系统性能:企业与云计算(Systems Performance: Enterprise and the Cloud)
Table of Contents
http://www.brendangregg.com/blog/2020-07-15/systems-performance-2nd-edition.html
https://book.douban.com/subject/26586598/
这本书主要讲的是系统性能分析方法和优化手段,结合的环境是企业部署和云计算,即大规模系统。我印象比较深刻的就是,如何展示出一个集群下面上千个多核CPU的使用状况。
云计算是未来的趋势,这一点对于技术人员在思考问题和解决问题时非常重要:对于应用开发人员来说,我是否可以利用云来节省成本;对于云环境开发人员来说,我做的事情是否可以扩展到云环境下。
虽然这本书介绍了不少优化工具和手段,但是实际情况是复杂的,可能书中介绍到的工具或者是手段根本就用不上,所以专注在方法和原理会更加重要。从方法和原理出发,结合实际情况,找到可以使用的工具和手段,才是正确的路径。
1. 第2章 方法
系统的各种延时
| 事件 | 延时 | 相对时间比例 |
|---|---|---|
| 1个CPU周期 | 0.3ns(3GHz) | 1s |
| L1缓存 | 0.9ns | 3s |
| L2缓存 | 2.8ns | 9s |
| L3缓存 | 12.9ns | 43s |
| 内存访问 | 120ns | 6分 |
| SSD | 50-150us | 2-6天 |
| 旋转磁盘 | 1-10ms | 1-12月 |
| 互联网:CA-NY | 40ms | 4年 |
| 互联网:CA-UK | 81ms | 8年 |
| 互联网:CA-AU | 183ms | 19年 |
| TCP包重传 | 1-3s | 105-317年 |
| OS虚拟化系统重启 | 4s | 423年 |
| SCSI命令超时 | 30s | 3千年 |
| 硬件虚拟化系统重启 | 40s | 4千年 |
| 物理系统重启 | 5m | 32千年 |
术语“使用率”经常用于描述设备的使用情况,诸如CPU和磁盘设备,有基于时间定义,也有基于容量定义的。基于容量的定义着眼于资源本身可以完成多少事情,那么100%使用率的CPU或者是磁盘是没有办法完成更多任务的;而基于时间的定义着眼于资源有多少比例的时间在处于使用状态(或者是处于空闲这状态),那么100%使用率的CPU或者是磁盘可以通过排队来完成更多的任务。
在大多数情况下,我们更喜欢使用基于时间定义的“使用率”,比如CPU或者是磁盘,如果他们正在满负荷运行的话,那么新来的任务就只能排队。这个排队数量也常被称为饱和度。但是也有一些资源是基于容量的,比如内存,这个就没有饱和度可言。
USE方法(utilization, saturation, errors)应用于性能研究,用来识别系统瓶颈:对于所有的资源,查看它的使用率,饱和度和错误。
建立系统的分析模型有很多用途,特别是对于可扩展性分析:研究当负载或资源扩展时性能会如何变化,这里的资源可以是硬件如CPU核,也可以是软件如进程或线程。
除对生产系统的观测(测量)和实验性测试(仿真)之外,分析建模可以被认为是第三类性能评估方法。上述三者至少择其二可让性能研究最为透彻:分析建模和仿真,或仿真和测量。
如果是对一个现有系统做分析,可以从测量开始,归纳负载特征和测量性能。如果系统没有生产环境复杂或要测试的工作负载在生产环境不可见,可以用工作负载仿真做测试,建模基于测试和仿真的结果,用于性能预测。
可扩展性分析可以揭示性能由于资源限制停止线性增长的点,即拐点。找到这些点是否存在或存在在哪里,这对研究阻碍系统扩展性的性能问题有指导意义。
