The Tail at Scale
Table of Contents
- 1. Introduction
- 2. Key Insights
- 3. Why Variability Exists?
- 4. Component-Level Variability Amplified By Scale
- 5. Reducing Component Variability
- 6. Living with Latency Variability
- 7. Within Request Short-Term Adaptations
- 8. Cross-Request Long-Term Adaptations
- 9. Large Information Retrieval Systems
- 10. Mutations
- 11. Hardware Trends and Their Effects
- 12. Conclusion
- http://cacm.acm.org/magazines/2013/2/160173-the-tail-at-scale/fulltext
- http://duanple.blog.163.com/blog/static/7097176720133511217445/
1. Introduction
2. Key Insights
- It is challenging for service providers to keep the tail of latency distribution short for interactive services as the size and complexity of the system scales up or as overall use increases. Temporary high-latency episodes (unimportant in moderate-size systems) may come to dominate overall service performance at large scale.(大规模集群保持低延迟是一件非常具有挑战性的事情。随着集群规模扩大,原来一些临时的高延迟时间会逐渐扩大,最终影响整体性能)
- Just as fault-tolerant computing aims to create a reliable whole out of less-reliable parts, large online services need to create a predictably responsive whole out of less-predictable parts; we refer to such systems as "latency tail-tolerant," or simply "tail-tolerant."(大型在线系统需要能够在将一些难以预测的部件组合能够以预测的方式进行相应,就像从一些不可靠的组件搭建成一个可靠的系统,称之为tail-tolerant system)
- Here, we outline some common causes for high-latency episodes in large online services and describe techniques that reduce their severity or mitigate their effect on whole-system performance. In many cases, tail-tolerant techniques can take advantage of resources already deployed to achieve fault-tolerance, resulting in low additional overhead. We explore how these techniques allow system utilization to be driven higher without lengthening the latency tail, thus avoiding wasteful overprovisioning.(分析出现尾部高延迟的原因,然后提出一些技术来解决这个问题,这些技术能够直接利用现有的fault-tolerance system)
3. Why Variability Exists?
Variability of response time that leads to high tail latency in individual components of a service can arise for many reasons, including:
- Shared resources. Machines might be shared by different applications contending for shared resources (such as CPU cores, processor caches, memory bandwidth, and network bandwidth), and within the same application different requests might contend for resources;(共享资源导致资源竞争)
- Daemons. Background daemons may use only limited resources on average but when scheduled can generate multi-millisecond hiccups;(后台程序消耗资源有限但是触发调度容易产生停滞)
- Global resource sharing. Applications running on different machines might contend for global resources (such as network switches and shared file systems);(全局资源共享)
- Maintenance activities. Background activities (such as data reconstruction in distributed file systems, periodic log compactions in storage systems like BigTable, and periodic garbage collection in garbage-collected languages) can cause periodic spikes in latency; and(日常维护性质活动,比如hbase的compaction)
- Queueing. Multiple layers of queueing in intermediate servers and network switches amplify this variability.(中间服务器以及网络交换机的排队)
Increased variability is also due to several hardware trends:
- Power limits. Modern CPUs are designed to temporarily run above their average power envelope, mitigating thermal effects by throttling if this activity is sustained for a long period;(现代CPU有时候能够以超过平均功率上限运行,但是如果活动会持续很长时间的话那么通过throttling机制来防止过热)
