A Glance on StreamBase
Table of Contents
StreamBase是一款商业流式计算系统,被一些金融行业和政府部门使用。
- 金融行业:http://www.mittrchinese.com/single.php?p=67643
- 政府部门:http://www.cnw.com.cn/weekly/htm2006/20060302_45800.shtml
StreamBase是一个商业应用软件,但是提供了develop edition.相对于付费使用的enterprise edition功能更少,但是不妨碍我们从外部使用和API接口来对StreamBase本身进行分析。文档还是比较丰富的,但是因为时间和精力限制我们不能够针对里面每个部件进行仔细分析,并且很多功能并没有试用。
1. Development
StreamBase本身是使用Java编写的,IDE称为StreamBase Studuo.IDE是基于Eclipse来进行二次开发的,所以IDE本身功能是非常强大的。但是StreamBase的IDE并不仅仅限于编写代码方便这一层。StreamBase本身提供了相当多operator,functor以及组件来帮助构建应用程序,用户本身在IDE上面可能只需要拖拖控件,然后相关联一些,设置好传输的schema并且设置一下控件计算过程,就可以编译出一个高效处理的流式计算应用程序了。同时StreamBase本身提供了类SQL来表达计算过程。
对于编译这个过程而言的话,StreamBase是注册专利了。考虑一下如果我们仅仅是拖拖控件并且让各个组件之间相连的话,本身之间的数据是怎么传输的,拥塞控制是怎么做的,这些代码必然是在布局完成之后才可以生成的,所以相对来说也是值得申请专利的。并且StreamBase IDE以一种非常直观的方式来在一个canvas(画布)上面将这个应用程序框架布置好然后编译,确实可以让我们从高层的角度看到每个部件的工作细节,比如直接看到这个container的参数如何,ip/port分别是什么等。
2. Framework
http://streambase.com/developers/docs/latest/admin/ha-designing.html#d0e13346
我们这里不打算试图使用一个框图来表现StreamBase框架,使用代码的话可能会更好一些。注意我们启动的就是StreamBaseServer进程。
class StreamBaseServer{ // 对于一个StreamBaseServer来说的话包含了一系列Container Collection< Container > containers; }; // 对于Container我们手工指定了输入和输出 class Container{ // 每个Container包含下面这些要素 string uri; // container资源定位,需要手动填写 Application app; // container application.每一个container对应一个application // 每一个application也必须在一个container下面运行 // 但是用户不care这个部分,只care自己的app InputStream input; // 输入流,交给application处理 OutputStream output; // 输出流,application输出之后放在这个地方 };
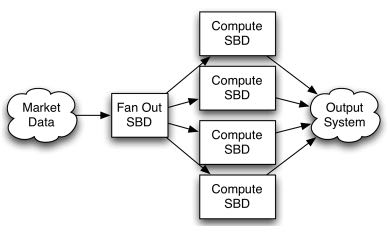
我们可以在一台机器上面启动StreamBaseServer进程之后,就会在启动各个机器上面的Container实例运行,然后每个container就会得到输入,然后交给container本身的application进行处理,然后输出。各个container之间可能相互连接,形成一个计算流图。如果这个过程难以理解的话,那么可以参考下面这个图 http://streambase.com/developers/docs/latest/admin/container-overview.html#container-overview_intro
3. Application
这里所谓的Application就是一个Process Entity.在StreamBase里面Application分为三类:
- operator.
- function.
- client.
