Unix Network Programming
Table of Contents
1. 简介
1.1. 网络模型
OSI(open systems interconnection,开放系统互连)模型是一种网络模型,是按照下面这样的方式划分的:
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
在现实中对应关系是这样的:
- 数据链路层和物理层是随系统提供的设备驱动程序和网络硬件。
- 网络层对应IPv4,IPv6.
- 传输层对应TCP,UDP.
- 会话层,表示层以及应用层对应我们具体的应用。
我们使用的套接字编程模型,就是对于传输层,网络层操作的封装,而对于这里也是系统调用和用户调用的区分点。 但是在Linux系统上,在这层界面这里也打了一个洞,允许我们使用SOCK_RAW选项来直接操作网络层。
1.2. 网络协议
常见的协议有下面这些:
| 协议 | 说明 |
|---|---|
| IPv4 | Internet Protocol version 4.使用32位地址,为TCP,UDP,SCTP,ICMP,IGMP提供分组递送服务。 |
| IPv6 | Internet Protocol version 6.使用128位地址,为TCP,UDP,SCTP,ICMPv6提供分组递送服务。 |
| TCP | Transmission Control Protocol.传输控制协议,面向连接的流套接字,关心确认,超时和重传细节等。 |
| UDP | User Datagram Protocol.用户数据报协议。无连接的数据报套接字,不保证最终可靠性。 |
| SCTP | Stream Control Transmission Protocol.流控制传输协议,类似TCP面向链接但是处理数据报而不是流。 |
| ICMP | Internet Control Message Protocol.网际控制消息协议。处理在路由器和逐渐之间流通的错误和控制信息 |
| IGMP | Internet Group Management Protocol.网际组管理协议。用于管理多播,但是没有IGMPv6. |
| ARP | Address Resolution Protocol.地址解析协议。把IPv4地址映射成为一个硬件地址比如以太网地址。 |
| RARP | Reverse Address Resolution Protocol.反向地址解析协议。将硬件地址解析成为IPv4地址。 |
| ICMPv6 | Internet Control Message Protocol version 6.综合了ICMP,IGMP,ARP的功能。 |
| BPF | BSD packet filter.BSD分组过滤器,提供了对于数据链路层访问能力。 |
| DLPI | datalink provider interface.数据链路层提供者接口,同样提供对于数据链路层访问能力。 |
所有网络协议由一个或者是多个称为请求评注(Request For Comments,RFC)的文档进行定义,这些RFC就是它们的正式规范。
1.3. 数据包大小限制
1.3.1. IP数据报头部字段
IPv4允许表示的最大字节数目数目是65536(包括IPv4首部),而IPv6允许表示65576字节(包括IPv6首部).注意IPv6有一个特大净荷(jumbo payload), 能够把净荷长度字段扩展到32位,所以理论上说IPv6允许表示字节数是4G.
1.3.2. 网络MTU
网络MTU(maximum transmission unit,最大传输单元)表示对于这个网络来说一次传输的最大数据字节数(不包括网络封装占用字节数),通常来说 MTU是网络硬件规定的。对于我们最常用的以太网来说,MTU是1500字节。IPv4要求MTU至少68字节,这样可以容纳下20字节定长头+40字节可选部分 +8字节最小片段,而IPv6要求MTU至少1280字节。IPv4和IPv6都可以很顺利地运行在以太网上。
1.3.3. 路径MTU
对于因特网来说我们底层使用的网络可能是异构的,在传输路径上某一部分使用的数据链路层是以太网,而在另外一部分使用的数据链路层比如是X.25的话, 那么这个路径上面的MTU取决于最小的MTU,而这个MTU就是路径MTU(path MTU).
1.3.4. IP分片
当IP数据包传递到数据链路层的时候,会首先知道数据链路层的MTU并且按照数据链路层的MTU进行分片,这些分片在达到最终目的地之前是不会重组的。 我们需要注意的是IPv4在主机上会执行分片,而允许IPv4的路由器也会对转发的数据进行分片,而IPv4仅仅是在主机上进行分片,而运行IPv6的路由器 不会对转发的数据进行分片。
因为IPv6都假设在主机已经完成了分片,所以可以认为IPv6隐含了不进行分片的选项。而IPv6有一个位可以设置DF位(Don't Fragment), 使用这个位的话那么IPv4对于数据是不进行分片的。如果不分片进行发送的话,如果超过网络MTU的话,那么IPv4会产生ICMPv4信息 "destionation unreachable,fragmentation need but DF bit set",而IPv6会返回ICMPv6信息"packet too big".可以看到使用不分片这个选项, 可以用来发现路径MTU,首先按照IPv4使用X字节发送并且setDF,如果返回ICMPv4错误消息的话,那么就可以减少X大小知道发送成功。
1.3.5. 最小重组缓冲区大小
最小重组缓冲区大小(minimum reassembly buffer size)是指IPv4或者是IPv6的任何事先都必须保证支持的最小数据报大小, 其值对于IPv4为576字节,对于IPv6为1500字节。最小重组缓冲区大小的设定,可以帮助应用程序在应用层面尽可能地试图避免分片。 如果IPv4为576字节的话,那么使用TCP情况下实际数据大小应该为576-IP首部(20)-TCP首部(20)=536字节。
1.3.6. TCP MSS
TCP MSS(maximum segment size,最大分节大小),用于告诉TCP对端在每个分节中能够发送的最大TCP数据量。MSS的目的是告诉对端其重组缓冲区大小 的实际值,从而试图避免分片。MSS经常设置成为MTU(1500)-IP固定长度(20)-TCP固定长度(20)=1460,而对于IPv6是1440因为IPv6长度40字节。 需要注意的是,这里只是试图避免分片。很明显对于MTU发现的话只是知道某个网络接口的MTU,而并不知道路径MTU.实际上按照MSS发送的话, 依然面临分片的可能,只不过分片不在主机这里而可能出现在转发路由器上。
2. 套接字接口
2.1. address
2.1.1. 通用地址结构
| 类型 | 基本类型 | 说明 | 头文件 |
|---|---|---|---|
| sa_family_t | unsigned short int | 套接字地址结构的地址族 | <bits/sockaddr.h> |
| socklen_t | uint32_t | 套接字地址结构的长度 | <sys/types.h> |
| in_addr_t | uint32_t | IPv4地址 | <netinet/in.h> |
| in_port_t | uint16_t | 端口号 | <netinet/in.h> |
//============================== //#include <bits/sockaddr.h> #define __SOCKADDR_COMMON(sa_prefix) \ sa_family_t sa_prefix##family #define __SOCKADDR_COMMON_SIZE (sizeof (unsigned short int)) //============================== //#include <bits/socket.h> /* Structure describing a generic socket address. */ struct sockaddr //老的通用套接字地址结构,对于比如Unix Domain Socket地址的话不能够容纳 { __SOCKADDR_COMMON (sa_); /* Common data: address family and length. */ char sa_data[14]; /* Address data. */ }; /* Structure large enough to hold any socket address (with the historical exception of AF_UNIX). We reserve 128 bytes. */ #if ULONG_MAX > 0xffffffff # define __ss_aligntype __uint64_t #else # define __ss_aligntype __uint32_t #endif #define _SS_SIZE 128 #define _SS_PADSIZE (_SS_SIZE - (2 * sizeof (__ss_aligntype))) struct sockaddr_storage //新的通用套接字地址结构,能够容纳几乎所有的套接字结构地址。 { __SOCKADDR_COMMON (ss_); /* Address family, etc. */ __ss_aligntype __ss_align; /* Force desired alignment. */ char __ss_padding[_SS_PADSIZE]; };
通用套接字结构是为了给底层系统调用来使用,系统调用根据这里的sa_family字段判断具体为什么协议族, 然后通过强转成为对应的具体套接字地址结构来进行处理。虽然这里有新的套接字地址结构,但是因为其实没有太大必要, 因为底层只是关心头部的有限几个字节然后分别做处理,同时因为历史原因都使用了sockaddr这个接口,所以可以说 基本上没有必要关心sockaddr_storage这个结构。
2.1.2. IPv4地址结构
//============================== //#include <netinet/in.h> struct in_addr { in_addr_t s_addr; }; struct sockaddr_in { __SOCKADDR_COMMON (sin_); //AF_INET in_port_t sin_port; /* Port number. */ struct in_addr sin_addr; /* Internet address. */ /* Pad to size of `struct sockaddr'. */ unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE - sizeof (in_port_t) - sizeof (struct in_addr)]; };
2.1.3. IPv6地址结构
//============================== //#include <netinet/in.h> /* IPv6 address */ struct in6_addr { union { uint8_t u6_addr8[16]; uint16_t u6_addr16[8]; uint32_t u6_addr32[4]; } in6_u; #define s6_addr in6_u.u6_addr8 #define s6_addr16 in6_u.u6_addr16 #define s6_addr32 in6_u.u6_addr32 }; /* Ditto, for IPv6. */ struct sockaddr_in6 { __SOCKADDR_COMMON (sin6_); //AF_INET6 in_port_t sin6_port; /* Transport layer port # */ uint32_t sin6_flowinfo; /* IPv6 flow information */ struct in6_addr sin6_addr; /* IPv6 address */ uint32_t sin6_scope_id; /* IPv6 scope-id */ };
2.1.4. IP地址表示和数值
使用inet_pton和inet_ntop可以在IP地址的表示(presentation)以及数值(numeric)之间进行转换,表示格式是ASCII字符串, 而数值格式是存放到套接字结构中的二进制,使用inet_pton和inet_ntop可以在这两种格式下面转换。 对于IPv4和IPv6的IP表示长度存在限制,如果提供的长度不足以表示的话那么会返回ENOSPC错误。但是幸运的是,系统提供了限制常数。
//#include <arpa/inet.h> /* Convert from presentation format of an Internet number in buffer starting at CP to the binary network format and store result for interface type AF in buffer starting at BUF. */ extern int inet_pton (int __af, __const char *__restrict __cp, void *__restrict __buf) __THROW; /* Convert a Internet address in binary network format for interface type AF in buffer starting at CP to presentation form and place result in buffer of length LEN astarting at BUF. */ extern __const char *inet_ntop (int __af, __const void *__restrict __cp, char *__restrict __buf, socklen_t __len) __THROW; //#include <netinet/in.h> #define INET_ADDRSTRLEN 16 #define INET6_ADDRSTRLEN 46
#include <arpa/inet.h> #include <netinet/in.h> #include <cstdio> int main(){ const char* ip="255.244.233.211"; char ip_dst[INET_ADDRSTRLEN]; sockaddr_in addr; inet_pton(AF_INET,ip,&(addr.sin_addr)); inet_ntop(AF_INET,&(addr.sin_addr),ip_dst,sizeof(ip_dst)); printf("%s\n",ip_dst); return 0; }
2.1.5. 端口号
IP用于标识通讯的机器,而端口号用于标识通信的进程。IANA(the Internet Assigned Numbers Authority,因特网分配数值权威机构) 维护着一个端口号分配状况清单,端口号被分为下面3段:
- 众所周知的端口号(well-known port)[0,1023],这些端口由IANA分配和控制。对于系统来说,使用这些端口通常需要root权限。
- 已登记的端口号(registered port)[1024,49151],这些端口不由IANA分配,但是由IANA登记并且提供它们使用清单。
- 动态端口(dynamic port)[49152,65535],IANA不管这些端口,我们可以自由使用,通常也称临时端口(ephemeral port).
注意对于不同的传输层协议,端口是可以复用的。
//#include <netinet/in.h> /* Standard well-known ports. */ enum { IPPORT_ECHO = 7, /* Echo service. */ IPPORT_DISCARD = 9, /* Discard transmissions service. */ IPPORT_SYSTAT = 11, /* System status service. */ IPPORT_DAYTIME = 13, /* Time of day service. */ IPPORT_NETSTAT = 15, /* Network status service. */ IPPORT_FTP = 21, /* File Transfer Protocol. */ IPPORT_TELNET = 23, /* Telnet protocol. */ IPPORT_SMTP = 25, /* Simple Mail Transfer Protocol. */ IPPORT_TIMESERVER = 37, /* Timeserver service. */ IPPORT_NAMESERVER = 42, /* Domain Name Service. */ IPPORT_WHOIS = 43, /* Internet Whois service. */ IPPORT_MTP = 57, IPPORT_TFTP = 69, /* Trivial File Transfer Protocol. */ IPPORT_RJE = 77, IPPORT_FINGER = 79, /* Finger service. */ IPPORT_TTYLINK = 87, IPPORT_SUPDUP = 95, /* SUPDUP protocol. */ IPPORT_EXECSERVER = 512, /* execd service. */ IPPORT_LOGINSERVER = 513, /* rlogind service. */ IPPORT_CMDSERVER = 514, IPPORT_EFSSERVER = 520, /* UDP ports. */ IPPORT_BIFFUDP = 512, IPPORT_WHOSERVER = 513, IPPORT_ROUTESERVER = 520, /* Ports less than this value are reserved for privileged processes. */ IPPORT_RESERVED = 1024, /* Ports greater this value are reserved for (non-privileged) servers. */ IPPORT_USERRESERVED = 5000 };
因为网络字节序是大端序表示的,所以在设置套接字地址端口的话需要做字节序转换。同样幸运的是, 系统提供了这样的转换函数
//#include <netinet/in.h> extern uint32_t ntohl (uint32_t __netlong) __THROW __attribute__ ((__const__)); extern uint16_t ntohs (uint16_t __netshort) __THROW __attribute__ ((__const__)); extern uint32_t htonl (uint32_t __hostlong) __THROW __attribute__ ((__const__)); extern uint16_t htons (uint16_t __hostshort) __THROW __attribute__ ((__const__));
其中n表示network,h表示host,而l表示long(32bit),s表示short(16bit).