- Garbage collection. Solid-state storage devices provide very fast random read access, but the need to periodically garbage collect a large number of data blocks can increase read latency by a factor of 100 with even a modest level of write activity; and(ssd需要定义做垃圾回收腾出空间)
- Energy management. Power-saving modes in many types of devices save considerable energy but add additional latency when moving from inactive to active modes.(一些设备考虑功耗问题导致从inactive到active状态会有比较长的延迟)
4. Component-Level Variability Amplified By Scale
- A common technique for reducing latency in large-scale online services is to parallelize sub-operations across many different machines, where each sub-operation is co-located with its portion of a large dataset. Parallelization happens by fanning out a request from a root to a large number of leaf servers and merging responses via a request-distribution tree. These sub-operations must all complete within a strict deadline for the service to feel responsive.(通常通过将请求并行化来减少总体延迟。整个请求的图状结构是tree,一级一级fanout出去。对于root来说需要控制好每个sub request的deadline来确保最终的响应及时)
- Variability in the latency distribution of individual components is magnified at the service level(单个组件上的延迟变差范围容易在服务级别放大)
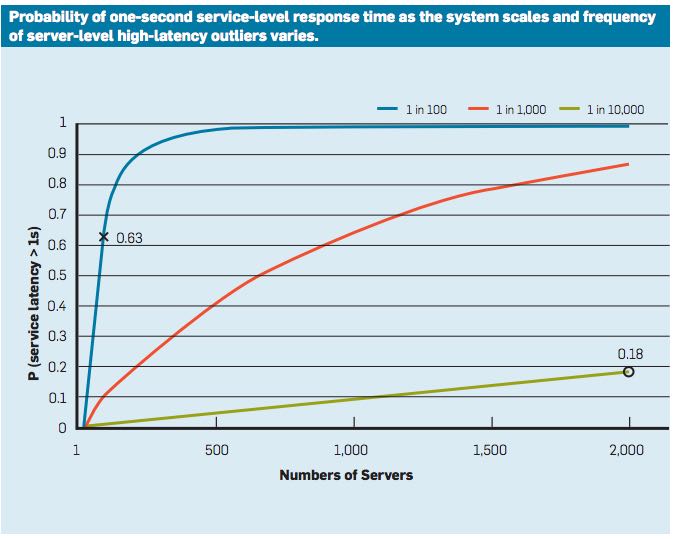
- for example, consider a system where each server typically responds in 10ms but with a 99th-percentile latency of one second.(假设服务大部分是在10ms,但是99%里面最大是1s)
- If a user request is handled on just one such server, one user request in 100 will be slow (one second).(也就是说在100个请求里面存在1个是超时的)
- The figure here outlines how service-level latency in this hypothetical scenario is affected by very modest fractions of latency outliers.
- If a user request must collect responses from 100 such servers in parallel, then 63% of user requests will take more than one second (marked "x" in the figure).(如果需要请求100个服务的话,那么只有63%的概率能够在1s内返回) (0.99 ^^ 100 = 0.63)
- Even for services with only one in 10,000 requests experiencing more than one-second latencies at the single-server level, a service with 2,000 such servers will see almost one in five user requests taking more than one second (marked "o" in the figure).(如果99.99%里面最大是1s的话,如果在2000台规模的话,那么也有1/5的请求不能够正常返回)
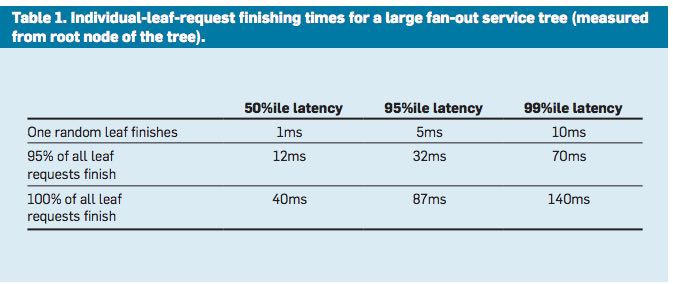
- Table 1 lists measurements from a real Google service that is logically similar to this idealized scenario;
- root servers distribute a request through intermediate servers to a very large number of leaf servers. The table shows the effect of large fan-out on latency distributions.
- The 99th-percentile latency for a single random request to finish, measured at the root, is 10ms. However, the 99th-percentile latency for all requests to finish is 140ms, and the 99th-percentile latency for 95% of the requests finishing is 70ms, meaning that waiting for the slowest 5% of the requests to complete is responsible for half of the total 99%-percentile latency.
- Techniques that concentrate on these slow outliers can yield dramatic reductions in overall service performance.
- Overprovisioning of resources, careful real-time engineering of software, and improved reliability can all be used at all levels and in all components to reduce the base causes of variability.