这三者没有本质的区别,都是java编写生成的.class文件,但是编写三者继承的类不同,最终表现方式不同。operator可以直接添加到StreamBase作为operator组件存在,而function可以在类SQL里面作为一个function存在,这两者都必须放在container下面才可以运行。而client application就只能够作为单个application存在。对于这类application不需要放在container下面运行,这个可以单独运行。我们后面会提到operator,function和client细微差别。
3.1. client
仔细看看client是如何实现的。StreamBase提供了编写一个client的基类,我们只需要实现里面特定的方法即可。具体编写方法可以参考这里 http://streambase.com/developers/docs/latest/apiguide/clientwizd.html
编写大致可以分为这么几个步骤:
- 使用uri初始化某个client.这样既可以从这个client dequeue读出数据,也可以enqueue传输数据。
- 然后起单独线程从client读取一个一个tuple,然后交给某个函数处理 // processTuple(dr.getStreamProperties(), tuples.next());
- 处理完成之后我们可以塞给client,让client发出去。
但是我们注意到对于一个client完全可以绑定到多个uri从中读取数据,然后最终界面只有processTuple.为了在处理tuple能够进行区分的话,所以可以认为每一个tuple里面实际上都标记了自己从哪一个container出来的,这也就是为什么processTuple第一个参数是stream property.在深层考虑的话并且阅读property所带的内容(http://streambase.com/developers/docs/latest/apidocs/java/index.html)并没有时间戳这个字段,所以可以猜测,StreamBase的time model是一个stream only的,即tuple先被递送那么先处理。
最后有必要说一下tuple的schema是怎么样的。对于tuple本身schema是不定的,可以认为是一个json表示。对于上下游之间传输的话,并没有交换schema这么一个过程,而是上下游的schema之前都已经配置好了。怎么说呢?个人觉得流式系统本身就是各个部件之间紧密耦合的,也不需要考虑上下游升级不同步的问题,所以约定要schema应该是可以接受的方案。
3.2. 细微差别
对于client来说的话是一个standalone的app,不需要放在container下面运行,因为内部实际上已经处理了输入和输出,并且仔细阅读生成代码,就是对于client来说的话入口函数就是main了。在main里面我们需要自己编写client,自己进行链接然后读取然后输出。而operator,function不同,这两个类没有main入口,只是关注处理部分而没有关注连接,实际上连接是StreamBase编译器已经帮你做好的部分。并且对于operator,function只允许在一台机器上面,没有和ip/port绑定,它所处的ip/port和自己所在container相关。
4. Container
所谓容器就是一个Application运行的环境。我们重新回头考虑operator和function的编写,对于operator/function编写的话只是关心处理流程,那么container就必须托管连接消息传输等内容,这个部分是由Stream管理的。除此之外container还可以接受外部到来的命令来控制input/output并且可以对application或者是system进行数据统计等信息。从设计角度来看这是一个非常好的设计,用户关心处理外层关心传输和信息监控等,非常好的流式处理系统的框架。container对于部署者来说可以配置在任何机器上面,以StreamBase定义URI来作为定位。
4.1. URI
StreamBase的URI相对来说比较简单而且也很好理解,格式如下:
sb://[host][:port][/container][;user=xxx;password=yyy]
具体文档可以参考这个地方 http://streambase.com/developers/docs/latest/reference/sburi.html
4.2. Stream
一个container可以有多个input stream和一个output stream.但是用户看不见,所以我们只能够从外部表现来分析了。container可以绑定到一个或者是多个URI上面起多份实例来做HA方案。这里我们从功能角度而言的话只考虑container绑定在一个URI上面。一旦绑定到一个URI的话那么output stream也就绑定了。
4.2.1. Adapter
我们必须让流式系统从某个地方接收数据,这样最外层contiainer的话input stream必须接收很多异构源。同理流式系统最终需要输出,那么输出的话可能目的地也是异构的。对于这些源或者是目的地的话可能有下面这些:
- CSV文件
- JDBC
- JMS
- Simulation.StreamBase提供了一个流产生模拟器(Just Input Stream).
- Custom.用户定制
但是不管如何为了处理异构情况就必须做Adapter.
4.2.2. Connection
http://streambase.com/developers/docs/latest/admin/container-jms.html Container和Container之间的话可以通过TCP进行直连来进行传输,对于Stream的话本身会进行缓冲并且定时会发送心跳。但是如果直接使用TCP直连的话那么 会存在丢消息的情况,如果需要确保container之间传输不丢消息的话那么可以连接上JMS(Java Message Service),这个东西类似于BigPipe.
4.3. System Container
http://streambase.com/developers/docs/latest/admin/container-overview.html#container-overview_system
对于每一个StreamBase Server上面都会存在一个Sytsem Container,主要是产生关于系统信息的流式数据。对于System Container主要包括下面几类:
- error // Emits a tuple containing each StreamBase Server runtime error, if any.
- control // Emits messages from this StreamBase Server in response to certain system-level events.
- statv2 // Emits tuples containing StreamBase monitoring statistics about the running server.
- connections // Emits a tuple every time a client connects to or disconnects from this server.
- subscriptions // Emits a tuple every time a client subscribes to or unsubscribes from any stream on this server.
