The Datacenter as a Computer
An Introduction to the Design of Warehouse-Scale Machines
Table of Contents
https://dl.acm.org/citation.cfm?id=1643608
介绍”现代“计算中心的各个方面。所谓”现代“的计算中心是区别于过去普通机房。”现代“计算中心通常是由一个组织进行建设, 然后只被这个组织或者是几个组织所使用;不仅关注性能更加关注性价比;通常采用同构机器,使用low-end server而不是high-end server; 将更多的精力花费在软件而非硬件上来优化整体效率等等。
这篇文章涉及的面比较多,包括软件设施,机房建设,硬件选购,制冷系统,成本效率计算,故障维修等。我打算先把这篇文章的目录放在这里,然后 按照目录对每个主题慢慢阅读。
1. Introduction
1.1 Warehouse-Scale Computers
1.2 Emphasis on Cost Efficiency
1.3 Not Just a Collection of Servers
1.4 One Datacenter vs. Several Datacenters
1.5 Why WSCs Might Matter to You
1.6 Architectural Overview of WSCs
1.6.1 Storage
1.6.2 Networking Fabric
1.6.3 Storage Hierarchy
1.6.4 Quantifying Latency, Bandwidth, and Capacity
1.6.5 Power Usage
1.6.6 Handling Failures
2. Workloads and Software Infrastructure
2.1 Datacenter vs. Desktop
2.2 Performance and Availability Toolbox
2.3 Cluster-Level Infrastructure Software
2.3.1 Resource Management
2.3.2 Hardware Abstraction and Other Basic Services
2.3.3 Deployment and Maintenance
2.3.4 Programming Frameworks
2.4 Application-Level Software
2.4.1 Workload Examples
2.4.2 Online: Web Search
2.4.3 Offline: Scholar Article Similarity
2.5 A Monitoring Infrastructure
2.5.1 Service-Level Dashboards
2.5.2 Performance Debugging Tools
2.5.3 Platform-Level Monitoring
2.6 Buy vs. Build
2.7 Further Reading
3. Hardware Building Blocks
3.1 Cost-Efficient Hardware
3.1.1 How About Parallel Application Performance?
3.1.2 How Low-End Can You Go?
3.1.3 Balanced Designs
4. Datacenter Basics
4.1 Datacenter Tier Classifications
4.2 Datacenter Power Systems
4.2.1 UPS Systems
4.2.2 Power Distribution Units
4.3 Datacenter Cooling Systems
4.3.1 CRAC Units
4.3.2 Free Cooling
4.3.3 Air Flow Considerations
4.3.4 In-Rack Cooling
4.3.5 Container-Based Datacenters
5. Energy and Power Efficiency
5.1 Datacenter Energy Efficiency
5.1.1 Sources of Efficiency Losses in Datacenters
5.1.2 Improving the Energy Efficiency of Datacenters
5.2 Measuring the Efficiency of Computing
5.2.1 Some Useful Benchmarks
5.2.2 Load vs. Efficiency
5.3 Energy-Proportional Computing
5.3.1 Dynamic Power Range of Energy-Proportional Machines
5.3.2 Causes of Poor Energy Proportionality
5.3.3 How to Improve Energy Proportionality
5.4 Relative Effectiveness of Low-Power Modes
5.5 The Role of Software in Energy Proportionality
5.6 Datacenter Power Provisioning
5.6.1 Deployment and Power Management Strategies
5.6.2 Advantages of Oversubscribing Facility Power
5.7 Trends in Server Energy Usage
5.8 Conclusions
5.8.1 Further Reading
6. Modeling Costs
6.1 Capital Costs
6.2 Operational Costs
6.3 Case Studies
6.3.1 Real-World Datacenter Costs
6.3.2 Modeling a Partially Filled Datacenter
7. Dealing with Failures and Repairs
7.1 Implications of Software-Based Fault Tolerance
7.2 Categorizing Faults
7.2.1 Fault Severity
7.2.2 Causes of Service-Level Faults
7.3 Machine-Level Failures
7.3.1 What Causes Machine Crashes?
7.3.2 Predicting Faults
7.4 Repairs
7.5 Tolerating Faults, Not Hiding Them
8. Closing Remarks
8.1 Hardware
8.2 Software
8.3 Economics
8.4 Key Challenges
8.4.1 Rapidly Changing Workloads
8.4.2 Building Balanced Systems from Imbalanced Components
8.4.3 Curbing Energy Usage
8.4.4 Amdahl's Cruel Law
8.5 Conclusions
1. Introduction
传统数据中心托管了大量中小应用,这些应用都跑在几台专有的机器上。这些机器通常都是属于不同组织的,它们之间是资源隔离的,通常也是异构的。
而WSCs和传统的数据中心不同:由一个组织管理,硬件和软件基本都是同构的,大量使用内部软件,资源共享,跑了数量不多但是规模都很大的应用。
Traditional datacenters, however, typically host a large number of relatively small- or medium-sized applications, each running on a dedicated hardware infrastructure that is de-coupled and protected from other systems in the same facility. Those datacenters host hardware and software for multiple organizational units or even different companies. Different computing systems within such a datacenter often have little in common in terms of hardware, software, or maintenance infrastructure, and tend not to communicate with each other at all.
WSCs currently power the services offered by companies such as Google, Amazon, Yahoo, and Microsoft’s online services division. They differ significantly from traditional datacenters: they belong to a single organization, use a relatively homogeneous hardware and system software platform, and share a common systems management layer. Often much of the application, middleware, and system software is built in-house compared to the predominance of third-party software running in conventional datacenters. Most importantly, WSCs run a smaller number of very large applications (or Internet services), and the common resource management infrastructure allows significant deployment flexibility. The requirements of homogeneity, single-organization control, and enhanced focus on cost efficiency motivate designers to take new approaches in constructing and operating these systems.
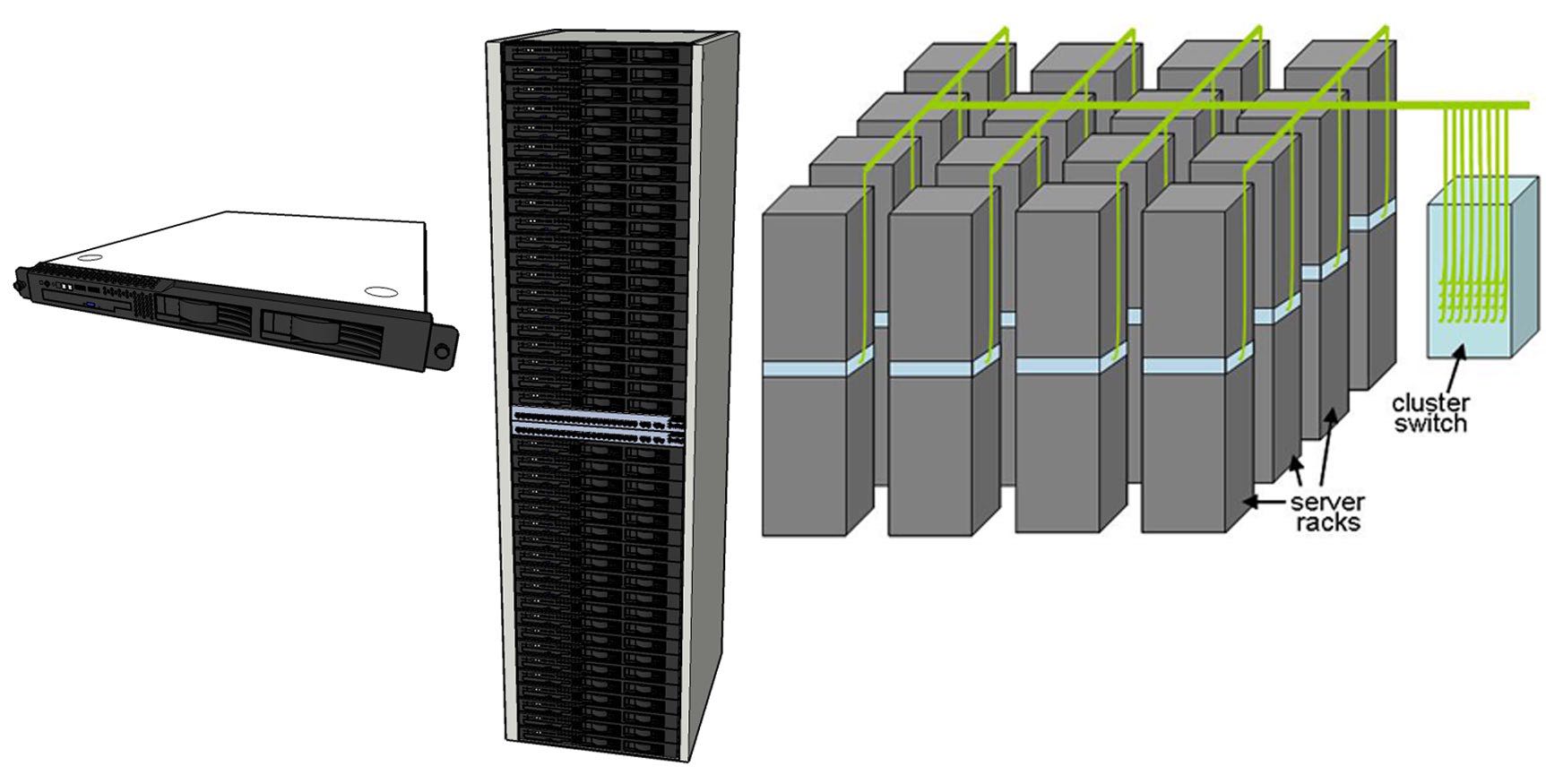
下图是典型的WSC内部基本配置:1U服务器,多个servers放在一个rack里面,之间通过intrarack交换机(1Gbps/10Gbps)通信。 而racks之间则通过cluster交换机通信,racks之间的带宽则没有那么大。
Typical elements in warehouse-scale systems: 1U server (left), 7´ rack with Ethernet switch (middle), and diagram of a small cluster with a cluster-level Ethernet switch/router (right).
