Umbra: A Disk-Based System with In-Memory Performance
https://umbra-db.com/interface/
文章主要讨论怎么把In-Memory DBMS怎么和Disk结合起来,Umbra是在Hyper系统上进行改进的,Hyper是个全内存数据库,Umbra给它增加Disk支持让它支持处理更大容量的数据。
为啥需要给全内存数据库增加Disk支持,是因为RAM容量增长速度放缓,想在RAM里面放置更多的数据成本没有办法线性增长,而Disk/SSD容量和价格比还可以继续保持。
Moreover, we currently observe two hardware trends that cast strong doubt on the viability of pure in-memory systems. First, RAM sizes are not increasing significantly any more. Ten years memory for a reasonable price. Today, affordable main memory sizes might have increased to 2 TB, but going beyond that dispro- portionately increases the costs. As costs usually have to be kept under control though, this has caused the growth of main memory sizes in servers to subside in the recent years.
On the other hand, SSDs have achieved astonishing improve- ments over the past years. A modern 2 TB M.2 SSD can read with about 3.5 GB/s, while costing only $500. In comparison, 2 TB of server DRAM costs about $20 000, i.e. a factor of 40 more. By placing multiple SSDs into one machine we can get excellent read bandwidths at a fraction of the cost of a pure DRAM solution. Because of this, Lomet argues that pure in-memory DBMSs are uneconomical [15]. They offer the best possible performance, of course, but they do not scale beyond a certain size and are far too expensive for most use cases. Combining large main memory buffers with fast SSDs, in contrast, is an attractive alternative as the cost is much lower and performance can be nearly as good.
全内存数据库和Disk-Based数据库的主要差别在于,全内存中的数据单元大小是可变的,而传统DBMS则是按照fixed size来管理page的。如果全内存数据库直接按照fixed size来管理的话,那么就不可避免地会涉及到内存整理(比如large string需要切分和整合),overhead会比较大。而如果可以按照varied size来管理的话,和全内存数据库结合会更好。整个过程还是会有disk/memory之间的swap,但是逻辑上会更加简单和直接。
A key ingredient for achieving this is a novel buffer manager that combines low-overhead buffering with variable-size pages. Com- pared to a traditional disk-based system, in-memory systems have the major advantage that they can do away with buffering, which both eliminates overhead and greatly simplifies the code. For disk- based systems, common wisdom dictates to use a buffer manager with fixed-size pages. However, while this simplifies the buffer manager itself, it makes using the buffer manager exceedingly diffi- cult. For example, large strings or lookup tables for dictionary com- pression often cannot easily be stored in a single fixed-size page, and both complex and expensive mechanisms are thus required all over the database system in order to handle large objects. We ar-utively if needed. Such a design leads to a more complex buffer manager, but it greatly simplifies the rest of the system. If we can rely upon the fact that a dictionary is stored consecutively in mem- ory, decompression is just as simple and fast as in an in-memory system. In contrast, a system with fixed-size pages either needs to re-assemble (and thus copy) the dictionary in memory, or has to use a complex and expensive lookup logic.
我理解全内存数据库操作方式是:
- 系统启动的时候将数据全部加载到内存
- 所有操作都在内存中进行,读写可以以log的方式进行持久化。
- 后台有线程不断地生成checkpoint
