探索Google App Engine背后的奥秘
Table of Contents
1. Google的核心技术
http://dbanotes.net/arch/google_app_engine_arch.html
本篇将主要介绍Google的十个核心技术,而且可以分为四大类:
- 分布式基础设施:GFS、Chubby 和 Protocol Buffer。
- 分布式大规模数据处理:MapReduce 和 Sawzall。
- 分布式数据库技术:BigTable 和数据库 Sharding。
- 数据中心优化技术:数据中心高温化、12V电池和服务器整合。
1.1. 分布式基础设施
- GFS
- Chubby
- Protocol Buffer
1.2. 分布式大规模数据处理
- MapReduce
- Sawzall
1.3. 分布式数据库技术
- BigTable/MegaStore/Spanner
- 数据库Sharding
1.4. 数据中心优化技术
- 数据中心高温化
- 大中型数据中心的PUE(Power Usage Effectiveness)普遍在2左右,也就是在服务器等计算设备上耗1度电,在空调等辅助设备上也要消耗一度电。对一些非常出色的数据中心,最多也就能达到1.7,但是Google通过一些有效的设计使部分数据中心到达了业界领先的1.2
- 在这些设计当中,其中最有特色的莫过于数据中心高温化,也就是让数据中心内的计算设备运行在偏高的温度下 ,Google的能源方面的总监Erik Teetzel在谈到这点的时候说:”普通的数据中心在70华氏度(21摄氏度)下面工作,而我们则推荐80华氏度(27摄氏度)”。
- 但是在提高数据中心的温度方面会有两个常见的限制条件:其一是服务器设备的崩溃点,其二是精确的温度控制。如果做好这两点,数据中心就能够在高温下工作,因为假设数据中心的管理员能对数据中心的温度进行正负1/2度的调节,这将使服务器设备能在崩溃点5度之内工作,而不是常见的20度之内,这样既经济,又安全。
- 12V电池
- 由于传统的UPS在资源方面比较浪费,所以Google在这方面另辟蹊径,采用了给每台服务器配一个专用的12V电池的做法来替换了常用的UPS,如果主电源系统出现故障,将由该电池负责对服务器供电。
- 虽然大型UPS可以达到92%到95%的效率,但是比起内置电池的99.99%而言是非常捉襟见肘的,而且由于能量守恒的原因,导致那么未被UPS充分利用的电力会被转化成热能,这将导致用于空调的能耗相应地攀升,从而走入一个恶性循环。
- 同时在电源方面也有类似的”神来之笔”,普通的服务器电源会同时提供5V和12V的直流电。但是Google设计的服务器电源只输出12V直流电,必要的转换在主板上进行,虽然这种设计会使主板的成本增加1美元到2美元,但是它不仅能使电源能在接近其峰值容量的情况下运行,而且在铜线上传输电流时效率更高。
- 服务器整合
- Google在硬件方面也引入类似服务器整合的想法,它的做法是在一个机箱大小的空间内放置两台服务器,这些做的好处有很多,首先,减小了占地面积。其次,通过让两台服务器共享诸如电源等设备,来降低设备和能源等方面的投入。
2. Google的整体架构猜想
http://dbanotes.net/arch/google_app_engine_arch_guess.html
在软件工程界,大家有一个共识,那就是”需求决定架构”,也就是说,架构的发展是为了更好地支撑应用。那么本文在介绍架构之前,先介绍一下Google所提供的主要产品有哪些?
2.1. 产品
对于Google和它几个主要产品,比如搜索和邮件等,大家已经非常熟悉了,但是其提供服务的不只于此,并主要可分为六大类:
- 各种搜索:网页搜索,图片搜索和视频搜索等。
- 广告系统:AdWords和AdSense。
- 生产力工具:Gmail和Google Apps等。
- 地理产品:地图,Google Earth和Google Sky等。
- 视频播放:Youtube。
- PaaS平台:Google App Engine。
2.2. 设计理念
- Scale,Scale,Scale.
- 容错. 在一个拥有两万台X86服务器的集群中,每天大约有110台机器会出现宕机等恶劣情况,所以容错是一个不可被忽视的问题。
- 低延迟. 低延迟对用户体验非常关键,而且为了避免光速和复杂网络环境造成的延时,Google已在很多地区设置了本地的数据中心。
- 廉价的硬件和软件.
