires several manual and non-scalable configuration changes, such as shutting down cleaner and checkpointer threads. #note: 什么是non-scalable configuration changes? 我的理解是BDB为了达到快速导入并且保持磁盘小的效果,修要比较麻烦的配置修改,但是这些配置修改却不太适合大量的数据导入
- The next solution we explored was to bulk load into a different MySQL table on the same cluster and use views to transparently swap to the new table. (批量导入到另外一个表然后通过view方式切换)
- We used the MyISAM storage engine, opting to skip InnoDB due to the large space requirements. This approach solves the locking problem, but still hurts serving latency during the load due to pressure on shared CPU and memory resources.(MyISAM可以解决锁表问题,但是占用资源比较多影响服务)
- We then tried completely offloading the index construc-tion to another system as building the index on the serving system has isolation problems.(在另外一个和线上服务独立的集群创建索引)
- We leveraged the fact that MyISAM allows copying of database files from another node into a live database directory, automatically making it available for serving. We bulk load to a separate cluster and then copy the resulting database files over to the live cluster. (因为MyISAM可以直接copy文件,所以在另外集群导入MySQL然后copy数据和索引文件到现有集群)
- This two-step approach requires the extra main-tenance cost of a separate MySQL cluster with exactly the same number of nodes as the live one. Additionally, the inability to load compressed data in the bulk load phase means data is copied multiple times between nodes: first, as a flat file to the bulk load cluster; then as an in-ternal copy during the LOAD statement; and finally, as a raw database file copy to the actual live database. Thesecopies make the load more time-consuming.(比较浪费资源,首先是需要单独创建索引的集群,另外是数据多次拷贝)
- The previous solution was not ideal, due to its depen-dency on redundant MySQL servers and the resulting vulnerability to failure downtime.
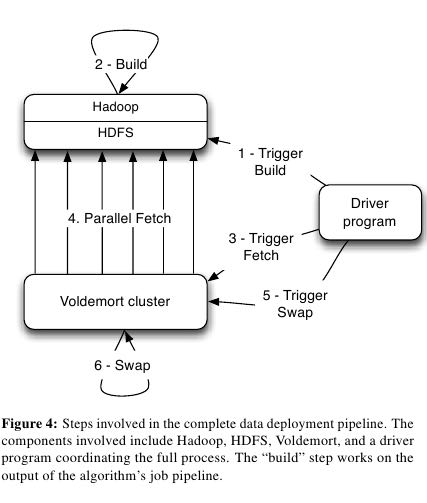
- To address this short-coming, the next attempted approach used the inherent fault tolerance and parallelism of Hadoop and built in-dividual node/partition-level data stores, which could be transferred to Voldemort for serving.
- A Hadoop job reads data from a source in HDFS , repartitions it on a per-node basis, and finally writes the data to individual storage engines (for example, Berkeley DB) on the local filesystem of the reducer phase Hadoop nodes. The num-ber of reducers equals the number of Voldemort nodes, but could have easily been further split on a per-partition basis.(Hadoop reduce将数据文件和索引文件先写到本地磁盘然后上传到HDFS。应该是数据文件可以直接写入到HDFS,但是索引文件需要先写本次磁盘然后上传)
- This data is then read from the local filesystem and copied onto HDFS, where it can be fetched by Voldemort. The benefit of this approach is that it leverages Hadoop’s parallelism to build the indexes offline; (Voldemort从HDFS上面拉取下来加载)
- however, it suf-fers from an extra copy from the local filesystem on the reducer nodes to HDFS, which can become a bottleneck with terabytes of data.(瓶颈在建立好的数据文件和索引文件上传到HDFS上)
5.2. Requirements
The lack of off-the-shelf solutions, along with the in-efficiencies of the previous experiments, motivated the building of a new storage engine and deployment pipeline with the following properties.
- Minimal performance impact on live requests: The incoming get requests to the live store must not be impacted during the bulk load. There is a trade-off between modifying the current index on the live server and a fast bulk load—quicker bulk loads result in increased I/O, which in turn hurts performance. As a result, we should completely rebuild the index offline and also throttle fetches to Voldemort.(限速拉取文件来减小对在线服务影响)
- Fault tolerance and scalability: Every step of the data load pipeline should handle failures and also scale horizontally to support future expansion with-out downtime.
- Rollback capability: The general trend we notice in our business is that incorrect or incomplete data due to algorithm changes or source data problems needs immediate remediation. In such scenarios, running a long batch load job to repopulate correct data is not acceptable. To minimize the time in error, our storage engine must support very fast rollback to a previous good state.