5. Reducing Component Variability
Interactive response-time variability can be reduced by ensuring interactive requests are serviced in a timely manner through many small engineering decisions, including:
- Differentiating service classes and higher-level queuing. Differentiated service classes can be used to prefer scheduling requests for which a user is waiting over non-interactive requests. Keep low-level queues short so higher-level policies take effect more quickly; for example, the storage servers in Google's cluster-level file-system software keep few operations outstanding in the operating system's disk queue, instead maintaining their own priority queues of pending disk requests. This shallow queue allows the servers to issue incoming high-priority interactive requests before older requests for latency-insensitive batch operations are served.(将服务等级进行划分,交互式请求响应优先级最高。 在low-level上的queue尽可能低短,这样在high-level上面就能够实现更多的策略 )
- Reducing head-of-line blocking. High-level services can handle requests with widely varying intrinsic costs. It is sometimes useful for the system to break long-running requests into a sequence of smaller requests to allow interleaving of the execution of other short-running requests; for example, Google's Web search system uses such time-slicing to prevent a small number of very computationally expensive queries from adding substantial latency to a large number of concurrent cheaper queries.(将每个request进行拆分然后各个subrequest之间能够穿插执行,这样能够防止一些长时间运行的request阻塞住短时间运行的request)
- Managing background activities and synchronized disruption. Background tasks can create significant CPU, disk, or network load; examples are log compaction in log-oriented storage systems and garbage-collector activity in garbage-collected languages. A combination of throttling, breaking down heavyweight operations into smaller operations, and triggering such operations at times of lower overall load is often able to reduce the effect of background activities on interactive request latency. For large fan-out services, it is sometimes useful for the system to synchronize the background activity across many different machines. This synchronization enforces a brief burst of activity on each machine simultaneously, slowing only those interactive requests being handled during the brief period of background activity. In contrast, without synchronization, a few machines are always doing some background activity, pushing out the latency tail on all requests.(将后台任务分解成为更多的子任务在系统空闲的时候执行。有时候同步执行一些background activity可能是有好处的,因为这样只是增加了一段时间的响应延迟,而如果这些activity是在各个机器上面随机执行的话,那么就可能影响所有时间段的请求)
- Missing in this discussion so far is any reference to caching. While effective caching layers can be useful, even a necessity in some systems, they do not directly address tail latency, aside from configurations where it is guaranteed that the entire working set of an application can reside in a cache.(缓存,但是缓存本质上不能够解决尾延迟问题,除非应用程序工作集合完全存放于cache内)
6. Living with Latency Variability
- The careful engineering techniques in the preceding section are essential for building high-performance interactive services, but the scale and complexity of modern Web services make it infeasible to eliminate all latency variability. Even if such perfect behavior could be achieved in isolated environments, systems with shared computational resources exhibit performance fluctuations beyond the control of application developers(对于large-scale系统来说本质上是不能够消除latency variability的)
- Google has therefore found it advantageous to develop tail-tolerant techniques that mask or work around temporary latency pathologies, instead of trying to eliminate them altogether. We separate these techniques into two main classes:
- The first corresponds to within-request immediate-response techniques that operate at a time scale of tens of milliseconds, before longer-term techniques have a chance to react.(一种是在单次请求响应这个级别上改进,时间规模在ms上)
- The second consists of cross-request long-term adaptations that perform on a time scale of tens of seconds to minutes and are meant to mask the effect of longer-term phenomena.(一种是在跨请求响应之间这个级别上改进,时间规模在sec以及min几倍上)
7. Within Request Short-Term Adaptations
- A broad class of Web services deploy multiple replicas of data items to provide additional throughput capacity and maintain availability in the presence of failures.
- The techniques here show how replication can also be used to reduce latency variability within a single higher-level request(通过使用replication来减少单次请求响应的延迟偏差)
7.1. Hedged requests
- A simple way to curb latency variability is to issue the same request to multiple replicas and use the results from whichever replica responds first.
- We term such requests "hedged requests" because a client first sends one request to the replica believed to be the most appropriate, but then falls back on sending a secondary request after some brief delay. The client cancels remaining outstanding requests once the first result is received.(首先请求第一个replica,delay一段时间如果没有响应的话那么请求第二个replica。一旦收到结果的话那么取消所有其他的请求)
- Although naive implementations of this technique typically add unacceptable additional load, many variations exist that give most of the latency-reduction effects while increasing load only modestly.(通常只会增加少量的负载)
- One such approach is to defer sending a secondary request until the first request has been outstanding for more than the 95th-percentile expected latency for this class of requests. This approach limits the additional load to approximately 5% while substantially shortening the latency tail. The technique works because the source of latency is often not inherent in the particular request but rather due to other forms of interference. (一个方法是如果延迟超过当前的95%百分位的话,那么发起第二个请求,这样相当只是增加了5%的额外开销。因为大部分的请求延迟原因并不是因为请求本身而是因为一些外部因素)
- For example, in a Google benchmark that reads the values for 1,000 keys stored in a BigTable table distributed across 100 different servers, sending a hedging request after a 10ms delay reduces the 99.9th-percentile latency for retrieving all 1,000 values from 1,800ms to 74ms while sending just 2% more requests. The overhead of hedged requests can be further reduced by tagging them as lower priority than the primary requests.