我们没有必要关心里面具体包含什么信息,提供这些信息之后我们能够很好地对系统进行监控,这点应该是System Container给我们最大的启发。
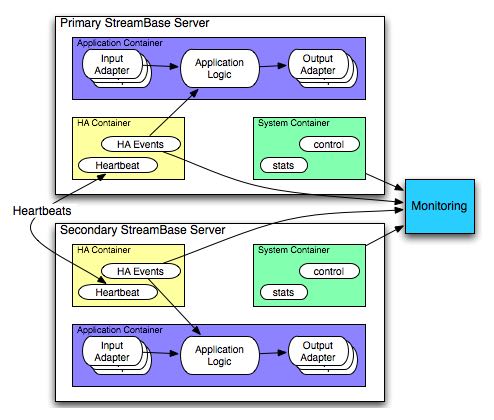
4.4. HA Container
http://streambase.com/developers/docs/latest/admin/ha-designing.html#d0e13346
可以看出HA Container实际包含了两个部分:
- Heartbeat
- HA Events
其中HeartBeat也是Tuple在container之间传输的 http://streambase.com/developers/docs/latest/adaptersguide/embeddedInputHAHeartbeat.html 在HA方案下面的话可以监控primary server的活动情况,然后将这些信息转换成为HA Events交给StreamBase Monitor来处理。
4.5. Monitor
http://streambase.com/developers/docs/latest/admin/ha-overview.html#ha-overview_useeventprocessing
Monitor完成的工作非常简单,就是从System Container和HA Container中获取数据并且进行处理。StreamBase将HA Problem认为应该使用CEP的方式来处理,就是说每一个部件如果出现问题的话那么一定可以反映在System Container和HA Container的输出流上面,然后monitor通过复杂事件处理这些tuple的话就能够检测到机器故障等问题,并且做相应处理。具体这里相应处理是通知administrator还是就有自动策略的话,这个并没有仔细研究过。
5. QueryTable
http://streambase.com/developers/docs/latest/authoring/querytab-overview.html
QueryTable可以用来存储接收到的tuple并且允许在多个container之间进行共享,但是不允许在API层面进行用户自定义的用途。QueryTable提供了增量流这个功能(delta stream),可以认为就是BigPipe的功能,但是猜想这里实现的方式应该是QueryTable自己记录下游已经成功接收到的点,这样可以使得下游使用起来更加方便。对于QueryTable支持内存table和磁盘table,对于磁盘table的话支持三种写模式:
- non-transaction模式。这种模式只是写入但是并不做transaction.
- half-transaction模式。这种模式保证transaction,但是对于flush的时机并不确定
- full-transaction模式。这种模式保证transaction,并且强制每次flush.
个人觉得如果仅仅就StreamBase内部来使用的话,完全可以代替JMS.但是如果外部程序还想进行二次分析的话,连接上JMS应该更加方便。
QueryTable也支持进行Replication. http://streambase.com/developers/docs/latest/authoring/querytab-replication.html 我们阅读一下replication的配置,似乎每一个QueryTable只允许配置一个replication(但是不确定)
<table-replication>
<param name="HB_OTHER_SERVER"
value="name_of_other_server"/>
<param name="REPL_OTHER_SERVER_PORT"
value="12345"/>
<param name="REPL_CHECK_INTERVAL" value="1"/>
<param name="REPL_BATCH_SIZE" value="100"/>
<param name="REPL_RECONNECT_INTERVAL"
value="250"/>
</table-replication>
从replication我们可以看到如果使用querytable来进行replication的话,那么是隔断时间进行检查的,并且一次send batch size个数的tuple到replicas上面。可以这个同步并不具有一致性的。
6. Clustering
使用StreamBase开发的应用程序本身就是通过连接StreamBase提供的组件并且进行配置来完成的,相对于编写代码来说的话有局限性。但是StreamBase提出了很多基于这种开发衍生的很多模式用来构建cluster.实现cluster主要目的包括下面这些:
- High Availability. a server cluster can be used to maximize the uptime of the processing engine.
- Fault Tolerance. A server cluster can provide an available backup server to take over in the event of certain hardware or software failures on the primary server.
- Disaster Recovery. Server cluster technologies can be used to provide a hot or warm offsite backup for a critical event processing engine.
- Scalability. Clustering technologies can be used to add processing power to an event processing engine by adding servers that share the load.
