The Hadoop Distributed File System
Table of Contents
http://storageconference.org/2010/Papers/MSST/Shvachko.pdf @ 2010
1. INTRODUCTION AND RELATED WORK
- Hadoop clus-ters at Yahoo! span 25 000 servers, and store 25 petabytes of application data, with the largest cluster being 3500 servers.(最大的集群有3.5k机器,所有机器共有25k,存储了25PB的数据)
2. ARCHITECTURE
2.1. NameNode
- The file content is split into large blocks (typically 128 megabytes, but user selectable file-by-file) and each block of the file is inde-pendently replicated at multiple DataNodes (typically three, but user selectable file-by-file). (文件内容会切块默认是128MB但是对于每个文件可选,另外副本数目对于每个文件也是可选的默认是3)
- HDFS keeps the entire namespace in RAM. The inode data and the list of blocks belonging to each file comprise the meta-data of the name system called the image. The persistent record of the image stored in the local host’s native files system is called a checkpoint. The NameNode also stores the modifica-tion log of the image called the journal in the local host’s na-tive file system.(对于namenode内容称为image,分为checkpoint和journal两个部分)。
- For improved durability, redundant copies of the checkpoint and journal can be made at other servers. Dur-ing restarts the NameNode restores the namespace by reading the namespace and replaying the journal.(对于这个image在远程上面也会进行备份来提高可用性)
- The locations of block replicas may change over time and are not part of the persistent checkpoint.(这个和gfs相同都是通过chunkserver启动之后汇报chunk来完成的)
2.2. DataNode
- Each block replica on a DataNode is represented by two files in the local host’s native file system. The first file contains the data itself and the second file is block’s metadata including checksums for the block data and the block’s generation stamp.(block存储上包含两个文件,一个是数据文件,另外一个就是checksum文件,并且包含block generation stamp。这个stamp可能就是用来标记old chunk的,类似于gfs里面的chunk version number)
- During startup each DataNode connects to the NameNode and performs a handshake. The purpose of the handshake is to verify the namespace ID and the software version of the DataNode. If either does not match that of the NameNode the DataNode automatically shuts down.(datanode启动的时候会和namenode交互,交换namespace id和software version id,如果两者不匹配的话,那么datanode就会shutdown。这个是为了处理兼容性问题,这个在从cdh3升级到cdh4时候需要考虑。兼容性问题猜想会涉及到RPC以及存储格式处理上)
- The namespace ID is assigned to the file system instance when it is formatted. The namespace ID is persistently stored on all nodes of the cluster(格式化的时候就会分配namespace id). A DataNode that is newly initialized and without any namespace ID is permitted to join the cluster and receive the cluster’s namespace ID. #note: 新增的chunkserver应该也会分配到这个namespace id。这个namespace id可以首先分配在namenode以及已知的datanode上面
- After the handshake the DataNode registers with the NameNode. DataNodes persistently store their unique storage IDs. The storage ID is an internal identifier of the DataNode, which makes it recognizable even if it is restarted with a differ-ent IP address or port. The storage ID is assigned to the DataNode when it registers with the NameNode for the first time and never changes after that.(对于每个新注册的datanode都会被namenode分配一个唯一的id,这个id和ip以及port都对应上了,并且以后不会改变。
- A DataNode identifies block replicas in its possession to the NameNode by sending a block report. A block report contains the block id, the generation stamp and the length for each block replica the server hosts. The first block report is sent immedi-ately after the DataNode registration. Subsequent block reports are sent every hour and provide the NameNode with an up-to-date view of where block replicas are located on the cluster.(datanode会进行block report给namenode,包括所有block的id,generation stamp,以及长度信息。第一次的block report是在启动时候,后面小时级别进行report)
#todo: 这里不太理解为啥需要汇报length,是不是每个文件长度不同?难道利用二分查找offset对应的文件?#note: 每个文件还是需要知道长度的,这样就可以知道往这个chunk上还能写多少个字节达到一个max chuk size,然后再写下一个块 - During normal operation DataNodes send heartbeats to the NameNode to confirm that the DataNode is operating and the block replicas it hosts are available. The default heartbeat in-terval is three seconds. If the NameNode does not receive a heartbeat from a DataNode in ten minutes the NameNode con-siders the DataNode to be out of service and the block replicas hosted by that DataNode to be unavailable. The NameNode then schedules creation of new replicas of those blocks on other DataNodes.(namenode和datanode之间每隔3s会有一次heartheat检测datanode是否存活,如果10min没有任何回复的话,那么认为datanode挂掉。namenode可能需要重新扫描所有在这个datandoe上面block然后做re-replication
- Heartbeats from a DataNode also carry information about total storage capacity, fraction of storage in use, and the num-ber of data transfers currently in progress. These statistics are used for the NameNode’s space allocation and load balancing decisions.(heartbeat信息包含这个datanode上面存储容量,以及磁盘使用百分比,以及这个datanode上面和client有多少数据量交互,这些指标都会用来当作namenode进行空间分配以及负载均衡的选择)
- The NameNode does not directly call DataNodes. It uses replies to heartbeats to send instructions to the DataNodes. The instructions include commands to:(namenode并不会直接datanode信息的,而是在heartbeat后面直接piggyback回去的,包括下面这些信息。对于这些信息没有考虑返回,但是并不是很大的问题)
- replicate blocks to other nodes;
- remove local block replicas;
- re-register or to shut down the node;
- send an immediate block report.