A set of low-end servers, typically in a 1U or blade enclosure format, are mounted within a rack and interconnected using a local Ethernet switch. These rack-level switches, which can use 1- or 10-Gbps links, have a number of uplink connections to one or more cluster-level (or datacenter-level) Ethernet switches. This second-level switching domain can potentially span more than ten thousand individual servers.
存储使用个人桌面级别的硬盘而不是使用企业级别的硬盘,一方面是因为GFS通过复制做了容错。另外一方面即便是企业级别的硬盘, 可靠性之间差别也比较难,很难估计那些硬盘在什么时候需要更换。所以不如通过软件来做容错会更加稳定。
Some WSCs, including Google’s, deploy desktop-class disk drives instead of enterprise-grade disks because of the substantial cost differential between the two. Because that data are nearly always replicated in some distributed fashion (as in GFS), this mitigates the possibly higher fault rates of desktop disks. Moreover, because field reliability of disk drives tends to deviate significantly from the manufacturer’s specifications, the reliability edge of enterprise drives is not clearly established. For example, Elerath and Shah [24] point out that several factors can affect disk reliability more substantially than manufacturing process and design.
一个rack内部的servers之间可以通过1Gbps进行通信,racks上通常配置4-8个1Gbps的uplinks连接到cluster交换机上, 这是考虑到racks之间通信量是rack内部的5-10倍。所以程序员在编写代码的时候就要尽可能地exploit rack-level networking locality.
Commodity switches in each rack provide a fraction of their bi-section bandwidth for interrack communication through a handful of uplinks to the more costly cluster-level switches. For example, a rack with 40 servers, each with a 1-Gbps port, might have between four and eight 1-Gbps uplinks to the cluster-level switch, corresponding to an oversubscription factor between 5 and 10 for communication across racks. In such a network, programmers must be aware of the relatively scarce cluster-level bandwidth resources and try to exploit rack-level networking locality, complicating software development and possibly impacting resource utilization.
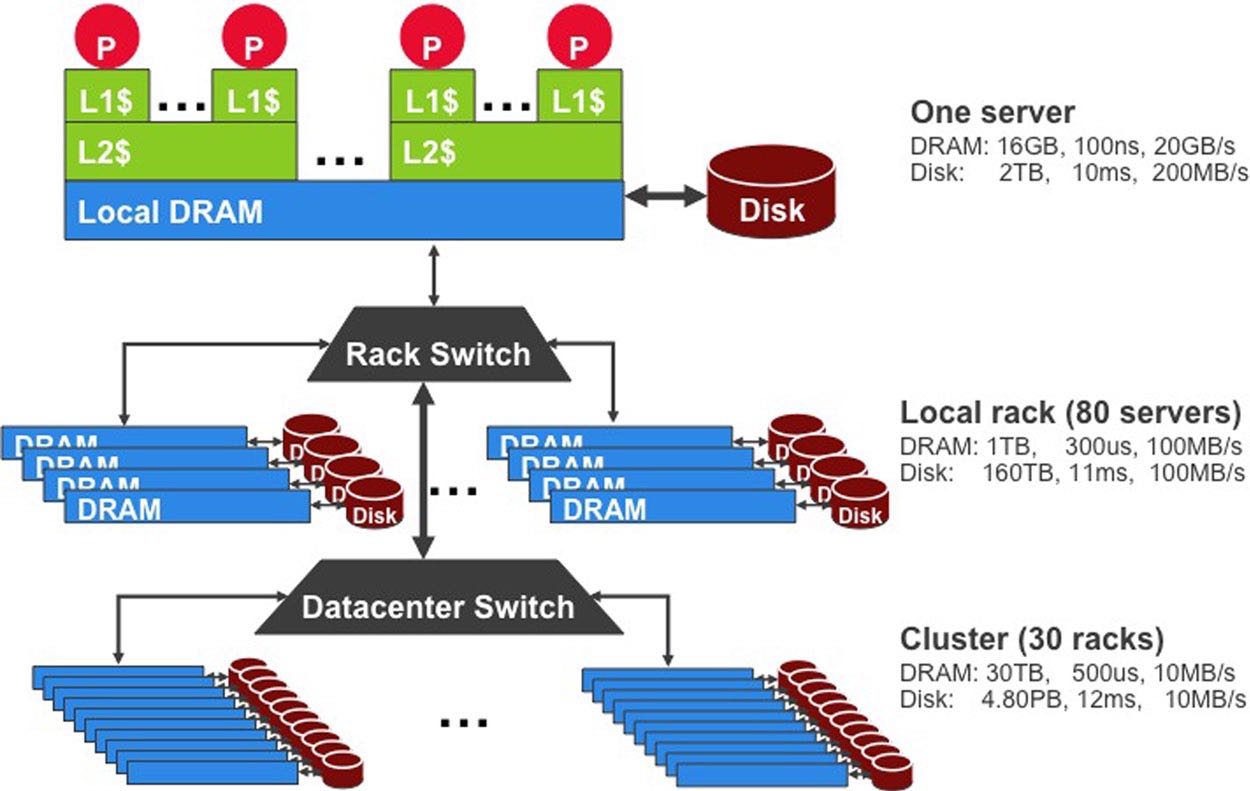
下图是整个集群级别的存储系统指标:
对2007年某个google的数据中心能耗高峰时期做分析,下面是每个硬件子系统能耗的百分比
| subsystem | ratio |
|---|---|
| CPUs | 33% |
| DRAM | 30% |
| Disks | 10% |
| Networking | 5% |
| Other(server) | 22% |
2. Workloads and Software Infrastructure
一个典型的WSC内部运行软件可以分为这么几层:
- platform-level software. 单机软件比如操作系统等。
- cluster-level infrastructure. 集群级别的基础架构,对集群资源做抽象。比如GFS, Mapreduce, Chubby等。
- resource management. Borg.
- hardware abstraction and basic services. GFS, Chubby.
- deployment and maintenance. Google's System Health Infrastructure.
- programming frameworks. MapReduce, BigTable.
- application-level software. 应用级别软件,比如Google Search, Gmail等。
在数据中心和在桌面计算机运行的软件有什么差别呢?
- ample parallelism. 数据中心有巨大的并行性
- workload churn. 工作负载的快速变动:互联网应用开发周期短,并且负载变动也会很大。
正式因为这点,我们不应该代码认为是不可变动的东西,这点和桌面系统软件。架构师考虑重写软件来充分利用硬件这种可能性。
A beneficial side effect of this aggressive software deployment environment is that hardware architects are not necessarily burdened with having to provide good performance for immutable pieces of code. Instead, architects can consider the possibility of significant software rewrites to take advantage of new hardware capabilities or devices
- platform homogeneity. 硬件通常是同构的.
- fault-free operation. 故障是常态。
所有二进制都需要链接类似gperftools这样的库,这样二进制不用重新部署就可以调查性能问题。
Finally, it is extremely useful to build the ability into binaries (or run-time systems) to obtain CPU, memory, and lock contention profiles of in-production programs. This can eliminate the need to redeploy new binaries to investigate performance problems.
3. Hardware Building Blocks
服务器选择low-end servers,配置和高配个人计算机差不多。不选择high-end servers(比如HPC的机器)主要是为了性价比考虑。 这节后面给出了一个简单的模型来说明,为什么选择low-end servers更加有优势。
Clusters of low-end servers are the preferred building blocks for WSCs today. This happens for a number of reasons, the primary one being the underlying cost-efficiency of low-end servers when compared with the high-end shared memory systems that had earlier been the preferred building blocks for the high-performance and technical computing space. Low-end server platforms share many key components with the very high-volume personal computing market, and therefore benefi more substantially from economies of scale.
