The Anatomy Of The Google Architecture
Table of Contents
http://www.slideshare.net/hasanveldstra/the-anatomy-of-the-google-architecture-fina-lv11 @ 2009.12
1. The Google Philosophy
- Jedis build their own lightsabres (the MS Eat your own Dog Food)
- Parallelize Everything
- Distribute Everything (to atomic level if possible)
- Compress Everything (CPU cheaper than bandwidth) 优化带宽
- Secure Everything (you can never be too paranoid)
- Cache (almost) Everything
- Redundantize Everything (in triplicate usually)
- Latency is VERY evil
2. The Basic Glue
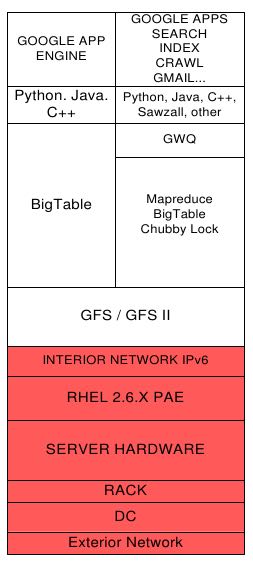
- Exterior Network (Perimeter Architecture) (外部接入层)
- Data Centre(数据中心)
- Rack Characteristics(机架设计)
- Core Server Hardware(硬件设计)
- Operating System Implementation(操作系统)
- Interior Network Architecture(内部网络架构)
2.1. Exterior Network
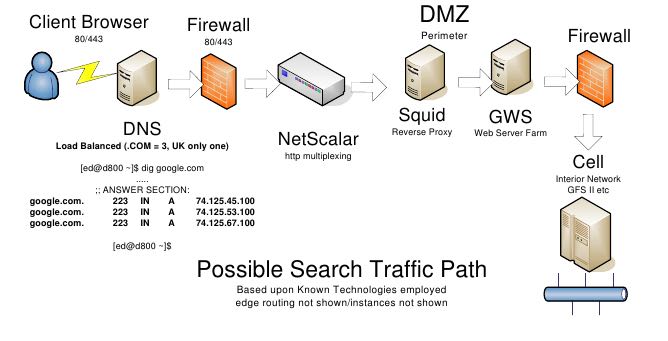
- DNS Load Balanced splits traffic (country, .com multiple DNS, other X1) to FW
- Firewall filters traffic (http/s, smtp,pop etc)
- Netscalar Load Balancers take Request from FW blocks DOS attacks, ping floods (DOS) - blocks non IPv4/6 and none 80/443 ports and http multiplexes (limited caching capability)
- User Request forwarded to Squid (Reverse Proxy) probably HUGE cache (Petabytes?)
- 反向代理,似乎是穿透型的cache
- 缓存命中率30-60%
- All Image Thumbnails caches, much Multimedia cached, Expensive common queries cached 缩略图片,多媒体以及开销比较大的搜索
- If not in Cache forwarded to GWS (Custom C++ Web Server) - now not using Custom apache?
- GWS sends the Request to appropriate internal (Cell) servers
2.2. Data Centre
- Last estimated were 36 Data Centers, 300+ GFSII Clusters and upwards of 800K machines.(36个数据中心,300+ GFS2集群, 80万机器 )
- US (#1) - Europe (#2) - Asia (#3) - South America/Russia (#4)
- Australia - on Hold
- Future: Taiwan, Malaysia, Lithuania, and Blythewood, South Carolina.
- Standard Google Modular DC (Cell) holds 1160 Servers / 250KW Power Consumption in 30 racks (40U).(cell有30个rack,支持40U one side.)