2.3. HDFS Client
- When an application reads a file, the HDFS client first asks the NameNode for the list of DataNodes that host replicas of the blocks of the file. It then contacts a DataNode directly and requests the transfer of the desired block. (选择任意一个datanode进行交互)
- When a client writes, it first asks the NameNode to choose DataNodes to host repli-cas of the first block of the file. The client organizes a pipeline from node-to-node and sends the data. When the first block is filled, the client requests new DataNodes to be chosen to host replicas of the next block.
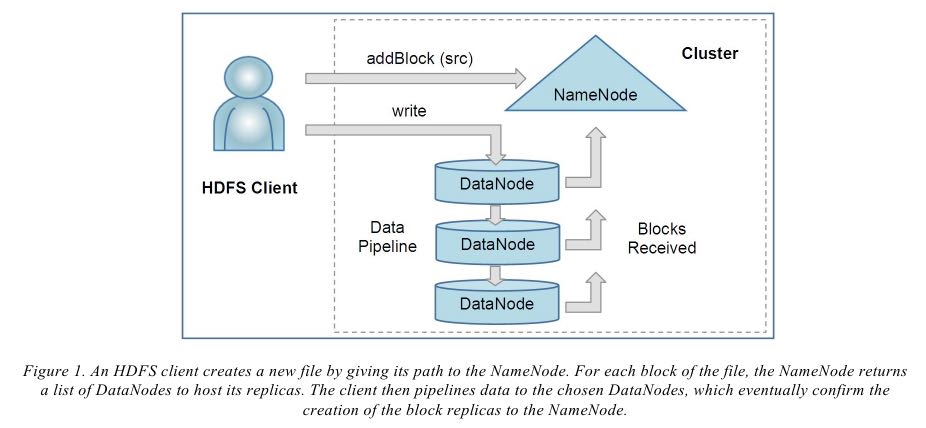
- Unlike conventional file systems, HDFS provides an API that exposes the locations of a file blocks. This allows applica-tions like the MapReduce framework to schedule a task to where the data are located, thus improving the read perform-ance. (提供API能够知道每个文件block的分布位置,这样在mapreduce时候可以尽可能地locally来访问文件)
- It also allows an application to set the replication factor of a file. By default a file’s replication factor is three. For criti-cal files or files which are accessed very often, having a higher replication factor improves their tolerance against faults and increase their read bandwidth.(通过增加副本数量的话可以用来提高错误容忍并且提高读带宽,但是同时也会增加写带宽)
2.4. Image and Journal
- During startup the NameNode ini-tializes the namespace image from the checkpoint, and then replays changes from the journal until the image is up-to-date with the last state of the file system. A new checkpoint and empty journal are written back to the storage directories before the NameNode starts serving clients.(namenode启动的时候会读取checkpoint信息并且回放journal内容,之后会生成新的checkpoint然后才开始serve client)
- If either the checkpoint or the journal is missing, or be-comes corrupt, the namespace information will be lost partly or entirely. In order to preserve this critical information HDFS can be configured to store the checkpoint and journal in multiple storage directories. Recommended practice is to place the di-rectories on different volumes, and for one storage directory to be on a remote NFS server. The first choice prevents loss from single volume failures, and the second choice protects against failure of the entire node. If the NameNode encounters an error writing the journal to one of the storage directories it automati-cally excludes that directory from the list of storage directories. The NameNode automatically shuts itself down if no storage directory is available.(如果checkpoint或者journal如果丢失的话,那么会namespace会信息丢失。namespace信息还是非常关键的。为了防止这个问题,可以让image信息在1)不同的目录下面备份 2)写到remote server。如果写一个目录失败的话,那么这个目录就直接丢弃下次不写,对于机器也应该是这样的。如果namenode没有任何地方可以记录的话,那么直接shutdown self。)
- The NameNode is a multithreaded system and processes requests simultaneously from multiple clients. Saving a trans-action to disk becomes a bottleneck since all other threads need to wait until the synchronous flush-and-sync procedure initi-ated by one of them is complete. In order to optimize this process the NameNode batches multiple transactions initiated by different clients. When one of the NameNode’s threads ini-tiates a flush-and-sync operation, all transactions batched at that time are committed together. Remaining threads only need to check that their transactions have been saved and do not need to initiate a flush-and-sync operation.(如果多个client同时写的话,每个线程都进行flush-sync操作会阻塞其他线程。可以将这些操作全部batch起来然后提交。这个提交之需要其中一个线程发起即可,完成之后其他线程之需要检查已经提交了那么就不需要sync了。这个倒是可以减少disk io)
2.5. CheckpointNode