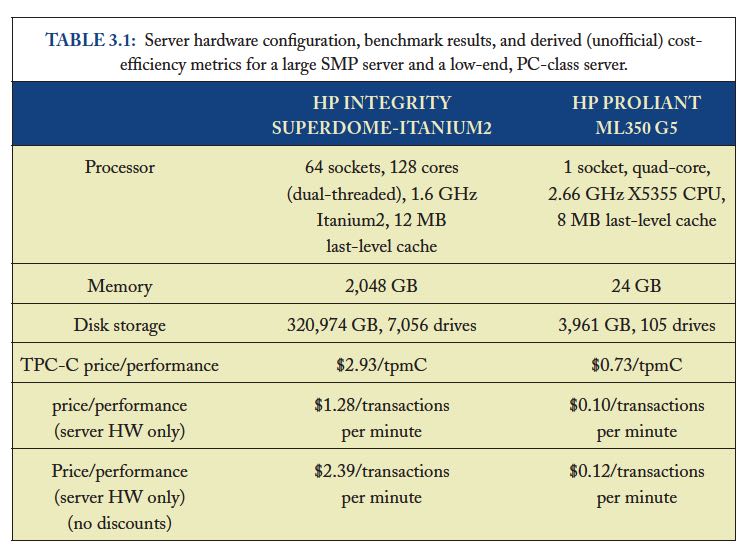
暂时不考虑通信效率,纯粹考虑单机的计算/存储性价比(用的是TPC-C基准测试)。
- low-end servers效率是high-end servers的3x
- 排除low-end servers存储成本的话,这个比例上升到12x(对于low-end servers来说存储占据了40%)
- 如果再排除high-end servers因为高价格带来实际购买折扣的话,那么这个比例到了20x
Data from the TPC-C benchmarking [85] entries are probably the closest one can get to information that includes both hardware costs and application-level performance in a single set of metrics. Therefore, for this exercise we have compared the best performing TPC-C system in late 2007—the HP Integrity Superdome-Itanium2 [87]—with the top system in the price/performance category (HP ProLiant ML350 G5 [88]). Both systems were benchmarked within a month of each other, and the TPC-C executive summaries include a breakdown of the costs of both platforms so that we can do a rational analysis of cost-efficiency.
The TPC-C benchmarking scaling rules arguably penalize the ProLiant in the official metrics by requiring a fairly large storage subsystem in the official benchmarking configuration: the storage subsystem for the ProLiant accounts for about three fourths of the total server hardware costs, as opposed to approximately 40% in the Superdome setup. If we exclude storage costs, the resulting price/performance advantage of the ProLiant platform increases by a factor of 3´ to more than 12´. Benchmarking rules also allow typical hardware discounts to be applied to the total cost used in the price/performance metric, which once more benefits the Superdome because it is a much more expensive system (~ $12M vs $75K for the ProLiant) and therefore takes advantage of deeper discounts. Assuming one would have the same budget to purchase systems of one kind or the other, it might be reasonable to assume a same level of discounting for either case. If we eliminate discounts in both cases, the ProLiant server hardware becomes roughly 20 times more cost-efficient than the Superdome.
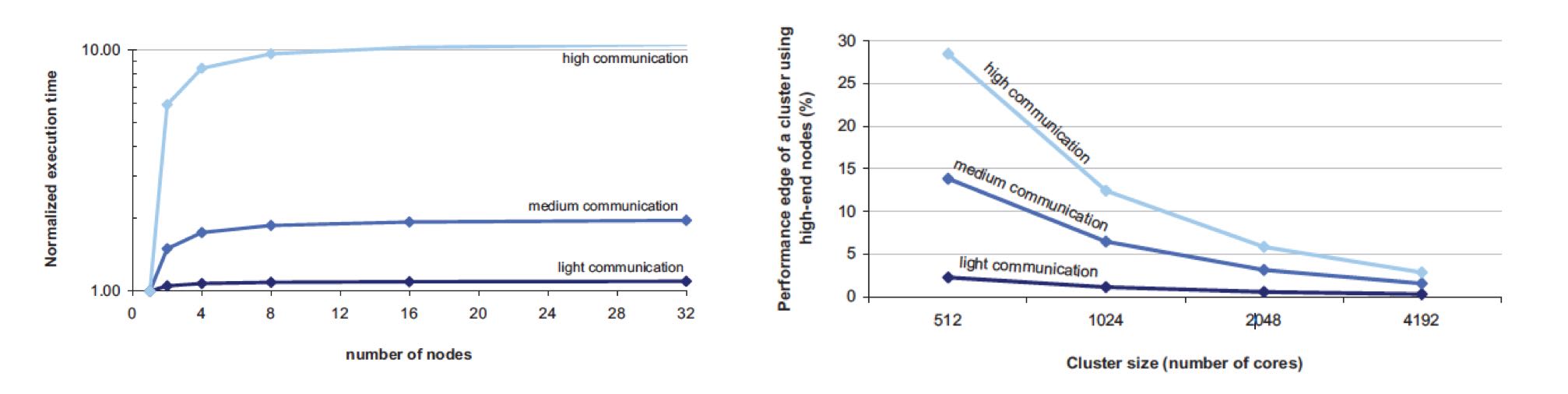
如果我们将通信效率考虑进来会怎么样呢?使用high-end servers是芯片之间通信效率很高,从这点上看应该是完爆low-end servers. 但是我们不能忘记,实际系统的workload是没有办法在有限的几台high-end servers上运行的,nodes/cores数量上升的话, 你可以看到这个performance edge(我的理解是performace的一阶导数)是快速下降的。也就是说,在大规模机器下, 多加机器没有办法提升单机性能,但是high-end server的price/core比low-end server的要很,在scale out的时候,cost-efficiency就会下降了。
Assume that a given parallel task execution time can be roughly modeled as a fixed local computation time plus the latency penalty of accesses to global data structures. If the computation fits into a single large shared memory system, those global data accesses will be performed at roughly DRAM speeds (~100 ns). If the computation only fits in multiple of such nodes, some global accesses will be much slower, on the order of typical LAN speeds (~100 ms). Let us assume further that accesses to the global store are uniformly distributed among all nodes so that the fraction of global accesses that map to the local node is inversely proportional to the number of nodes in the system— a node here is a shared-memory domain, such as one Integrity system or one ProLiant server. If the fixed local computation time is of the order of 1 ms—a reasonable value for high-throughput Internet services—the equation that determines the program execution time is as follows:
Execution time = 1 ms + f * [100 ns/# nodes + 100 ms * (1 - 1/# nodes)]
where the variable f is the number of global accesses per (1 ms) work unit. In Figure 3.1, we plot the execution time of this parallel workload as the number of nodes involved in the computation increases. Three curves are shown for different values of f, representing workloads with lightcommunication ( f = 1), medium-communication ( f = 10), and high-communication ( f = 100) patterns. Note that in our model, the larger the number of nodes, the higher the fraction of remote global accesses.
The point of this analysis is qualitative in nature. It is intended primarily to illustrate how we need to reason differently about baseline platform choice when architecting systems for applications that are too large for any single high-end server. The broad point is that the performance effects that matter most are those that benefit the system at the warehouse scale. Performance enhancements that have the greatest impact for computation that is local to a single node (such as fast SMP-style communication in our example) are still very important. But if they carry a heavy additional cost, their cost-efficiency may not be as competitive for WSCs as they are for small-scale computers.
如果我们更加偏好low-end servers的话,那么为什么不能使用PC-class computers甚至使用embedded devices呢? 简而言之就是在选择上存在一个sweet-spot, 单机性能也不能太差,否则最终还是会影响到cost-efficiency.
The advantages of using smaller, slower CPUs are a very similar to the arguments for using mid-range commodity servers instead of high end SMPs:
Multicore CPUs in mid-range servers typically carry a price/performance premium over lower-end processors so that the same amount of throughput can be bought two to five times more cheaply with multiple smaller CPUs.
Many applications are memory-bound so that faster CPUs do not scale well for large applications, further enhancing the price advantage of simpler CPUs.
Slower CPUs are more power efficient; typically, CPU power decreases by O(k2) when CPU frequency decreases by k.
However, offsetting effects diminish these advantages so that increasingly smaller building blocks become increasingly unattractive for WSCs.
As a rule of thumb, a lower-end server building block must have a healthy cost-efficienc advantage over a higher-end alternative to be competitive. At the moment, the sweet spot for many large-scale services seems to be at the low-end range of server-class machines (which overlaps somewhat with that of higher-end personal computers).
在设计硬件系统上需要做好平衡:
- 硬件要考虑软件开发的需要,比如Spanner需要GPS和原子钟。
- 硬件需要能够适合多种workload而不只是适合一种,来提高资源使用率。
- 硬件要能通过搭配充分利用好所有资源:比如使用其他机器上的内存的话,那么也需要提供好相应的网络带宽。
It is important to characterize the kinds of workloads that will execute on the system with respect to their consumption of various resources, while keeping in mind three important considerations:
Smart programmers may be able to restructure their algorithms to better match a more inexpensive design alternative. There is opportunity here to find solutions by softwarehardware co-design, while being careful not to arrive at machines that are too complex to program.
The most cost-efficient and balanced configuration for the hardware may be a match with the combined resource requirements of multiple workloads and not necessarily a perfect fit for any one workload. For example, an application that is seek-limited may not fully use the capacity of a very large disk drive but could share that space with an application that needs space mostly for archival purposes.