所以Umbra要解决的问题2中如果内存不够的情况,使用disk来做backup, 有点类似kernel swap, 但是target在全内存数据库这个场景下。
Umbra buffer management也比较简单,就是在为不同的object size分配不同size class的连续地址空间,如下图所示。它利用的原因是virtual memory allocate出来之后并不直接对应物理内存,所以它可以对每个size class分配巨大的虚拟内存空间,然后内存操作都映射到这个空间上。如果unpin某个page的话,可以先将page写入到磁盘上并且复用之前的物理内存。
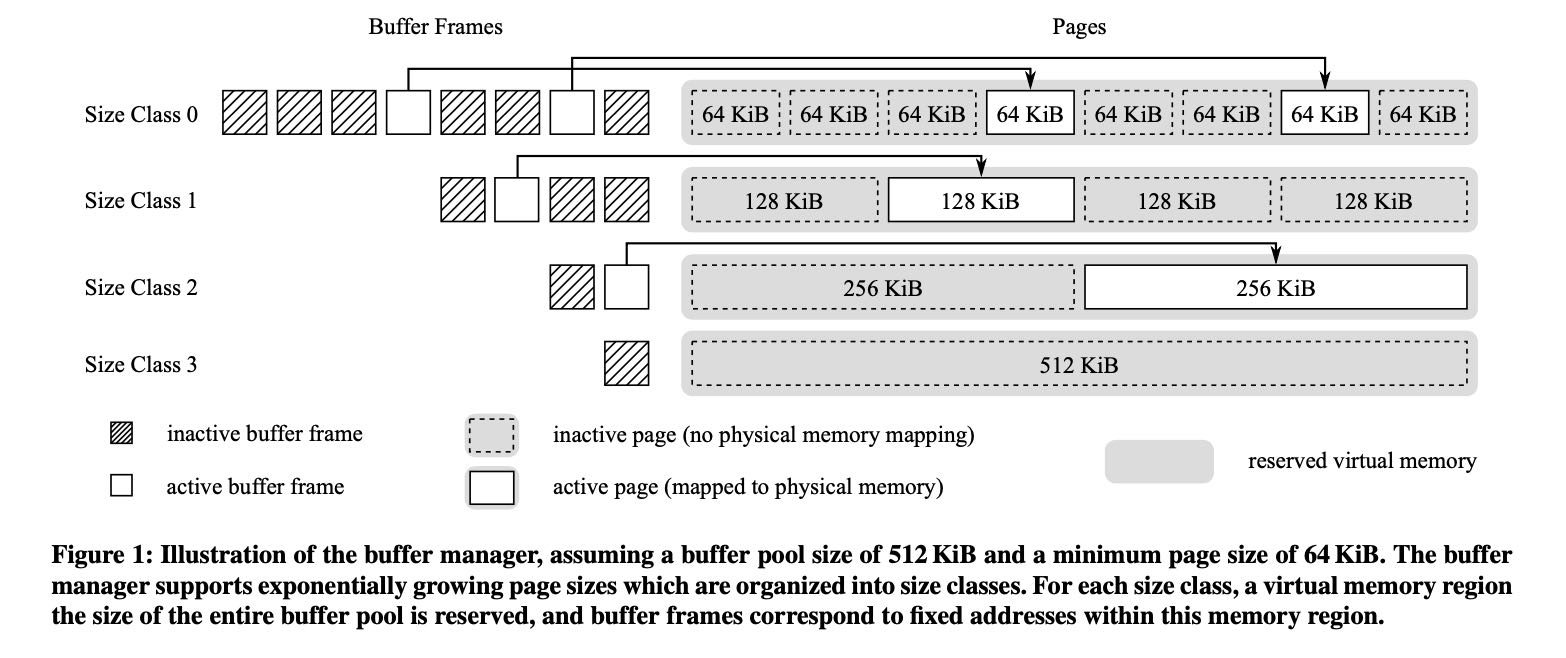
When a buffer frame becomes active, the buffer manager uses the pread system call to read data from disk into memory. This data is stored at the virtual memory address associated with the buffer frame, at which point the operating system creates an actual map- ping from these virtual addresses to physical memory (cf. Figure 1). If a previously active buffer frame becomes inactive due to eviction from the buffer pool, we first write any changes to the page data back to disk using the pwrite system call, and subsequently allow the kernel to immediately reuse the associated physical memory. On Linux, this can be achieved by passing the MADV_DONTNEED flag to the the madvise system call. This step is critical to ensure that the physical memory consumption of the buffer pool does not exceed the configured buffer pool size, as several times more vir- tual memory is allocated internally (cf. Figure 1). As the memory mappings used in the buffer manager are not backed by any actual files (see above), the madvise call incurs virtually no overhead.
During operation, the buffer manager keeps track of the total size of all pages that are currently held in memory. It ensures that their total size never exceeds the maximum size of the buffer pool by evicting pages to disk as required. Umbra employs essentially the same replacement strategy as LeanStore [14], where we specula- tively unpin pages but do not immediately evict them from main memory. These cooling pages are then placed in a FIFO queue, and eventually evicted if they reach the end of the queue.
Pointer Swizzling. 一个64bits指针可以同时表示 a)内存地址 b)某个disk page. 不过pointer swizzling最大的难题是,如果某个page在memory/disk之间转换的话,如何放持有这个pointer的对象感知到? 目前Umbra是按照B+tree来组织数据的,然后确保只有一个owner(parent)持有指针。
Due to the decentralized nature of pointer swizzling, some op- erations such as page eviction become more complicated. For ex- ample, the same page could be referenced by several swips, all of which would need to be updated when the page is evicted to disk. However, we cannot easily locate all swips that reference a given page, which makes it hard to maintain consistency [14]. To counter this, all buffer-managed data structures in Umbra are required to or- ganize their constituent pages in a (possibly degenerate) tree. This ensures by design that each page is referenced by exactly one own- ing swip, and no further swips besides that owning swip need to be updated when a page is loaded or evicted. In case of B+-trees, for instance, this entails that leaf pages may not contain references to their siblings, as this would require that leaf pages are referenced by more than one swip. We will outline below how efficient scans can still be implemented in light of these restrictions.

Versioned Latches. 可以实现exclusive/shared/optimistic mode.