- The NameNode in HDFS, in addition to its primary role serving client requests, can alternatively execute either of two other roles, either a CheckpointNode or a BackupNode. The role is specified at the node startup.(checkpoint node和backup node是namenode一种,可以在启动的时候直接指定角色)
- The CheckpointNode periodically combines the existing checkpoint and journal to create a new checkpoint and an empty journal.(checkpoint node做的事情就是合并chkp以及journal)
- The CheckpointNode usually runs on a different host from the NameNode since it has the same memory re-quirements as the NameNode. (对于checkpoint node来说通常也会host在另外一机器上面因为和namenode占用了相同内存大小。我理解这个checkpointnode并没有服务,而仅仅是为了做checkpoint。在合并chkp需要在内存里面进行merge以及update等操作,所以也是相当占用内存的)
- It downloads the current check-point and journal files from the NameNode, merges them lo-cally, and returns the new checkpoint back to the NameNode(实现上比较奇怪,是从namenode download下chkp和journal来进行合并的,然后将chkp传回给namenode)
- For a large cluster, it takes an hour to process a week-long journal. Good practice is to create a daily checkpoint.(对于大型clutser来说恢复周级别的journal需要小时,所以每天做一次chkp还是比较合理的)
2.6. BackupNode
- A recently introduced feature of HDFS is the BackupNode. Like a CheckpointNode, the BackupNode is capable of creating periodic checkpoints, but in addition it maintains an in-memory, up-to-date image of the file system namespace that is always synchronized with the state of the NameNode.(backupnode和chkpnode一样会进行checkpoint,但是backupnode和namenode保持的是一致的数据,因为不需要像chkp node一样进行download)
- The BackupNode can be viewed as a read-only NameNode. It contains all file system metadata information except for block locations. It can perform all operations of the regular NameNode that do not involve modification of the namespace or knowledge of block locations.(backup node可以作为一个readonly的name node,但是里面缺少所有的block locations信息。所以如果namenode挂掉的话,backupnode还是需要所有的datanode进行block report)
2.7. Upgrades, File Sytsems Snapshots
- During software upgrades the possibility of corrupting the system due to software bugs or human mistakes increases. The purpose of creating snapshots in HDFS is to minimize potential damage to the data stored in the system during upgrades.(创建snapshot的原因就是为了减少系统升级带来的风险)
- The snapshot (only one can exist) is created at the cluster administrator’s option whenever the system is started.(注意snapshot只能够存在一份,从过程上来看的话,snapshot时间非常长,而不像gfs一样轻量)
- If a snapshot is requested, the NameNode first reads the checkpoint and journal files and merges them in memory. Then it writes the new checkpoint and the empty journal to a new location, so that the old checkpoint and journal remain unchanged. (首先会做一个新的checkpoint,这样老的checkpoint以及journal就没有变化)
- During handshake the NameNode instructs DataNodes whether to create a local snapshot. The local snapshot on the DataNode cannot be created by replicating the data files direc-tories as this will require doubling the storage capacity of every DataNode on the cluster. Instead each DataNode creates a copy of the storage directory and hard links existing block files into it. When the DataNode removes a block it removes only the hard link, and block modifications during appends use the copy-on-write technique. Thus old block replicas remain un-touched in their old directories.(在heartbeat时候通知datanode进行snapshot。对于snapshot来说实现并不是重新copy所有的chunk,这样会造成空间翻倍,是在新的目录下面做硬链接,链接到原来老的目录下面文件。这样如果之后有写操作的话使用COW)