Fungible resources tend to be more efficiently used. Provided there is a reasonable amount of connectivity within a WSC, effort should be put on creating software systems that can flexibly utilize resources in remote servers. This affects balance decisions in many ways. For instance, effective use of remote disk drives may require that the networking bandwidth to a server be equal or higher to the combined peak bandwidth of all the disk drives locally connected to the server.
4. Datacenter Basics
数据中心建设的大部分开销在能源提供和冷却系统上。可以看到成本度量单位都是以W来计算了。
It is not surprising, then, that the bulk of the construction costs of a datacenter are proportional to the amount of power delivered and the amount of heat to be removed; in other words, most of the money is spent either on power conditioning and distribution or on cooling systems. Typical construction costs for a large datacenter are in the $10–20/W range (see Section 6.1) but vary considerably depending on size, location, and design.
UPS(uninterruptable power supply)的作用:
- 接入多个发电机,选择其中一个使用。如果发生故障的话会自动切换,但是需要10-15s才能完全恢复。
- 在10-15s这个恢复期间通过电池和飞轮(?)做过渡。
- 平稳输入的电压。
The UPS typically combines three functions in one system.
First, it contains a transfer switch that chooses the active power input (either utility power or generator power). After a power failure, the transfer switch senses when the generator has started and is ready to provide power; typically, a generator takes 10–15 s to start and assume the full rated load.
Second, the UPS contains batteries or flywheels to bridge the time between the utility failure and the availability of generator power. A typical UPS accomplishes this with an AC–DC–AC double conversion; that is, input AC power is converted to DC, which feeds a UPS-internal DC bus that is also connected to strings of batteries. The output of the DC bus is then converted back to AC to feed the datacenter equipment. Thus, when utility power fails, the UPS loses input (AC) power but retains internal DC power because the batteries still supply it, and thus retains AC output power after the second conversion step. Eventually, the generator starts and resupplies input AC power, relieving the UPS batteries of the datacenter load.
Third, the UPS conditions the incoming power feed, removing voltage spikes or sags, or harmonic distortions in the AC feed. This conditioning is naturally accomplished via the double conversion steps.
冷却系统分为室内和室外冷却,室内冷却是通过空调系统,室外冷却是通过水冷降温。先看一下室内冷却系统CRAC(computer room air conditioning) 机器被放在钢铁网格上,距离水泥地面差不多2-4 feet,下面的空间主要是用来填充冷气的。这些机器整齐排列,但是之间间隔着cold aisle和hot aisles. 冷却剂的温度在12-14C,从CRAC出去的时候在16-20C, 被吹到cold aisle下面是18-22C.
The cooling system is somewhat simpler than the power system. Typically, the datacenter’s floor is raised—a steel grid resting on stanchions is installed 2–4 ft above the concrete floor (as shown in Figure 4.2). The under-floor area is often used to route power cables to racks, but its primary use is to distribute cool air to the server racks.
CRAC units (CRAC is a 1960s term for computer room air conditioning) pressurize the raised floor plenum by blowing cold air into the plenum. This cold air escapes from the plenum through perforated tiles that are placed in front of server racks and then flows through the servers, which expel warm air in the back. Racks are arranged in long aisles that alternate between cold aisles and hot aisles to avoid mixing hot and cold air. (Mixing cold air with hot reduces cooling efficiency; some newer datacenters even partition off the hot aisles with walls to avoid leaking the hot air back into the cool room [63].) Eventually, the hot air produced by the servers recirculates back to the intakes of the CRAC units that cool it and then exhaust the cool air into the raised floor plenum again.
CRAC units consist of coils through which a liquid coolant is pumped; fans push air through these coils, thus cooling it. A set of redundant pumps circulate cold coolant to the CRACs and warm coolant back to a chiller or cooling tower, which expel the heat to the outside environment. Typically, the incoming coolant is at 12–14°C, and the air exits the CRACs at 16–20°C, leading to cold aisle (server intake) temperatures of 18–22°C. (The server intake temperature typically is higher than the CRAC exit temperature because it heats up slightly on its way to the server and because of recirculation that cannot be eliminated.) The warm coolant returns to a chiller that cools it down again to 12–14°C.
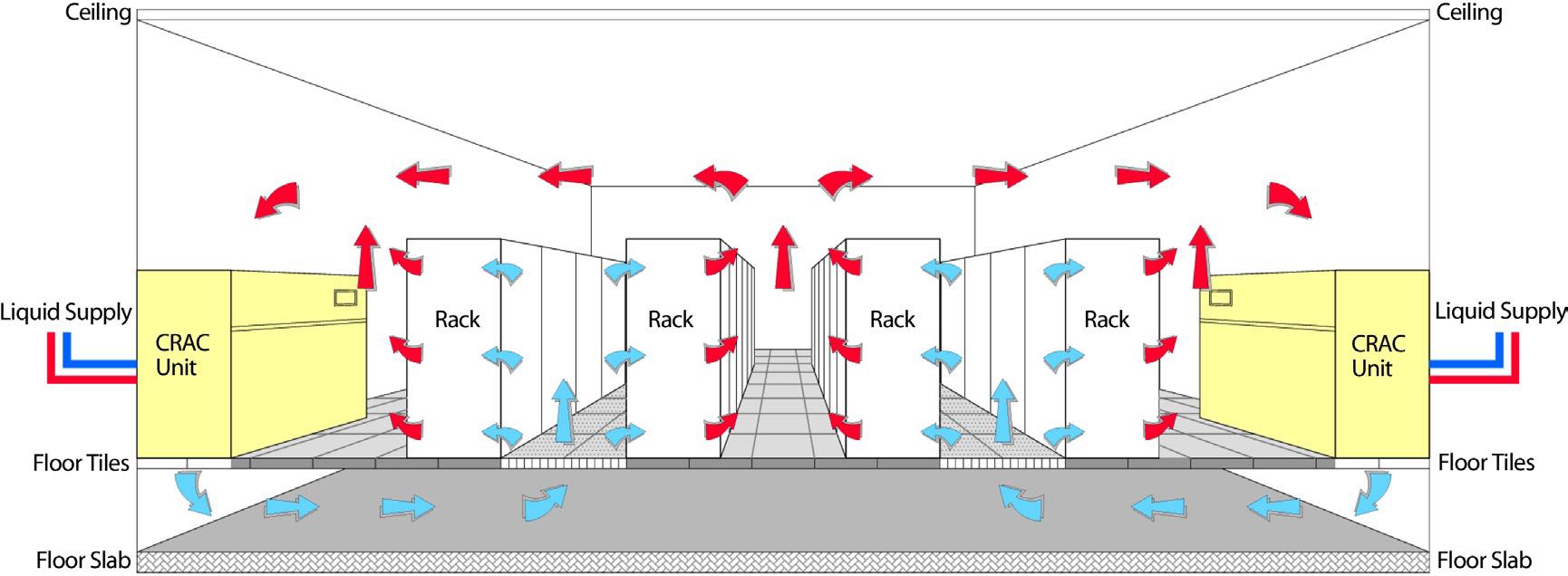
大部分的free-cooling都是使用水冷。水冷主要是为了用来降低冷凝剂的温度,我的理解是还需要使用额外的能量将冷凝剂降低到12-14C. 这种水冷系统在低湿度的环境下效率很高,并且附近不能太冷,否则需要额外的机制确保水管不会冻住。
Cooling towers work best in temperate climates with low humidity; ironically, they do not work as well in very cold climates because additional mechanisms are needed to prevent ice formation on the towers.
这些冷却设备还需要配置额外的发电机来确保持续工作。如果冷却设备出现故障的话,数据中心在几分钟内就会因为过热而无法运转。
Most of the mechanical cooling equipment is also backed up by generators (and sometimes UPS units) because the datacenter cannot operate without cooling for more than a few minutes before overheating. In a typical datacenter, chillers and pumps can add 40% or more to the critical load that needs to be supported by generators.
改进供电和冷却系统是减少数据中心开销最主要的措施。文章里面提到了三种方法:
- 改进的CRAC. 将hot aisle和cold aisle完全隔离开,这样可以提高冷却效率。
- in-rack cooling. 每个rack增加一个额外的冷却系统:在rack后面增加管子,里面流过冷水。servers产生的热空气在这里就会冷却下来。
- container-based datacenter. 将多个rackes放在一个箱子里面,这个箱子有独立的电源,冷却,网线,照明设备。
As mentioned before, newer datacenters have started to physically separate the hot aisles from the room to eliminate recirculation and optimize the path back to the CRACs. In this setup the entire room is filled with cool air (because the warm exhaust is kept inside a separate plenum or duct system) and, thus, all servers in a rack will ingest air at the same temperature [63].
