Throttle的Python实现
参考文章和实现有:
- How we built rate limiting capable of scaling to millions of domains
- https://github.com/leandromoreira/nginx-lua-redis-rate-measuring/blob/master/src/resty-redis-rate.lua
throttle实现依赖于FlowRate来计算rate,根据计算出来的rate和设置的rate相比较,来决定delay多长时间。
下面是一种FlowRate的原始实现。这种实现的缺陷是没有办法对流量做到平滑处理:如果一段时间没有流量,相当于积累了比较多的时间片, 然后突然来了很大的流量的话,计算出来的rate会被低估。
class NaiveFlowRate:
def __init__(self):
self.cnt = 0
self.ts = int(time.time())
def update(self, inc=1):
self.cnt += inc
now_ts = int(time.time())
return self.cnt / (now_ts - self.ts)
文章里面给出来的FlowRate实现则解决了这个问题,它会估算过去1分钟的rate,而对更早时间的流量会忽略掉。 当然这里1分钟也可以配置,可以实现成为5分钟,10分钟等等,只不过1分钟的实现会更加简单(可以在一个redis pipeline下3条指令完成)。 下面代码中,RedisFlowRate是用redis做存储可以用来做跨进程限速,而SmoothFlowRate则只能用于单进程限速
class RedisFlowRate:
def __init__(self, client: redis.StrictRedis, key_prefix):
self.key_prefix = key_prefix
self.client: redis.StrictRedis = client
def update(self, key, value=1):
value = int(value)
cur_ts = int(date_util.current_timestamp())
cur_sec, cur_min = cur_ts % 60, (cur_ts // 60) % 60
past_min = (cur_min + 59) % 60
past_key = '{}{}.{}'.format(self.key_prefix, key, past_min)
cur_key = '{}{}.{}'.format(self.key_prefix, key, cur_min)
pipe = self.client.pipeline(transaction=False)
pipe.get(past_key)
pipe.incr(cur_key, value)
pipe.expire(cur_key, 2 * 60 - cur_sec)
resp = pipe.execute()
past_counter = int(resp[0]) if resp[0] else 0
current_counter = max(0, int(resp[1]) - value)
current_rate = past_counter * ((60 - cur_sec) / 60) + current_counter
return current_rate / 60
class SmoothFlowRate:
def __init__(self, unit=60):
self.last_count = 0
self.cur_count = 0
self.cur_ts = 0
self.cur_bucket = 0
self.unit = unit
def __str__(self):
return '{}(ts = {}, bucket = {}, last = {}, curr = {})'.format(
__class__.__name__, self.cur_ts, self.cur_bucket,
self.last_count, self.cur_count)
def update(self, inc=1):
now = int(date_util.current_timestamp())
bucket = now // self.unit
if self.cur_bucket == 0:
self.cur_bucket = bucket
elif self.cur_bucket < (bucket - 1):
self.last_count = 0
self.cur_count = 0
elif self.cur_bucket == (bucket - 1):
self.last_count = self.cur_count
self.cur_count = 0
self.cur_ts = now
self.cur_bucket = bucket
self.cur_count += inc
last_ratio = (self.cur_ts % self.unit) / self.unit
rate = (1 - last_ratio) * self.last_count + self.cur_count
rate = rate / self.unit # per seconds.
return rate
实现完了FlowRate之后就可以实现Throttle了:
- 假设过去1分钟,共处理了N条记录
- 估算rate是R, 而要求rate是R0,这里假设rate单位是/s
- N ~= 60 * R
- 应该delay时间应该是 N/R0 - N/R = (60 * R) / R0 - 60 = 60 * (R/R0 - 1)
class SmoothThrottle(object):
def __init__(self, rate_limit):
self.rate_limit = rate_limit
self.flow_rate = SmoothFlowRate(unit=60)
def set_rate_limit(self, v):
self.rate_limit = v
def run(self, inc=1):
rate = self.flow_rate.update(inc)
if not self.rate_limit or rate < self.rate_limit:
return 0
delay = self.flow_rate.unit * (rate - self.rate_limit) / self.rate_limit
if delay > 0.1:
date_util.delay_seconds(delay)
return delay
return 0
为了确保rate计算正确以及throttle可以正常限速,我做了如下测试:
- 测试起两个线程 producer, worker, 之间通过Q传输数据
- producer 按照一定速度产生数字序列
- 按照高斯分布产生数字 value, 然后等待0.1s
- 所以我们估算出来的rate是 value/0.1 = 10 * value
- worker 不断处理数字序列
- 如果是验证rate计算正确,那么就直接更新flow rate,然后读取估算的rate
- 如果是验证throttle正常限速,那么更新flow rate之后立刻限速,然后读取估算的rate
throttle = SmoothThrottle(rate_limit=50)
flow_rate = throttle.flow_rate
class Worker:
def __init__(self, Q):
self.Q: Queue = Q
self.rates = []
self._exit = False
def run(self):
Q = self.Q
while True:
try:
v = self.Q.get(timeout=0.1)
except queue.Empty:
v = None
if self._exit:
break
if v is not None:
throttle.run(v) # 测试限速是否工作
# flow_rate.update(v) # 测试rate是否估算正确
rate = flow_rate.update(0)
self.rates.append(rate)
def exit(self):
self._exit = True
class Producer:
def __init__(self, Q, mean, std):
self.Q: Queue = Q
self.mean = mean
self.std = std
def run(self):
size = 1000
for x in range(5):
values = np.random.normal(loc= self.mean, scale= self.std, size=size)
for v in values:
self.Q.put(v)
date_util.delay_seconds(0.1)
date_util.delay_seconds(100)
def collect():
Q = queue.Queue(maxsize=1)
worker = Worker(Q)
t1 = threading.Thread(target=worker.run)
producer = Producer(Q, mean=10, std=5)
t2 = threading.Thread(target=producer.run)
t1.start()
t2.start()
t2.join()
worker.exit()
t1.join()
rates = worker.rates
print('# of pts = {}'.format(len(rates)))
return rates
产生的数字序列符合高斯分布N(10, 5),所以估计出来的rate应该是100.