- The cluster administrator can choose to roll back HDFS to the snapshot state when restarting the system. The NameNode recovers the checkpoint saved when the snapshot was created. DataNodes restore the previously renamed directories and initi-ate a background process to delete block replicas created after the snapshot was made. Having chosen to roll back, there is no provision to roll forward. The cluster administrator can recover the storage occupied by the snapshot by commanding the sys-tem to abandon the snapshot, thus finalizing the software up-grade.(如果想进行回滚的话,那么namenode就会使用原来老的checkpoint并且将之后写的chunk全部删除。所以一旦回滚之后的话,就没有办法roll forward了。当然也可以直接放弃snapshot)
- System evolution may lead to a change in the format of the NameNode’s checkpoint and journal files, or in the data repre-sentation of block replica files on DataNodes. The layout ver-sion identifies the data representation formats, and is persis-tently stored in the NameNode’s and the DataNodes’ storage directories. During startup each node compares the layout ver-sion of the current software with the version stored in its stor-age directories and automatically converts data from older for-mats to the newer ones. The conversion requires the mandatory creation of a snapshot when the system restarts with the new software layout version.(系统的升级可能会导致格式上不识别,因为namenode以及datanode的存储目录来说都会带上layout version。这样如果namenode以及datanode升级之后的话,会自动地进行数据转换。但是这种转换要求系统重启时候创建一个snapshot)
3. FILE I/O OPERATIONS AND REPLICA MANGEMENT
3.1. File Read and Write
- HDFS im-plements a single-writer, multiple-reader model. The HDFS client that opens a file for writing is granted a lease for the file; no other client can write to the file. The writ-ing client periodically renews the lease by sending a heartbeat to the NameNode. When the file is closed, the lease is revoked. The lease duration is bound by a soft limit and a hard limit. Until the soft limit expires, the writer is certain of exclusive access to the file. If the soft limit expires and the client fails to close the file or renew the lease, another client can preempt the lease. If after the hard limit expires (one hour) and the client has failed to renew the lease, HDFS assumes that the client has quit and will automatically close the file on behalf of the writer, and recover the lease. The writer's lease does not prevent other clients from reading the file; a file may have many concurrent readers.(HDFS提供的的是single-writer/multi-reader的实现,和gfs一样提供了lease机制,但是这个lease机制仅仅针对writer来说的。从功能上看,hdfs相对于gfs来说确实简单)
- An HDFS file consists of blocks. When there is a need for a new block, the NameNode allocates a block with a unique block ID and determines a list of DataNodes to host replicas of the block.(每个chunk都是通过master分配id的,并且决定那些datanodes来host这些chunk)
- The DataNodes form a pipeline, the order of which minimizes the total network distance from the client to the last DataNode. Bytes are pushed to the pipeline as a sequence of packets. The bytes that an application writes first buffer at the client side. After a packet buffer is filled (typically 64 KB), the data are pushed to the pipeline. The next packet can be pushed to the pipeline before receiving the acknowledgement for the previous packets. The number of outstanding packets is limited by the outstanding packets window size of the client.(pipeline实现方式是client首先写到D0,D0一旦接收完成之后就会向D1发送,同时ACK给client。这样client继续发送下一个packet。每个packet占据64KB.当然这里有一个窗口概念(前面说的窗口大小=1),这个窗口的大小也是可以配置的。)