In-rack cooling products are a variant on the idea of filling the entire room with cool air and can also increase power density and cooling efficiency beyond the conventional raised-floor limit. Typically, an in-rack cooler adds an air-to-water heat exchanger at the back of a rack so that the hot air exiting the servers immediately flows over coils cooled by water, essentially short-circuiting the path between server exhaust and CRAC input. In some solutions, this additional cooling removes just part of the heat, thus lowering the load on the room’s CRACs (i.e., lowering power density as seen by the CRACs), and in other solutions it completely removes all heat, effectively replacing the CRACs. The main downside of these approaches is that they all require chilled water to be brought to each rack, greatly increasing the cost of plumbing and the concerns over having water on the datacenter floor with couplings that might leak.
Container-based datacenters go one step beyond in-rack cooling by placing the server racks into a standard shipping container and integrating heat exchange and power distribution into the container as well. Similar to full in-rack cooling, the container needs a supply of chilled water and uses coils to remove all heat from the air that flows over it. Air handling is similar to in-rack cooling and typically allows higher power densities than regular raised-floor datacenters. Thus, container-based datacenters provide all the functions of a typical datacenter room (racks, CRACs, PDU, cabling, lighting) in a small package. Like a regular datacenter room, they must be complemented by outside infrastructure such as chillers, generators, and UPS units to be fully functional.
5. Energy and Power Efficiency
数据中心性能效率(DCPE, datacenter performance efficiency)可以细分为下面3个部分:
- PUE(power usage effectiveness): 强调机房运营效率,尤其是供电和冷却效率。
- SPUE(server PUE): 强调服务器硬件本身能耗转换,比如CPU,DRAM,风扇等。
- 最后一部分就是计算效率,强调能耗动态适应性:如果load低的时候,那么能耗必须也尽可能低。
Instead, we find it more useful to factor DCPE into three components that can be independently measured and optimized by the appropriate engineering disciplines, as shown in the equation below:

良好设计的机房PUE在2.0以下,最先进的设计可以达到1.4:
- 小心处理气流
- 提高cold aisle温度
- 利用free cooling
- 给每个server配备mini-UPS.
It is commonly accepted that a well-designed and well-operated datacenter should have a PUE of less than 2, and the 2007 EPA report on datacenter power consumption states that in a “state-of-the-art” scenario a PUE of 1.4 is achievable by 2011 [26]. The most obvious improvements opportunities are the use of evaporative cooling towers, more efficient air movement, and the elimination of unnecessary power conversion losses.
In April of 2009, Google published details of its datacenter architecture, including a video tour of a container-based datacenter built in 2005 [33]. This datacenter achieved a state-of-the-art annual PUE of 1.24 in 2008 yet differs from conventional datacenters in only a few major aspects:
Careful air flow handling: The hot air exhausted by servers is not allowed to mix with cold air, and the path to the cooling coil is very short so that little energy is spent moving cold or hot air long distances.
Elevated cold aisle temperatures: The cold aisle of the containers is kept at about 27°C rather than 18–20°C. Higher temperatures make it much easier to cool datacenters efficiently.
Use of free cooling: Several cooling towers dissipate heat by evaporating water, greatly reducing the need to run chillers. In most moderate climates, cooling towers can eliminate the majority of chiller runtime. Google’s datacenter in Belgium even eliminates chillers altogether, running on “free” cooling 100% of the time.
Per-server 12-V DC UPS: Each server contains a mini-UPS, essentially a battery that floats on the DC side of the server’s power supply and is 99.99% efficient. These per-server UPSs eliminate the need for a facility-wide UPS, increasing the efficiency of the overall power infrastructure from around 90% to near 99% [34].
普通服务器的SPUE基本在1.6-1.8之间(意味着最高有44%的能量被浪费了),最小可以做到1.2. 这里VRM(voltage regulator module)指稳压器模块。
Although PUE captures the facility overheads, it does not account for inefficiencies within the IT equipment itself. Servers and other computing equipment use less than 100% of their input power for actual computation. In particular, substantial amounts of power may be lost in the server’s power supply, voltage regulator modules (VRMs), and cooling fans. The second term (b) in the efficiency calculation accounts for these overheads, using a metric analogous to PUE but instead applied to computing equipment: server PUE (SPUE). It consists of the ratio of total server input power to its useful power, where useful power includes only the power consumed by the electronic components directly involved in the computation: motherboard, disks, CPUs, DRAM, I/O cards, and so on. In other words, useful power excludes all losses in power supplies, VRMs, and fans. No commonly used measurement protocol for SPUE exists today, although the Climate Savers Computing Initiative (climatesaverscomputing.org) is working on one. SPUE ratios of 1.6–1.8 are common in today’s servers; many power supplies are less than 80% efficient, and many motherboards use VRMs that are similarly inefficient, losing more than 30% of input power in electrical conversion losses. In contrast, a state-of-the-art SPUE should be less than 1.2 [17].
把PUE * SPUE = TPUE(true PUE). 如果这样计算的话,那么现在这个能源浪费还是非常高的。
The combination of PUE and SPUE therefore constitutes an accurate assessment of the joint efficiency of the total electromechanical overheads in facilities and computing equipment. Such true (or total) PUE metric (TPUE), defined as PUE * SPUE, stands at more than 3.2 for the average datacenter today; that is, for every productive watt, at least another 2.2 W are consumed! By contrast, a facility with a PUE of 1.2 and a 1.2 SPUE would use less than half as much energy. That is still not ideal because only 70% of the energy delivered to the building is used for actual computation, but it is a large improvement over the status quo. Based on the current state of the art, an annual TPUE of 1.25 probably represents the upper limit of what is economically feasible in real-world settings.
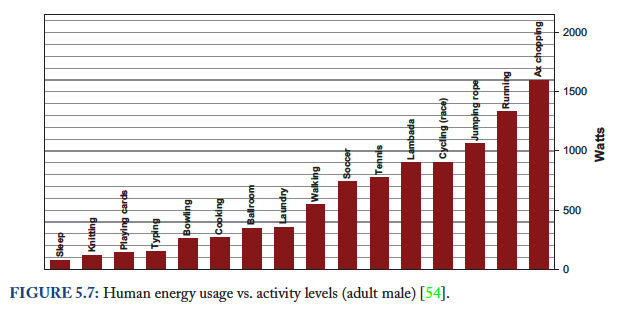
“成比例的能耗使用计算”(engery-proportional computing,我后面写成EPC)理想情况就是:如果idle的话,那么最好就能能耗; 然后能耗使用是和load成线性比例的。EPC要求有"wide dynamic power range",这点拿人体来做参考。
We suggest that energy proportionality should be added as a design goal for computing components. Ideally, energy-proportional systems will consume almost no power when idle (particularly in active idle states where they are still available to do work) and gradually consume more power as the activity level increases.
Energy-proportional machines would exhibit a wide dynamic power range—a property that is rare today in computing equipment but is not unprecedented in other domains. Humans, for example, have an average daily energy consumption approaching that of an old personal computer: about 120 W. However, humans at rest can consume as little as 70 W while being able to sustain peaks of well more than 1 kW for tens of minutes, with elite athletes reportedly approaching 2 kW[54]. Figure 5.7 lists several occupational activities and their corresponding energy expenditures for adult males illustrating a dynamic power range of nearly 20x compared to the factor of 2x of today’s typical computers. It is generally accepted that energy efficiency is one of the features favored by evolutionary processes; we wonder if energy proportionality might have been a successful means to achieve higher energy efficiency in organisms.
从下图可以看到,现在EPC依然做的还不够好。如果细分每个子系统的话,可以看到现在server-class CPU做的还是很不错的, 尤其是现在用于嵌入式设备和移动设备上的CPU这方面做的更好。而DRAM和Disk等其他组件还有待改进。
Figure 5.8 shows the power usage of the main subsystems for a recent Google server as the compute load varies from idle to full activity levels. The CPU contribution to system power is nearly 50% when at peak but drops to less than 30% at low activity levels, making it the most energyproportional of all main subsystems. In our experience, server-class CPUs have a dynamic power range that is generally greater than 3.0´ (more than 3.5´ in this case), whereas CPUs targeted at the embedded or mobile markets can do even better. By comparison, the dynamic range of memory systems, disk drives, and networking equipment is much lower: approximately 2.0´ for memory, 1.3´ for disks, and less than 1.2´ for networking switches. This suggests that energy proportionality at the system level cannot be achieved through CPU optimizations alone, but instead requires improvements across all components.

改进磁盘的EPC一种方法是使用降低RPM但是增加多个读取头来补偿,因为发现大部分能耗都浪费在磁片旋转上。
Disk drives, for example, spend a large fraction of their energy budget simply keeping the platters spinning, possibly as much as 70% of their total power for high RPM drives. Creating additional energy efficiency and energy proportionality may require smaller rotational speeds, smaller platters, or designs that use multiple independent head assemblies. Carrera et al. [11] considered the energy impact of multispeed drives and of combinations of severclass and laptop drives to achieve proportional energy behavior. More recently, Sankar et al. [81] have explored different architectures for disk drives, observing that because head movements are relatively energy-proportional, a disk with lower rotational speed and multiple heads might achieve similar performance and lower power when compared with a single-head, high RPM.