下面是一系列性能扩展性曲线,没有严格的模型,但用视觉可以识别出各种类型。对于每一条曲线,x轴是扩展的维度,y轴是相应的性能(吞吐量,每秒事务速等等),曲线的类型如下:
- 线性扩展:性能随着资源的扩展成比例的增加,这种情况并非永久持续,但这可能是其他扩展情况的早期阶段。
- 竞争:架构的某些组件是共享的,而且只能串行使用,对这些共享资源的竞争会减少扩展的效益。(在拐点处性能放缓)
- 一致性:由于要维持数据的一致性,传播数据变化的代价会超过扩展带来的好处。(超过拐点性能下降)
- 拐点:某个因素碰到了扩展的制约点,从而改变了扩展曲线。
- 扩展上限:到达了一个性能的极限。该极限可能是设备瓶颈,诸如总线或互连器件到了吞吐量的最大值,或者是一个软件设置的限制(系统资源控制)。
排队理论 Kendall标记法
该标记发为每一个属性指定一个符号,格式如下:A/S/m. 到达过程A, 服务时间分布S以及服务中心数目m。标记法还有扩展格式以及囊括更多的要素:系统中缓冲数目,任务数目上限和服务规则。通常研究的排队系统如下:
- M/M/1: 马尔可夫到达(指数分布到达),马尔可夫服务时间(指数分布),一个服务中心。
- M/M/c: 和M/M/1一样,但是服务中心有多个。
- M/G/1: 马尔可夫到达,服务时间是一般分布,一个服务中心。(通常用于研究旋转的物理硬盘性能)
- M/D/1: 马尔科夫到达,确定性的服务时间(固定时间),一个服务中心。
其中M/D/1是一个相对简单的示例。这个模型有个特点就是:如果使用率超过60%,那么平均响应时间会成为2倍;如果使用率超过80%,那么时间会成为3倍。
可视化 线图/散点图/热图
线图相对简单,为了观察到长尾,最好设置几个百分位:50%,90%,99%.
散点图相比线图,可以观察到具体点的分布情况。在点数量少的情况下没有问题,点重合严重的时候就难以辨认。
热图通过把x和y轴的区域分组量化,能够解决散点图的扩展问题,所分成的组成为“桶”。这些“桶”是涂色的,颜色是依据落在x和y轴区域内的事件数目而定。这样量化既解决了散点图可视化密度上的限制,又使得热图不管显示的是单个系统还是成千上万个系统,都可以用一样的方法。(扩展性很好)
2. 第4章 观测工具
性能观测工具可以按照两个维度划分:范围(系统和进程),方式(计数和跟踪)
| 范围\方式 | 计数 | 跟踪 |
|---|---|---|
| 系统 | vmstat/mpstat/iostat/sar | tcpdump/dtrace/systemtap/perf |
| 进程 | ps/top/pmap | strace/gdb/truss/mdb |
静态和动态追踪
静态追踪是通过在编译之前在源代码中增加静态探针实现的。在源代码中没有可见的动态探针的例子,因为动态探针的是在编译后软件运行时加入的。
动态探针会在函数的入口,利用内核空间的现场修改功能(live patching),将第1个指令变为int的软中断指令,而该软中断已经接到指示执行跟踪的action。内核空间的现场修改功(live patching)能所采用的技术,会因处理器类型的不同而有所不同。
当动态跟踪被开启时,指令才会被替换;而动态跟踪被禁用时,指令会回到原来的状态。所以只有当开启的时候才会存在开销,并且这个开销是和执行action的频率成比例的。
SystemTap 采用其他的内核框架作源:静态探针用tracepoints,动态探针用kprobes,用户级别的探针用uprobes。这些源以为其他的工具所用(perf, LTTng)。