7.2. Tied requests
- The hedged-requests technique also has a window of vulnerability in which multiple servers can execute the same request unnecessarily. That extra work can be capped by waiting for the 95th-percentile expected latency before issuing the hedged request, but this approach limits the benefits to only a small fraction of requests. Permitting more aggressive use of hedged requests with moderate resource consumption requires faster cancellation of requests.(之前的方法只能够改善少量的请求效果。如果能够取消请求的话那么实际上可以采用更加激进的使用方法作用于更多数的请求)
- A common source of variability is queueing delays on the server before a request begins execution. For many services, once a request is actually scheduled and begins execution, the variability of its completion time goes down substantially. (延迟偏差最主要的原因还是因为queue,对于许多服务来说,一旦request进入queue之后那么偏差很快就会下来)
- Mitzenmacher said allowing a client to choose between two servers based on queue lengths at enqueue time exponentially improves load-balancing performance over a uniform random scheme. (可以通过判断两个服务当前queue长度来选择使用) #note: client需要了解server内部情况. 但是可以通过适当封装对用户透明。
- An alternative to the tied-request and hedged-request schemes is to probe remote queues first, then submit the request to the least-loaded server.
- It can be beneficial but is less effective than submitting work to two queues simultaneously for three main reasons:
- load levels can change between probe and request time; (load会随时间变化,而且容易出现thundering herd)
- request service times can be difficult to estimate due to underlying system and hardware variability; (即使选择负载最低的server也不一定能够保证响应时间最短)
- and clients can create temporary hot spots by all clients picking the same (least-loaded) server at the same time. (thundering herd)
- We advocate not choosing but rather enqueuing copies of a request in multiple servers simultaneously and allowing the servers to communicate updates on the status of these copies to each other. We call requests where servers perform cross-server status updates "tied requests."(也可以通过向多个server发送请求,而server之间是可以进行通信的)
- The simplest form of a tied request has the client send the request to two different servers, each tagged with the identity of the other server ("tied"). When a request begins execution, it sends a cancellation message to its counterpart. The corresponding request, if still enqueued in the other server, can be aborted immediately or deprioritized substantially.(一个简单的方式就是请求上标记好tag说明请求哪几个server,这样一旦某个server开始处理的话那么就可以将其他server请求取消)
- There is a brief window of one average network message delay where both servers may start executing the request while the cancellation messages are both in flight to the other server. A common case where this situation can occur is if both server queues are completely empty. It is useful therefore for the client to introduce a small delay of two times the average network message delay (1ms or less in modern data-center networks) between sending the first request and sending the second request.(但是上面方法如果在queue都比较空的时候会造成两个server都在计算,两个server都发送取消信息。解决办法是client在等待一小段时间之后再次发送)
7.3. Experiments
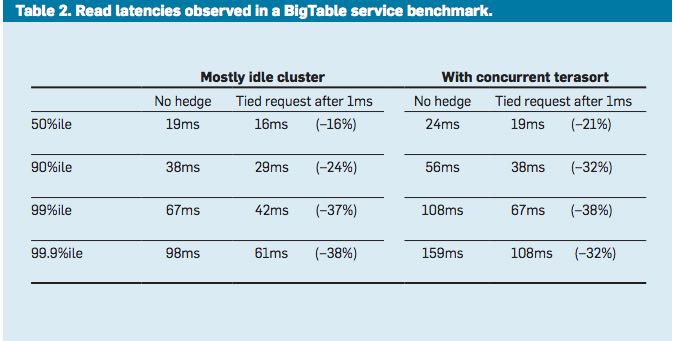
- Google's implementation of this technique in the context of its cluster-level distributed file system is effective at reducing both median and tail latencies.