为了达到EPC简单地使用低功耗模式是不可行的,因为通常低功耗意味着进入非活跃模式。虽然在非活跃模式下面能耗很好, 但是当转变到活跃模式的时候,一个是会产生很高的延迟,第二个是这个过程如果频繁的话会有更多的能耗。
As discussed earlier, the existence of long idleness intervals would make it possible to achieve higher energy proportionality by using various kinds of sleep modes. We call these low-power modes inactive because the devices are not usable while in those modes, and typically a sizable latency and energy penalty is incurred when load is reapplied. Inactive low-power modes were originally developed for mobile and embedded devices, and they are very successful in that domain. However, most of those techniques are a poor fit for WSC systems, which would pay the inactive-to-active latency and energy penalty too frequently. The few techniques that can be successful in this domain are those with very low wake-up latencies, as is beginning to be the case with CPU low-power halt states (such as the x86 C1E state).
Unfortunately, these tend to also be the low-power modes with the smallest degrees of energy savings. Large energy savings are available from inactive low-power modes such as spun-down disk drives. A spun-down disk might use almost no energy, but a transition to active mode incurs a latency penalty 1,000 times higher than a regular access. Spinning up the disk platters adds an even larger energy penalty. Such a huge activation penalty restricts spin-down modes to situations in which the device will be idle for several minutes, which rarely occurs in servers.
相比inactive low-power mode, 更高的方式就是avtive low-power mode. 在这个模式下面,组件依然在运转的比如CPU 依然在执行指令,disk依然可以读取写入,但是它们工作在类似降级模式下。
Active low-power modes are those that save energy at a performance cost while not requiring inactivity. CPU voltage-frequency scaling is an example of an active low-power mode because it remains able to execute instructions albeit at a slower rate. The (presently unavailable) ability to read and write to disk drives at lower rotational speeds is another example of this class of lowpower modes. In contrast with inactive modes, active modes are useful even when the latency and energy penalties to transition to a high-performance mode are significant. Because active modes are operational, systems can remain in low-energy states for as long as they remain below certain load thresholds. Given that periods of low activity are more common and longer than periods of full idleness, the overheads of transitioning between active energy savings modes amortize more effectively.
EPC对于软件基础层的要求就是:软件基础层要对EPC进行封装,并且意识到EPC可能会造成性能问题,然后提供性能保证。 如果底层软件没有做到这点的话,那么应用开发者一旦发现出现性能问题,就会倾向增加更多的机器来补偿这种性能问题。
This software layer must overcome two key challenges: encapsulation and performance robustness. Energy-aware mechanisms must be encapsulated in lower-level modules to minimize exposing additional infrastructure complexity to application developers; WSC application developers already deal with unprecedented scale and platform-level complexity. In large-scale systems, completion of an end-user task also tends to depend on large numbers of systems performing at adequate levels. If individual servers begin to exhibit excessive response time variability as a result of mechanisms for power management, the potential for service-level impact is fairly high and can result in the service requiring additional machine resources, resulting in little net improvements.
WSCs设计者还要意识到,每个组件EPC是不断变化的。比如上图可以看到,CPU的EPC变得越来越好。但是总的来说应用软件的workload 通常不会发生比较大的变化,对每个组件的load需求也是相对固定的。这个时候我们就要调整每个组件的能耗来适应软件的workload. 比如CPU就可以使用DVS(dynamic voltage scaling)来降低CPU的功耗(因为CPU性能增速远好于disk和dram)
WSC designs, as with any machine design, attempt to achieve high energy efficiency but also to strike a balance between the capacity and performance of various subsystems that matches the expected resource requirements of the target class of workloads. Although this optimal point may vary over time for any given workload, the aggregate behavior of a wide set of workloads will tend to vary more slowly. Recognition of this behavior provides a useful input to system design. For example, an index search program may perform best for a given ratio of CPU speed to storage capacity: too much storage makes search too slow, and too little storage may underuse CPUs. If the desired ratio remains constant but the energy efficiency of various components evolve at a different pace, the energy consumption budget can shift significantly over time.
We have observed this kind of phenomenon over the past few years as CPU energy efficiency improvements have outpaced those of DRAM and disk storage. As a result, CPUs that used to account for more than 60% of the system energy budget are now often less than 45–50%. Consider the system used in Figure 5.8 as a balanced server design today as an example: two dual-core x86 CPUs at 2.4 GHz, 8 GB of DRAM, and two disk drives. Moore’s law still enables creation of CPUs with nearly twice the computing speed every 18 months or so (through added cores at minor frequency changes) and at nearly the same power budget. But over the last few years, this pace has not been matched by DRAM and disk technology, and if this trend continues, the energy usage in a well-balanced server design might be dominated by the storage subsystem.
One consequence of such a trend is the decreasing utility of CPU voltage-frequency scaling for power management. Figure 5.11 shows the potential power savings of CPU dynamic voltage scaling (DVS) for that same server by plotting the power usage across a varying compute load for three frequency-voltage steps. Savings of approximately 10% are possible once the compute load is less than two thirds of peak by dropping to a frequency of 1.8 GHz (above that load level the application violates latency SLAs). An additional 10% savings is available when utilization drops further to one third by going to a frequency of 1 GHz. However, as the load continues to decline, the gains of DVS once again return to a maximum of 10% or so as a result of lack of energy proportionality at the system level. Although power savings in the 10–20% range is not negligible, they are not particularly impressive especially considering that most systems today have no other power management control knobs other than CPU DVS. Moreover, if the CPU continues to decrease in importance in overall system power, the impact of DVS is bound to decrease further.
6. Modeling Costs
7. Dealing with Failures and Repairs
对于传统服务器来说,在软件层面上没有很好的容错机制,就需要硬件提供很高的可靠性,包括冗余电源,风扇,ECC内存,RAIDS磁盘等。
For traditional servers the cost of failures is thought to be very high, and thus designers go to great lengths to provide more reliable hardware by adding redundant power supplies, fans, error correction coding (ECC), RAID disks, and so on. Many legacy enterprise applications were not designed to survive frequent hardware faults, and it is hard to make them fault-tolerant after the fact. Under these circumstances, making the hardware very reliable becomes a justifiable alternative.
硬件修复或者是更换通常也需要选择好操作时间窗口和控制杀掉-重启操作的速率,这样可以有效地减少对服务带来的影响。
By choosing opportune time windows and rate-limiting the pace of kill–restart actions, operators can still manage the desired amount of planned service-level disruptions.
硬件上不需要透明地处理所有错误,但是如果一旦能检测到出现错误的话,那么就要及时通知到软件,让软件进行进行适当的恢复操作。 但是这并不意味着硬件就不需要做任何容错处理。硬件和软件都需要做部分容错处理,trade-off就是那边做成本更低,效率更高。 比如使用ECC DRAM就是一种很经济地硬件容错手段,这种容错放在软件层面,通常会增加开发成本。后面给了一个Google早期创建索引 文件因为内存出错而导致搜索出现随机结果的例子。
我这里有点好奇,当有ECC功能的DRAM出现检测到出现奇偶校验错误,但是没有办法纠错的话,会出现什么故障呢?通知CPU然后内核出现panic错误?
In a system that can tolerate a number of failures at the software level, the minimum requirement made to the hardware layer is that its faults are always detected and reported to software in a timely enough manner as to allow the software infrastructure to contain it and take appropriate recovery actions. It is not necessarily required that hardware transparently corrects all faults. This does not mean that hardware for such systems should be designed without error correction capabilities. Whenever error correction functionality can be offered within a reasonable cost or complexity, it often pays to support it. It means that if hardware error correction would be exceedingly expensive, the system would have the option of using a less expensive version that provided detection capabilities only. Modern DRAM systems are a good example of a case in which powerful error correction can be provided at a very low additional cost.
Relaxing the requirement that hardware errors be detected, however, would be much more difficult because it means that every software component would be burdened with the need to check its own correct execution. At one early point in its history, Google had to deal with servers that had DRAM lacking even parity checking. Producing a Web search index consists essentially of a very large shuffle/merge sort operation, using several machines over a long period. In 2000, one of the then monthly updates to Google’s Web index failed prerelease checks when a subset of tested queries was found to return seemingly random documents. After some investigation a pattern was found in the new index files that corresponded to a bit being stuck at zero at a consistent place in the data structures; a bad side effect of streaming a lot of data through a faulty DRAM chip. Consistency checks were added to the index data structures to minimize the likelihood of this problem recurring, and no further problems of this nature were reported. Note, however, that this workaround did not guarantee 100% error detection in the indexing pass because not all memory positions were being checked—instructions, for example, were not. It worked because index data structures were so much larger than all other data involved in the computation, that having those self-checking data structures made it very likely that machines with defective DRAM would be identified and excluded from the cluster. The following machine generation at Google did include memory parity detection, and once the price of memory with ECC dropped to competitive levels, all subsequent generations have used ECC DRAM.
service级别故障可以按照严重程度区分可以有下面几类:损坏,宕机,降级和故障屏蔽。
We broadly classify service-level failures into the following categories, listed in decreasing degree of severity:
- Corrupted: committed data that are impossible to regenerate, are lost, or corrupted
- Unreachable: service is down or otherwise unreachable by the users
- Degraded: service is available but in some degraded mode
- Masked: faults occur but are completely hidden from users by the fault-tolerant software/
研究表明,即便是我们的服务是reliable,依然有1-2%的流量/用户因为互联网链路原因没有办法访问到我们的服务, 也就是说对外呈现出来可用性只能达到99%. 如果访问的是Google服务器的话,这个可用性组多也就只能到达99.9%.