Linux性能事件(Linux Performance Events, LPE),简称为perf,通过不断演化,现在所支持的性能观测的范围已经相当宽泛。虽然没有DTtrace和SystemTap那样的实时编程能力,但perf可以执行静态和动态追踪(基于tracepoints, kprobe和uprobe),还有profiling。此外它还能检查跟踪,局部变量和数据类型。因为它已经成为Linux内核主线的一部分,所以是最容易使用的,所提供的观测能力足够解答你的疑问。
3. 第7章 内存
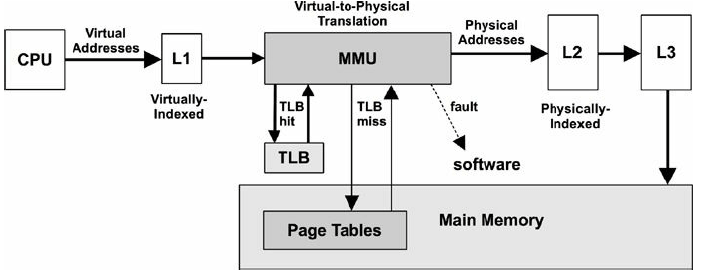
下图描绘了通用的MMU,以及各级CPU缓存和主内存。(访问二级和三级缓存,有一个虚拟地址到物理地址的转换过程,可能会读取页表)
4. 第8章 文件系统
研究应用程序IO性能时经常会发现,文件系统性能比磁盘性能更为重要。文件系统通过缓存,缓冲以及异步IO等手段来缓和磁盘延时对应用程序的影响。尽管如此,性能分析和可用的工具集一直集中在磁盘性能方向。
在动态跟踪技术发达的今天,文件系统分析既简单又实用。本章展示了如何详细剖析文件系统请求,包括从应用程序的角度,使用动态跟踪去度量开始到结束的时间。这使得我们在寻找糟糕性能来源的时候,能够很快排除文件系统以及底下磁盘设备的嫌疑,并把关注点放到其他方面。
应用程序可能会用到其他IO种类如下。
- 裸I/O: 绕过了整个文件系统,直接发给磁盘地址。有些应用程序使用了裸I/O,特别是数据库,因为他们能比文件系统更好的缓存自己的数据。其缺点在于难以管理,即不能使用常用文件系统工具执行备份恢复和监控。
- 直接I/O: 允许应用程序绕过缓存使用文件系统,这有点像同步写,而且在读取时也能用。它没有裸I/O那么直接,文件系统仍会把文件地址映射到磁盘地址,I/O可能会被文件系统重新调整大小以适应文件系统在磁盘上的块大小。不仅仅是读缓存和写缓冲,预取可能也因此失效,这取决于文件系统的实现。
直接IO可用于备份文件系统的应用程序,防止只读一次的数据污染文件系统缓存。裸IO和直接IO还可以用于那些在进程堆里自建缓存的应用程序,避免了双重缓存的问题。
5. 第9章 磁盘
振动对磁盘I/O延时的影响 https://www.youtube.com/watch?v=tDacjrSCeq4
怠工磁盘。当前有一类旋转磁盘的性能问题我们称之为怠工磁盘。这些磁盘有时返回很慢的I/O,超过一秒却不报告任何的错误。事实上它最好报告一个错误,而不是拖这么久才返回,因为如果这样,操作系统或者磁盘控制器就可以实施一些改进性的措施,例如在冗余的环境下把磁盘下线并且报告错误。怠工磁盘比较麻烦,特别当他们作为虚拟磁盘的一部分由存储阵列暴露出来时,这种情况下操作系统并不能直接看到它们,因而提高了问题的辨别难度。
磁盘数据控制器。机械磁盘给系统提供了一套简单的接口,并表明了固定的每磁道扇区数比例和连续的可寻址偏移量范围。事实上磁盘上的一切受磁盘数据控制器的掌控,一个磁盘内部的微处理器,由固件中的逻辑控制。控制器决定磁盘如何排布这些可寻址的偏移量,其中可以实现一些算法如扇区分区。要有这个意识,但是很难分析,操作系统无法得知磁盘数据控制器内部情况。
SSD的控制器有以下任务:
- 输入,每个页面(通常8KB大小)的读和写,只能写已擦除的页面,一次性擦除32~64页。
- 输出,仿真一个硬盘驱动器的块接口,任意扇区数的读或写(4KB or 512B)。
控制器的闪存转换层(FTL, Flash Translation Layer)负责输入和输出之间的转换,同时必须跟踪空闲块。事实上它使用自己的文件系统来完成这个工作,例如一个日志结构文件系统。