- After data are written to an HDFS file, HDFS does not pro-vide any guarantee that data are visible to a new reader until the file is closed. If a user application needs the visibility guaran-tee, it can explicitly call the hflush operation. Then the current packet is immediately pushed to the pipeline, and the hflush operation will wait until all DataNodes in the pipeline ac-knowledge the successful transmission of the packet. (写入的数据并不一定保证就可以被看到,除非这个文件关闭了。如果希望可以立刻可见的话,那么可以使用hflush调用。hflush调用的话会等待到所有的datanodes都确认所有的消息才会返回)
- When a client opens a file to read, it fetches the list of blocks and the locations of each block replica from the NameNode. The locations of each block are ordered by their distance from the reader. When reading the content of a block, the client tries the closest replica first. If the read attempt fails, the client tries the next replica in sequence. A read may fail if the target DataNode is unavailable, the node no longer hosts a replica of the block, or the replica is found to be corrupt when checksums are tested.(client读取文件的时候会获得这个文件所有chunk的位置,从离client最近的chunkserver开始尝试)
- HDFS permits a client to read a file that is open for writing. When reading a file open for writing, the length of the last block still being written is unknown to the NameNode. In this case, the client asks one of the replicas for the latest length be-fore starting to read its content.(如果这个文件在写的时候同时在读的话,那么client读取到最后一个chunkEOF之后,需要重新询问一个replics当前chunk的长度,这样才能够继续往前读。如果跨越chunk的话,那么可能还需要和NameNode之间进行通信。
3.2. Block Placement
- HDFS estimates the network bandwidth between two nodes by their distance. The distance from a node to its parent node is assumed to be one. A distance between two nodes can be cal- culated by summing up their distances to their closest common ancestor. A shorter distance between two nodes means that the greater bandwidth they can utilize to transfer data.(node和node之间的距离用来评估之间的网络带宽。两个node距离是通常是通过计算两个点到共同祖先的距离。node到switch距离通常计算为1,这只是简单的算法)
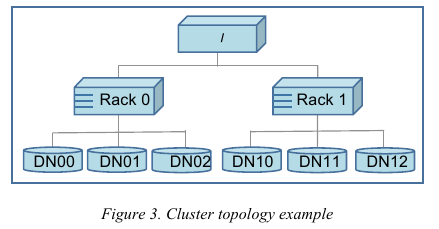
- HDFS allows an administrator to configure a script that re-turns a node’s rack identification given a node’s address. The NameNode is the central place that resolves the rack location of each DataNode. When a DataNode registers with the NameNode, the NameNode runs a configured script to decide which rack the node belongs to. If no such a script is config-ured, the NameNode assumes that all the nodes belong to a default single rack.(HDFS允许配置脚本来计算两个node之间的距离。对于默认计算的方式就是按照所有的node都在相同的rack下面)
- The default HDFS block placement policy provides a tradeoff between minimizing the write cost, and maximizing data reliability, availability and aggregate read bandwidth.(默认的block placement是在写代价,数据可靠性以及可用性,同时考虑读取带宽上的折中)
- When a new block is created, HDFS places the first replica on the node where the writer is located, (写入的点是local)
- the second and the third replicas on two different nodes in a different rack, (不同的节点同时不同的rack)
- and the rest are placed on random nodes with restrictions that (其他节点随机放置)
- no more than one replica is placed at one node and no more than two replicas are placed in the same rack when the number of replicas is less than twice the number of racks.(确保不会在统一个节点有两个replicas,确保在一个rack下面不会存在两个以上的replics【如果replicas的个数小于两倍的rack的个数】)
- The default HDFS replica placement policy can be summa-rized as follows:
- No Datanode contains more than one replica of any block.
- No rack contains more than two replicas of the same block, provided there are sufficient racks on the cluster.
3.3. Replication management
- The NameNode detects that a block has become under- or over-replicated when a block report from a DataNode arrives.