Service availability/reachability is very important, especially because Internet service revenue is often related in some way to traffic volume [12]. However, perfect availability is not a realistic goal for Internet-connected services because the Internet itself has limited availability characteristics. Chandra et al. [91] report that Internet end points may be unable to reach each other between 1% and 2% of the time due to a variety of connectivity problems, including routing issues. That translates to an availability of less than two “nines.” In other words, even if your Internet service is perfectly reliable, users will, on average, perceive it as being no greater than 99.0% available. As a result, an Internet-connected service that avoids long-lasting outages for any large group of users and has an average unavailability of less than 1% will be difficult to distinguish from a perfectly reliable system. Google measurements of Internet availability indicate that it is likely on average no better than 99.9% when Google servers are one of the end points, but the spectrum is fairly wide. Some areas of the world experience significantly lower availability.
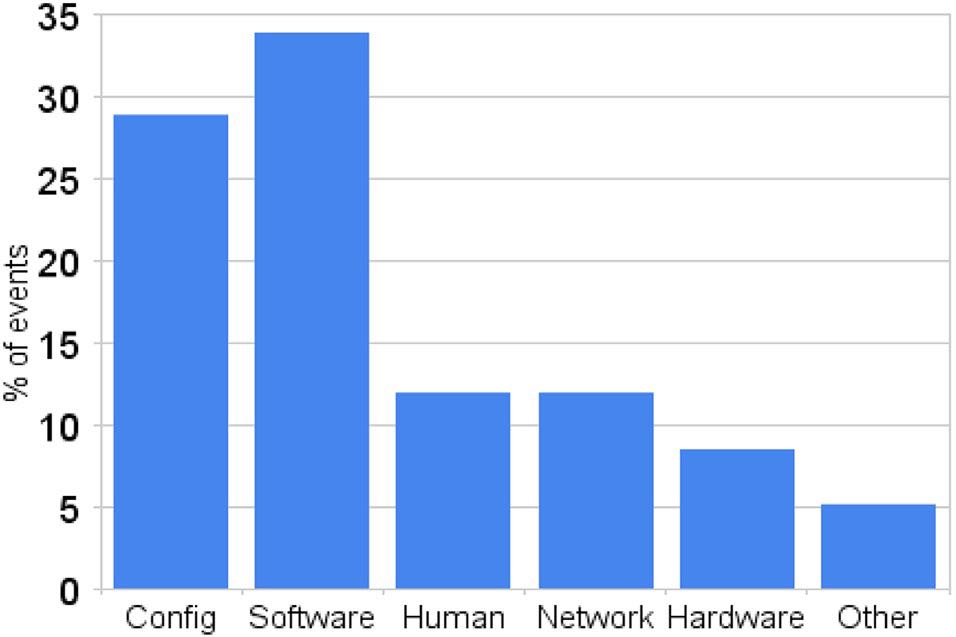
下面这张图是某个google在线服务出现故障的原因分布。可以看到大部分故障原因都是错误配置,软件Bug和人工误操作所引起的。
Our experience at Google is generally in line with Oppenheimer’s classification, even if the category definitions are not fully consistent. Figure 7.1 represents a rough classification of all events that corresponded to noticeable disruptions at the service level in one of Google’s large-scale online services. These are not necessarily outages (in fact, most of them are not even user-visible events) but correspond to situations where some kind of service degradation is noticed by the monitoring infrastructure and has to be scrutinized by the operations team. As expected, the service is less likely to be disrupted by machines or networking faults than by software errors, faulty configuration data, and human mistakes.
有哪些原因造成机器crash呢?(Machine Crashes) 事实证明还是软件造成机器crash的比例比较高。纯粹因为硬件造成机器crash的主要在 两个子系统上:内存和硬盘。但是按照这些硬件错误率的保守估计,每年最多只有10%的machine crash. 而实际上我们观察的数比这个高, 这些高出的部分都是因为软件造成的。
DRAM soft-errors. Although there are little available field data on this topic, it is generally believed that DRAM soft error rates are extremely low once modern ECCs are used. In a 1997 IBM white paper, Dell [22] sees error rates from chipkill ECC being as low as six errors for 10,000 one-GB systems over 3 years (0.0002 errors per GB per year—an extremely low rate). A survey article by Tezzaron Semiconductor in 2004 [83] concludes that single-error rates per Mbit in modern memory devices range between 1,000 and 5,000 FITs (faults per billion operating hours), but that the use of ECC can drop soft-error rates to a level comparable to that of hard errors.
A recent study by Schroeder et al. [77] evaluated DRAM errors for the population of servers at Google and found FIT rates substantially higher than previously reported (between 25,000 and 75,000) across multiple DIMM technologies. That translates into correctable memory errors affecting about a third of Google machines per year and an average of one correctable error per server every 2.5 hours. Because of ECC technology, however, only approximately 1.3% of all machines ever experience uncorrectable memory errors per year.
Disk errors. Studies based on data from Network Appliances [3], Carnegie Mellon [76], and Google [65] have recently shed light onto the failure characteristics of modern disk drives. Hard failure rates for disk drives (measured as the annualized rate of replaced components) have typically ranged between 2% and 4% in large field studies, a much larger number than the usual manufacturer specification of 1% or less.
The numbers above suggest that the average fraction of machines crashing annually due to disk or memory subsystem faults should be less than 10% of all machines. Instead we observe crashes to be more frequent and more widely distributed across the machine population. We also see noticeable variations on crash rates within homogeneous machine populations that are more likely explained by firmware and kernel differences.
Another indirect evidence of the prevalence of software-induced crashes is the relatively high mean time to hardware repair observed in Google’s fleet (more than 6 years) when compared to the mean time to machine crash (6 months or less).
在预测故障的时候,我们需要平衡accuracy和recall(主要是penalty, 因为没有及时预报造成的损失)。如果软件容错处理做得好的话,那么这个penalty会比较低。 所以在预测故障方面,我们适当地关注accuracy. 而传统软件在recall上面就要做得尽可能高。但是他们也指出,他们在磁盘故障预测上做得并不好。
Because software in WSCs is designed to gracefully handle all the most common failure scenarios, the penalties of letting faults happen are relatively low; therefore, prediction models must have much greater accuracy to be eco nomically competitive. By contrast, traditional computer systems in which a machine crash can be very disruptive to the operation may benefit from less accurate prediction models.
Pinheiro et al. [65] describe one of Google’s attempts to create predictive models for disk drive failures based on disk health parameters available through the Self-Monitoring Analysis and Reporting Technology standard. They conclude that such models are unlikely to predict most failures and will be relatively inaccurate for the failures the models do predict. Our general experience is that only a small subset of failure classes can be predicted with high enough accuracy to produce useful operational models for WSCs.
为了提高维修方面的效率,可以从两个角度出发: 1. 以吞吐量而不是延迟角度来优化修复效率。可以每天更换一批硬盘来提高效率。 2. 通过 健康系统观察所有机器的健康情况,可以快速发现哪些以及存在问题。
There are two characteristics of WSCs that directly affect repairs efficiency. First, because of the large number of relatively low-end servers involved and the presence of a software fault tolerance layer, it is not as critical to quickly respond to individual repair cases because they are unlikely to affect overall service health. Instead, a datacenter can implement a schedule that makes the most efficient use of a technician’s time by making a daily sweep of all machines that need repairs attention. The philosophy is to increase the rate of repairs while keeping the repairs latency within acceptable levels.