#include <netinet/in.h> #include <cstdio> int main(){ sockaddr_in addr; addr.sin_port=htons(12345); in_port_t port=ntohs(addr.sin_port); printf("%d\n",port); return 0; }
2.2. socket
获得操作网络IO的套接字文件描述符。
//#include <sys/socket.h> /* Create a new socket of type TYPE in domain DOMAIN, using protocol PROTOCOL. If PROTOCOL is zero, one is chosen automatically. Returns a file descriptor for the new socket, or -1 for errors. */ extern int socket (int __domain, int __type, int __protocol) __THROW;
domain取值有下面这些:
| domain | 说明 |
|---|---|
| AF_INET | IPv4协议 |
| AF_INET6 | IPv6协议 |
| AF_LOCAL | Unix域协议 |
我们也可以写对应的PF_xxx版本(更加符合本意,PF意思就是protocol family),历史原因出现AF_xxx和PF_xxx, 不过现在基本上所有的实现PF_xxx的值和AF_xxx的值都是相等的。
type取值有下面这些:
| type | 说明 |
|---|---|
| SOCK_STREAM | 字节流套接字 |
| SOCK_DGRAM | 数据报套接字 |
| SOCK_RAW | 原始套接字 |
protocol取值有下面这些:
| type | 说明 |
|---|---|
| IPPROTO_TCP | TCP传输协议 |
| IPPROTO_UDP | UDP传输协议 |
通常来说我们指定了domain,type的话,protocol=0的话那么就会自动选择使用具体的传输协议了。
2.3. connect
建立客户端和服务端的连接。
2.3.1. 使用说明
//#include <sys/socket.h> /* Open a connection on socket FD to peer at ADDR (which LEN bytes long). For connectionless socket types, just set the default address to send to and the only address from which to accept transmissions. Return 0 on success, -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern int connect (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len);
对于addr这个参数就是套接字地址结构,len表示这个套接字地址结构长度。
客户端在调用connect之前不比一定需要进行bind.如果没有进行bind的话,那么内核会确定源IP地址同时选择一个临时端口进行通信。 如果是TCP协议的话,那么客户端会会开始进行三次握手。从TCP状态迁移图可以看到,如果connect之后会进入SYN_SENT状态, 如果失败的话那么是不可用的,必须首先close然后重新socket.
2.3.2. 非阻塞
默认情况下connect是阻塞版本,直到对端的ACK响应之后才返回。但是如果客户端需要尝试多个连接的话并且顺序阻塞连接的话, 那么最后一个connect必须等待前面所有链接建立好。我们可以使用非阻塞来解决这个问题。或者我们可以使用多线程方案解决。
对于非阻塞的connect版本如果没有立刻返回的话,那么返回EINPROGRESS错误但是三次握手依然进行,但是我们必须处理立刻连接 上的情况,因为对于本地网络的话很可能立刻就连接上。通常完成之后我们使用IO复用来监听,如果connect成功连接的话那么描述符 变成可写状态,如果出现错误的话那么变成可读可写状态。
2.3.3. 三次握手
[dirlt@localhost.localdomain]$ ./connect -b 44567 61.135.169.105 80 bind (0.0.0.0:44557) connect (61.135.169.105,80)... connect succeed
使用tcpdump观察结果是
//tcpdump tcp port 44567 -ttt 00:00:00.000000 IP 192.168.189.128.44567 > 61.135.169.105.http: Flags [S], seq 4248773398, win 5840, options [mss 1460,sackOK,TS val 30454000 ecr 0,nop,wscale 4], length 0 00:00:00.006770 IP 61.135.169.105.http > 192.168.189.128.44567: Flags [S.], seq 127082468, ack 4248773399, win 64240, options [mss 1460], length 0 00:00:00.000057 IP 192.168.189.128.44567 > 61.135.169.105.http: Flags [.], ack 1, win 5840, length 0 00:00:00.000537 IP 192.168.189.128.44567 > 61.135.169.105.http: Flags [F.], seq 1, ack 1, win 5840, length 0 00:00:00.000212 IP 61.135.169.105.http > 192.168.189.128.44567: Flags [.], ack 2, win 64239, length 0
2.3.4. ETIMEOUT
如果SYN分节发给一个在路由器中存在表项,但是已经没有运行主机的话,没有得到SYN的ACK分节,就会返回ETIMEOUT的错误。
[dirlt@localhost.localdomain]$ ./connect -b 44567 192.168.189.1 80 bind (0.0.0.0:44567) connect (192.168.189.1,80)... connect failed:Connection timed out
使用tcpdump观察结果是
//tcpdump tcp port 44567 -ttt 00:00:00.000000 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30204841 ecr 0,nop,wscale 4], length 0 00:00:03.000471 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30207841 ecr 0,nop,wscale 4], length 0 00:00:05.999875 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30213841 ecr 0,nop,wscale 4], length 0 00:00:11.999685 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30225841 ecr 0,nop,wscale 4], length 0 00:00:24.000321 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30249841 ecr 0,nop,wscale 4], length 0 00:00:48.000312 IP 192.168.189.128.44567 > 192.168.189.1.http: Flags [S], seq 342722628, win 5840, options [mss 1460,sackOK,TS val 30297841 ecr 0,nop,wscale 4], length 0
可以看到分别在3,8(3+5),19(3+5+11),43(3+5+11+24),91(3+5+11+24+48)s之后5次尝试发送SYN分节。
2.3.5. ECONNREFUSED
如果SYN分节发给一个在路由器中存在表项并且主机存在,但是主机端口并没有提供服务的话,返回RST分节,那么就会返回ECONNREFUSED的错误。 我们这里使用本地主机ip,然后访问端口1,这个服务肯定是不存在的。
[dirlt@localhost.localdomain]$ ./connect -b 44567 192.168.189.128 1 bind (0.0.0.0:44567) connect (192.168.189.128,1)... connect failed:Connection refused
使用tcpdump观察结果是
//tcpdump tcp port 44567 -ttt -i lo.因为这里走的是loopback接口 00:00:00.000000 IP 192.168.189.128.44567 > 192.168.189.128.tcpmux: Flags [S], seq 1074623492, win 32792, options [mss 16396,sackOK,TS val 36551959 ecr 0,nop,wscale 4], length 0 00:00:00.000031 IP 192.168.189.128.tcpmux > 192.168.189.128.44567: Flags [R.], seq 0, ack 1074623493, win 0, length 0
可以看到返回的是一个RST分节。
2.3.6. ENETUNREACH
如果SYN分节发给一个不在路由器表中的表项的话,那么就回返回ENETUNREACH的错误。路由器会返回ICMP错误"destination unreachable",然后客户端内核接收到之后, 依然会尝试继续发送SYN分节,直到超过一定次数之后就会停止然后返回ENERUNREACH错误。但是也有另外两种情况,一种是按照本地系统转发表根本没有到达 远程路径,那么久会直接返回错误,另外一种情况是connect不等待完成就返回。
[dirlt@localhost.localdomain]$ ./connect -b 44567 192.168.189.0 1 bind (0.0.0.0:44567) connect (192.168.189.0,1)... connect failed:Network is unreachable
使用tcpdump没有任何结果,因为本地路由表没有这个路由表项
[root@localhost dirlt]# /sbin/route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.189.0 * 255.255.255.0 U 0 0 0 eth1 link-local * 255.255.0.0 U 0 0 0 eth1 default 192.168.189.2 0.0.0.0 UG 0 0 0 eth1
#todo: 如何复现一个主机不可达的错误???
2.3.7. EADDRINUSE
Local address is already in use.
发生这种情况通常是本地可用的port都使用完。可以通过下面这些办法解决:
- 修改本地可用的port数量
- 加快回收处于TIME_WAIT连接
- 安全复用处于TIME_WAIT连接
2.4. bind
将套接字和一个本地协议地址进行绑定。
//#include <sys/socket.h> /* Give the socket FD the local address ADDR (which is LEN bytes long). */ extern int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len) __THROW;
第一个参数就是待绑定的套接字,第二个参数是套接字地址,第三个参数是套接字地址长度。 因为我们最常用的协议还是IP包括IPv4和IPv6,所以套接字地址就涉及到IP和port这两个字段的设置。 如果IP选择通配地址的话,那么内核自己选择IP地址,否则就是进程指定。对于port来说如果port==0 的话,那么内核自己选择port,否则是进程指定port.
对于IP的通配地址,IPv4使用INADDR_ANY,而IPv6使用in6addr_any.
//#include <netinet/in.h> /* Address to accept any incoming messages. */ #define INADDR_ANY ((in_addr_t) 0x00000000) /* Address to loopback in software to local host. */ #ifndef INADDR_LOOPBACK # define INADDR_LOOPBACK ((in_addr_t) 0x7f000001) /* Inet 127.0.0.1. */ #endif extern const struct in6_addr in6addr_any; /* :: */ extern const struct in6_addr in6addr_loopback; /* ::1 */ #define IN6ADDR_ANY_INIT { { { 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 } } } #define IN6ADDR_LOOPBACK_INIT { { { 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1 } } }
2.5. listen
将主动套接字设置成为被动套接字。
2.5.1. 使用说明
//#include <sys/socket.h> /* Prepare to accept connections on socket FD. N connection requests will be queued before further requests are refused. Returns 0 on success, -1 for errors. */ extern int listen (int __fd, int __n) __THROW;
对于socket创建套接字来说,假设设置成为了一个主动套接字可以立刻进行连接。listen函数 将主动套接字设置成为被动套接字,指示内核应该接受指向该套接字的连接请求。对于TCP状态转换来说, 是从CLOSED状态变成LISTEN状态。
2.5.2. backlog
变为被动状态之后,服务端等待客户端进行connnect(发送SYN分节).从收到SYN分节,到被accept进行处理 这段过程中连接上的客户端,服务端是需要保存这些连接的。服务端需要将这些连接保存在一个队列内部, 这个队列内部包括的连接状态分别是:
- 接收到SYN分节,返回了ACK分节和自己的SYN分节。连接处于SYN_RCVD状态。incomplete queue.
- 三次握手完成,等到accept进行处理。连接处理ESTABLELISHED状态。complete queue.
在队列里面并没有分配fd,只是保存了连接的状态,直到accept之后才正式分配fd.至于这个队列的长度,就是 listen调用里面第二个参数n的含义,通常我们称为backlog.但是对于这个解释是历史上BSD的解释。
但是在linux系统下面,backlog的值修改成为了已经完成三次握手但没有accept的队列长度(complete queue)。 而SYN_RCVD队列长度(incomplete queue)是/proc/sys/net/ipv4/tcp_max_syn_backlog里面存放的值。这样修改区分开来是存在原因的。 假设backlog是两个队列长度上限的话,那么是不能够有效抵御SYN flood攻击的。SYN flood攻击就是客户端直接伪造IP数据报, 只是发送一个SYN分节之后然后立刻断掉,这样服务端在超时时间内维护这样的连接,如果客户端发送过多的这样的数据报的话, 那么服务端将不能够正常地接受新的连接,最终拒接服务(denial of service).
这里值得看一个问题,就是如果客户端SYN分节到达的时候,如果服务端incomplete queue已经满的时候,是否应该返回 RST分节还是不回复ACK分节,而让客户端进行重传。对于manpage理解解释两种返回情况都是可以接受的,所以在应用层必须区分。 但是实际上更好的做好还是让客户端重传,因为如果响应RST分节的话那么客户端没有办法区分,是因为服务端没有开启对应的服务, 还是因为incomplete queue已满这两种情况。并且实际上,客户端可能稍微重传等待一段时间,服务端incomplete queue部分连接 应经建立起来了,客户端就可以被处理了。
2.6. accept
处理已经建立好的连接。
2.6.1. 使用说明
//#include <sys/socket.h> This function is a cancellation point and therefore not marked with __THROW. */ extern int accept (int __fd, __SOCKADDR_ARG __addr, socklen_t *__restrict __addr_len);
这里的fd就是之前listen处理被动状态的监听套接字,addr和addr_len表示处理连接的客户端地址。返回值表示 连接的套接字。使用这个套接字可以和连接上的客户端进行通信。我们需要提供fd的原因可能是因为,底层tcp实现的话, 是不同的fd对应不用的处理队列,所以必须提供fd来查找到相应的处理队列,然后从队列中取出一个可以处理的连接。
2.6.2. 惊群效应(thundering herd)
如果服务端的模型是首先派生出很多线程或者是进程,然后每个线程或者是进程分别调用accept的话。如果一个连接 建立完成并且可用的话,那么操作系统通常会唤起所有线程或者是进程,但是最终结果只有一个accept成功。 这个代价是巨大的,因为会造成很多不必要的线程或者是进程切换。解决这个问题可以从用户态进行加锁处理,这样 可以在用户态规定处理顺序,同时避免了没有必要的系统调用以及带来的线程和进程切换。
2.6.3. 非阻塞
默认情况下面accept是阻塞版本,直到连接三次握手完成进入complete queue并且被取出才返回。如果我们使用非阻塞版本的话, 那么accept就会立刻返回。和非阻塞情况一样我们也必须处理accept立刻返回的情况,如果没有可用连接的话返回EWOULDBLOCK/EAGAIN 错误。之后可以使用IO复用来检测accept是否有新连接,如果有新连接的话那么fd变成可读状态。非阻塞和阻塞accept相同, 也必须考虑ECONNABORTED这样的错误。
2.6.4. ECONNABORTED/EPROTO
建立连接完成之后但是在accept之前,如果客户端取消连接发送RST分节的话,那么accept得到的就不是一个有效套接字了。 系统可以选择在accept内部完成这个操作,也可以返回错误交给用户来完成。POSIX规定是返回ECONNABORTED错误(BSD返回EPROTO),然后 在应用层上可以进行忽略然后进行下一次accept.我们可以模拟这个情况,如果设置了套接字SO_LINGER的话,并且linger_time为0的时候, 那么在关闭时候并不会发送FIN分节而是直接发送RST分节。
[dirlt@localhost.localdomain]$ ./connect -l -b 44568 127.0.0.1 44567 setsockopt SO_LINGER bind (0.0.0.0:44568) connect 127.0.0.1:44567 ... connect succeed
[dirlt@localhost.localdomain]$ ./server -d 10 44567 bind (0.0.0.0:44567) listen 5 accept ... client (127.0.0.1:44568) accept ...
