Tenzing A SQL Implementation On The MapReduce Framework
Table of Contents
- 1. ABSTRACT
- 2. INTRODUCTION
- 3. HISTORY AND MOTIVATION
- 4. IMPLEMENTATION OVERVIEW
- 5. SQL FEATURES
- 6. PERFORMANCE
- 7. RELATED WORK
- 8. CONCLUSION
- http://research.google.com/pubs/pub37200.html @ 2011
- http://duanple.blog.163.com/blog/static/70971767201192484915767/
这个MR框架实现和Hadoop还不太一样。这里的worker是常驻的,实现上应该是接收master的指令并被通知输入位置,完成之后通知master完成计算以及输出位置,但是计算上还是Map+Reduce实现方式,多轮迭代应该也是通过多轮的mapreduce来完成的。可以减少mapper/reducer启动带来的额外开销和延迟,并且最终给出的是一个通用框架。
1. ABSTRACT
2. INTRODUCTION
- In this paper, we describe Tenzing, a SQL query execution engine built on top of MapReduce.
- We have been able to build a system with latency as low as ten seconds, high effciency, and a comprehensive SQL92 implementation with some SQL99 extensions.
- Tenzing also supports efficiently querying data in row stores, column stores, Bigtable, GFS, text and protocol buffers.
- Users have access to the underlying platform through SQL extensions such as user defined table valued functions and native support for nested relational data.
3. HISTORY AND MOTIVATION
- At the end of 2008, the data warehouse for Google Ads data was implemented on top of a proprietary third-party database appliance henceforth referred to as DBMS-X. While it was working reasonably well, we faced the following issues:
- Increased cost of scalability: our need was to scale to petabytes of data, but the cost of doing so on DBMS-X was deemed unacceptably high.
- Rapidly increasing loading times: importing new data took hours each day and adding new data sources took proportionally longer. Further, import jobs competed with user queries for resources, leading to poor query performance during the import process
- Analyst creativity was being stifled by the limitations of SQL and lack of access to multiple sources of data. An increasing number of analysts were being forced to write custom code for more complex analysis, often directly against the source (such as Sawzall against logs).
- We decided to do a major re-design of the existing plat-form by moving all our analysis to use Google infrastructure, and specifically to the MapReduce platform. The new plat-form had to:
- Scale to thousands of cores, hundreds of users and petabytes of data.
- Run on unreliable off-the-shelf hardware, while contin-uing to be highly reliable.
- Match or exceed the performance of the existing plat-form.
- Have the ability to run directly off the data stored on Google systems, to minimize expensive ETL processes.
- Provide all the required SQL features to the analysts to minimize the learning curve, while also support-ing more advanced functionality such as complex user-defined functions, prediction and mining.
4. IMPLEMENTATION OVERVIEW
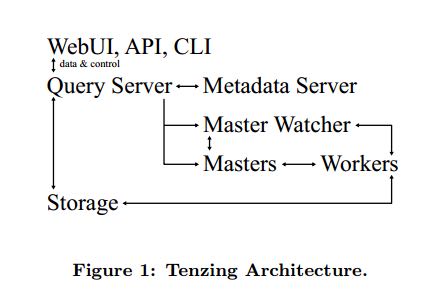
The system has four major components: the worker pool, query server, client interfaces, and metadata server.
- The distributed worker pool is the execution system which takes a query execution plan and executes the MapRe-duces.
- In order to reduce query latency, we do not spawn any new processes, but instead keep the processes running constantly. This allows us to significantly decrease the end-to-end latency of queries.
- The pool consists of master and worker nodes, plus an overall gatekeeper called the master watcher. The workers manipulate the data for all the tables defined in the metadata layer.
- Since Tenzing is a heteroge-neous system, the backend storage can be a mix of various data stores, such as ColumnIO, Bigtable, GFS files, MySQL databases, etc.
- The query server serves as the gateway between the client and the pool. (query server解析请求并且进行执行优化)
- The query server parses the query, ap-plies optimizations and sends the plan to the master for execution.