- state = 1 表示 exclusive mode
- state = n + 1 表示有n个线程共享这个latch(In the rare case that the state bits are not sufficient to count the number of threads, an additional 64-bit integer is used as an overflow counter)
- version 表示这个latch的版本号

String Handling. 其中prefix可以用来加速字符串比较,offset/pointer中两个bits来区分这个string的存储类型:persistent, transient(query lifetime), temporary(function lifetime). 因为对全内存数据库也不太了解,所以这里面subtlety也没有办法体会到。

Statistics. 使用抽样统计以及增量更新sketches的方式来维护统计值
In Umbra, we instead implement a scalable online reservoir sampling algorithm that we recently de- veloped [2]. In doing so, we can ensure that the query optimizer always has access to an up-to-date sample with minimal overhead.
Besides a random sample, we additionally maintain updateable HyperLogLog sketches on each individual column. As we have shown previously [6], our implementation of updateable Hyper- LogLog sketches can provide almost perfect cardinality estimates on individual columns with moderate overhead. Furthermore, this enables the query optimizer to utilize highly accurate multi-column estimates through a combination of sketch-based and sampling- based estimation [6].
Compilation & Execution 和Hyper将一个Pipeline/Fragment编译成为整体代码不同,Umbra将Fragment拆分成为了多个steps/operators, 多个operators之间可以以不同的并行度执行,同时可以做到更好的调度。同时在编译上,选择了使用更加精简的IR表示,可以不依赖LLVM使用比较小的代价就生成代码,LLVM的问题在于它的general-purpose所以有许多overhead但是Umbra不需要。 执行期间并不是立刻将IR编译为机器码的,而是解释+编译,并且Umbra IR -> LLVM IR很容易,或许可以使用LLVM JIT功能。
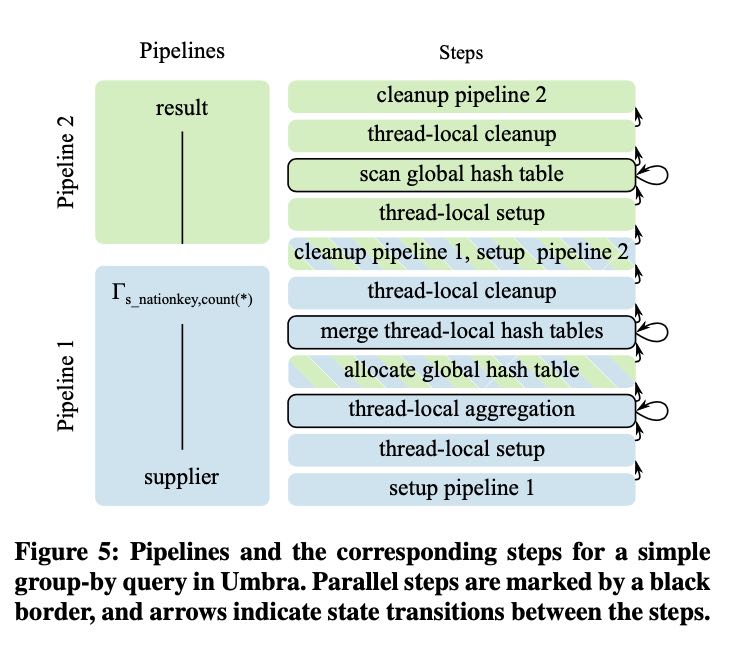
In generated code, each step corresponds to a separate function which can be called by the runtime system of Umbra. For the pur- pose of query execution, these individual steps are viewed as states with well-defined transitions between steps, which are orchestrated by the query executor of Umbra (cf. Figure 5). In case of multi- threaded steps, a morsel-driven approach is employed to distribute the available work to worker threads, and the step function pro- cesses a single morsel on each invocation [12].
Another important difference is that query code is not generated directly in the LLVM intermediate representation (IR) language. Instead, we implement a custom lightweight IR in Umbra, which allows us to generate code efficiently without relying on LLVM. Since LLVM is designed as a versatile general-purpose code gener- ation framework, it can incur a noticeable overhead due to function- ality that is not required by Umbra anyway. By implementing a cus- tom IR, we can avoid this potentially expensive roundtrip through LLVM during code generation.
Unlike HyPer, Umbra does not immediately compile this IR to optimized machine code. Instead, we employ an adaptive compila- tion strategy which strives to optimize the tradeoff between com- pilation and execution time for each individual step [10]. Initially, the IR associated with a step is always translated into an efficient bytecode format and interpreted by a virtual machine backend. For parallel steps, the adaptive execution engine then tracks progress in- formation to decide whether compilation could be beneficial [10]. If applicable, the Umbra IR is translated into LLVM IR and com- pilation is delegated to the LLVM just-in-time compiler. Conceptu- ally, our IR language is designed to closely resemble a subset of the LLVM IR, such that translation from our format into LLVM format can be achieved cheaply and in linear time.