似乎并没有返回ECONNABORTED的错误,而且这个连接正常返回了。然后我们看看tcpdump结果
00:00:00.000000 IP localhost.localdomain.44568 > localhost.localdomain.44567: Flags [S], seq 1612964784, win 32792, options [mss 16396,sackOK,TS val 86983449 ecr 0,nop,wscale 4], length 0 00:00:00.000158 IP localhost.localdomain.44567 > localhost.localdomain.44568: Flags [S.], seq 1610609404, ack 1612964785, win 32768, options [mss 16396,sackOK,TS val 86983449 ecr 86983449,nop,wscale 4], length 0 00:00:00.000050 IP localhost.localdomain.44568 > localhost.localdomain.44567: Flags [.], ack 1, win 2050, options [nop,nop,TS val 86983449 ecr 86983449], length 0 00:00:00.002227 IP localhost.localdomain.44568 > localhost.localdomain.44567: Flags [R.], seq 1, ack 1, win 2050, options [nop,nop,TS val 86983451 ecr 86983449], length 0
可以看到三次握手之后确实发送了RST分节。
2.6.5. EPIPE
我们继续从上面情况分析下来,假设连接已经断开,而如果我们读写的话那么会是什么情况呢?
[dirlt@localhost.localdomain]$ ./connect -l -b 44568 127.0.0.1 44567 setsockopt SO_LINGER bind (0.0.0.0:44568) connect 127.0.0.1:44567 ... connect succeed
[dirlt@localhost.localdomain]$ ./server -d 10 -h 44567 usage:./server [-r] [-d delay] [-b ip] [-c] port [dirlt@localhost.localdomain]$ ./server -c 44567 bind (0.0.0.0:44567) listen 5 accept ... client (127.0.0.1:44568) read failed:Connection reset by peer caught signal:Broken pipe write failed:Broken pipe accept ...
可以看到读取的话返回-1出现错误(reset by peer),而写的话会提示broken pipe错误码是EPIPE.EPIPE表示管道断开, 通常还会触发一个信号SIGPIPE,默认情况是使得程序退出。对于服务端来说的话我们不希望这样的默认行为, 所以通常情况下面我们设置SIGPIPE为我们自定义行为。
2.7. close/shutdown
关闭建立好的连接
//#include <unistd.h> /* Close the file descriptor FD. This function is a cancellation point and therefore not marked with __THROW. */ extern int close (int __fd); //#include <sys/socket.h> /* Shut down all or part of the connection open on socket FD. HOW determines what to shut down: SHUT_RD = No more receptions; SHUT_WR = No more transmissions; SHUT_RDWR = No more receptions or transmissions. Returns 0 on success, -1 for errors. */ extern int shutdown (int __fd, int __how) __THROW;
对于close和shutdown区别是这样的,close会做引用计数,而shutdown是close引用计数==0的时候的真实操作(SHUT_RDWR). 并且可以看到close是全关闭,而shutdown可以完成半关闭。SHUT_RDWR就相当于调用一次SHUT_RD和SHUT_WR.
SHUT_RD能够关闭读半部,执行这个部分不会发送任何分节,而kernel内部会将已经接收到的所有数据都全部丢弃,继续read 这个fd的话都是返回0.而如果对端继续发送数据的话都会被无条件地确认。SHUT_WR能够关闭写半部,执行这个部分会发送FIN分节, 而原来kernel内部维持的数据会首先全部发送出去,继续write这个fd的话会产生EPIPE错误。半关闭在有些情况下面是必要的, 如果没有半关闭的话,那么应用层必须使用一些其他技术或者是协议来通知对端,自己已经将数据发送完毕。
[dirlt@localhost.localdomain]$ ./connect -H -b 44567 119.75.218.45 80 bind (0.0.0.0:44567) connect 119.75.218.45:80 ... connect succeed read succeed=0 caught signal:Broken pipe write failed:Broken pipe
2.8. getsockname/getpeername
#todo:
2.9. option
2.9.1. 概览
对于套接字选项的获取和设置,我们最常用的函数包括:
- getsockopt/setsockopt.
- fcntl.
- ioctl.
本节讨论的所有选项都是通过getsockopt/setsockopt来操作的,对于fcntl/ioctl会在其他地方进行讨论。
//#include <sys/socket.h> /* Put the current value for socket FD's option OPTNAME at protocol level LEVEL into OPTVAL (which is *OPTLEN bytes long), and set *OPTLEN to the value's actual length. Returns 0 on success, -1 for errors. */ extern int getsockopt (int __fd, int __level, int __optname, void *__restrict __optval, socklen_t *__restrict __optlen) __THROW; /* Set socket FD's option OPTNAME at protocol level LEVEL to *OPTVAL (which is OPTLEN bytes long). Returns 0 on success, -1 for errors. */ extern int setsockopt (int __fd, int __level, int __optname, __const void *__optval, socklen_t __optlen) __THROW;
首先列出我们本节讨论的选项有哪些,然后在每个子章节单独介绍。
| level | optname | 说明 | 数据类型 |
|---|---|---|---|
| SOL_SOCKET | SO_ERROR | 获取待处理错误并且清楚 | int |
| SO_KEEPALIVE | 周期性测试连接是否仍然存活 | int | |
| SO_LINGER | 若有数据待发延迟关闭 | linger{} | |
| SO_RCVBUF | 接收缓冲区大小 | int | |
| SO_SNDBUF | 发送缓冲区大小 | int | |
| SO_RCVLOWAT | 接收缓冲区低水位标记 | int | |
| SO_SNDLOWAT | 发送缓冲区低水位标记 | int | |
| SO_RCVTIMEO | 接收超时 | timeval | |
| SO_SNDTIMEO | 发送超时 | timeval | |
| SO_REUSEADDR | 允许重用本地地址 | int | |
| IPPROTO_TCP | TCP_MAXSEG | TCP最大分片大小 | int |
| TCP_NODELAY | 禁止nagle算法 | int | |
| TCP_QUICKACK | 快速ACK算法 | int | |
| TCP_CORK | 阻塞TCP发送 | int |
我们可以使用viewsockopt.cc来查看这些选项的默认值。
[dirlt@localhost.localdomain]$ ./viewsockopt SO_ERROR:0 SO_KEEPALIVE:off SO_LINGER:l_onoff=off,l_linger=0 SO_RCVBUF:87380 SO_SNDBUF:16384 SO_RCVLOWAT:1 SO_SNDLOWAT:1 SO_RCVTIMEO:(0,0) SO_SNDTIMEO:(0,0) SO_REUSEADDR:off TCP_MAXSEG:536 TCP_NODELAY:off TCP_QUICKACK:on TCP_CORK:off
2.9.2. SO_ERROR
当一个套接字发生错误时,那么协议模块内部so_error会被设置成为Exx错误码,我们称它为套接字的待处理错误(pending error). 内核能够以下面两种方式之一立刻通知进程这个错误:
- IO复用通知可读可写
- 信号驱动IO发起SIGIO信号
通知之后我们可以使用getsockopt来获取这个错误,也可以直接进行读写然后来得到这个错误,然后so_error清零。 如果使用读写来获得这个错误的话,如果有数据进行读写的话那么正常进行,如果没有的话那么返回-1,并且errno会被置为so_error。 对于读取的话如果是正常关闭连接的话,那么read返回为0,如果为异常关闭比如RST分节的话,那么会返回对应的错误。 这个选项只允许获取而不允许修改。
2.9.3. SO_KEEPALIVE
客户端连接服务端之后如果客户端宕机的话,服务端不知道客户端已经宕机继续维持连接,我们称这种情况为半开连接(half-open connection). 如果服务端不检测出半开连接的话那么就会维持连接最终耗尽资源。当然在应用层服务端可自己来进行这个保活(keepalive)机制的实现, 但是TCP内部也自带这样的机制。如果设置了这个选项的话,一段时间内套接字任一方向没有数据交换的话,那么TCP会自动给对端发送 保持存活探测分节(keep-alive probe),这个分节对端必须相应,结果会有三种情况:
- 响应ACK,对端存活
- 响应RST,对端可能已经崩溃重启,so_error置为ECONNRESET.
- 对端没有响应,那么按照TCP重传机制重传,最终错误可能为ETIMEOUT(超时),ENETUNREACH(路由错误).
如果产生错误的话,如果我们使用IO复用/信号驱动IO的话,我们是可以立刻检测到的并且进行响应处理。
2.9.4. SO_LINGER
默认情况下面,close的动作是发送完成缓冲区内数据,并且发送FIN分节之后立即返回。返回之后如果数据或者是FIN分节没有确认的话, 那么tcp实现会自动进行重传,但是如果重传失败的话,我们也是没有办法知道的。使用SO_LINGER选项可以在一定长度上解决这个问题。 SO_LINGER使用的值是下面这个类型,如果l_onoff=0的话,那么就是按照默认情况处理。下面我们讨论l_onoff=1的情况。
//#include <bits/socket.h> /* Structure used to manipulate the SO_LINGER option. */ struct linger { int l_onoff; /* Nonzero to linger on close. */ int l_linger; /* Time to linger. */ };
如果l_linger==0的话,那么close会立刻丢弃缓冲区内部数据并且发送RST分节断开连接立即返回,而不是走正常的断开连接过程。 这样可以避免TIME_WAIT状态。但是实际上我们并不推荐这么使用,因为这样如果还没有发出数据的话都会被丢弃, 而且对端会认为本端可能是因为状态出错等其他原因断开连接,而非主动断开。
如果l_linger!=0的话,那么close会等待l_linger(单位s)的时间或者是等待到最后数据和FIN的ACK返回为止。不过如果close 设置称为非阻塞的话,那么还是会立刻返回。如果close返回的原因,是因为等待到了最后的数据和FIN的ACK的话,那么返回值为0, 否则返回-1,errno=EWOULDBLOCK.所以这里可以认为l_linger是一个超时时间,在这么长时间内等待剩余数据和FIN的确认。这样的话, 我们可以在一定程度了解到最后断开的情况。
2.9.5. SO_RCVBUF/SO_SNDBUF
每个套接字都有一个发送缓冲区和接收缓冲区。对于TCP来说,接收缓冲区的大小在每次交互过程中都会传递,告诉发送端自己空闲缓冲区多少, 这样发送端可以个根据接收端缓冲区大小来控制发送速度,而不会出现发送端发送过快而接收端处理不过来,导致不断地重传数据。 而对于发送缓冲区来说如果kernel buffer没有空闲空间的话,那么write将会阻塞或者是返回EAGAIN的错误。对于UDP来说问题相对简单一些, 如果接收缓冲区过小的话,如果发送端发送过快就直接丢弃数据包,而发送端缓冲区大小是为了限制一次发送数据报大小的,因为只要每次 写操作的话,那么kernel buffer立刻丢入网卡发送队列中了。因为UDP相对来说概念简单一些,所以我们这里主要考虑TCP方面的东西。
首先我们考虑设置这个选项时机,因为TCP的窗口规模选项是在建立连接时候使用SYN分节相互交换得到的,所以对于客户端来说必须在connect 之前设置,而服务端必须在listen之前设置。其次设置套接字缓冲区大小的时候必须考虑性能问题,通常来说管道的容量应该带宽*延迟, 在我们设置缓冲区大小的时候,需要考虑管道的容量。如果管道容量越大的话,那么我们设置的缓冲区大小也必须越大。如果管道容量很大 缓冲区大小也很大的话,那么TCP层必须允许交换这么大的窗口大小,这就是TCP的长胖管道特征(long fat pipe).
#note: 设置了缓冲区大小的话,但是取出来似乎不是设置的值。并且通过tcpdump观察的话,似乎窗口并没有什么变化。 每次交换窗口大小和设置的没有任何关系。
2.9.6. SO_RCVTIMEO/SO_SNDTIMEO
可以设置针对这个套接字的读写超时,影响的函数包括:
- read/write
- readv/writev
- recv/send
- recvfrom/sendto
- recvmsg/sendmsg
设置超时的结构是struct timeval.
2.9.7. SO_REUSEADDR
使用SO_REUSEADDR选项的话那么允许监听(被动打开)的套接字绑定在一个正在被使用的端口上。使用这个选项必须在 socket和bind之间调用。但是这里有一个问题,就是这个检查是在什么时候进行的。我们使用connect.cc进行两次正常连接:
[dirlt@localhost.localdomain]$ ./connect -b 44567 119.75.217.56 80 bind (0.0.0.0:44567) connect 119.75.217.56:80 ... connect succeed [dirlt@localhost.localdomain]$ ./connect -b 44567 119.75.217.56 80 bind (0.0.0.0:44567) bind failed:Address already in use
可以看到在bind就出现错误。如果我们使用这个选项的话,在socket之后系统并不知道我们是被动打开的话, 那么bind没有问题,但是在connect时候就会出现问题,因为这样会造成两个连接出现:
[dirlt@localhost.localdomain]$ ./connect -r -b 44568 119.75.217.56 80 setsockopt SO_REUSEADDR bind (0.0.0.0:44568) connect 119.75.217.56:80 ... connect succeed [dirlt@localhost.localdomain]$ ./connect -r -b 44568 119.75.217.56 80 setsockopt SO_REUSEADDR bind (0.0.0.0:44568) connect 119.75.217.56:80 ... connect failed:Cannot assign requested address
对于服务器来说,如果我们使用派生子进程来处理连接的话,而服务器需要重启的话,如果不使用这个选项会存在问题。 因为服务器关闭之后,子进程的连接依然被使用着,使用netstat可以看到端口依然被使用。如果服务器重启需要重新绑定 这个端口的话那么就会出问题。
另外一种情况是在同一个端口上面启动多个服务器实例,比如我们主机有双网卡两个ip分别是x,y.使用这个选项的话,允许 我们分别使用(x,z),(y,z)来启动两个服务器实例。但是需要注意的是,只要使用了任何一个可用ip的话那么就不允许使用 通配地址,如果使用通配地址的话那么就不允许绑定特定ip.