- A Data Centre would consist of 100s of Modular Cells.(每个数据中心最多100左右个cell)
- MDCs can also be deployed autonomously at the Perimeter (stand alone). MDC可以独立部署
2.3. Rack

- Mini Server Size
- Old Servers are Custom 1U
- New Servers are 2U
- seem 1/3 width of a normal 2U Server 宽度为普通2U服务器的1/3宽
- 40U/80U Custom Racks (50% each side)
- Huge Heating and Power Issues(冷却系统)
- Optimized Motherboards(主板优化)
- Have their own HW builds(定制硬件)
- Motherboard directly mounted into Rack
- servers have no casing - just bare boards(没有盖子)
- assist with heat dispersal issues
2.4. Hardware
#note: 配置都非常普通
- 2U Low-Cost (but not slow) Commodity Servers
- 2009 Currently 2-Way, Dual Core/16GB/1-2TB +- Standard
- Both Intel/AMD Chipsets - 1 NIC - 2 USB
- Looks like they RAID1/mirror the disks for better I/O - read performance
- SATA 7.2K/10K/15K drives? 8 x 2GB DDR3 ECC
- Standard HW Build (Several HW Build Versions at any one time)
- Currently at 7Gen Build (1G 2005 was probably Dual Core/SMP)
- Each Server 12V Battery Backup and can run autonomously without external power (lasts 20-30s?)
| YEAR | Average Server Specification |
|---|---|
| 1999/2000 | PII/PIII 128MB+ |
| 2003/2004 | Celeron 533, PIII 1.4 SMP, 2-4GB DRAM, Dual XEON 2.0/1-4GB/40-160GB IDE - SATA Disks via Silicon Images SATA 3114/SATA 3124 |
| 2006 | Dual Opteron/Working Set DRAM(4GB+)/2x400GB IDE (RAID0?) |
| 2009 | 2-Way/Dual Core/16GB/1-2TB SATA |
2.5. Operating System
- 100% Redhat Linux Based since 1998 inception
- RHEL (Why not CentOS?)
- 2.6.X Kernel
- PAE(Physical Address Extension) 物理地址扩展,32位下面支持64GB内存
- Custom glibc.. rpc… ipvs…
- Custom FS (GFS II)
- Custom Kerberos
- Custom NFS
- Custom CUPS
- Custom gPXE bootloader #note: open-source network booting software
- Custom EVERYTHING…..
- Kernel/Subsystem Modifications
- tcmalloc - replaces glibc 2.3 malloc - much faster! works very well with threads…
- rpc - the rpc layer extensively modified to provide > perf increase < latency (52%/40%) #todo: ???
- Significantly modified Kernel and Subsystems - all IPv6 enabled
- Developed and maintained systems to automate installation, updates, and upgrades of Linux systems.
- Served as technical lead of team responsible for customizing and deploying Linux to internal systems and workstations.
- Use Python as the primary scripting language
- Deploy Ubuntu internally (likely for the Desktop) - also Chrome OS base
2.6. Interior Network
Routing Protocol:
- Internal network is IPv6 (exterior machines can be reached using IPv6)
- Heavily Modified Version of OSPF as the IRP
- Intra-rack network is 100baseT
- Inter-rack network is 1000baseT
- Inter-DC network pipes unknown but very fast
Technology:
- Juniper, Cisco, Foundry, HP, routers and switches
Software:
- ipvs (ip virtual server)
3. The Major Glue
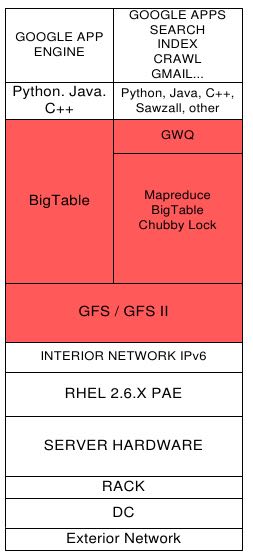
- Google File System Architecture - GFS II
- Google Database - Bigtable
- Google Computation - Mapreduce
- Google Scheduling - GWQ
3.1. GOOGLE FILE SYSTEM
- GFS II “Colossus“ Version 2 improves in many ways (is a complete rewrite)
- Elegant Master Failover (no more 2s delays…) master 2s内可以恢复
- Chunk Size is now 1MB - likely to improve latency for serving data other than Indexing 偏向实时处理,chunksize=1MB
- Master can store more Chunk Metadata (therefore more chunks addressable up to 100 million) = also more Chunk Servers 支持亿级别chunk
3.2. GOOGLE DATABASE
- Increased Scalability (across Namespace/Datacenters)
- Tablets spread over DC s for a table but expensive (both computationally and financially!) #note: 对于tablet跨数据中心的话代价非常大
- Multiple Bigtable Clusters replicated throughout DC 数据中心之间的bigtable集群相互同步。
- Current Status
- Many Hundreds may be thousands of Bigtable Cells. Late 2009 stated 500 Bigtable clusters(2009年500个多个bigtable cluster)
- At minimum scaled to many thousands of machine per cell in production 每个集群上面有上千台机器。
- Cells manage Managing 3-figure TB data (0.X PB) 每个集群管理PB级别数据。
3.3. GOOGLE MAPREDUCE
- STATISTICS
- In September 2009 Google ran 3,467,000 MR Jobs with an average 475 sec completion time averaging 488 machines per MR and utilising 25.5K Machine years
- Technique extensively used by Yahoo with Hadoop (similar architecture to Google) and Facebook (since 06 multiple Hadoop clusters, one being 2500CPU/1PB with HBase).