- The Tenzing optimizer applies some basic rule and cost based optimizations to create an optimal execution plan.
- Tenzing has several client interfaces, including a com-mand line client (CLI) and a Web UI.
- The CLI provides more power such as complex scripting and is used mostly by power users.
- The Web UI, with easier-to-use features such as query & table browsers and syntax highlighting, is geared towards novice and intermediate users.
- There is also an API to directly execute queries on the pool, and a standalone bi-nary which does not need any server side components, but rather launches its own MapReduce jobs.
- The metadata server provides an API to store and fetch metadata such as table names and schemas, and pointers to the underlying data. The metadata server is also responsi-ble for storing ACLs (Access Control Lists) and other secu-rity related information about the tables. The server uses Bigtable as the persistent backing store.(metaserver存储表名和schema,以及数据存储位置,还有ACL等信息)
A typical Tenzing query goes through the following steps:
- A user (or another process) submits the query to the query server through the Web UI, CLI or API.
- The query server parses the query into an intermediate parse tree.(query server解析SQL请求)
- The query server fetches the required metadata from the metadata server to create a more complete inter-mediate format.(从metadata server获取元信息并且决定中间格式)
- The optimizer goes through the intermediate format and applies various optimizations.(优化器进行优化)
- The optimized execution plan consists of one or more MapReduces. For each MapReduce, the query server finds an available master using the master watcher and submits the query to it. At this stage, the execution has been physically partitioned into multiple units of work(i.e. shards).(对于每个步骤与master watcher交互获取可用master完成每个MapReduce)
- Idle workers poll the masters for available work. Re-duce workers write their results to an intermediate storage.(每个MapReduce,master会交给worker来完成)
- The query server monitors the intermediate area for results being created and gathers them as they arrive. The results are then streamed to the upstream client.(query server返回结果)
5. SQL FEATURES
5.1. Projection And Filtering
5.2. Aggregation
5.3. Joins
5.3.1. BROADCAST JOINS
- If small enough, the secondary table is pulled into the memory of each mapper / reducer process for in- memory lookups, which typically is the fastest method for joining.
- The data structure used to store the lookup data is determined at execution time. For example, if the sec- ondary table has integer keys in a limited range, we use an integer array. For integer keys with wider range, we use a sparse integer map. Otherwise we use a data type specific hash table. (查询存储格式根据数据内容和大小不同而异)
- We apply filters on the join data while loading to re- duce the size of the in-memory structure, and also only load the columns that are needed for the query.(只是fetch必要的记录和字段)
- For multi-threaded workers, we create a single copy of the join data in memory and share it between the threads.(单次查询尽量用同一份copy)
- Once a secondary data set is copied into the worker process, we retain the copy for the duration of the query so that we do not have to copy the data for every map shard. This is valuable when there are many map shards being processed by a relatively small number of workers.(单次查询尽量用同一份copy)
- For tables which are both static and frequently used, we permanently cache the data in local disk of the worker to avoid remote reads. Only the first use of the table results in a read into the worker. Subsequent reads are from the cached copy on local disk.(多次查询之间也尽量用一份copy)
- We cache the join results from the last record; since input data often is naturally ordered on the join at- tribute(s), it saves us one lookup access.(保存最后一次join位置减少查询dataset大小)
5.3.2. REMOTE LOOKUP JOINS
For sources which support remote lookups on index (e.g., Bigtable), Tenzing supports remote lookup joins on the key (or a prefix of the key). We employ an asynchronous batch lookup technique combined with a local LRU cache in order to improve performance. The optimizer can intelligently switch table order to enable this if needed.(通过聚合批量以及异步的方式进行查询)
5.3.3. DISTRIBUTED SORT-MERGE JOINS
Distributed sort-merge joins are the most widely used joins in MapReduce implementations. Tenzing has an im- plementation which is most effective when the two tables being joined are roughly the same size and neither has an index on the join key.(比较通用的join算法)
#note: 对应在Hadoop里面就是reducer-join
5.3.4. DISTRIBUTED HASH JOINS
Distributed hash joins are frequently the most effective join method in Tenzing when:
- Neither table fits completely in memory,
- One table is an order of magnitude larger than the other,
- Neither table has an efficient index on the join key.