[dirlt@localhost.localdomain]$ ./server -b 127.0.0.1 44567 bind (127.0.0.1:44567) listen 5 accept ... [dirlt@localhost.localdomain]$ ./server -b 192.168.189.128 44567 bind (192.168.189.128:44567) listen 5 accept ... [dirlt@localhost.localdomain]$ ./server 44567 bind (0.0.0.0:44567) bind failed:Address already in use
如果我们首先绑定通配地址先的话
[dirlt@localhost.localdomain]$ ./server 44567 bind (0.0.0.0:44567) listen 5 accept ... [dirlt@localhost.localdomain]$ ./server -b 127.0.0.1 44567 bind (127.0.0.1:44567) bind failed:Address already in use [dirlt@localhost.localdomain]$ ./server -b 192.168.189.128 44567 bind (192.168.189.128:44567) bind failed:Address already in use
2.9.8. TCP_MAXSEG
这个选项允许我们获取和设置TCP连接的最大分节大小(MSS).TCP连接建立之前双方就会交换各自的MSS,然后选择最小的MSS 作为本次连接的MSS,为的就是尽可能地减少分片。在TCP建立之前,使用TCP_MAXSEG获得的MSS是系统默认值(虽然我们系统默认值为 536,但是实际发送的mss还是1460,这点可以从tcpdump中观察到),建立之后的MSS是双方较小的MSS.之前说过,MSS取决于路径MTU, 如果路由发生变化的话造成路径MTU发生变化的话,那么MSS可能发生改变。
#todo: TCP_MAXSEG默认值是536,但是实际连接发现交换还是按照1460来进行交换。以及如何侦测路径MTU.
#note: 路径MTU发现实现上并不复杂,原理上说只需要在IP首部加上DF标记(donnot-fragment不要分片),然后按照一个小的MTU对应MSS进行传输。 如果路径上MTU小于这次传输数据的话,那么会返回一个ICMP错误。原理上通过这种反馈的方式就可以得到路径MTU.但是因为路径MTU取决于IP报文路由选择的路径 ,所以这是一个动态变化值,路径MTU也必须不断地进行修改和调整。
2.9.9. TCP_NODELAY
开启本选项将禁止Nagel算法,默认情况下面是使用Nagel算法。使用Nagel算法效果是数据并不会立即发送,而是等待到一定大小的时候 才会进行发送,这样可以减少分组。通过减少传输分组的数目,防止一个连接在任何时刻存在多个小分组确认。这点对于广域网网络环境 非常合适,能够有效地利用网络。
#todo: 减少网络上分组有什么好处?和所处的网络状况是否相关?
#note: 减少网络拥塞。通常是因为网络上分组非常多造成的,一旦出现网络拥塞的话那么丢包概率就会上升。在广域网下面丢包重传代价是非常大的, 所以都会尽可能地减少网络分组来提高在广域网下面传输效率。
如果只是在广域网情况下,考虑综合考虑网络情况并且有效利用的话,那么Nagel确实很好。但是如果从应用角度出发,如果是交互式应用程序, 或者是涉及到局域网传输的话,那么Nagel并不适合。对于交互式应用程序希望尽快地响应,而在局域网内传输质量非常好,没有必要来减少分组的数目, 相反快速和实时性才是最主要的。
2.9.10. TCP_QUICKACK
quick ACK是相对于delay ACK来说的。delay ACK算法就是说,接收到数据之后我并不回复ACK,而是我假设我可能也要发送数据,发送这个数据时候我捎带ACK回去, 如果在某段时间内没有数据的话,那我才响应ACK.问题就是说,如果我没有数据要发送的话,那么必须等待一段时间之后才会返回ACK.通常使用nagel算法的话都会 使用delay ACK算法,因为这样可以减少网络上面的分组传输。而quick ACK接收到数据之后就尽快回复ACK.
和TCP_NODELAY的状况相同,如果是局域网或者是交互式应用程序的话,网络情况良好或者是要求比较高的实时性的时候,那么delay ACK算法就不适合了。 使用这个选项可以使用quick ACK而不实用delay ACK算法。通常来说使用TCP_NODELAY的话也使用TCP_QUICKACK.绝大部分实现采用的延迟是200ms,但是这个对于 局域网下面应用程序来说肯定是不能够忍受的。
2.9.11. TCP_CORK
这个选项是使用nagel算法的一个扩展,所以不可以和TCP_NODELAY来配合使用。nagel算法会等待数据到达一定程度之后然后发送,但是对于这个程度我们不可以控制。 而使用TCP_CORK这个选项是可以控制的。我们首先设置TCP_CORK,然后就可以往tcp kernel buffer里面write数据,但是这个时候并不直接发送,而是等到我们clear TCP_CORK 这个标记之后才会发送。不过man 7 tcp里面也提到在实现的时候,如果内部存在数据但是200ms没有发送的话,那么就会自动发送。
2.10. IO
对于模型的解释,我们假设情况是read(buf,x)和write(buf,x).
2.10.1. 阻塞IO(blocking IO)
这个是最流行的IO模型,默认情形下面所有的套接字都是阻塞的。read(buf,x)行为是:
- 用户调用read(buf,x)阻塞
- 系统调用sysread
- 如果kernel_buffer没有数据的话,那么一直阻塞直到有数据产生为止。
- 当有数据产生假设y个字节的话,z=y>x?x:y,然后memcopy(buf,kernel_buffer,z)
- 系统调用sysread返回,读取z个字节。
- 用户调用read(buf,x)返回
而write(x)行为是:
- 用户调用write(buf,x)阻塞
- 系统调用syswrite
- 如果kernel buffer没有空间的话,那么一直阻塞直到有空间为止。
- 假设有y个字节的可用空间,z=y>x?x:y,然后memcopy(kernel_buffer,buf,z)
- 系统调用sywrite返回,写入z个字节。
- 用户调用write(buf,x)返回
2.10.2. 非阻塞IO(nonblocking IO)
非阻塞IO和阻塞IO执行逻辑上非常相似,只不过在等待数据/空间时候逻辑稍有不同。read(buf,x)行为是:
- 用户调用read(buf,x)阻塞
- 系统调用sysread
- 如果kernel_buffer没有数据的话,那么返回EWOULDBLOCK/EAGAIN.
- 当有数据产生假设y个字节的话,z=y>x?x:y,然后memcopy(buf,kernel_buffer,z)
- 系统调用sysread返回,读取z个字节。
- 用户调用read(buf,x)返回
而write(x)行为是:
- 用户调用write(buf,x)阻塞
- 系统调用syswrite
- 如果kernel buffer没有空间的话,那么返回EWOULDBLOCK/EAGAIN.
- 假设有y个字节的可用空间,z=y>x?x:y,然后memcopy(kernel_buffer,buf,z)
- 系统调用sywrite返回,写入z个字节。
- 用户调用write(buf,x)返回
然后上层进行轮询检查是否有数据可读或者是空间可用。
设置非阻塞IO的话可以使用如下代码:
int flags=fcntl(fd,F_GETFL,0); flags |= O_NONBLOCK; fcntl(fd,F_SETFL,flags);
2.10.3. IO复用(IO multiplexing)
对于单路的情况,那么阻塞或者是非阻塞就足够使用了。但是如果是多路IO的话,如果我们使用阻塞方式的话那么必须按照某个数据到来的顺序 阻塞调用,而如果使用非阻塞的话那么必须显示地轮询每路IO.IO复用解决的就是这么一个问题,能够监听多路IO的状态,直到某路或者是多路 状态变成可读或者是可写的话才返回。IO复用和底层每路的IO是否处于阻塞或者是非阻塞状态无关,对应于应用层来说,见到的都是一样的模型。 多路等待或者是轮询时间都让系统来进行托管,而不是在用户态处理。
- select/pselect
//#include <bits/time.h> /* A time value that is accurate to the nearest microsecond but also has a range of years. */ struct timeval { __time_t tv_sec; /* Seconds. */ __suseconds_t tv_usec; /* Microseconds. */ }; //#include <sys/select.h> /* fd_set for select and pselect. */ typedef struct { /* XPG4.2 requires this member name. Otherwise avoid the name from the global namespace. */ #ifdef __USE_XOPEN __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; # define __FDS_BITS(set) ((set)->fds_bits) #else __fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS]; # define __FDS_BITS(set) ((set)->__fds_bits) #endif } fd_set; /* Maximum number of file descriptors in `fd_set'. */ #define FD_SETSIZE __FD_SETSIZE /* Access macros for `fd_set'. */ #define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp) #define FD_CLR(fd, fdsetp) __FD_CLR (fd, fdsetp) #define FD_ISSET(fd, fdsetp) __FD_ISSET (fd, fdsetp) #define FD_ZERO(fdsetp) __FD_ZERO (fdsetp) /* Check the first NFDS descriptors each in READFDS (if not NULL) for read readiness, in WRITEFDS (if not NULL) for write readiness, and in EXCEPTFDS (if not NULL) for exceptional conditions. If TIMEOUT is not NULL, time out after waiting the interval specified therein. Returns the number of ready descriptors, or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern int select (int __nfds, fd_set *__restrict __readfds, fd_set *__restrict __writefds, fd_set *__restrict __exceptfds, struct timeval *__restrict __timeout); This function is a cancellation point and therefore not marked with __THROW. */ extern int pselect (int __nfds, fd_set *__restrict __readfds, fd_set *__restrict __writefds, fd_set *__restrict __exceptfds, const struct timespec *__restrict __timeout, const __sigset_t *__restrict __sigmask);
其中nfds应该是我们关心到的最高fd+1,read_fds表示我们关心读状态变化的fd有哪些,write_fds表示关心写状态, except_fds表示关心异常状态。timeout表示等待超时的时间(us)。对于fd_set的话表示文件描述符集合,提供了一系列 FD_xxx操作来操作这个集合。对于这些集合必须每次都重新设置,因为每次select返回之后集合状态都有可能改变。 至于pselect提供了在等待期间屏蔽一些信号的功能,基本功能和select相同。
这里面我们最关心的还是什么才算是读状态变化(可读),写状态发生变化(可写)以及异常状态的出现(异常)。
条件 可读 可写 异常 有数据可读 Y 对端写连接关闭 Y 有新连接建立好可以accept Y 有空间可写 Y 对端读连接关闭 Y 非阻塞connect连接成功或失败 Y 待处理错误 Y Y TCP带外数据 Y 这里待处理错误是指,如果连接上出现套接字错误的话,我们通常可以使用getsockopt的SO_ERROR选项获得。 而如果使用select的话,那么会返回。然后read/write的话会返回-1,并且将errno置为这个错误,方便我们进行处理。 因为TCP带外数据基本都不进行使用了,所以就不详细说而来。
这里我们还必须明确清楚另外一个问题,那就是什么称为数据可读以及有空间可写。直觉上我们认为只要kernel buffer 有1字节数据和1字节空间就算,但是对于socket来说或可以设置这个阈值,分别是SO_RCVLOWAT和SO_SNDLOWAT这个两个阈值。 对于UDP来说没有这个问题,只要UDP发送缓冲区和接受缓冲区大于这阈值的话,那么总是可读和可写的。对于kernel buffer 大小,就是发送缓冲区和接收缓冲区大小,也可以通过SO_SNDBUF和SO_RCVBUF来设置。
select存在限制,那就是FD_SETSIZE这个大小。通常来说这个值是1024,但是对于高并发的网络服务器肯定是不能够满足的。 调整这个大小需要重新编译内核。并且存在一个问题,select内部是使用线性算法来扫描集合是否有状态变化的,因此 就是调整FD_SETSIZE的话,性能也会出现问题。更好的方式就是使用epoll.这个可以在fs/select.c下面看到实现。
- poll/ppoll
//#include <sys/poll.h> /* Type used for the number of file descriptors. */ typedef unsigned long int nfds_t; /* Data structure describing a polling request. */ struct pollfd { int fd; /* File descriptor to poll. */ short int events; /* Types of events poller cares about. */ short int revents; /* Types of events that actually occurred. */ }; /* Poll the file descriptors described by the NFDS structures starting at FDS. If TIMEOUT is nonzero and not -1, allow TIMEOUT milliseconds for an event to occur; if TIMEOUT is -1, block until an event occurs. Returns the number of file descriptors with events, zero if timed out, or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout); /* Like poll, but before waiting the threads signal mask is replaced with that specified in the fourth parameter. For better usability, the timeout value is specified using a TIMESPEC object. This function is a cancellation point and therefore not marked with __THROW. */ extern int ppoll (struct pollfd *__fds, nfds_t __nfds, __const struct timespec *__timeout, __const __sigset_t *__ss);
poll解决了select一个问题就是检测fd集合大小的限制,但是没有解决select内部实现使用线性扫描的方式。 poll的超时时间单位是ms如果为负值的话那么就是永久等待。poll相对于select另外一个好处就是不需要每次都重新设置, 因为poll调用完成之后,事件状态都存放在了revents这个字段上,而events是我们关心事件字段这个没有发生改变。 我们可以在fs/select.c里面看到实现。
常数 作为events输入 作为revents结果 说明 POLLIN Y Y 普通或者是带外数据可读 POLLRDNORM Y Y 普通数据可读 POLLRDBAND Y Y 带外数据可读 POLLRDPRI Y Y 优先级数据可读 POLLOUT Y Y 普通数据可写 POLLWRNORM Y Y 普通数据可写 POLLWRBAND Y Y 带外数据可写 POLLERR Y 发生错误 POLLHUP Y 发生挂起 POLLNVAL Y 不是一个有效描述符 对于我们来说最常用的就是三个常数,POLLIN,POLLOUT,POLLERR.而可读和可写的定义可以认为和select基本一致。 所以最终我们可以认为,poll就是select另外接口。
2.10.4. 信号驱动IO(signal-driven IO)
信号驱动IO的方式是发送SIGIO信号来通知我们某个fd是可读或者是可写的。fd的阻塞等待或者是轮询都让系统来进行托管,而不是在用户态处理。
设置信号驱动IO的话可以使用如下代码:
//首先设置信号驱动,这样准备好之后会发送SIGIO信号 int flags=fcntl(fd,F_GETFL,0); flags |= O_ASYNC; fcntl(fd,F_SETFL,flags); //设置SIGIO信号属主 fcntl(fd,F_SETOWN,getpid());
2.10.5. 异步IO(asynchronous IO)
异步IO和阻塞IO是非常像的,只不过在调用read/write时候自己进行不阻塞,而让系统去托管整个等待,轮询以及读取,写入过程,完成之后 通知调用者这件事情已经操作完成(C++回调).对于read(x)和write(x)语义就需要稍加改变,可能是必须读取x个字节或者是必须写完x个字节。
2.10.6. 高级IO
- recv/send
//#include <sys/socket.h> /* Send N bytes of BUF to socket FD. Returns the number sent or -1. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t send (int __fd, __const void *__buf, size_t __n, int __flags); /* Read N bytes into BUF from socket FD. Returns the number read or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t recv (int __fd, void *__buf, size_t __n, int __flags); /* Send N bytes of BUF on socket FD to peer at address ADDR (which is ADDR_LEN bytes long). Returns the number sent, or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t sendto (int __fd, __const void *__buf, size_t __n, int __flags, __CONST_SOCKADDR_ARG __addr, socklen_t __addr_len); /* Read N bytes into BUF through socket FD. If ADDR is not NULL, fill in *ADDR_LEN bytes of it with tha address of the sender, and store the actual size of the address in *ADDR_LEN. Returns the number of bytes read or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t recvfrom (int __fd, void *__restrict __buf, size_t __n, int __flags, __SOCKADDR_ARG __addr, socklen_t *__restrict __addr_len);
recv/send界面上和write/read非常相似,不过多了一个flags参数。对我们比较有用的参数有下这些:
flags 说明 MSG_DONTWAIT 将阻塞IO临时修改为非阻塞读写,完成之后修改回来 MSG_PEEK 能够peek已经可读数据,读取之后不从缓冲区丢弃 MSG_WAITALL 阻塞直到请求数目数据可读的时候返回 - readv/writev
//#include <bits/uio.h> /* Structure for scatter/gather I/O. */ struct iovec { void *iov_base; /* Pointer to data. */ size_t iov_len; /* Length of data. */ }; //#include <sys/uio.h> /* Read data from file descriptor FD, and put the result in the buffers described by IOVEC, which is a vector of COUNT `struct iovec's. The buffers are filled in the order specified. Operates just like `read' (see <unistd.h>) except that data are put in IOVEC instead of a contiguous buffer. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t readv (int __fd, __const struct iovec *__iovec, int __count); /* Write data pointed by the buffers described by IOVEC, which is a vector of COUNT `struct iovec's, to file descriptor FD. The data is written in the order specified. Operates just like `write' (see <unistd.h>) except that the data are taken from IOVEC instead of a contiguous buffer. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t writev (int __fd, __const struct iovec *__iovec, int __count);
使用readv/writev能够将不连续的内存,调用一次系统完全读出/写入。
- recvmsg/sendmsg
这个函数可以说是最通用的IO函数了
//#include <bits/socket.h> /* Structure describing messages sent by `sendmsg' and received by `recvmsg'. */ struct msghdr { void *msg_name; /* Address to send to/receive from. */ socklen_t msg_namelen; /* Length of address data. */ struct iovec *msg_iov; /* Vector of data to send/receive into. */ size_t msg_iovlen; /* Number of elements in the vector. */ void *msg_control; /* Ancillary data (eg BSD filedesc passing). */ size_t msg_controllen; /* Ancillary data buffer length. !! The type should be socklen_t but the definition of the kernel is incompatible with this. */ int msg_flags; /* Flags on received message. */ }; /* Structure used for storage of ancillary data object information. */ struct cmsghdr { size_t cmsg_len; /* Length of data in cmsg_data plus length of cmsghdr structure. !! The type should be socklen_t but the definition of the kernel is incompatible with this. */ int cmsg_level; /* Originating protocol. */ int cmsg_type; /* Protocol specific type. */ #if (!defined __STRICT_ANSI__ && __GNUC__ >= 2) || __STDC_VERSION__ >= 199901L __extension__ unsigned char __cmsg_data __flexarr; /* Ancillary data. */ #endif }; //#include <sys/socket.h> /* Send a message described MESSAGE on socket FD. Returns the number of bytes sent, or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t sendmsg (int __fd, __const struct msghdr *__message, int __flags); /* Receive a message as described by MESSAGE from socket FD. Returns the number of bytes read or -1 for errors. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t recvmsg (int __fd, struct msghdr *__message, int __flags);
其中flags和send/recv的flags含义相同,我们主要看看msghdr里面的部分:
- msg_name/msg_namelen表示套接字地址和长度
- msg_iov/msg_iovlen表示io vector的读写部分。
- msg_control/msg_controllen表示辅助数据的长度
- msg_flags表示recvmsg返回的标记。
我们这里不过多使用辅助数据是什么,但是可以看看辅助数据结构。msg_control是由多个cmsghdr组成的, 我们可以使用下面的宏来遍历进行访问:
- CMSG_DATA(cmsg).数据
- CMSG_FIRSTHDR(hdr)
- CMSG_NXTHDR(cmsg,hdr).
- epoll
#todo:
2.11. conversion
2.11.1. 使用说明
关于名字与地址转换,我们这里只关注主机名和IP地址之间的转换接口。至于实现方面的话,大致有两种方式:
- 本地配置文件比如/etc/hosts,优先使用。
- 采用类似DNS这样的解析服务,可以认为是一个分布式有层级关系的名字解析集群,
不过具体顺序的话,在/etc/host.conf里面可以查看。
//#include <netdb.h> extern int gethostbyaddr_r (__const void *__restrict __addr, __socklen_t __len, int __type, struct hostent *__restrict __result_buf, char *__restrict __buf, size_t __buflen, struct hostent **__restrict __result, int *__restrict __h_errnop); extern int gethostbyname_r (__const char *__restrict __name, struct hostent *__restrict __result_buf, char *__restrict __buf, size_t __buflen, struct hostent **__restrict __result, int *__restrict __h_errnop); extern int gethostbyname2_r (__const char *__restrict __name, int __af, struct hostent *__restrict __result_buf, char *__restrict __buf, size_t __buflen, struct hostent **__restrict __result, int *__restrict __h_errnop); /* Return string associated with error ERR_NUM. */ extern __const char *hstrerror (int __err_num) __THROW;
其中_r表示这是一个可重入版本,gethostbyname2_r相比较gethostbyname_r多了一个参数__af,这个参数可以指明希望 返回IPv4还是IPv6的返回地址,gethostbyaddr_r的__type告诉传入的addr是IPv4还是IPv6地址,值可以是AF_INET或者是AF_INET6.
然后我们看看最主要的结构struct hostent.
/* Description of data base entry for a single host. */ struct hostent { char *h_name; /* Official name of host. */ char **h_aliases; /* Alias list. */ int h_addrtype; /* Host address type. */ //AF_INET or AF_INET6 int h_length; /* Length of address. */ //表示h_addr_list里面每个元素长度,IPv4为4,IPv6为16. char **h_addr_list; /* List of addresses from name server. */ #define h_addr h_addr_list[0] /* Address, for backward compatibility. */ };
如果IPv4的话对于h_addr_list里面的元素类型应该强转成为in_addr结构,如果是IPv6的话对于h_addr_list里面的元素类型应强转为in6_addr. 可以看到这些指针内容都是需要有空间存放的,所以接口里面的_buf,_buflen就是用来存放这些空间的,常用来说1K~2K就足够了,除非这个机器 有相当数量的IP和别名。这些函数没有讲错误设置成为errno,而是放在了参数返回值里面,我们使用hstrerror来获得这些错误字符串。
2.11.2. name2addr
//第一次请求
[dirlt@localhost.localdomain]$ ./name2addr iptv.tsinghua.edu.cn
====================IPv4====================
hostname:iptv.tsinghua.edu.cn
ip:
203.91.120.222
====================IPv6====================
hostname:iptv.tsinghua.edu.cn
ip:
2001:da8:217:1::222
//第二次请求
[dirlt@localhost.localdomain]$ ./name2addr www.baidu.com
====================IPv4====================
hostname:www.a.shifen.com
alias:
www.baidu.com
ip:
119.75.217.109
119.75.218.70
gethostbyname2_r(www.baidu.com,AF_INET6) failed:Unknown server error
//tcpdump结果
[root@localhost dirlt]# tcpdump udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
//iptv.tsinghua.edu.cn
00:10:06.161527 IP 192.168.30.132.filenet-rmi > 192.168.30.2.domain: 62338+ A? iptv.tsinghua.edu.cn. (38)
00:10:06.163248 IP 192.168.30.132.filenet-pa > 192.168.30.2.domain: 948+ PTR? 2.30.168.192.in-addr.arpa. (43)
00:10:06.164792 IP 192.168.30.2.domain > 192.168.30.132.filenet-rmi: 62338 1/4/5 A 203.91.120.222 (231)
00:10:06.167666 IP 192.168.30.132.filenet-cm > 192.168.30.2.domain: 6184+ AAAA? iptv.tsinghua.edu.cn. (38)
00:10:06.169991 IP 192.168.30.2.domain > 192.168.30.132.filenet-pa: 948 NXDomain 0/1/0 (120)
00:10:06.170517 IP 192.168.30.132.filenet-re > 192.168.30.2.domain: 40975+ PTR? 132.30.168.192.in-addr.arpa. (45)
00:10:06.175797 IP 192.168.30.2.domain > 192.168.30.132.filenet-cm: 6184 1/4/5 AAAA 2001:da8:217:1::222 (243)
00:10:06.339048 IP 192.168.30.2.domain > 192.168.30.132.filenet-re: 40975 NXDomain 0/1/0 (122)
//www.baidu.com
00:10:18.998104 IP 192.168.30.132.filenet-re > 192.168.30.2.domain: 16416+ A? www.baidu.com. (31)
00:10:19.003218 IP 192.168.30.2.domain > 192.168.30.132.filenet-re: 16416 3/4/4 CNAME www.a.shifen.com., A 119.75.218.70, A 119.75.217.109 (226)
00:10:19.007622 IP 192.168.30.132.filenet-re > 192.168.30.2.domain: 41204+ AAAA? www.baidu.com. (31)
00:10:19.012565 IP 192.168.30.2.domain > 192.168.30.132.filenet-re: 41204 1/0/0 CNAME www.a.shifen.com. (58)
2.11.3. addr2name
//第一次请求
[dirlt@localhost.localdomain]$ ./addr2name 127.0.0.1
====================IPv4====================
hostname:localhost.localdomain
alias:
localhost
localhost
ip:
127.0.0.1
//第二次请求
[dirlt@localhost.localdomain]$ ./addr2name ::1
====================IPv6====================
hostname:localhost6.localdomain6
alias:
localhost6
ip:
::1
//第三次请求
[dirlt@localhost.localdomain]$ ./addr2name 119.75.217.109
gethostbyaddr_r(119.75.217.109,AF_INET) failed:Unknown host
//tcpdump结果
//对于前两个请求,在本地就已经处理完成,所以没有走网络。
[root@localhost dirlt]# tcpdump udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
00:12:55.853398 IP 192.168.30.132.filenet-re > 192.168.30.2.domain: 7658+ PTR? 109.217.75.119.in-addr.arpa. (45)
00:12:55.854920 IP 192.168.30.132.filenet-pch > 192.168.30.2.domain: 29796+ PTR? 2.30.168.192.in-addr.arpa. (43)
00:12:55.860191 IP 192.168.30.2.domain > 192.168.30.132.filenet-re: 7658 NXDomain 0/1/0 (134)
00:12:56.038356 IP 192.168.30.2.domain > 192.168.30.132.filenet-pch: 29796 NXDomain 0/1/0 (120)
00:12:56.038849 IP 192.168.30.132.filenet-pch > 192.168.30.2.domain: 11191+ PTR? 132.30.168.192.in-addr.arpa. (45)
00:12:56.044013 IP 192.168.30.2.domain > 192.168.30.132.filenet-pch: 11191 NXDomain 0/1/0 (122)
3. TCP
#todo: man 7 tcp
3.1. 特点
TCP(Transmission Control Protocol,传输控制协议)相对于UDP来说更加复杂而功能也更加强大。首先TCP是面向连接的, 这就意味着如果两端需要进行通信的话,那么双方必须首先建立连接然后才可以交换数据。其次TCP提供了可靠性的保证, 如果一端发送数据的话如果在一段时间内没有回应的话,那么会进行数据重传,直到对端返回ACK.如果尝试多次重传失败的话, 那么TCP就会放弃。(但是这个TCP放弃动作应用层是见不到的,所以实际上在应用层为了首先我们的可靠性保证的话, 还是需要得到应用层的ACK).对于超时时间TCP能够根据网络状况估算往返时间(round-trip time)来不断地调整。因为TCP提供的 是一个有序的字节流,所以在会进行必要的排序,因为在IP层一次传输的大小是有限制的,TCP必须进行分片并且做记号, 然后接收端必须将根据这些记号重新组合成为一个有序的字节流。另外TCP还提供了流量控制功能(flow control),因为两端 发送和接收速度会存在差异,如果缺乏流量控制相互通信的话,那么一端数据可能就直接被丢弃了,通过流量控制 可以考虑发送端本端tcp kernel buffer有多少空间,这样可以限制对端发送速度。最后TCP连接是全双工的,也就是说, 在同一个连接上,双端可以交换信息。总结起来,TCP特点有下面这些:
- 面向链接
- 有序字节流
- 可靠性
- 超时机制
- 流量控制
- 全双工
3.2. TCP首部
TCP首部数据格式如下,如果不计可选字段的话占用20个字节(通常来说也就是占用20个字节)
struct tcp_header_t{ uint16_t src_port; uint16_t dst_port; uint32_t seq; uint32_t ack_seq; //ACK序号,确认需要是上次成功接收数据序号+1 uint8_t header_length:4; //给出的首部中32bit的数目,因为首部最大15*4byte=60byte. uint8_t reserved:6; uint8_t urg:1; uint8_t ack:1; uint8_t psh:1; //接收方应该尽快地将这个报文段交给应用层 uint8_t rst:1; uint8_t syn:1; uint8_t fin:1; uint16_t win_size; //可以看到窗口大小65535字节 uint16_t checksum; //强制性字段,发送端进行计算和存储,接收端进行校验 uint16_t urg_ptr; //紧急指针当urg==1的时候才有效,+seq表示紧急数据最后一个字节的序号 uint8_t option[0]; //最常见可选字段是MSS };
序号用来标识从TCP发送端向TCP接收端发送的数据字节流,它表示在这个报文段中的第一个数据字节。 如果将字节流看做在两个应用程序之间的单向流动,则TCP用序号对每一个字节进行计数。我们可以看到序号是32bit无符号整数, 所以当序号到达2^31-1之后又会从0开始。
3.2.1. RST分节
产生RST分节通常有下面几个情况:
- 连接或者是发送到到某个没有监听对应端口的服务器上。内部产生一个ICMP端口不可达信息而TCP则使用复位。
- 想主动取消一个已有连接。通常来说我们是等待数据发送完成之后发送FIN称为有序释放(orderly release),否则称为异常释放(abortive release).