- 优先移动计算. 处理大规模数据的时候,Google还是倾向于移动计算,而不是移动数据。
- 服务模式. 在Google的系统中,服务是相当常用的,比如其核心的搜索引擎需要依赖700-1000个内部服务,而且服务这种松耦合的开发模式在测试,开发和扩展等方面都有优势,因为它适合小团队开发,并且便于测试。
2.3. 整体架构的猜想
在整体架构这部分,首先会举出Google的三种主要工作负载,接着会试着对数据中心进行分类,最后会做一下总结。
- 三种工作负载
- 本地交互:用于在用户本地为其提供基本的Google服务,比如网页搜索等,但会将内容的生成和管理工作移交给下面的内容交付系统,比如:生成搜索所需的Index等。通过本地交互,能让用户减少延迟,从而提高用户体验,而且其对SLA要求很高,因为是直接面对客户的。 #note: 类似CDN
- 内容交付:用于为Google大多数服务提供内容的存储,生成和管理工作,比如创建搜索所需的Index,存储YouTube的视频和GMail的数据等,而且内容交互系统主要基于Google自己开发那套分布式软件栈。还有,这套系统非常重视吞吐量和成本,而不是SLA。 #note: 离线计算和存储
- 关键业务:主要包括Google一些企业级事务,比如用于企业日常运行的客户管理和人力资源等系统和赚取利润的广告系统(AdWords和AdSense),同时关键业务对SLA的要求非常高。 #note: 在线业务
- 两类数据中心
- 按照2008年数据,Google在全球有37个数据中心,其中19个在美国,12个在欧洲,3个在亚洲(北京、香港、东京),另外3个分布于俄罗斯和南美。
- 虽然Google拥有数据中心数量很多,但是它们之间存在一定的差异,而且主要可以分为两类:其一是巨型数据中心,其二是大中型数据中心。
- 巨型数据中心。服务器规模应该在十万台以上,常坐落于发电厂旁以获得更廉价的能源,主要用于Google内部服务,也就是内容交付服务,而且在设计方面主要关注成本和吞吐量,所以引入了大量的定制硬件和软件,来减低PUE并提升处理量,但其对SLA方面要求不是特别严厉,只要保证绝大部分时间可用即可。
- 大中型数据中心。服务器规模在千台至万台左右,可用于本地交互或者关键业务,在设计方面上非常重视延迟和高可用性,使得其坐落地点尽可能地接近用户而且采用了标准硬件和软件,比如Dell的服务器和MySQL的数据库等,常见的PUE大概在1.5和1.9之间。
巨型与大中型数据中心的对比表
| 巨型数据中心 | 大中型数据中心 | |
|---|---|---|
| 工作负载 | 内容交付 | 本地交互/关键业务 |
| 地点 | 离发电厂近 | 离用户近 |
| 设计特点 | 高吞吐,低成本 | 低延迟,高可用性 |
| 服务器定制化 | 多 | 少 |
| SLA | 普通 | 高 |
| 服务器数量 | 十万台以上 | 千台以上 |
| 数据中心数量 | 十个以内 | 几十个 |
| PUE估值 | 1.2 | 1.5 |
3. Google App Engine的简介
3.1. Google App Engine的介绍
Google App Engine 提供一整套开发组件来让用户轻松地在本地构建和调试网络应用,之后能让用户在Google强大的基础设施上部署和运行网络应用程序,并自动根据应用所承受的负载来对应用进行扩展,并免去用户对应用和服务器等的维护工作。同时提供大量的免费额度和灵活的资费标准。在开发语言方面,现支持Java和Python这两种语言,并为这两种语言提供基本相同的功能和API。
在功能上,主要有六个方面:
- 动态网络服务,并提供对常用网络技术的支持,比如SSL等 。
- 持久存储空间,并支持简单的查询和本地事务。
- 能对应用进行自动扩展和负载平衡。
- 一套功能完整的本地开发环境,可以让用户在本机上对App Engine进行开发和调试。
- 支持包括Email和用户认证等多种服务。
- 提供能在指定时间和定期触发事件的计划任务和能实现后台处理的任务队列。
3.2. Google App Engine的主要组成部分
主要可分为五部分:
- 应用服务器:主要是用于接收来自于外部的Web请求。
- Python WSGI. 虽然Python版应用服务器是基于标准的Python Runtime,但是为了安全并更好地适应App Engine的整体架构,对运行在应用服务器内的代码设置了很多方面的限制,比如不能加载用C编写Python模块和无法创建Socket等。