These conditions are often satisfied by OLAP queries with star joins to large dimensions, a type of query often used with Tenzing.
#note: 对应在Hadoop里面就是mapper-join.在Mapper阶段就将两个需要join的数据按照hash进行划分,然后每个mapper都只是取相应hash的部分
5.4. Analytic Functions
5.5. OLAP Extensions
5.6. Set Operations
5.7. Nested Queries And Subqueries
5.8. Handling Structured Data
5.9. Views
5.10. DML
5.11. DDL
5.12. Table Valued Functions
- Tenzing supports both scalar and table-valued user-defined functions, implemented by embedding a Sawzall interpreter in the Tenzing execution engine. The framework is designed such that other languages can also be easily integrated. In- tegration of Lua and R has been proposed, and work is in progress.(UDF使用swazall实现然后通过内嵌的swazall解释器来运行。同时框架设计上也允许其他语言比如Lua和R来编写UDF)
- Tenzing currently has support for creating func- tions in Sawzall that take tables (vector of tuples) as input and emit tables as output. These are useful for tasks such as normalization of data and doing complex computation involving groups of rows.(所谓的Table Valued Functions就是能够以多个表为输入同时输出多个表,广义一点来看的话就是能够处理vector,这点和scalar对应)
5.13. Data Formats
Tenzing supports direct querying of, loading data from, and downloading data into many formats. Various options can be specified to tweak the exact form of input / output.
- For example, for delimited text format, the user can spec- ify the delimiter, encoding, quoting, escaping, headers, etc.
- ColumnIO, a columnar storage system developed by the Dremel team.
- Bigtable, a highly distributed key-value store.
- Protocol buffers stored in compressed record for- mat (RecordIO) and sorted strings format.
- MySQL databases.
- Data embedded in the metadata (useful for testing and small static data sets).
6. PERFORMANCE
6.1. MapReduce Enhancements
Tenzing is tightly integrated with the Google MapReduce implementation, and we made several enhancements to the MapReduce framework to increase throughput, decrease la-tency and make SQL operators more efficient.(在MapReduce实现上做了一些修改来减少延迟和提高吞吐,以及使得SQL算子操作更有效率)
- Workerpool. One of the key challenges we faced was re-ducing latency from minutes to seconds. It became rapidly clear that in order to do so, we had to implement a solution which did not entail spawning of new binaries for each new Tenzing query(需要将计算的延迟从分钟级别减少到秒级别,在实现上需要使得每次产生新的query不会开辟新的进程)。The MapReduce and Tenzing teams collab-oratively came up with the pool implementation. A typical pool consists of three process groups:
- The master watcher. The watcher is responsible for receiving a work request and assigning a free master for the task. The watcher also monitors the overall health of the pool such as free resources, number of running queries, etc. There is usually one one watcher process for one instance of the pool.(master watcher接收请求然后将这个任务指派给master,然后这个master去调度这个请求,同时监控总体资源情况)
- The master pool. This consists of a relatively small number of processes (usually a few dozen). The job of the master is to coordinate the execution of one query. The master receives the task from the watcher and distributes the tasks to the workers, and monitors their progress. Note that once a master receives a task, it takes over ownership of the task, and the death of the watcher process does not impact the query in any way.(针对某个job临时的jobtracker)
- The worker pool. This contains a set of workers (typi-cally a few thousand processes) which do all the heavy lifting of processing the data. Each worker can work as either a mapper or a reducer or both. Each worker constantly monitors a common area for new tasks and picks up new tasks as they arrive on a FIFO basis. We intend to implement a priority queue so that queries can be tiered by priority.(以FIFO方式完成所有提交的task,可以担任mapper/reducer的角色)
- Using this approach, we were able to bring down the la-tency of the execution of a Tenzing query itself to around 7 seconds. (使用上面的方式可以将查询延迟降到7s)
- There are other bottlenecks in the system however, such as computation of map splits, updating the metadata service, committing / rolling back results (which involves file renames), etc. which means the typical latency varies between 10 and 20 seconds currently. (但是还有一些其他瓶颈比如计算map split,更新metadata信息,重命名文件等,这些时间加在一起在10-20s左右变化)
- We are working on various other enhancements and believe we can cut this time down to less than 5 seconds end-to-end, which is fairly ac-ceptable to the analyst community.