- TCP接收到一个根本不存在该连接上的分组。通常这种情况是比如server掉电重启,而client认为连接还存在然后发送分组,这种情况称为
半打开连接(half-open connection),server会以RST分节响应。
3.2.2. PSH分节
#todo:
3.2.3. URG分节
#todo:
3.3. TCP状态
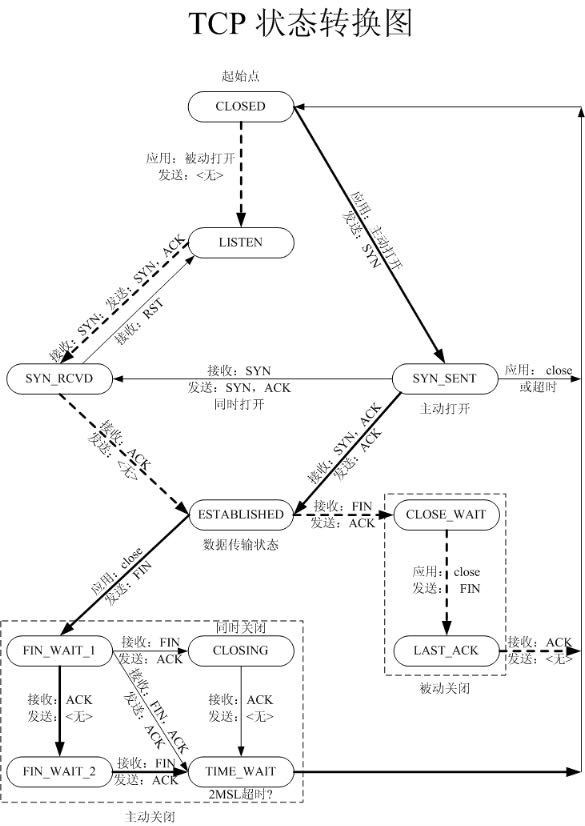
注意这里的图表示和TCP/IP详解v1里面的图有点不同,少了两条通路
- SYN_RCVD->FIN_WAIT1,TCP/IPv1可以直接发送FIN分节。就是假设一个client连接上但是没有完成三次握手但是放在incomplete queue里面,然后服务器主动将这个连接断开。
这个至少在应用层面上是很少见的。我们不考虑。
- SYN_SENT->SYN_RCVD,TCP/IPv1可以直接接收到SYN并且返回SYN/ACK分节。这个同时打开的情况。这个在应用层面上也很少见。
不过作者也说很多BSD的TCP实现都不能够正确支持这种同时打开的情况,即使实现也没有很少地测试过。我们不考虑。
另外一种少见的情况就是同时关闭,都从ESTABLISHED进入FIN_WAIT_1状态,同样我们不考虑。
3.3.1. 连接的建立和终止
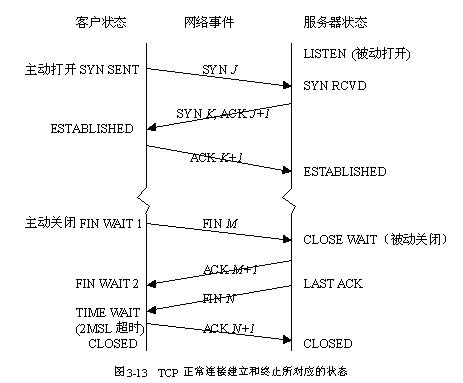
首先服务器必须准备好接受外来的连接,这个过程称为被动打开(passive open),通常包括socket,bind,listen,accept这4个步骤。 而客户端通过调用socket,connect来链接服务端,这个过程称为主动打开(active open).建立连接的过程大致是这样的,下面我们使用 A表示active一端(通常为client),P表示passive一端(通常为server).
- A->P SYN/x.
- P->A ACK/x+1,SYN/y.
- A->P ACK/y+1.
这个过程称为三次握手(three-way handshake).在三次握手时候交换MSS和窗口大小信息。对于这个x的选择是系统自动产生的,为了防止 在网络中被延迟的分组在以后又被传送而导致链接另外一方做出错误解释的话,这个x必须每次尽可能地不同。系统会维护一个ISN(initial sequence number), 是一个32bit计数器每4ms+1.
在关闭连接时候,主动调用close的一段称为主动关闭(active close),而接收到FIN分节的一端执行关闭称为被动关闭(passive close). 关闭链接的过称大致是这样的,同样使用A表示active一端(通常为client),P表示passive一端(通常为server).
- A->P FIN/x(active调用close).
- P->A ACK/x+1
- P->A FIN/y(passive调用close)
- A->P ACK/y+1
3.3.2. TIME_WAIT状态
Coping with the TCP TIME-WAIT state on busy Linux servers | Vincent Bernat : http://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux.html
有关TCP状态中最不容易理解的就是TIME_WAIT这个状态了,这个状态是主动执行关闭的话会经历的状态,在这个状态停留时间 是最长分节生命期(maximum segment liftime,MSL)的两倍,我们称为2MSL.MSL意思是任何一个IP数据报可能停留在网络中存活 的最长时间,这个时间是一个有限值,不同系统设置不同。RFC建议值是2min,而BSD的传统实现是30s.TIME_WAIT状态存在有两个理由:
- 可靠地实现TCP全双工连接终止。
- 允许老的重复分组在网络中消失。
这里有一个定时器称为2MSL定时器。
首先看第一个理由。如果最后passive调用close的话发出FIN分节并且active一端收到,但是响应ACK丢失的话,那么passive一端 还会重复发出FIN分节以等待确认。如果这个时候没有TIME_WAIT状态而是直接退出的话,让passive一段重复发送FIN分节到来的话, active一端会直接响应一个RST分节造成连接错误终止。
对于第二个理由,我们首先考虑一个迷途的重复分组(lost duplicate).如果A->B发送一个分节但是这个分节因为中途部分路由器出现问题, 在路由器停留时间过长,导致A->B发送分节超时而重发。如果A->B重发之后并且都关闭,然后AB又同时使用相同的IP和端口并且分节序列号 正好匹配的话(虽然概率很低),那么这个以前连接的分组就会出现在新的连接被处理。而TCP_WAIT状态的话,使得不允许在2MSL之内使用 相同的端口连接,就不会出现这样老分组出现在新连接上了。
个人觉得出现TIME_WAIT状态主要还是第一个原因,第二个出现问题的几率在普通网络环境内是很难出现的,因为需要正好匹配到原有 的序列号也是需要一定几率的,而毕竟序列号占用TCP中的4个字节,范围是[0,2^32-1].
3.3.3. FIN_WAIT2状态
假设client执行了半关闭进入FIN_WAIT2状态,然后等待server端传输完成并且发送FIN分节。但是如果server代码有bug的话没有发送FIN分节, 那么会导致server句柄一直存在,而client因为没有得到FIN分节而阻塞在read这个操作上面,并且这个是无限等待的。
所以在实现上来说添加了定时器来避免这个问题。FIN_WAIT2在等待一段时间时候那么就会进行CLOSED状态,client端的read就会返回然后退出。 而在server端就显示这个连接一直存在并且fd也被占用。也就是说如果netstat发现很多CLOSE_WAIT状态并且句柄泄露的话,那么很可能是 server在会话完成之后没有调用close而造成的资源泄露。
3.3.4. TFO(tcp fast open)
http://www.pagefault.info/?p=282
RFC:http://www.ietf.org/id/draft-cheng-tcpm-fastopen-00.txt
PDF:http://www.ietf.org/proceedings/80/slides/tcpm-3.pdf
TFO在client开始SYN的时候允许设在TCP选项上面设置TFO option,然后server决定是否开启TFO这个功能。如果server决定开启TFO的话,那么server回复的SYNACK里面就会标记"我 开启了TFO",并且带上cookie。之后 google chrome虽然keepalive时间为4mim,但是35%请求还是会超过keepalive的时间然后重新发起连接,如果之前server是开启 TFO功能的话,那么client这次连接发起 的SYN会带上请求和cookie。
然后RFC793虽然规定了 SYN可以带上数据,但是请求必须在3WHS之后才能够处理(一方面是为了防止过时的SYN,另外一方面是为了防止SYN flood attack)。但是TFO的实现允许在SYN就带上数据并且立刻处理,可以查看pdf里面TFO过程。为了防止SYN flood attack使用了cookie机制进行验证。而TFO并不防止过时的SYN这样的请求,允许SYN+数据发送多次并且响应,这就要求了server有能力确定是否开启TFO(server如果判断请求是幂等的话,那么就可以开启TFO)。
Rather than trying to capture all the dubious SYN packets to make TFO 100% compatible with TCP semantics, we've made a design decision early on to accept old SYN packets with data, i.e., to allow TFO for a class of applications that are tolerant of duplicate SYN packets with data, e.g., idempotent or query type transactions. We believe this is the right design trade-off balancing complexity with usefulness. There is a large class of applications that can tolerate dubious transaction requests.