3.4. GOOGLE WORKQUEUE
- Batch Submission/Scheduler System 批量提交和调度系统
- Arbitrates (process priorities) Schedules, Allocates Resources, process failover, Reports status, collects results 优先级分配资源,处理failover,汇报状态
- Workqueue can manage many tens of thousands of machines 管理上万机器
- Launched via API or command line (sawzall example shown)
saw --program code.szl --workqueue testing --input_files /gfs/cluster1/2005-02-0[1-7]/submits.* \ --destination /gfs/cluster2/$USER/output@100
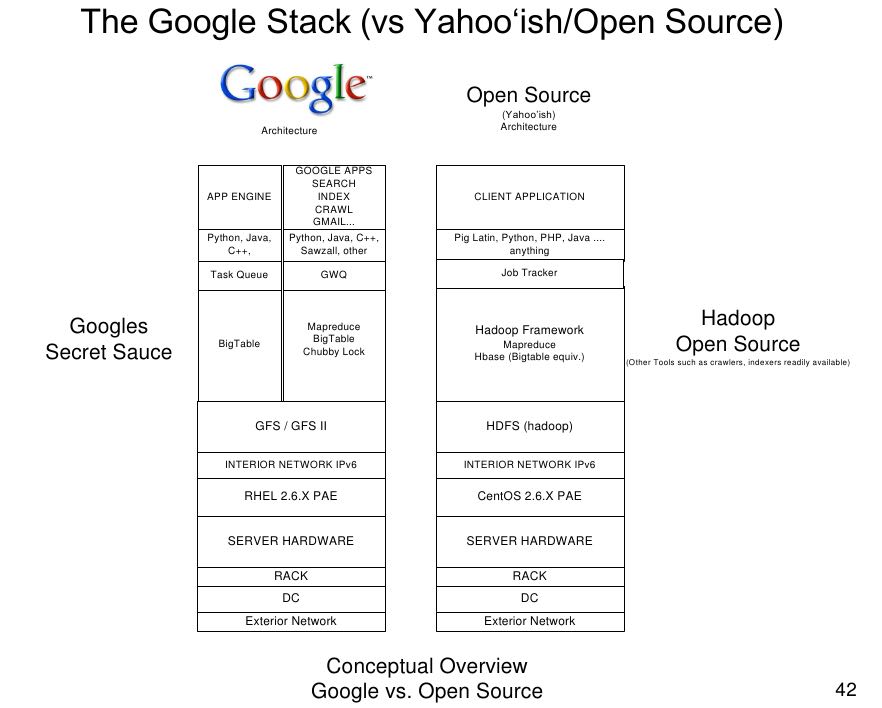
4. BUILD YOUR OWN GOOGLE
- Google PROFITS US $16M A DAY
- “Libraries are the predominant way of building programs”
- Agile Methodologies Used (development iterations, teamwork, collaboration, and process adaptability throughout the life-cycle of the project) #todo: 敏捷开发?
- An infrastructure handles versioning of applications so they can be release without a fear of breaking things = roll out with minimal QA #todo: 持续集成?