- Java Jetty. 大多数常用的Java API(App Engine有一个The JRE Class White List来定义那些Java API能在App Engine的环境中被使用)
- Datastore:主要用于对信息进行持久化,并基于Google著名的BigTable技术。 #note: 底层应该是MegaStore
- 在接口方面,Python版提供了非常丰富的接口,而且还包括名为GQL的查询语言,而Java版则提供了标准的JDO和JPA这两套API。
- 在未来的App Engine for Business套件中包含标准的SQL数据库服务,但现在还不确定这个SQL数据库的实现方式。
- 服务:除了必备的应用服务器和Datastore之外,GAE还自带很多服务来帮助开发者,比如:Memcache,邮件,网页抓取,任务队列,XMPP等。
- 管理界面:主要用于管理应用并监控应用的运行状态,比如,消耗了多少资源,发送了多少邮件和应用运行的日志等。
- 本地开发环境:主要是帮助用户在本地开发和调试基于GAE的应用,包括用于安全调试的沙盒,SDK和IDE插件等工具。
3.3. 限制和资费
App Engine的使用限制
| 类别 | 限制 |
|---|---|
| 每个开发者所拥有的项目 | 10个 |
| 每个项目的文件数 | 1000个 |
| 每个项目代码的大小 | 150MB |
| 每个请求最多执行时间 | 30秒 |
| Blobstore(二进制存储)的大小 | 1GB |
| HTTP Response的大小 | 10MB |
| Datastore中每个对象的大小 | 1MB |
App Engine的免费额度表
| 类型 | 数量(每天) |
|---|---|
| 邮件API调用 | 7000次 |
| 传出(outbound)带宽 | 10G |
| 传入(inbound)带宽 | 10G |
| CPU时间 | 46个小时 |
| HTTP请求 | 130万次 |
| Datastore API | 1000万次 |
| 存储的数据 | 1G |
| URL抓取的API | 657千次 |
从上面免费额度来看,除了存储数据的容量外,其它都是非常强大的。
4. Google App Engine的架构
4.1. 设计理念
App Engine在设计理念方面,主要可以总结为下面这五条:
- 重用现有的Google技术:在App Engine开发的过程中,重用的思想也得到了非常好的体现,比如Datastore是基于Google的bigtable技术,Images服务是基于Picasa的,用户认证服务是利用Google Account的,Email服务是基于Gmail的等。
- 无状态:为了让更好地支持扩展,Google没有在应用服务器层存储任何重要的状态,而主要在datastore这层对数据进行持久化,这样当应用流量突然爆发时,可以通过为应用添加新的服务器来实现扩展。
- 硬限制:App Engine对运行在其之上的应用代码设置了很多硬性限制,比如无法创建Socket和Thread等有限的系统资源,这样能保证不让一些恶性的应用影响到与其临近应用的正常运行,同时也能保证在应用之间能做到一定的隔离。
- 利用Protocol Buffers技术来解决服务方面的异构性
- 分布式数据库:因为App Engine将支撑海量的网络应用,所以独立数据库的设计肯定是不可取的,而且很有可能将面对起伏不定的流量,所以需要一个分布式的数据库来支撑海量的数据和海量的查询。
4.2. 组成部分
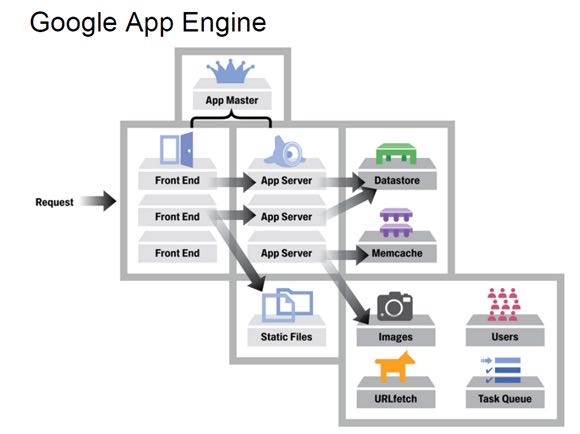
前端包括下面几个部分:
- Front End:既可以认为它是Load Balancer,也可以认为它是Proxy,它主要负责负载均衡和将请求转发给App Server(应用服务器)或者Static Files等工作。
- Static Files:在概念上,比较类似于CDN(Content Delivery Network,内容分发网络),用于存储和传送那些应用附带的静态文件,比如图片,CSS和JS脚本等。
- App Server:用于处理用户发来的请求,并根据请求的内容来调用后面的Datastore和服务群。
- App Master:是在应用服务器间调度应用,并将调度之后的情况通知Front End。
5. Datastore的设计
6. 总结
6.1. 注意点
- 执行速度偏慢:由于其分布式的设计,所以在速度方面不是最优的,比如普通的Memcache能在几毫秒完成操作,而App Engine的Memcache则大概需要50(毫)秒才能完成操作。