- Streaming & In-memory Chaining. #note: 类似 MapReduce-Online 中提到的做法
- The original im-plementation of Tenzing serialized all intermediate data to GFS. This led to poor performance for multi-MapReduce queries, such as hash joins and nested sub-selects.(中间物化代价非常高)
- We im-proved the performance of such queries significantly by im-plementing streaming between MapReduces, i.e. the up-stream and downstream MRs communicate using the net-work and only use GFS for backup.(通过网络传输但是在GFS上进行备份)
- We subsequently im-proved performance further by using memory chaining, where the reducer of the upstream MR and the mapper of the downstream MR are co-located in the same process.(上下游pipelining)
- #note: 感觉可能还是spark/shark架构会更加合适,很明显MapReduce方式不太适合DAG计算
- Sort Avoidance. 一些操作不需要做sort可以关闭,这样mapper输出直接就feed给reducer.
- Certain operators such as hash join and hash aggregation require shuffling, but not sorting. The MapReduce API was enhanced to automatically turn off sorting for these operations.
- When sorting is turned off, the mapper feeds data to the reducer which directly passes the data to the Reduce() function bypassing the intermediate sorting step. This makes many SQL operators significantly more efficient.
- Block Shuffle. 如果不需要做sort的话那么进行shuffle的时候,那么可以通过将rows聚合成为一个block,以block为单元进行shuffle.
- Typically, MapReduce uses row based en-coding and decoding during shuffle. This is necessary since in order to sort the data, rows must be processed individu-ally. However, this is inefficient when sorting is not required.
- We implemented a block-based shuffle mechanism on top of the existing row-based shuffler in MapReduce that combines many small rows into compressed blocks of roughly 1MB in size.
- By treating the entire block as one row and avoiding reducer side sorting, we were able to avoid some of the over-head associated with row serialization and deserialization in the underlying MapReduce framework code.
- This lead to 3X faster shuffling of data compared to row based shuffling with sorting.
- Local Execution. 如果处理数据非常小的话那么可以在本地执行而不需要提交到worker pool.
- The backend can detect the size of the underlying data to be processed. If the size is under a threshold (typically 128 MB), the query is not sent to thepool, but executed directly in the client process. This re-duces the query latency to about 2 seconds.
6.2. Scalability
6.3. System Benchmarks
6.4. Experimental LLVM Query Engine
- Our execution engine has gone through multiple itera- tions to achieve single-node efficiency close to commercial DBMS.
- The first implementation translated SQL expres- sions to Sawzall code. This code was then compiled using Sawzall’s just-in-time (JIT) compiler. However, this proved to be inefficient because of the serialization and deserializa- tion costs associated with translating to and from Sawzall’s native type system. (第一版通过将SQL表达式编译成为Swazall代码,然后Swazall通过JIT编译器编译然后运行。但是和Sawzall native type system之间转换的序列化和反序列化代价太高)
- The second and current implementation uses Dremel’s SQL expression evaluation engine, which is based on direct evaluation of parse trees of SQL expressions. While more efficient than the original Sawzall implementa- tion, it was still somewhat slow because of its interpreter-like nature and row based processing.(通过Dremel SQL表达式计算引擎,但是计算引擎实现本质上是解释器,同时处理方式是基于行的)
- For the third iteration, we did extensive experiments with two major styles of execution: LLVM based native code gen- eration with row major block based intermediate data and column major vector based processing with columnar in- termediate storage.(LLVM生成本地代码运行,并且有两种中间存储格式)