- Table 2 lists the times for servicing a small read request from a BigTable where the data is not cached in memory but must be read from the underlying file system; each file chunk has three replicas on distinct machines.
- The table includes read latencies observed with and without tied requests for two scenarios:
- The first is a cluster in which the benchmark is running in isolation, in which case latency variability is mostly from self-interference and regular cluster-management activities. In it, sending a tied request that does cross-server cancellation to another file system replica following 1ms reduces median latency by 16% and is increasingly effective along the tail of the latency distribution, achieving nearly 40% reduction at the 99.9th-percentile latency.
- The second scenario is like the first except there is also a large, concurrent sorting job running on the same cluster contending for the same disk resources in the shared file system. Although overall latencies are somewhat higher due to higher utilization, similar reductions in the latency profile are achieved with the tied-request technique discussed earlier. The latency profile with tied requests while running a concurrent large sorting job is nearly identical to the latency profile of a mostly idle cluster without tied requests. Tied requests allow the workloads to be consolidated into a single cluster, resulting in dramatic computing cost reductions.
- In both Table 2 scenarios, the overhead of tied requests in disk utilization is less than 1%, indicating the cancellation strategy is effective at eliminating redundant reads.( 事实上在两种情况下面对于磁盘额外开销小于1%)
8. Cross-Request Long-Term Adaptations
- Here, we turn to techniques that are applicable for reducing latency variability caused by coarser-grain phenomena (such as service-time variations and load imbalance). (考虑一些造成延迟偏差粗粒度的影响)
- Although many systems try to partition data in such a way that the partitions have equal cost, a static assignment of a single partition to each machine is rarely sufficient in practice for two reasons:(静态进行数据partition的缺点)
- First, the performance of the underlying machines is neither uniform nor constant over time, for reasons (such as thermal throttling and shared workload interference) mentioned earlier.(机器并不是同构的,即使是同构的机器性能也会不断变化)
- And second, outliers in the assignment of items to partitions can cause data-induced load imbalance (such as when a particular item becomes popular and the load for its partition increases).(容易造成负载不均衡)
8.1. Micro-partitions
- To combat imbalance, many of Google's systems generate many more partitions than there are machines in the service, then do dynamic assignment and load balancing of these partitions to particular machines. Load balancing is then a matter of moving responsibility for one of these small partitions from one machine to another.(将partition size做小,这样parition number就多,load balanace只需要以partition为单位进行平衡即可)
- Failure-recovery speed is also improved through micro-partitioning, since many machines pick up one unit of work when a machine failure occurs. (同时做故障恢复时间也短因为并行度更高)
8.2. Selective replication
- An enhancement of the micro-partitioning scheme is to detect or even predict certain items that are likely to cause load imbalance and create additional replicas of these items.(对于hot partition可以增加replica的数量)
- Load-balancing systems can then use the additional replicas to spread the load of these hot micro-partitions across multiple machines without having to actually move micro-partitions.(然后load-balancig系统可以平衡这些新增加的replicas)
8.3. Latency-induced probation
- By observing the latency distribution of responses from the various machines in the system, intermediate servers sometimes detect situations where the system performs better by excluding a particularly slow machine, or putting it on probation.(检测server的运行情况,如果出现或者是推断某台server比较慢的话,那么可以将其列入黑名单)
- The source of the slowness is frequently temporary phenomena like interference from unrelated networking traffic or a spike in CPU activity for another job on the machine, and the slowness tends to be noticed when the system is under greater load.(通常slowness原因都是非常类似的,所以可以根据一些现象推断出来)
- However, the system continues to issue shadow requests to these excluded servers, collecting statistics on their latency so they can be reincorporated into the service when the problem abates. This situation is somewhat peculiar, as removal of serving capacity from a live system during periods of high load actually improves latency.(系统能够不断地检测slow machine, 一旦恢复正常的话那么又可以进行服务) #note: 类似hadoop的blacklist tasktracer机制
9. Large Information Retrieval Systems
- In large information-retrieval (IR) systems, speed is more than a performance metric; it is a key quality metric, as returning good results quickly is better than returning the best results slowly.(速度非常重要)
- Two techniques apply to such systems, as well as other to systems that inherently deal with imprecise results:
- Good enough. In large IR systems, once a sufficient fraction of all the leaf servers has responded, the user may be best served by being given slightly incomplete ("good-enough") results in exchange for better end-to-end latency. (不需要等待所有的leaf server返回,只要当前结果足够好就可以返回)
- Since waiting for exceedingly slow servers might stretch service latency to unacceptable levels, Google's IR systems are tuned to occasionally respond with good-enough results when an acceptable fraction of the overall corpus has been searched, while being careful to ensure good-enough results remain rare.