- When a block becomes over replicated, the NameNode chooses a replica to remove. The NameNode will prefer not to reduce the number of racks that host replicas, and secondly prefer to remove a replica from the DataNode with the least amount of available disk space. The goal is to balance storage utilization across DataNodes without reducing the block’s availability.(如果over-replicated的话,那么会选择一个replica移除。首先考虑不要减少rack数目,然后考虑从磁盘空间空闲最少的节点删除。)
- When a block becomes under-replicated, it is put in the rep- lication priority queue. A block with only one replica has the highest priority, while a block with a number of replicas that is greater than two thirds of its replication factor has the lowest priority. (对于under-replicated来说,会将这个请求加入队列。1个replica有最高优先级)
- A background thread periodically scans the head of the replication queue to decide where to place new replicas. Block replication follows a similar policy as that of the new block placement. (后台线程扫描这个queue决定如何进行这个block replication,使用的策略和block placement非常类似)
- If the number of existing replicas is one, HDFS places the next replica on a different rack. In case that the block has two existing replicas, (如果只有1个replica的话,那么放在其他rack上面)
- if the two existing replicas are on the same rack, the third replica is placed on a different rack; (如果两个已经同一个rack的话,那么放在其他rack上面)
- other-wise, the third replica is placed on a different node in the same rack as an existing replica. Here the goal is to reduce the cost of creating new replicas.(其他情况的话,那么在相同的rack但是不同的node上面放置)
- The NameNode also makes sure that not all replicas of a block are located on one rack. If the NameNode detects that a block’s replicas end up at one rack, the NameNode treats the block as under-replicated and replicates the block to a different rack using the same block placement policy described above. After the NameNode receives the notification that the replica is created, the block becomes over-replicated. The NameNode then will decides to remove an old replica because the over-replication policy prefers not to reduce the number of racks.(另外namenode会确保不是所有的节点都在一个rack上面。如果是这样的话,那么认为这个under-replicated,然后在其他rack创建一个副本。之后回检测到over-replicated,从原来的rack所删除一个副本)
3.4. Balancer
在block replacement里面没有考虑磁盘利用率的情况,这样容易造成在一个节点上面过热如果这个节点是刚上来的话。但是这样也会造成inbalance的问题。
- The balancer is a tool that balances disk space usage on an HDFS cluster. It takes a threshold value as an input parameter, which is a fraction in the range of (0, 1). A cluster is balanced if for each DataNode, the utilization of the node (ratio of used space at the node to total capacity of the node) differs from the utilization of the whole cluster (ratio of used space in the clus-ter to total capacity of the cluster) by no more than the thresh-old value.(如何来定义balanced的状态。如果对于每个datanode节点的磁盘利用率,和全局的磁盘利用率相差很大的话,那么就认为inbalanced.所以我们需要提供一个阈值来定义这个差距)
- It iteratively moves replicas from DataNodes with higher utilization to DataNodes with lower utilization. One key requirement for the balancer is to maintain data availability. When choosing a replica to move and deciding its destination, the balancer guarantees that the decision does not reduce either the number of replicas or the number of racks.(不断地从高磁盘利用率node将数据移到低磁盘利用率node,但是同时也需要考虑可用性,原则上就是不能够减少chunk的racks数量)
- The balancer optimizes the balancing process by minimiz-ing the inter-rack data copying. If the balancer decides that a replica A needs to be moved to a different rack and the destina- tion rack happens to have a replica B of the same block, the data will be copied from replica B instead of replica A.(寻找就近的chunk进行移动)
- A second configuration parameter limits the bandwidth consumed by rebalancing operations. The higher the allowed bandwidth, the faster a cluster can reach the balanced state, but with greater competition with application processes.(另外可以配置传输速率。高速率的话使得整个balance过程回更快,但是占用更多的带宽)
3.5. Block Scanner
block scanner主要是用来发现corrupted chunk。每次扫描的时候,chunkserver会调整读取带宽确保可以在一定period内完成(可配)。对于在每次扫描的时候,校验的时间会记录到chunkserver的内存里面(这个作用应该是确保不会频繁地造成校验)。client如果读取一个block成功的话,也会通知datanode,这个通知也回被作为一次校验,更新校验时间。
Whenever a read client or a block scanner detects a corrupt block, it notifies the NameNode. The NameNode marks the replica as corrupt, but does not schedule deletion of the replica immediately. Instead, it starts to replicate a good copy of the block. Only when the good replica count reaches the replication factor of the block the corrupt replica is scheduled to be re-moved. This policy aims to preserve data as long as possible. So even if all replicas of a block are corrupt, the policy allows the user to retrieve its data from the corrupt replicas.(如果block scanner或者是cient发现corrupted block的话,回通知namenode。namenode回进行标记但是不先删除,而是先将做一个好的副本,然后再将坏的chunk删除。)