3.4. 流量控制
3.4.1. 滑动窗口
如果TCP采用停止等待协议来进行数据传送的话,那么吞吐量是会存在问题的,我们完全可以采用类似于流水线的方式来提高吞吐量。 发送方可以在停尸并等待确认之前发送多个连续分组,由于发送方不必等待每一个发送分组就停下来等待确认,可以加快数据的传输。 而这种传输方式就是滑动窗口传输方式。
演示滑动窗口工作原理非常直观。发送端只需要想象我们有一个连续的字节流,然后我们通过一个window来观察这个字节流。每次发送的内容都是在 window里面的数据,一旦发送端接收到window最末端的字节ACK的话,那么窗口就可以向前进行移动并且从内核buffer丢弃。接收端也是同样的道理, 首先有一个空window,然后每接收到一些数据就向这个window里面填充,一旦window最末端的被连续填充之后,那么窗口就可以向前移动并且返回ACK, 而被连续填充部分就可以报告给应用层,让应用层处理这个部分的数据。这里需要注意的就是,滑动窗口协议并不需要确认每一个字节,如果发送端接收的 ACK为x的话,那么就可以认为x以前的所有数据都已经被确认了。
但是我们不要区分地看待这两个窗口。事实上发送端是不会主动规定这个窗口大小的,这个窗口大小是接收端通知的。接收端告诉发送端自己的窗口大小之后, 这样发送端发送的数据只能够在这个窗口里面,好处就是能够比较有效地处理快发送端-慢接收端这样的情况。接收端一旦接收到数据的话,那么自己的窗口大小就变小了。 如果返回ACK的时候就会附带上自己的窗口大小,通知发送端可以少发送一些。而一旦接收端将自己的数据推送给应用层之后,窗口大小变大那么也会通过捎带ACK 或者是主动ACK通知发送端窗口大小发生变化。这个过程称为窗口更新。
我们考虑一个问题就是,接收端什么时候返回窗口更新的ACK.捎带ACK是一个时机,另外一个时机就是主动发送ACK来通知发送端(这样可以避免僵局).虽然TCPv1里面没有提到这个过程, 而是认为发送端应该主动进行使用坚持定时器进行窗口探测,但是从TCPv1(P212.Fig20-3,segemnt 9)来看的话,接收端主动通过ACK来通知窗口更新,应用也是实现的一种方式。
因为窗口大小是接收端来规定的,那么窗口大小是多少才合适呢?因为这个影响到了TCP的性能。其实和CPU流水线一样,如果数据能够充满通信介质的话,那么吞吐量是最高的。 计算通道容量为capacity(bit)=bandwidth(b/s)*round-trip-time(s),这个被称为带宽时延乘积,也就是窗口大小最合适的值。当不管有多少个报文段填充了这个管道, 返回路径上总是具有相同数目的ACK,那么这个时候就是连接理想稳定状态。
3.4.2. 慢启动算法
滑动窗口规定和发送端和接收端的数据发送多少,但是却没有规定如何进行发送。一种粗暴方式就是发送端一开始便向网络发送多个报文段, 直到达到接收方通告的窗口大小为止。这个策略如果在局域网内部是可行的,但是如果一旦中途经过多个路由器和速度慢的链路的话,这些路由器必须缓存 这些分组并且有可能耗尽存储器空间造成丢包,这种方式会降低TCP连接的吞吐量的。我们希望的方式是能够以一种平稳的方式进行启动,效果就是 新分组进入网络的速率和另外一段返回确认的速率相当。
慢启动是这样做的维护一个拥塞窗口(congestion window,cwnd).cwnd单位是报文段,但是在进行比较是时候会折合称为字节数(*最大报文字节数). 初始cwnd=1,不允许超过min(cwnd,receiver-windows-size).然后发送端收到一个ACK的话那么cwnd+=1.可以看到最好情况的话,cwnd是指数增长的。 首先发送一个cwnd大小的数据,然后返回一个ACK之后,cwnd=2。这个时候允许发送2个报文段,然后返回两个ACK之后的话,cwnd=4。 事实上如果对于网络运行情况良好的网络来说,这个启动一点不慢,cwnd很快就不是瓶颈了。但是使用了拥塞窗口之后,可以使得启动这个过程相对来说比较平稳。 慢速启动算法没有解决的问题就是,如果出现拥塞分组丢失的话,那么应该如何处理。
3.4.3. 拥塞避免算法
拥塞避免算法通常和慢启动算法一起使用。慢启动算法里面有两个问题没有解决:
- 如果出现拥塞分组丢失的话,那么cwnd如何进行调整。
- 当cwnd如果超过某个界限的话,那么每收到一个ACK就+1的话,拥塞窗口过大就没有太大的意义了。
本质来说慢启动算法只是考虑到了启动初期这段时间的发送方式,而没有考虑到平稳之后以及出现拥塞之后的调整方式,拥塞避免算法解决了这些问题。 拥塞避免算法和慢启动算法是两个不同目的和独立的算法,但是当拥塞发生的时候我们希望降低分组进入网络的传输速度,这点可以通过慢启动来解决。 因为在实际中,通常慢启动算法和拥塞避免算法是一起工作的。我们假定由于分组收到损坏而引起的丢失是非常少的(<1%),所以我们认为分组丢失通常意味着 源和目的之间的某处网络发生了拥塞。分组丢失通常有两种指示:
- 超时重传。
- 收到重复需要确认。(也可能因为分片乱序造成)
在TCP层通过判断这两个条件出发来确定是否发生拥塞。
为此我们必须规定一个阈值,超过这个阈值之后那么就不属于慢速启动的范围了,而属于如何控制住拥塞的范围了应该使用另外一种策略来控制拥塞窗口。 从另外一个角度来说,可以认为这个阈值反应了当前传输网络所处的一个环境。这个阈值我们这里称为ssthresh(slow start threshold,慢启动阈值). 然后我们在来仔细回顾一下3个参数的含义:
- receiver-window-size.接收端窗口大小,这个属于接收方进行的流量控制。
- cwnd.拥塞窗口,这个属于发送端进行的流量控制。
- ssthresh.慢启动阈值,这个用来界定当前发送情况是慢启动还是拥塞避免。
那么工作逻辑是这样的:
max_segment_size=536
cwnd=1
ssthresh=64*1024 # 64K
def handle_congestion(connection):
#如果出现阻塞的话
congestion=connection.congestion()
reason=congesiton.reason()
#一旦出现拥塞的话,那么慢启动阈值缩减为当前窗口大小一半
ssthresh=min(connection.peer_recv_window_size(),
cwnd*max_segment_size)/2
#至少为2个报文段
ssthresh=max(ssthresh,2*max_segent_size)
#如果是超时出发拥塞的话,那么cwnd=1
if(reason=='timeout'):
cwnd=1
def handle_ack(connection): # 正常ACK
#如果ack到达的话,那么需要增加cwnd
#但是增加cwnd的方法取决于我们是否正在进行慢启动
if((cwnd*max_segment_size)<ssthresh):
#如果处于慢启动的话,那么cwnd+=1
#这是一种指数增长
cwnd+=1
else:
#否则1/cwnd.这是一种加性增长(additive increase).
cwnd+=1/cwnd
3.4.4. 快速重传算法
如果接收端返回的是重复序号ACK的话,通常有两种情况:
- 分组乱序到达
- 分组部分缺失
本质上都是因为分组没有按照顺序到达,但是第一种情况是之后终究会到达,而第二种情况就是永远不会到达。对于第二种情况的话,如果我们没有特殊处理的话, 我们只能够等待重传定时器超时然后再发起重传。我们可以针对这种情况快速地进行重传,不过我们需要找准如何区分情况1,2的界限,快速重传算法规定的就是这个界限。 如果相同的ACK到来>=3次的话,那么就认为是情况2,那么这个时候就可以立即发起重传,而不用等待重传定时器超时,这个就是快速重传算法。
3.4.5. 快速恢复算法
快速重传算法一旦发现需要重传的话,那么立刻会调用快速恢复算法。使用的是拥塞算法部分的主体而不是慢启动算法部分的主体,原因也非常简单, 就是因为触发快速重传算法,是因为接收端返回了重复的ACK并且将之前发送端发送的数据丢弃了,所以网络应该处于一个非拥塞并且流畅的状态。 那么这个时候我们可以适当扩大拥塞窗口的大小,快速地发送缺失的部分来进行重传。这里我们需要对于拥塞算法部分进行一些修改。
- 当第一次收到3ACK的时候,ssthresh减半,然后cwnd=ssthresh/max_segment_size+3,重传丢失报文。
- 如果见到的还是重复ACK的话,那么cwnd+=1.
- 如果是接收到数据ACK的话,那么cwnd=ssthresh/max_segment_size.这个时候回复正常。
参数我们没有必要深究,之所以这个时候可以cwnd+=1不断地提高拥塞窗口大小,是因为这个如果接收到还是重复ACK的话,那么对端是会将刚才发送的数据丢弃的, 网络上面是有流动数据而没有发生拥塞,这个原因和为什么3ACK之后就可以使用拥塞避免而不是慢启动原因是一样的。思想就是一旦我们需要快速重传的话,我们应该 尽可能地提高拥塞窗口大小,一旦正常运行的话那么将拥塞窗口回复原来的水平,使用原有逻辑。
3.4.6. ICMP差错
如果ICMP差错是源端抑制的话,那么cwnd=1而ssthresh不发生任何变化,重新使用慢启动算法。
3.5. 定时器
3.5.1. 重传定时器
重传超时时间(RTO,Retranmission TimeOut)的测量依赖于RTT(round-trip time)的。首先我们看看RTT的测量方式,然后看看如何通过RTT重传超时时间的。
RTT的测量过程是这样的。我们有一个状态status,=0表示没有进行RTT测量状态,=1表示正在进行测量。开始status=0,我们t1时刻发送一个报文段,然后status=1. 等待对端对这个报文段ACK,到达时刻为t2.那么RTT=t2-t1,然后status=0.我们使用status这个状态是希望针对每一个连接我们只是希望测量一次RTT值, 如果在发送报文段时候RTT已经开始测量的话那么这个报文段不计时。
如果在重传一个分组的时候,我们不知道这个ACK是针对原始发送分组的确认,还是针对重传分组的确认,我们没有好的办法来确定RTT.对于这种情况的话, 我们就不更新RTT。也就是说如果我们一旦在进行重传状态之后,我们不进行RTT的更新。这个就是Karn算法。
从RTT计算RTO的算法有两个版本。第一个版本比较简单
R=xR+(1-x)RTT #R表示历史的RTT内容,通常x=0.9,初始为0s RTO=yR #通常y=2
但是Jacobson认为如果在RTT变化范围很大的时候,这种方式计算出的RTO并不能够很好地适应这种变化。那么第二个版本就是
E=RTT-R #R表示历史RTT,E表示偏差值 R=R+gE #通常g=0.125,然后修正历史RTT,初始为0s D=D+h(abs(E)-D) #通常h=0.25,被平滑之后的偏差,初始为3s RTO=R+4D
当TCP超时并且重传时,它不一定要重传相同的报文段。相反,TCP允许进行重新分组而发送一个较大的报文段,这将有助于提高性能。
3.5.2. 坚持定时器
还是从滑动窗口这个部分考虑。如果接收端收到数据之后自己的窗口填满了,然后返回ACK(winsize=0)发送端接收到之后,那么停止发送数据 等待接收端的窗口打开。一旦接收端将数据交给上层之后,自己窗口开了,给发送端ACK(winsize=x),注意这个ACK是没有数据的,因此 发送端没有必要相应。如果第二个ACK丢失的话,那么就会有一个问题,发送端不知道接收端窗口打开,而接收端认为自己已经通知了发送端。
打破这个僵局的话需要坚持定时器(persist timer).这个定时器会隔断时间触发发送端发送一个窗口探查报文段(window probe).这个报文段非常简单, 就是一个1字节的数据,然后等待接收端返回自己的窗口大小。时间间隔大致是这样的,首次是A(1.5s),然后下一次是2A,下一次是4A,然后8A这样的 指数退避(exponential backoff)方式来增加时间间隔,但是上限是60s。如果这个窗口探测报文段需要重传的话,重传策略应该和普通数据重传策略相同。
如果接收端处理速度很慢的话,每次只是用内核态读取1个字节的话窗口从0->1,然后立刻ACK进行窗口通知。这样容易出现一个问题, 称为SWS(silly window syndrome),就是网络上面会有非常多的小数据分组进行传输。这个现象可以在两端的任何一段发生,比如接收方一旦有一个 小窗口就立刻通知,而发送端一旦有少量数据就立刻发送。解决办法也可以在两端完成,在接收端的话只有当窗口达到一定大小才会进行通知, 而发送端的话可以等待发送数据达到一定程度之后才进行发送。
3.5.3. 保活定时器
保活定时器通常都是服务器端使用的。假设有很多客户端连接上了服务端,但是这些客户端直接网络断开了,而服务器认为这些客户端一直还存在, 在服务器还维持非常多的连接占用资源。为了解决这个问题,TCP为每个连接底层维护了一个保活定时器,通常是在没有接受任何分段的2个小时后发送一个保活分段。 这个保活分段就是一个带有特殊数据的ACK分节/或者是要求相应的ACK分节,结果会有下面这几种:
- 客户端正常响应,响应正常的ACK分节。
- 客户端主机崩溃,现在关闭或者是正在重启,但是在路由表内可见。那么每个75s内会重发一次,发送10次之后连接超时。
- 客户端主机崩溃,但是已经启动完毕。那么直接返回RST分节。
- 客户端主机正常允许,但是从路由表中删除了。底层TCP会接收到ICMP的主机不可达错误。
所有这些错误通知服务端的方式应该都是置连接为可读/可写,然后发起read/write的时候服务端就会检测到这个错误。
3.6. 读写数据
3.6.1. 读数据
#todo:
3.6.2. 写数据
首先应用层只是调用write将应用层数据完全copy到内核的tcp send buffer上,至于这个tcp send buffer大小是SO_SNDBUF来控制的。 写入write成功仅仅表示写入到tcp send buffer而不表示已经发送或者是对端已经接收到。然后本端将tcp send buffer按照MSS 来进行切分,并且加上TCP的头部传递给IP层。因为TCP之前已经按照MSS进行了分片,那么在主机的IP层不会进行分片操作。 tcp send buffer不会被丢弃直到对端收到这块buffer所包含内容的确认为止。同时如果数据链路层输出队列满的话, 那么新到的IP分组将会丢弃,并且沿着协议栈向上反馈。TCP注意到这个错误的话,那么会等待一段时间然后重传,而不会让应用层看到。
如果底层tcp send buffer空间不够的话,如果使用的是阻塞IO的话那么就会hang住直到tcp send buffer有空闲然后继续写入, 直到数据完全写完为止。如果使用的是非阻塞IO的话,那么如果有部分空间的话就会返回已经成功写入的字节数,否则返回错误EAGAIN.