6.1. Fault Tolerance
对于出错容忍的话,StreamBase提出了下面4模板策略解决方案。 http://streambase.com/developers/docs/latest/admin/ha-overview.html#ha-overview_templates
6.1.1. Hot-Hot Server Pair Template
这种方式的话primary和secondary server都在同时进行计算,并且将计算结果交给下游。优点是primary server如果失败的话那么secondary server依然能够工作,几乎没有任何切换时间。并且下游的话只需要选取首先到来的tuple就可以处理了,可以保证处理速度最快。缺点就是浪费计算和网络资源。
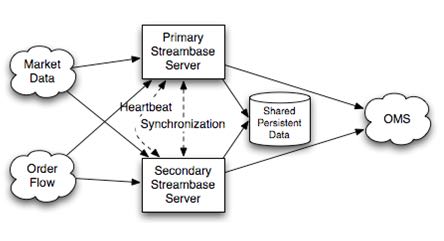
6.1.2. Hot-Warm Server Pair Template
这种方式的话primary和secondary server都在同时计算,但是只有primary server将计算结果交给下游。优点是primary server如果失败的话,那么secondary server可以很快地就切换上来而不需要任何恢复状态工作,但是相对于Hot-Hot方式时间稍微长一些,但是没有Hot-Hot那么耗费网络资源,但是也浪费了计算资源。
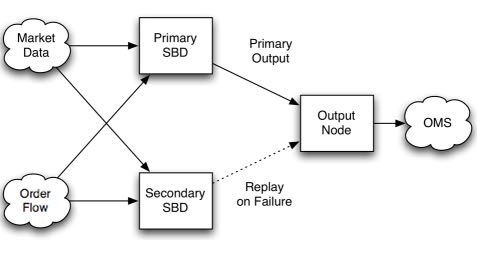
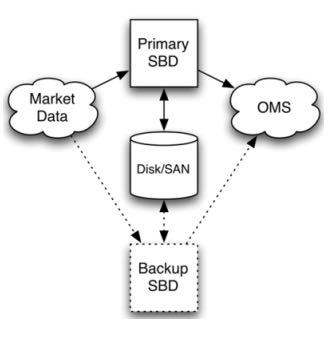
6.1.3. Shared Disk Template
这种方式的话primary server在计算之后,将计算的一些中间关键状态存储到磁盘或者是SAN(Storage Area Network)或者认为是一个可靠的存储介质上面。如果primary server failover的话,那么secondary server会从介质中读取出关键状态然后接着进行计算。优点是没有浪费任何计算和网路资源,但是恢复时间的话依据状态多少而定,相对于前面两种的话恢复时间可能会稍长。
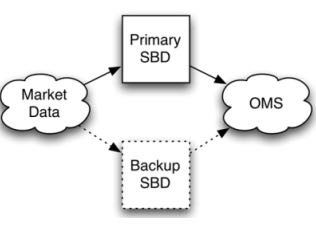
6.1.4. Fast Restart Template
最后一种限定了应用场景,就是stateless或者是near stateless的application.对于无状态的话那么我们方案可以非常简单,只要primary server failover的话,那么secondary server立即启动并且接上上面的流进行计算即可。因为无状态,所以我们可以这么做。
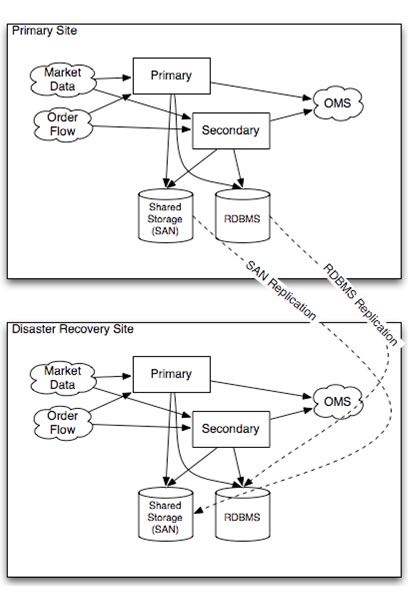
6.2. Disaster Recovery
To implement a disaster recover scenario, an offsite implementation can combine the hot-warm and shared disk templates. The disaster recovery site would run an identical deployment, with shared storage implemented over a network connection using either SAN or relational database storage. http://streambase.com/developers/docs/latest/admin/ha-overview.html#ha-overview_disasterrecovery
6.3. Scalability
You can use clustering techniques to implement scaling of your StreamBase Server implementation from one to multiple servers. With planning, the same parallel code and data techniques allow you to add new servers to a stream processing cluster to meet higher load demands. http://streambase.com/developers/docs/latest/admin/ha-overview.html#ha-overview_scalability