由磁盘控制器提供的RAID成为硬件RAID. RAID也可以由操作系统软件实现,不过硬件RAID更受欢迎,原因是在专用硬件上执行大量消耗CPU的校验和以及奇偶校验更为高效。然而处理器的不断进步,使得CPU开始有富余的周期和核心,减少了减负校验计算的需要。一些存储解决方案已经回到了软RAID上(例如使用ZFS)。这样既降低了复杂度和硬件开销,也提高了操作系统的监控性。
6. 第10章 网络
包的长度通常受限于网络接口的最大传输单元(MTU)长度,许多以太网中它设置为1500B,以太网支持接近9000B特大包(帧),也称为巨型帧。这能够提高网络吞吐性能,同时因为需要更少的包而降低了数据传输延时。
这两者的融合影响了巨型帧的接受程度:陈旧的网络硬件和未正确配置的防火墙。陈旧的不支持巨型帧中的硬件可能会用IP协议分段包,或者返回ICMP“不能分段”错误,来要求发送方减小包长度。现在未正确配置的防火墙开始起作用:对于过去基于ICMP的网络工具攻击,防火墙管理员通常以阻塞所有的ICMP包方式应对。这会阻止所有用的“不能分段”报文到达发送方,并且一旦包长度超过1500B,将导致网络包被静默丢弃。为避免这个问题,许多系统坚持使用默认的1500MTU。
交换机提供两个连入的主机专用的通信路径,允许多对主机间的多个传输不受影响。此技术取代了集线器,而在此之前是共享物理总线,例如以太网同轴线。集线器在所有主机间共享所有包,当主机同时传输时,这种共享就会导致竞争。在高负载情况下,这种行为会导致性能问题。自使用交换机以后就不再存在这种问题了。
路由器在网络间传递数据包,并且用网络协议和路由表来确认最佳的传递路径。两个城市将发送一个数据包,可能涉及10多个甚至更多的路由器,以及其他的网络硬件。路由器和路由经常是设置为动态更新的,因此网络能够自动响应网络和路由器的停机,以及平衡负载。
路由器和交换机都包含微处理器,它们本身在高负载情况下会成为性能瓶颈。作为一个极端的例子,我曾经发现因为有限的CPU能力,一个早期的10GbE以太网交换机只能在所有端口上驱动11Gb/s.
sysctl -a | grep tcp 来查看TCP的设置参数
- net.core.rmem_max/wmem_max 用来设置套接字的读写最大缓冲大小
- tcp_moderate_rcvbuf=1 启动TCP接受缓冲的自动调整
- net.ipv4.tcp_rmem/wmem 设置读写的缓冲区大小,分别是最小/默认/最大字节数
- tcp_max_sync_backlog=4096 收到第一个SYN的连接缓冲队列长度
- net.core.somaxconn=1024 TCP连接建议等待accept的缓冲队列长度
- net.core.netdev_max_backlog=10000 每个CPU的网络设备积压队列长度
- net.ipv4.tcp_tw_reuse=1 重新利用TIME_WAIT会话
- net.ipv4.tcp_tw_recycle=0 也可以重新利用TIME_WAIT会话,但是没有上面安全
7. 第11章 云计算
虚拟化有两种方式:OS虚拟化和硬件虚拟化。OS虚拟化类似cgroups这样的方案,硬件虚拟化则是类似VMWare/KVM/Xen这样的方案。硬件虚拟化也分为好几种,但是我完全不懂之间的差别,后面有机会要好好学习下。
8. 第13章 案例研究
对于初学者而言,在你研究性的问题时迷失方向会令人沮丧,这种感觉也是正常的:你会感觉迷失,你会犯错误的想法,经常会是错的。这里引用尼尔斯波尔,一位丹麦物理学家的话:“所谓专家,就是即使在很狭小的领域也犯过所有错误的人。”通过给你们讲这个故事,我希望能安慰你们,犯错误和走错方向是正常的,即便是我们中最杰出的人,并希望这些技术和方法能帮助你们找到自己的道路。