4. UDP
#todo: man 7 udp
4.1. 特点
UDP(User Datagram Procotol,数据报传输协议)是一个简单的传输层协议,在RFC768中有详细说明。 应用程序向UDP socket写入消息之后消息被封装到一个UDP数据包,然后UDP数据包封装到IP数据包,然后发送到目的地。 UDP不保证UDP数据报会到达最终目的地,并且不保证到达顺序和发送顺序相同,也不保证每个数据包只到达一次。 在网络编程中,我们使用UDP最多的问题就是因为UDP缺乏传输可靠性,比如不会进行校验,不会进行重传,也不会进行去重,也不进行顺序保证等。 而这些都是TCP所有的特点。每个UDP数据报都有一个长度,如果数据报正确到达目的地的话那么数据报长度也会一起传递给应用程序, 而TCP因为是面向流的,所以需要自己在应用程序上进行切分,除此之外UDP因为是面向无连接的,所以可以相对来说比较灵活并且省去了建立链接的开销。 UDP可以是全双工的,只要在UDP层面上提供链接这样的概念。总结起来,UDP特点有下面这些:
- 无连接
- 面向记录
- 不保证可靠和有序
- 无流量控制
- 全双工
4.2. 读写数据
4.2.1. 读数据
#todo:
4.2.2. 写数据
和TCP输出一样,UDP也维护着内核udp send buffer,大小可以通过SO_SNDBUF来控制,而这个参数控制着一次写UDP数据报的大小上限。 如果一个应用程序写一个大于udap send buffer的数据报的话,那么会返回EMSGSIZE错误。因为UDP是不可靠的传输协议,所以没有必要 维持udp send buffer,只要发送给IP层之后那么udp send buffer就立即可用了。然后UDP将udp send buffer加上UDP头部然后传递 给IP层,IP层加上IP头部并且MTU-IP-UDP来进行分片。IP层数据包进行数据链路层,如果这个时候数据链路层没有队列存放这个IP数据报的话, 那么会返回ENOBUFS给应用程序。
5. Unix域套接字
#todo: unix domain socket
Unix domain socket走的是loopback接口。loopback接口是没有网卡流量限制,同时也没有网络软中断限制的。
6. 示例程序
6.1. connect.cc
#include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <cstdio> #include <cstdlib> #include <cstring> #include <string> #include <signal.h> static const char* prog=0; static std::string connect_ip; static int connect_port=0; static int bind_port=0; static bool linger=false; static bool reuseaddr=false; static bool half_close=false; static void usage(){ fprintf(stderr,"usage:%s [-b port] [-l] [-r] [-H] ip port\n",prog); } static void signal_handler(int signo){ printf("caught signal:%s\n",strsignal(signo)); } int main(int argc,char* const argv[]){ prog=argv[0]; bool except=true; for(int i=1;i<argc;i++){ if(argv[i][0]=='-'){ switch(argv[i][1]){ case 'h': usage(); return 0; case 'b': bind_port=atoi(argv[i+1]); i++; break; case 'l': linger=true; break; case 'r': reuseaddr=true; break; case 'H': half_close=true; break; default: fprintf(stderr,"%s:unknown option '%s'\n",prog,argv[i]); usage(); return -1; } }else{ connect_ip=argv[i]; connect_port=atoi(argv[i+1]); except=false; break; } } if(except){ usage(); return -1; } int fd=socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); if(fd==-1){ printf("socket failed:%m\n"); return -1; } if(reuseaddr){ int ok=1; printf("setsockopt SO_REUSEADDR\n"); if(setsockopt(fd,SOL_SOCKET,SO_REUSEADDR,&ok,sizeof(ok))==-1){ fprintf(stderr,"setsockopt SO_REUSEADDR failed:%m\n"); return -1; } } if(linger){ struct linger val; val.l_onoff=1; val.l_linger=0; printf("setsockopt SO_LINGER\n"); if(setsockopt(fd,SOL_SOCKET,SO_LINGER,&val,sizeof(val))==-1){ fprintf(stderr,"setsockopt SO_LINGER failed:%m\n"); return -1; } } if(bind_port){ sockaddr_in addr; memset(&addr,0,sizeof(addr)); addr.sin_family=AF_INET; addr.sin_addr.s_addr=INADDR_ANY; addr.sin_port=htons(bind_port); printf("bind (0.0.0.0:%d)\n",bind_port); if(bind(fd,(struct sockaddr*)&addr,sizeof(addr))==-1){ printf("bind failed:%m\n"); return -1; } } sockaddr_in addr; memset(&addr,0,sizeof(addr)); addr.sin_family=AF_INET; inet_pton(AF_INET,connect_ip.c_str(),&(addr.sin_addr)); addr.sin_port=htons(connect_port); printf("connect %s:%d ...\n",connect_ip.c_str(),connect_port); if(connect(fd,(struct sockaddr*)&addr,sizeof(addr))==-1){ printf("connect failed:%m\n"); return -1; }else{ printf("connect succeed\n"); } signal(SIGPIPE,signal_handler); if(half_close){ char data[1]; int ret=0; //SHUT_RD shutdown(fd,SHUT_RD); ret=read(fd,data,sizeof(data)); if(ret==-1){ printf("read failed:%m\n"); }else{ printf("read succeed=%d\n",ret); } //SHUT_WR shutdown(fd,SHUT_WR); ret=write(fd,data,sizeof(data)); if(ret==-1){ printf("write failed:%m\n"); }else{ printf("write succeed=%d\n",ret); } } return 0; }
6.2. server.cc
#include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <cstdio> #include <cstdlib> #include <cstring> #include <string> #include <signal.h> static const char* prog=0; static int delay_time=0; static std::string bind_ip; static int bind_port=0; static bool echo_char=false; static bool reuseaddr=false; static void usage(){ fprintf(stderr,"usage:%s [-r] [-d delay] [-b ip] [-c] port\n",prog); } void sig_handler(int signo){ printf("caught signal:%s\n",strsignal(signo)); } int main(int argc,char* const argv[]){ prog=argv[0]; bool except=true; for(int i=1;i<argc;i++){ if(argv[i][0]=='-'){ switch(argv[i][1]){ case 'h': usage(); return 0; case 'r': reuseaddr=true; break; case 'b': bind_ip=argv[i+1]; i++; break; case 'd': delay_time=atoi(argv[i+1]); i++; break; case 'c': echo_char=true; break; default: fprintf(stderr,"%s:unknown option '%s'\n",prog,argv[i]); usage(); return -1; } }else{ bind_port=atoi(argv[i]); except=false; break; } } if(except){ usage(); return -1; } int fd=socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); if(fd==-1){ printf("socket failed:%m\n"); return -1; } if(reuseaddr){ int ok=1; printf("setsockopt SO_REUSEADDR\n"); if(setsockopt(fd,SOL_SOCKET,SO_REUSEADDR,&ok,sizeof(ok))==-1){ fprintf(stderr,"setsockopt SO_REUSEADDR failed:%m\n"); return -1; } } sockaddr_in addr; memset(&addr,0,sizeof(addr)); addr.sin_family=AF_INET; addr.sin_port=htons(bind_port); if(bind_ip.size()){ inet_pton(AF_INET,bind_ip.c_str(),&(addr.sin_addr)); printf("bind (%s:%d)\n",bind_ip.c_str(),bind_port); }else{ addr.sin_addr.s_addr=INADDR_ANY; printf("bind (0.0.0.0:%d)\n",bind_port); } if(bind(fd,(struct sockaddr*)&addr,sizeof(addr))==-1){ printf("bind failed:%m\n"); return -1; } printf("listen 5\n"); if(listen(fd,5)==-1){ printf("listen failed:%m\n"); return -1; } if(delay_time){ sleep(delay_time); } signal(SIGPIPE,sig_handler); while(1){ sockaddr_in cli_addr; socklen_t cli_addr_size=sizeof(cli_addr); printf("accept ...\n"); int conn_fd=accept(fd,(struct sockaddr*)&cli_addr,&cli_addr_size); if(conn_fd==-1){ printf("accept failed:%m\n"); return -1; } char cli_ip[INET6_ADDRSTRLEN]; inet_ntop(AF_INET,&(cli_addr.sin_addr),cli_ip,sizeof(cli_ip)); printf("client (%s:%d)\n",cli_ip,ntohs(cli_addr.sin_port)); if(echo_char){ char data[1]; int ret=read(conn_fd,data,sizeof(data)); if(ret==-1){ printf("read failed:%m\n"); }else{ printf("read succeed=%d\n",ret); } ret=write(conn_fd,data,sizeof(data)); if(ret==-1){ printf("write failed:%m\n"); }else{ printf("write succeed=%d\n",ret); } } close(conn_fd); } return 0; }
6.3. viewsockopt.cc
#include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <netinet/tcp.h> #include <sys/time.h> #include <cstdio> union val{ int i; struct linger l; struct timeval t; }; static const char* sock_str_flag(union val* v){ static char buf[1024]; snprintf(buf,sizeof(buf),"%s",v->i?"on":"off"); return buf; } static const char* sock_str_value(union val* v){ static char buf[1024]; snprintf(buf,sizeof(buf),"%d",v->i); return buf; } static const char* sock_str_linger(union val* v){ static char buf[1024]; snprintf(buf,sizeof(buf),"l_onoff=%s,l_linger=%d", v->l.l_onoff?"on":"off", v->l.l_linger); return buf; } static const char* sock_str_timeval(union val* v){ static char buf[1024]; snprintf(buf,sizeof(buf),"(%d,%d)", v->t.tv_sec, v->t.tv_usec); return buf; } static struct sock_opt{ const char* opt_str; int opt_level; int opt_name; const char* (*func)(union val* v); } sock_opts[]={ {"SO_ERROR",SOL_SOCKET,SO_ERROR,sock_str_value}, {"SO_KEEPALIVE",SOL_SOCKET,SO_KEEPALIVE,sock_str_flag}, {"SO_LINGER",SOL_SOCKET,SO_LINGER,sock_str_linger}, {"SO_RCVBUF",SOL_SOCKET,SO_RCVBUF,sock_str_value}, {"SO_SNDBUF",SOL_SOCKET,SO_SNDBUF,sock_str_value}, {"SO_RCVLOWAT",SOL_SOCKET,SO_RCVLOWAT,sock_str_value}, {"SO_SNDLOWAT",SOL_SOCKET,SO_SNDLOWAT,sock_str_value}, {"SO_RCVTIMEO",SOL_SOCKET,SO_RCVTIMEO,sock_str_timeval}, {"SO_SNDTIMEO",SOL_SOCKET,SO_SNDTIMEO,sock_str_timeval}, {"SO_REUSEADDR",SOL_SOCKET,SO_REUSEADDR,sock_str_flag}, {"TCP_MAXSEG",IPPROTO_TCP,TCP_MAXSEG,sock_str_value}, {"TCP_NODELAY",IPPROTO_TCP,TCP_NODELAY,sock_str_flag}, {"TCP_QUICKACK",IPPROTO_TCP,TCP_QUICKACK,sock_str_flag}, {"TCP_CORK",IPPROTO_TCP,TCP_CORK,sock_str_flag}, {NULL,0,0,NULL} }; int main(){ for(int i=0;sock_opts[i].opt_str;i++){ printf("%s:",sock_opts[i].opt_str); int fd=-1; switch(sock_opts[i].opt_level){ case SOL_SOCKET: case IPPROTO_TCP: fd=socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); break; default: continue; } union val v; socklen_t size=sizeof(v); getsockopt(fd, sock_opts[i].opt_level, sock_opts[i].opt_name, &v,&size); printf("%s\n",sock_opts[i].func(&v)); close(fd); } return 0; }
6.4. name2addr.cc
#include <netdb.h> #include <sys/socket.h> #include <arpa/inet.h> #include <cstdio> static void print_hostent(const char* s,const struct hostent* p){ printf("====================%s====================\n",s); if(p->h_name){ printf("hostname:%s\n",p->h_name); } if(p->h_aliases && p->h_aliases[0]){ printf("alias:\n"); for(int i=0;p->h_aliases[i];i++){ printf("\t%s\n",p->h_aliases[i]); } } if(p->h_addr_list && p->h_addr_list[0]){ printf("ip:\n"); for(int i=0;p->h_addr_list[i];i++){ char ip[INET6_ADDRSTRLEN]; inet_ntop(p->h_addrtype,p->h_addr_list[i],ip,sizeof(ip)); printf("\t%s\n",ip); } } } int main(int argc,char* const argv[]){ if(argc!=2){ fprintf(stderr,"usage:%s hostname\n",argv[0]); return -1; } const char* hostname=argv[1]; char buf[16*1024]; struct hostent ent; struct hostent* entp; int herrno=0; { //AF_INET gethostbyname2_r(hostname,AF_INET,&ent,buf,sizeof(buf),&entp,&herrno); if(!entp){ fprintf(stderr,"gethostbyname2_r(%s,AF_INET) failed:%s\n", hostname,hstrerror(herrno)); goto next1; }else{ print_hostent("IPv4",entp); } } next1: { //AF_INET6 gethostbyname2_r(hostname,AF_INET6,&ent,buf,sizeof(buf),&entp,&herrno); if(!entp){ fprintf(stderr,"gethostbyname2_r(%s,AF_INET6) failed:%s\n", hostname,hstrerror(herrno)); goto next2; }else{ print_hostent("IPv6",entp); } } next2: return 0; }
6.5. addr2name.cc
#include <netdb.h> #include <sys/socket.h> #include <arpa/inet.h> #include <cstdio> #include <cstring> static void print_hostent(const char* s,const struct hostent* p){ printf("====================%s====================\n",s); if(p->h_name){ printf("hostname:%s\n",p->h_name); } if(p->h_aliases && p->h_aliases[0]){ printf("alias:\n"); for(int i=0;p->h_aliases[i];i++){ printf("\t%s\n",p->h_aliases[i]); } } if(p->h_addr_list && p->h_addr_list[0]){ printf("ip:\n"); for(int i=0;p->h_addr_list[i];i++){ char ip[INET6_ADDRSTRLEN]; inet_ntop(p->h_addrtype,p->h_addr_list[i],ip,sizeof(ip)); printf("\t%s\n",ip); } } } int main(int argc,char* const argv[]){ if(argc!=2){ fprintf(stderr,"usage:%s ip\n",argv[0]); return -1; } const char* ip=argv[1]; char buf[16*1024]; struct hostent ent; struct hostent* entp; int herrno=0; if(strchr(ip,':')){ //ipv6. struct sockaddr_in6 addr; inet_pton(AF_INET6,ip,&(addr.sin6_addr)); gethostbyaddr_r(&(addr.sin6_addr),sizeof(addr.sin6_addr),AF_INET6, &ent,buf,sizeof(buf),&entp,&herrno); if(!entp){ fprintf(stderr,"gethostbyaddr_r(%s,AF_INET6) failed:%s\n", ip,hstrerror(herrno)); return -1; } print_hostent("IPv6",entp); }else{ //ipv4. struct sockaddr_in addr; inet_pton(AF_INET,ip,&(addr.sin_addr)); gethostbyaddr_r(&(addr.sin_addr),sizeof(addr.sin_addr),AF_INET, &ent,buf,sizeof(buf),&entp,&herrno); if(!entp){ fprintf(stderr,"gethostbyaddr_r(%s,AF_INET) failed:%s\n", ip,hstrerror(herrno)); return -1; } print_hostent("IPv4",entp); } return 0; }