- 私有API:其API有很多都是私有,特别是在其服务方面,虽然Google提供了很不错的文档,但是在学习和移植等方面,成本都很高。
- 执行会出现失败的情况:根据很多人的实际经验,App Engine会不定时出现执行失败的情况,特别是Datastore和URLFetch这两部分,虽然Google已经将Datastore方面出现错误的几率从原先的0.4降至现在的0.1,但是失败的情况是很难避免的。
- 有时会停机:虽然总体而言,停机并不频繁,但是在今年初出现长达136分钟故障导致部分用户的应用无法正常运行,其发生原因来自于其备份数据中心出现了问题。
- 无法选择合适的数据中心:比如,你应用所面对的用户主要在欧洲,但是你应用所属App Engine服务器却很有可能是被部署在一个美国的数据中心内,虽然你的应用很有可能在将来移动至欧洲某个数据中心,但是你却无法控制整个过程。
- 有时会处理请求超时:虽然能平均在100至200ms之间完成海量的请求,但是有时会出现处理请求超时的情况。
- 不支持裸域名:只支持类似CNAME的子域名。
6.2. 最佳实践
- 适应App Engine的数据模型:因为其数据模型,并不是传统的关系模式,而且在性能方面表现也和关系型数据库差别很大,所以如果想要用好非常关键的Datastore,那么理解和适应其数据模型是不可或缺的。
- 对应用进行切分:由于App Engine对每个应用都有一定资源限制,而且为了让应用更SOA化和更模块化,可以对一个应用切分多个子应用,比如,可以分成一个用于前端的Web应用和多个用于REST服务的后台应用。
- 极可能多地利用Memcache,这样不仅能减少昂贵的Datastore操作,而且能减轻Datastore的压力。
- 在上面提到过,由于App Engine在执行某些操作时会出现失败的情况,比如Datastore方面,所以要在设计和实现这两方面做好相应的异常处理工作。
- 由于Datastore不是关系型数据库,导致在执行常见的求总数操作时显的有点”捉襟见肘”,所以最好使用Google推荐的Sharded Counters技术来计算总数。
- 由于Blobstore还只是刚走出试验期而已,而且其他模块对静态文件(比如图片等)支持不佳,比如Datastore只支持1MB以内的对象,同时每个应用只能最多上传一千个文件,而且速度不是最优,所以推荐使用其他专业的云存储,比如Amazon的S3或者Google马上就要推出的Google Storage等。
- 尽量使用批处理方式,不论是在使用Datastore还是发送邮件等。
- 不要手动创建Index:因为App Engine会自动根据你在代码中查询来创建相关的Index。
6.3. 适用场景
- Web Hosting:这是最常见的场景,在App Engine上已经部署了数以十万计的小型网站(其中有很多主要为了学习目的),而且还部署了一些突发流量很大的网站,其中最著名的例子就是美国白宫的”Open For Questions”这个站点,主要用于让美国人民给奥巴马总统提问的,这个站点在短短的几个小时内处理接近百万级别的流量。
- REST服务:这也是在App Engine平台上很常见的场景,最出名的例子就是BuddyPoke,BuddyPoke的客户端就是一个Flash应用,在用户的浏览器上运行,而它的服务器端则是以REST服务的形式放置在App Engine上,每当Flash客户端需要读取和存储数据的时候,它都会发请求给后端的REST服务,来让其执行相关的Datastore操作。
- 依赖Google服务的应用:比如应用能够通过App Engine的Email服务来发送大规模的电子邮件。
6.4. 未来的期望
- 更稳定的表现,更少的超时异常和更快的反应速度,特别是在Datastore和Memcached这两方面。
- 支持对数据中心的选择,虽然现在App Engine会根据应用的用户群的所在地来调整应用所在的数据中心,但由于整个过程对开发者而言是不可控的,所以希望能在创建应用的时候,能让用户自己选择合适的数据中心。
- SLA,如果App Engine能像S3那样设定一些SLA条款,这样将使用户更放心地在App Engine上部署应用。
- 新的语言:比如PHP,但是如果在现有的App Engine架构上添加一门新的语言,整个工作量会非常大的,因为App Engine有接近一半的模块是语言特定的,比如应用服务器和开发环境等,所以短期内我认为不太可能支持新的语言。