The Design of a Practical System for Fault-Tolerant Virtual Machines
https://pdos.csail.mit.edu/6.824/papers/vm-ft.pdf
https://pdos.csail.mit.edu/6.824/notes/l-vm-ft.txt
https://pdos.csail.mit.edu/6.824/papers/vm-ft-faq.txt
这个功能在VMware vSphere 4.0里面实现,性能最多降低10%。FT的实现方式是primary/backup(hot), 之间通过replay log来做状态同步。
常见应用(非网络密集型)下logging之间传输带宽使用控制在20Mb/s一下,这里面常见应用比如下面几个:
- SPECJbb2005 CPU/MEM密集
- Kernel Compile CPU/MMU/Disk密集
- Oracle Swingbench 数据库benchmark测试
- MS-SQL DVD Store 数据库benchmark测试
通过状态机(state-machine)方式来实现同步,最重要的就是解决日志内容问题。如果动作是deterministic的话,那么只要保证order就好,如果是non-deterministic的话,除了保证order之外,还需要将涉及到不确定行为的内容都记录下来。这个问题有点像mysql replication, 如果我们使用SQL statement format来做log的话,那么在碰到类似 `now()` 这样的调用时时候就会出现分歧;但是如果使用row format来做log的话则没有问题,但是就是体积比较大;最终使用了mixed format作为replication log比较合适。
现在这个FT-VM实现只支持单核(uni-processor), 可以想象多核(multi-processor)是不好给instructions定序的。比如process A和B都访问了读写了某一块内存,那么如何给这两个事件定序呢?这是一个很大的问题。文章的后面提到是否可以考虑使用transactional memory这样的技术。不仅是primary VM执行的时候使用单核,在replay log的时候也使用单核。
下图是FT的基本实现
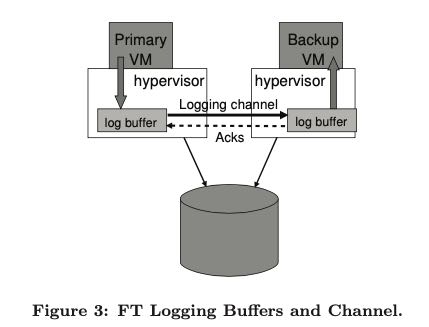
- primary/backup VM有各自的小磁盘来存储log
- log之间通过logging channel传输
- 工作磁盘使用的shared disk
使用shared disk有几个好处:
- shared disk可以承担做分布式锁的问题
- 可以不考虑data同步的问题
- backup VM不用做write disk
文章后面还谈论到了两种alternatives:
- shared vs. non-shared disk.
- 如果不使用shared disk的话,那么backup VM就需要自己写disk.
- non-shared disk需要实现初始同步
- backup VM disk可能会限制replay的速度
- executing disk reads on backup VM.
- primary VM将read data发送到backup VM
- 是backup VM去自己读,好处是可以显著降低logging bandwidth
关于检测故障,文章使用了两种办法:
- primary/backup之间有UDP心跳,如果backup在一段时间内没有收到心跳的话,就要尝试切换
- split-brain solved by shared disk
- primary会主动检测logging channel的情况:
- 如果消费比较慢的话,那么primary VM也会降低自己执行速率(少见)
- 如果长时间没有消费(差距很大)的话,那么backup VM其实可以被踢掉
关于自动切换的话,其实还有个蛮tricky的问题,这个问题有点类似memory barrier. primary VM在做任何side-effect/output之前,必须确保之前所有的logs都被backup VM ack. 这样如果primary VM在执行了side-effect操作之后挂掉的话,backup VM确保可以拿到所有的历史信息继续执行。不过即便如何,我们依然没有办法保证exactly-once.
Duplicate output at cut-over is pretty common in replication systems Clients need to keep enough state to ignore duplicates Or be designed so that duplicates are harmless
VMware有个叫做VMotion的东西,可以对某个VM进行迁移,这个迁移过程非常快。我猜想基本操作就是快照+changelog,这个过程和他们的FT模型是非常类似的,只不过changelog改成logging channel,而primary VM在前移完成之后不必销毁。
关于如何处理timer interrupts和network packet. 注意处理network packet使用bounce buffer也是为了给write data memory定序。 因为network packet数据写入到data memory是通过DMA来完成的,那么DMA和CPU发起的操作是没有办法全局定序的。
Each log entry: instruction #, type, data.
FT's handling of timer interrupts
Goal: primary and backup should see interrupt at
the same point in the instruction stream
Primary:
FT fields the timer interrupt
FT reads instruction number from CPU
FT sends "timer interrupt at instruction X" on logging channel
FT delivers interrupt to primary, and resumes it
(this relies on CPU support to interrupt after the X'th instruction)
Backup:
ignores its own timer hardware
FT sees log entry *before* backup gets to instruction X
FT tells CPU to interrupt (to FT) at instruction X
FT mimics a timer interrupt to backup
FT's handling of network packet arrival (input)
Primary:
FT tells NIC to copy packet data into FT's private "bounce buffer"
At some point NIC does DMA, then interrupts
FT gets the interrupt
FT pauses the primary
FT copies the bounce buffer into the primary's memory
FT simulates a NIC interrupt in primary
FT sends the packet data and the instruction # to the backup
Backup:
FT gets data and instruction # from log stream
FT tells CPU to interrupt (to FT) at instruction X
FT copies the data to backup memory, simulates NIC interrupt in backup
Why the bounce buffer?
We want the data to appear in memory at exactly the same point in
execution of the primary and backup.
Otherwise they may diverge.
VM-FT的好处是什么?什么时候应该在application层面做replication?
When might FT be attractive?
Critical but low-intensity services, e.g. name server.
Services whose software is not convenient to modify.
What about replication for high-throughput services?
People use application-level replicated state machines for e.g. databases.
The state is just the DB, not all of memory+disk.
The events are DB commands (put or get), not packets and interrupts.
Result: less fine-grained synchronization, less overhead.
GFS use application-level replication, as do Lab 2 &c
后面是否支持了multi-processors呢?
VMware KB (#1013428) talks about multi-CPU support. VM-FT may have switched from a replicated state machine approach to the state transfer approach, but unclear whether that is true or not. http://www.wooditwork.com/2014/08/26/whats-new-vsphere-6-0-fault-tolerance/ http://www-mount.ece.umn.edu/~jjyi/MoBS/2007/program/01C-Xu.pdf
作者如何确定他们找到了所有的non-determinism?
Q: How were the creators certain that they captured all possible forms of non-determinism? A: My guess is as follows. The authors work at a company where many people understand VM hypervisors, microprocessors, and internals of guest OSes well, and will be aware of many of the pitfalls. For VM-FT specifically, the authors leverage the log and replay support from a previous a project (deterministic replay), which must have already dealt with sources of non-determinism. I assume the designers of deterministic replay did extensive testing and gained experience with sources of non-determinism that the authors of VM-FT use.