- Ability to handle large data sets: The easy access to scalable computing through Hadoop, along with the growing use of complex algorithms has resulted in large data sets being used as part of many core products. Classic examples of this, in the context of social networks, include storing relationships be-tween a pair of users, or between users and an entity. When dealing with millions of users, these pairs can easily reach billions of tuples, motivating our storage engine to support terabytes of data and perform well under a large data to memory ratio.(存储格式假设数据大小远大于可用内存大小)
6. Read-only Extensions
6.1. Storage Format
- Many storage formats try to build data structures that keep the data memory resident in the process’s address space, ignoring the effects of the operating system’s page cache. The several orders of magnitude latency gap be-tween page cache and disk means that most of the real performance benefit by maintaining our own structure is for elements already in the page cache. In fact, this cus-tom structure may even start taking memory away from the page cache. This potential interference motivated the need for our storage engine to exploit the page cache in-stead of maintaining our own complex heap-based data structure. Because our data is immutable, Voldemort memory maps the entire index into the address space. Ad-ditionally, because Voldemort is written in Java and runs on the JVM, delegating the memory management to the operating system eases garbage collection tuning.(充分利用os page cache一方面可以简化代码而不用自己去维护比较复杂的cache结构,另外一方面因为page cache不是通过JVM来管理的所以可以缓解JVM GC的压力来提高效率) #note: 用JVM编写的存储系统最好不要来自己管理cache,或者由上层来管理cache,或者由JNI来间接管理cache,因为cache对JVM GC的影响会非常大
- To take advantage of the parallelism in Hadoop during generation, we split the input data destined for a particular node into multiple chunk buckets, which in turn are split into multiple chunk sets. Generation of multiple chunk sets can then be done independently and in parallel.(在一个节点上的数据有若干个chunk buckets组成,而每个chunk bucket则由若干个chunk sets组成)
- A chunk bucket is defined by the primary partition id and replica id, thereby giving it a unique identifier across all nodes. For a store with N =2, the replica id would be either 0 for the primary replica or 1 for the secondary replica. Our initial design had started with the simpler design of having one chunk bucket per-node (that is, multiple chunk sets stored on a node with no knowledge of partition/replica), but the current smaller granularity is necessary to aid in rebalancing(这种partition方式直接就是dynamo里面提到的第三种方式) 这里的chunk bucket是指一个partition上的数据,由partition-id和replica-id共同标记。
- The number of chunk sets per bucket is decided dur-ing generation on the Hadoop side. The default value is one chunk set per bucket, but can be increased by the store owner for more parallelism. The only lim-itation is that a very large value for this parameter would result in multiple small-sized files—a scenario that HDFS does not handle efficiently.(chunk set对应hadoop里面一次reduce生成的文件,通常来说一个bucket包含一个set,但是可能为了加快构建可能包含多个set。但是也需要控制set文件的大小,不然就会存在许多小文件存储在HDFS上)
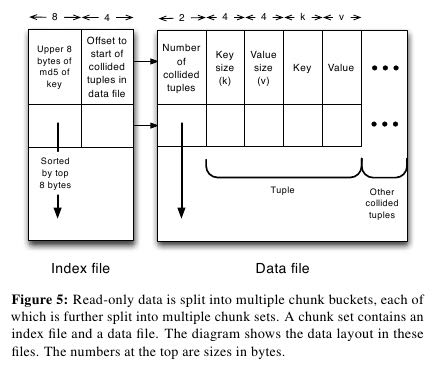
- As shown in Figure 5, a chunk set includes a data file and an index file. The standard naming convention for all our chunk sets is partition-id_replica-id_chunk-set-id.{data, index} where partition id is the id of the primary partition, replica id is a number between 0 to N −1, and chunk set id is a number between 0 to the predefined number of sets per bucket−1.(从下图里面可以看出文件组织有点类似链式冲突hash表结构,不过在查询index的时候是通过二分来查找的)
- The index file is a compact structure containing the sorted upper 8 bytes of the MD5 of the key followed by the 4 byte offset of the corresponding value in the data file.
- We had initially started by using the full 16 bytes of the MD5 signature, but saw performance problems as the number of stores grew. In particular, the indexes for all stores were not page cache resident, and thrashing behavior was seen for certain stores due to other high-throughput stores. To alleviate this problem, we needed to cut down on the amount of data being memory mapped, which could be achieved by reducing the available key-space and accepting collisions in the data file.(之所以选用前8个字节来做index key是考虑到index文件大小和冲突概率的折衷)
- The data file is also a very highly-packed structure where we store the number of collided tuples followed by a list of collided tuples (key size, value size, key, value). The order of these multiple lists is the same as the corre-sponding 8 bytes of MD5 of key in the index file. Here, we need to store the key bytes instead of the MD5 in the tuples to distinguish collided tuples during reads.
6.2. Chunk Set Generation
6.3. Data Versioning
- Every store is represented by a directory, which in turn contains directories corresponding to “versions” of the data. A symbolic link per store is used to point to the current serving version directory. Because the data in all version directories except the serving one is inactive, we are not affecting page cache usage and latency. (通过目录来保存历史版本,软链接指向当前使用的版本。存储历史并不会影响到page cache以及latency)
- Every version directory (named version-no) has a configurable number as-sociated with it, which should monotonically increase with every new fetch. A commonly used example for the version number is the timestamp of push.(版本号应该是单调递增的,比如push时间戳。
- Swapping in a new data version on a single node is done as follows:
- copy into a new version directory,
- close the current set of active chunk set files,
- open the chunk set files from the new version,
- memory map all the index files,
- and change the symbolic link to the new version.