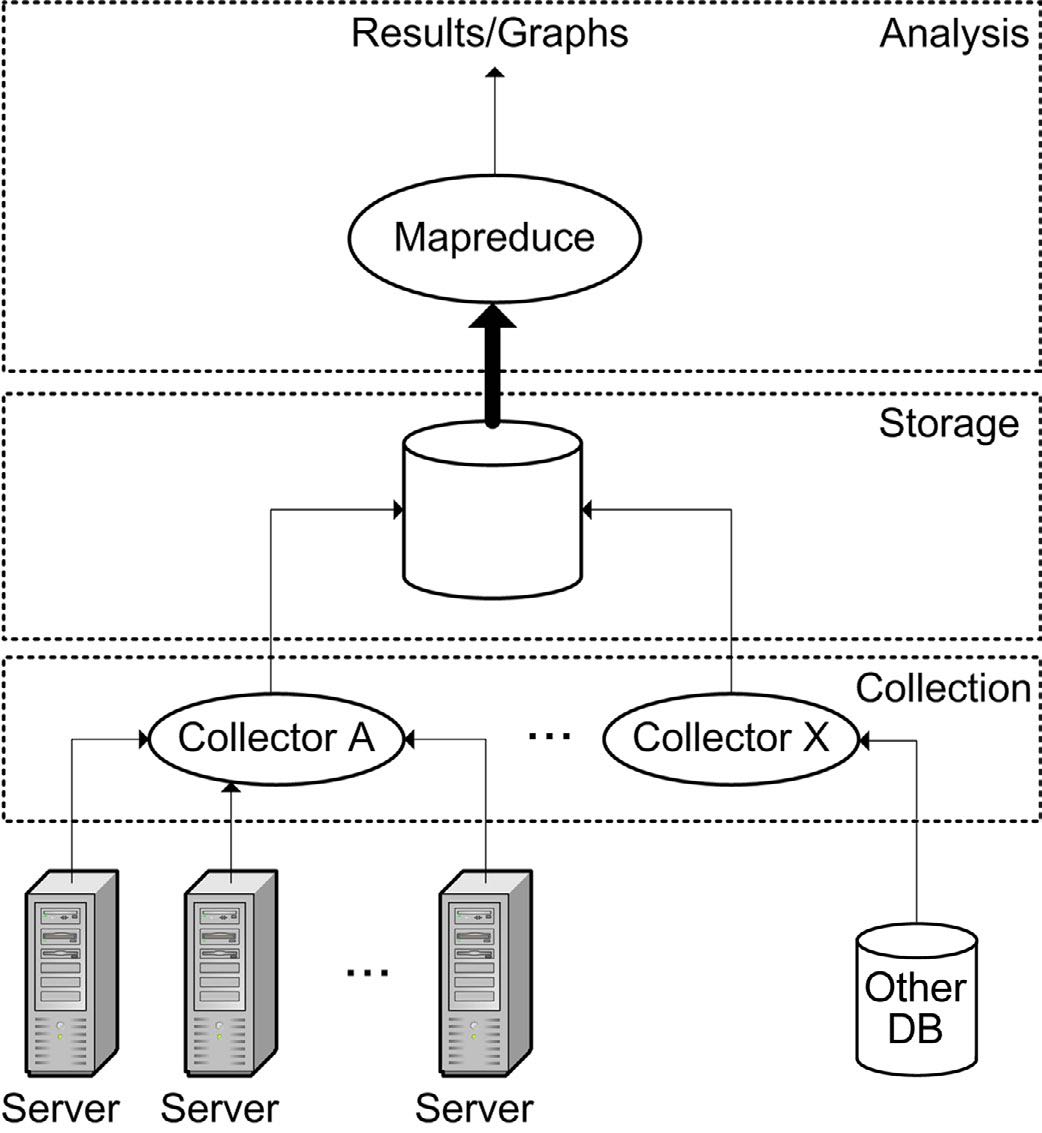
In addition, when there are many thousands of machines in operation, massive volumes of data about machine health can be collected and analyzed to create automated systems for health determination and diagnosis. The Google System Health infrastructure illustrated in Figure 7.4 is one example of a monitoring system that takes advantage of this massive data source. It constantly monitors every server for configuration, activity, environmental, and error data. System Health stores this information as a time series in a scalable repository where it can be used for various kinds of analysis, including an automated machine failure diagnostics tool that uses machine learning methods to suggest the most appropriate repairs action.
8. Closing Remarks
我觉得WSCs在选择硬件和软件方面的思路是换换相扣的:
- 硬件方面使用low-end servers, consumer-grade disk drives以及以太网络是考虑到了大规模生产可以明显降低成本。
- 数据中心通常需要很多大量机器,所以即便单个硬件故障率可以做的很低,但是上了规模之后这个故障率可就不低了。
- 如果硬件上没有办法做到完全透明的fault-tolerant,那么软件就要处理这个问题,软件要能做到容错处理。
- 软件容错处理不仅仅是硬件故障率的要求,软件本身故障率也很高。许多机器宕机都是因为各种软件故障比如固件,操作系统等等。
- 软件如果要做容错处理,那么就不能可丁可卯地运行,需要在一定的load以下。但是如果在低负载的情况下耗能严重的话,那么就不经济了。
这也是为什么WSC设计者要强调EPC.
The building blocks of choice for WSCs are commodity server-class machines, consumer- or enterprise-grade disk drives, and Ethernet-based networking fabrics. Driven by the purchasing volume of hundreds of millions of consumers and small businesses, commodity components benefit from manufacturing economies of scale and therefore present significantly better price/performance ratios than their corresponding high-end counterparts. In addition, Internet applications tend to exhibit large amounts of easily exploitable parallelism, making the peak performance of an individual server less important than the aggregate throughput of a collection of servers.
The higher reliability of high-end equipment is less important in this domain because a faulttolerant software layer is required to provision a dependable Internet service regardless of hardware quality—in clusters with tens of thousands of systems, even clusters with highly reliable servers will experience failures too frequently for software to assume fault-free operation. Moreover, large and complex Internet services are often composed of multiple software modules or layers that are not bug-free and can fail at even higher rates than hardware components.
尽管low-end servers很吸引人,但是如果业务需要的话比如分布式关系数据库的话,可能还是要用上higher-end servers. 但是这些servers仅仅是special cases.
Despite the attractiveness of low-end, moderately reliable server building blocks for WSCs, high-performance, high-availability components still have value in this class of systems. For example, fractions of a workload (such as SQL databases) may benefit from higher-end SMP servers with their larger interconnect bandwidth.
未来网络和存储子系统的性能和WSC程序员更加相关:DRAM/FLASH的价格高居不下,disk drives的性能短时间上不来, 加上未来需要处理更多的数据,所以怎么利用好磁盘存储是个问题。为了利用并行性,网络带宽在未来依然是稀缺资源。
The performance of the networking fabric and the storage subsystem can be more relevant to WSC programmers than CPU and DRAM subsystems, unlike what is more typical in smaller scale systems. The relatively high cost (per gigabyte) of DRAM or FLASH storage make them prohibitively expensive for large data sets or infrequently accessed data; therefore, disks drives are still used heavily. The increasing gap in performance between DRAM and disks, and the growing imbalance between throughput and capacity of modern disk drives makes the storage subsystem a common performance bottleneck in large-scale systems. The use of many small-scale servers demands networking fabrics with very high port counts and high bi-section bandwidth. Because such fabrics are costly today, programmers must be keenly aware of the scarcity of datacenter-level bandwidth when architecting software systems. This results in more complex software solutions, expanded design cycles, and sometimes inefficient use of global resources.
分布式应用和HPC应用有几点不同:
- HPC对集群没有容错能力,而分布式应用有容错能力。
- HPC各个节点通信密集,而分布式应用通信相对少些。
- 因为通信相对较少,所以分布式应用更容易挖掘机器的并行性。
- 分布式应用不要求机器满负荷跑,留出空余用来做容错处理,并且load随着日/周波动;HPC经常几天几周地以满负荷运转。
This workload differs substantially from that running in traditional high-performance computing (HPC) datacenters, the traditional users of large-scale cluster computing. Like HPC applications, these workloads require significant CPU resources, but the individual tasks are less synchronized than in typical HPC applications and communicate less intensely. Furthermore, they are much more diverse, unlike HPC applications that exclusively run a single binary on a large number of nodes. Much of the parallelism inherent in this workload is natural and easy to exploit, stemming from the many users concurrently accessing the service or from the parallelism inherent in data mining. Utilization varies, often with a diurnal cycle, and rarely reaches 90% because operators prefer to keep reserve capacity for unexpected load spikes (flash crowds) or to take on the load of a failed cluster elsewhere in the world. In comparison, an HPC application may run at full CPU utilization for days or weeks.
机房建设固定成本随着时间分摊出去,所以要尽可能减少运维成本。WSCs利用率的特征是:fully idle和high load的时间都非常少, 大部分时间都是处低负载的情况,这也是为什么WSC设计者强调EPC的理由:如果低负载的话,那么就要低功耗。
Power- and energy-related costs are particularly important for WSCs because of their size. In addition, fixed engineering costs can be amortized over large deployments, and a high degree of automation can lower the cost of managing these systems. As a result, the cost of the WSC “enclosure” itself (the datacenter facility, the power, and cooling infrastructure) can be a large component of its total cost, making it paramount to maximize energy efficiency and facility utilization. For example, intelligent power provisioning strategies such as peak power oversubscription may allow more systems to be deployed in a building.
The utilization characteristics of WSCs, which spend little time fully idle or at very high load levels, require systems and components to be energy efficient across a wide load spectrum, and particularly at low utilization levels. The energy efficiency of servers and WSCs is often overestimated using benchmarks that assume operation peak performance levels. Machines, power conversion systems, and the cooling infrastructure often are much less efficient at the lower activity levels, for example, at 30% of peak utilization, that are typical of production systems. We suggest that energy proportionality be added as a design goal for computing components. Ideally, energy-proportional systems will consume nearly no power when idle (particularly while in active idle states) and gradually consume more power as the activity level increases. Energy-proportional components could substantially improve energy efficiency of WSCs without impacting the performance, availability, or complexity. Unfortunately, most of today’s components (with the exception of the CPU) are far from being energy proportional.