- In general, good-enough schemes are also used to skip nonessential subsystems to improve responsiveness; for example, results from ads or spelling-correction systems are easily skipped for Web searches if they do not respond in time.(有时候这个方案可以推广到其他系统,对于一些不是非常关键的子系统来说,甚至可以不必等待其返回就可以返回结果)
- Canary requests. Another problem that can occur in systems with very high fan-out is that a particular request exercises an untested code path, causing crashes or extremely long delays on thousands of servers simultaneously. To prevent such correlated crash scenarios, some of Google's IR systems employ a technique called "canary requests";(防止特殊请求造成集群集体crash)
- rather than initially send a request to thousands of leaf servers, a root server sends it first to one or two leaf servers. The remaining servers are only queried if the root gets a successful response from the canary in a reasonable period of time.(先发送请求到几台有限的server,如果响应及时的话那么就进行正常请求)
- If the server crashes or hangs while the canary request is outstanding, the system flags the request as potentially dangerous and prevents further execution by not sending it to the remaining leaf servers.(如果会造成crash或者是hang住的话,那么就认为这个请求本身是危险的,那么就不向其他机器发送请求)
- Canary requests provide a measure of robustness to back-ends in the face of difficult-to-predict programming errors, as well as malicious denial-of-service attacks.(能够作为加强健壮性的一种手段)
- The canary-request phase adds only a small amount of overall latency because the system must wait for only a single server to respond, producing much less variability than if it had to wait for all servers to respond for large fan-out requests;
- Despite the slight increase in latency caused by canary requests, such requests tend to be used for every request in all of Google's large fan-out search systems due to the additional safety they provide.
- Good enough. In large IR systems, once a sufficient fraction of all the leaf servers has responded, the user may be best served by being given slightly incomplete ("good-enough") results in exchange for better end-to-end latency. (不需要等待所有的leaf server返回,只要当前结果足够好就可以返回)
10. Mutations
The techniques we have discussed so far are most applicable for operations that do not perform critical mutations of the system's state, which covers a broad range of data-intensive services. Tolerating latency variability for operations that mutate state is somewhat easier for a number of reasons:(之前讨论的都是没有修改系统状态的操作,通常是涉及到数据密集性的服务。而对于修改状态的操作而言情况相对更加简单一些)
- First, the scale of latency-critical modifications in these services is generally small.(规模不会很大)
- Second, updates can often be performed off the critical path, after responding to the user. (对时间响应不是很敏感)
- Third, many services can be structured to tolerate inconsistent update models for (inherently more latency-tolerant) mutations.(服务也可以忍受不一致)
- And, finally, for those services that require consistent updates, the most commonly used techniques are quorum-based algorithms (such as Lamport's Paxos); since these algorithms must commit to only three to five replicas, they are inherently tail-tolerant.(如果需要一致性的话可以使用quorum-based算法,而这些算法通常只是会提交到3-5 replicas,同样规模不是很大)
11. Hardware Trends and Their Effects
- Variability at the hardware level is likely to be higher in the future due to more aggressive power optimizations becoming available and fabrication challenges at deep submicron levels resulting in device-level heterogeneity. Device heterogeneity combined with ever-increasing system scale will make tolerating variability through software techniques even more important over time. (设备级别本身出现延迟偏差的几率是越来越高)
- Fortunately, several emerging hardware trends will increase the effectiveness of latency-tolerating techniques.
- higher bisection bandwidth in data-center networks and network-interface optimizations that reduce per-message overheads (such as remote direct-memory access) will reduce the cost of tied requests, making it more likely that cancellation messages are received in time to avoid redundant work.
- Lower per-message overheads naturally allow more fine-grain requests, contributing to better multiplexing and avoiding head-of-line blocking effects.