- The entire operation is coordinated using a read-write lock. A rollback follows the same sequence of steps, except that files are opened in an older version directory. Both of these operations are very fast as they are purely metadata operations: no data reads take place.
6.4. Data Load
6.5. Retrieval
- The most time-consuming step is to search the index file. A binary search in an index of 1 million keys can result in around 20 key comparisons; if the index file is not cached, then 20 disk seeks are required to read one value. (检索最耗时的部分还是在查询index file上) #note: 用bloom filter屏蔽key不存在这种最坏情况。
- As a small optimization, while fetching the files from HDFS, Voldemort fetches the index files after all data files to aid in keeping the index files in the page cache. 首先传输数据文件,然后传输index文件,来帮助index文件留在page cache里面
- Rather than binary search, another retrieval strategy for sorted disk files is interpolation search. This search strategy uses the key distribution to predict the approxi-mate location of the key, rather than halving the search space for every iteration. Interpolation search works well for uniformly distributed keys, dropping the search com-plexity from O(log N) to O(log log N). This helps in the uncached scenario by reducing the number of disk seeks. As MD5 (and its subsets) provides a fairly represen-tative uniform distribution, there will be minimal speedup from these techniques. (插值搜索可以在key分布不均匀的情况下提高效率)
6.6. Schema Upgrades
6.7. Rebalancing
因为Voldemort定位为只读数据库,所以在membership的变化下数据可以保持强一致性。而Dynamo这类读写数据库的话,在membership的变化数据只能够保持最终一致性。
- Our smallest unit of rebalancing is a partition. In other words, the addition of a new node translates to giving the ownership of some partitions to that node. The rebalancing process is run by a tool that coordinates the full process.(Again,这种partition方式就是dynamo里面提到的第三种方式,好处就是在rebalance的时候不需要scan key range而只是需要移动对应的partition data file)
- The following describes the rebalancing strategy during the addition of a new node.
- First, the rebalancing tool is provided with the future cluster topology metadata, and with this data, it generates a list of all primary partitions that need to be moved. The tool moves partitions in small batches so as to checkpoint and not refetch too much data in case of failure.(driver会计算出哪些partition需要移动,但是每次移动一批partition而不是全部。这样可以方便做checkpoint,并且在失败重试情况下面少取数据)
- For every small batch of primary partitions, the sys-tem generates an intermediate cluster topology metadata, which is the current cluster topology plus changes in own-ership of the batch of partitions moved.
- Voldemort must take care of all secondary replica movements that might be required due to the primary partition movement.(还需要考虑secondary replica的移动)
- A plan is generated that lists the set of donating and steal-ing node-id pairs along with the chunk buckets being moved. With this plan, the rebalancing tool starts asyn-chronous processes (through the administrative service) on the stealer nodes to copy all chunk sets corresponding to the moving chunk buckets from their respective donor nodes.(移动过程完全是异步操作)
- Rebalancing works only on the active version of the data, ignoring the previous versions. (只是操作当前版本的数据)
- During this copy-ing, the nodes go into a “rebalancing state” and are not allowed to swap any new data.(节点在rebalance期间会标记正在进行状态,在此期间不允许load数据。这个设计可以简化不少问题)
- Here it is important to note that the granularity of the bucket selected makes this process as simple as copying files. If buckets were defined on a per-node basis (that is, have multiple chunk sets on a per-node basis), the system would have had to iterate over all the keys on the node and find the keys belonging to the moving partition, finally running an extra merge step to coalesce with the live index on the stealer node’s end.
- Once the fetches are complete, the rebalancing tool updates the intermediate cluster topology on all the nodes while also running the swap operation, for all the stores on the stealer and donor nodes. The entire process repeats for every batch of primary partitions. #todo: 为什么不等待所有节点rebalance/fetch完成所有数据之后,直接通知所有节点更新到最终的membership并且做swap操作(as an atomic operation)? 分批执行fetch可以理解是因为这样可以让这个系统平滑,可以分批更新membership就不太理解了。(也许等待所有节点都完成fetch然后切换等待时间太长,因为是只读数据库所有分批更新membership会非常安全并且可以看到效果)
- The intermediate topology change also needs to be propagated to all the clients. Voldemort propagates this information as a lazy process where the clients still use the old metadata. If they contact a node with a request fora key in a partition that the node is no longer responsible for, a special exception is propagated, which results in a rebootstrap step along with a retry of the previous request. (上面的问题同样出现在如何通知client上。如果只是每次几个primary partition增量更新的话,那么client对于membership的更新也只能够是增量的,只能更新本次所取的key对应的partition在哪个node上这个信息。可是如果所有节点的membership是最后全量更新的话,那么client则可以选择是增量更新还是全量更新,可以知道所有的partition在哪些node上面这个信息。增量的更新可以降低延迟,但是会增大吞吐)
- The rebalancing tool has also been designed to handle failure scenarios elegantly. Failure during a fetch is not a problem as no new data has been swapped. However, failure during the topology change and swap phase on some nodes requires (a) changing the cluster topology to the previous good cluster topology on all nodes and (b) rolling back the data on nodes that had successfully swapped.