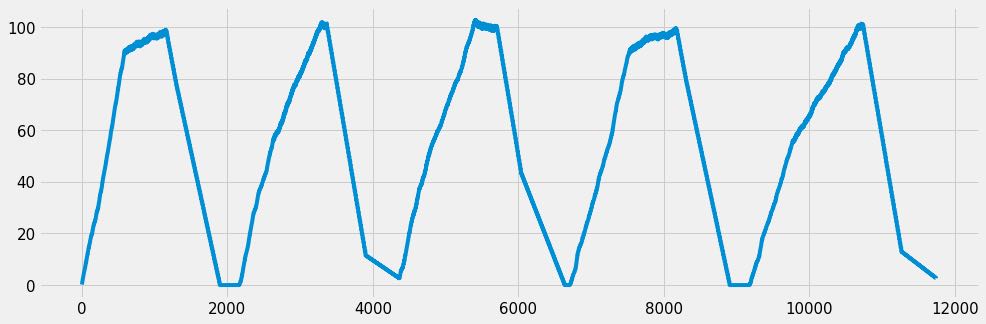
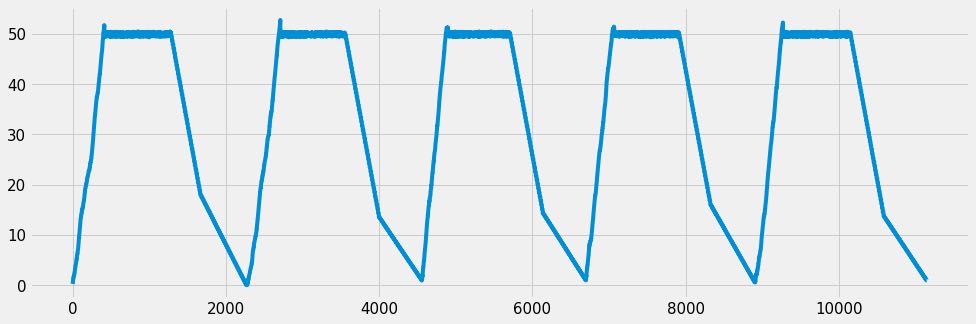
throttle的rate_limit设置为50, 所以在50上会被削平.
UPDATE@202002 最近发现这个限速器在生产环境有点问题,没有对突发流量做到限速,而且实际速度和限制速度差别还蛮大的。
同事推荐给了我两个实现让我看看:
- https://github.com/EvoluxBR/python-redis-rate-limit
- http://bobintornado.github.io/development/2017/05/15/Rate-Limiting-Using-Redis-in-Python.html
其实这些实现都是使用固定窗口(有1s, 10s, 60s)的,在这个时间窗口内设置一个次数上限。而我上面的rate limiter是60s的近似滑动窗口,在限速上会更加平滑一些。
滑动窗口比固定窗口有个好处是,没有办法预支流量。比如10s窗口的开始,固定窗口允许在第1s内请求10 * limit_qps的,这就是一个尖峰,但是滑动窗口会考虑到当前窗口大小,不会出现这样的情况。
滑动窗口和固定窗口都会存在窗口结束流量突增的问题。比如在一个10s窗口,前面9s没有请求,最后1s请求理论上是可以达到 10 * limit_qps的。1s固定窗口没有这个问题,窗口足够小了。
不管任何窗口以及窗口大小的rate limiter, 等待是个问题。等待时间还相对比较好算,即使是随机一个也没有问题。我觉得等待区分乐观等待和悲观等待:
- 乐观等待:假设现在rate还行,我就先提交,如果发现rate limit过线了,我就撤销并且等待。然后不断重试,直到ok.
- 悲观等待:我先获取当前rate, 如果过线了,我就等待。然后不断重试,直到ok再进行提交。
我实现的限速器使用了乐观等待,但是并不是正确的实现,在超量的情况下面并没有撤销。在并发程度比较小的时候没有什么问题,当并发度非常高的时候,误差程度非常大。 考虑到撤销在实现上比较复杂,所以我还是改成了悲观等待的实现方式,虽然这样在基本不超量情况下会多一次redis交互,但是先照顾正确性吧。
class SmoothThrottle(object):
def __init__(self, rate_limit):
self.rate_limit = rate_limit
self.flow_rate = SmoothFlowRate(unit=60)
def set_rate_limit(self, v):
self.rate_limit = v
def _wait_once(self, rate):
if not self.rate_limit or rate < self.rate_limit:
return 0
delay = self.flow_rate.unit * (rate - self.rate_limit) / self.rate_limit
if delay > 0.1:
date_util.delay_seconds(delay + random.random() * 0.5)
return delay
return 0
def get_rate(self):
return self.flow_rate.update(0)
def _wait(self):
res = 0
while True:
rate = self.get_rate()
v = self._wait_once(rate)
res += v
if v == 0:
break
return res
def run(self, inc=1):
res = self._wait()
rate = self.flow_rate.update(inc)
return res + self._wait_once(rate)
不过不管是乐观还是悲观等待,在最后一次提交的时候还是可能会出现超量的情况,毕竟整个操作并不是原子的。如果所有这些逻辑都写在lua脚本提交到redis的话,是可以保证原子性的。