3.6. Decommissioing
decommission的作用主要就是为了让node下线。
- 首先标记node为decom状态
- 之后namenode会将node上面所有的chunk全部迁移走
- 完成之后将这个node标记,这个时候node就可以直接下线了。
3.7. Inter-Cluster Data Copy
使用distcp这样的mapreduce来运行集群上面的文件copy。
4. PRACTICE AT YAHOO!
Large HDFS clusters at Yahoo! include about 3500 nodes. A typical cluster node has:
- 2 quad core Xeon processors @ 2.5ghz
- Red Hat Enterprise Linux Server Release 5.1
- Sun Java JDK 1.6.0_13-b03
- 4 directly attached SATA drives (one terabyte each)
- 16G RAM
- 1-gigabit Ethernet
集群配置如下:
- Forty nodes in a single rack share an IP switch. The rack switches are connected to each of eight core switches. The core switches provide connectivity between racks and to out-of-cluster re-sources. #todo: 这个网络拓扑是怎么配置的?
- For each cluster, the NameNode and the BackupNode hosts are specially provisioned with up to 64GB RAM; applica-tion tasks are never assigned to those hosts. (nn和bn有64GB内存考虑比较吃内存,并且在这个机器上面也不分配其他程序)
- 3500节点总共占据9.8PB数据,有效数据占据3.3GB使用3副本方式。
在这个3500节点的cluster
- 60million files
- 63million blocks(每个文件的block比较低)
- 平均每个datanode上面有5.4w个blocks
- 每天user app产生2million文件
4.1. Durability of Data
- for a large cluster, the prob-ability of losing a block during one year is less than .005
分析数据丢失
- The key understanding is that about 0.8 percent of nodes fail each month. (每个月大约有0.8%的机器挂掉)
- 这就意味着在3500nodes集群来说,每天会有1-2台机器挂掉。
- 上面放置了大约5.4w个blocks
- 而这些blocks可以在大概2min内完成,因为丢失block概率是非常小的。
- Correlated failure of nodes(主要就是掉电和交换机故障)
- In addition to total failures of nodes, stored data can be corrupted or lost. The block scanner scans all blocks in a large cluster each fortnight and finds about 20 bad replicas in the process.(14天扫描一次每天发现大约20个bad replicas)
4.2. Caring for the Commons
- permission
- quota
- The total space available for data storage is set by the num-ber of data nodes and the storage provisioned for each node. Early experience with HDFS demonstrated a need for some means to enforce the resource allocation policy across user communities. Not only must fairness of sharing be enforced, but when a user application might involve thousands of hosts writing data, protection against application inadvertently ex-hausting resources is also important.(总体的磁盘大小限制以及每个node上面磁盘大小限制。另外也需要为不同的用户进行资源分配,一方面是因为公平原因,另外一方面是防止用户恶意行为可能导致整个系统资源耗尽)
- For HDFS, because the system metadata are always in RAM, the size of the namespace (number of files and directories) is also a finite resource. To manage storage and namespace resources, each directory may be assigned a quota for the total space occupied by files in the sub-tree of the namespace beginning at that directory. A sepa-rate quota may also be set for the total number of files and di-rectories in the sub-tree. (为了限制namenode metadata占用量,可以限制每个目录下面文件占用磁盘空间大小,以及文件数目)
- mapreduce
- While the architecture of HDFS presumes most applications will stream large data sets as input, the MapReduce program-ming framework can have a tendency to generate many small output files (one from each reduce task) further stressing the namespace resource. (如果运行mapreduce的话可能回产生非常多的小文件对namenode造成压力)
- As a convenience, a directory sub-tree can be collapsed into a single Hadoop Archive file. A HAR file is similar to a familiar tar, JAR, or Zip file, but file system opera-tion can address the individual files for the archive, and a HAR file can be used transparently as the input to a MapReduce job.(为了解决这个问题,某个目录下面的文件合并成为一个文件,成为Hadoop Archive file,这样可以减少小文件数目,而对于HAR的访问对于mapreduce来说是透明的)
4.3. Benchmarks
5. FUTURE WORK
- NameNode的自动恢复。现在BackupNode已经算是Warm NameNode了,但是缺少block reports,所以如果切换到BackupNode的话还需要block reports比较耗时。如果BackupNode能够同时接收block reports的话,那么可以作为Hot NameNode存在。
- NameNode的扩展性问题。NameNode现在瓶颈在于内存使用上,尤其是当内存块使用完的时候出现GC更加糟糕有时候需要restart。虽然我们鼓励用户创建大文件,并且增加了配额管理以及archive tool,但是依然没有解决本质问题。