SRE Google运维解密(SRE: How Google Runs Production Systems)
Table of Contents
https://book.douban.com/subject/26875239/
1. 第2章 Google生产环境
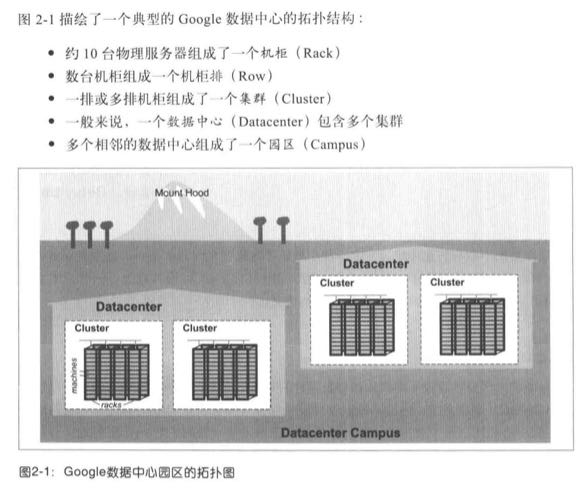
下图描绘了一个典型的Google数据中心的拓扑结构。
- 约10台物理服务器组成了一个机柜(rack)
- 数台机柜组成一个机柜台(row)
- 一排或多排机柜组成一个集群(cluster)
- 一般来说,一个数据中心(datacenter)包含多个集群
- 多个相邻的数据中心组成了一个园区(campus)
每个数据中心内的物理服务器都需要能够互相进行网络通信。为了解决这个问题,我们用几百台Google自己制造的交换机以clos连接方式连接起来,创建了一个非常快的虚拟网络交换机,这个交换机有几万个虚拟端口。这个交换机的名字叫Jupiter。在Google最大的一个数据中心内,Jupiter可以提供1.3PB/s的交叉带宽。
Google的数据中心是由一套全球覆盖的骨干网B4连接起来的,B4是基于SDN网络技术(使用OpenFlow标准协议)构建的,可以给中型规模的骨干网络提供海量带宽,同时可以利用动态带宽管理优化网络连接,最大化平均带宽。
2. 第7章 Google的自动化系统的演进
可靠性是最基本的功能
当然为了有效的进行故障调试,自我检查中所依赖的内部运作细节也应该暴露给管理整体系统的操作员。在非计算机领域对自动化影响的类似讨论,例如民航或工业应用中,经常会指出高效的自动化的缺点。随着时间的推移,操作员与系统的有用的直接接触会减少,因为自动化会覆盖越来越多的日常活动。不可避免的,当自动化系统出现问题时,操作员将无法成功的操作该系统。
由于缺乏实践,他们已经丧失了反应的流畅性,他们有关系统“应该”做什么的心理模型不再反映现实中系统“正在进行”的活动。这种情况在系统非自主运行时出现的更多,即,当自动化逐渐取代了手动操作,假设其他的手工操作仍然可能执行,并且如之前一样一直可用。令人难过的事,随着时间的推移,这个假设终将不再正确:这些手动操作最后将无法执行,因为允许它们执行的功能已经不存在。
Google也经历过自动化在某些条件下是有害的情况。参看下面“自动化允许大规模故障发生”的补充材料。但是以Google的经验来看,在更多的系统中自动化和自主化的行为不再是可选的附加项。随着服务规模扩大,肯定是这样的,但是不论系统规模大小,系统中具有更多自主行为的系统,仍然有很多好处。可靠性是最基本的功能,并且自主性和弹性行为是达到这一特征的有效途径。
3. 第21章 应对过载
QPS陷阱
不同的请求可能需要数量迥异的资源来处理。某个请求的成本可能由各种各样的因素决定,例如客户端的代码不同(有的服务有很多种客户端实现),或者甚至是当时的现实时间(家庭用户和企业用户,交互请求和批量请求)。
如果在多年的经验积累中得出:按照QPS来规划服务容量,或者是按照某种静态属性(认为其能指代处理所消耗的资源:例如某个请求所需要读取key-value数量)一般是错误的选择。就算这个指标在某一个时间段内看起来工作还算良好,早晚也会发生变化。有些变动是逐渐发生的,有些则是非常突然的(例如某个软件的新版本突然使得某些请求消耗的资源大幅减少)。这种不断变动的目标,使得设计和实现良好的负载均衡策略使用起来非常困难。
更好的解决方案是直接用以可用资源来衡量可用容量。例如某个服务可能在某个数据中心预留了500CPU内核和1TB内存用以提供服务,用这些数字来建模该数据中心的服务容量是非常合理的。我们经常将某个请求的“成本”定义为,该请求在正常情况下所消耗的CPU时间(这里要考虑到不同的CPU类型的性能差异问题)。
在绝大部分情况下,我们发现简单的使用CPU数量作为资源配给的主要信号就可以工作得很好,原因如下:
- 在有垃圾回收GC机制的编程环境,内存的压力通常自然而然地变成CPU的压力。在内存受限的情况下,GC会增加。
- 在其他编程环境里,其他资源一般可通过某种比例进行配置,以便这些资源的短缺情况非常罕见。
如果过量分配其他非CPU资源不可行的话,我们可以在计算资源消耗的时候,将各种系统资源分别考虑在内。
4. 第23章 管理关键状态:利用分布式共识来提高可靠性
同时对开发者来说,仅仅针对支持BASE的数据存储来设计应用程序是很困难的。例如Jeff Shute在《F1: A Distributed SQL Database That Scales》曾经说过:“我们发现开发者通常花费了大量的时间,构建一个极为复杂和容易出错的机制,来应对最终一致性下可能过时的数据。我们认为对开发者来说这是一种无法接受的负担,数据一致性的问题应该在数据库的解决。”
当决定在哪里放置共识组的副本时,另一个重要因素是要考虑地理位置的分布,或者更准确的说,副本直接的网络延迟,对性能的影响。一个做法是将副本分布得最均匀化,使得副本之间的RTT基本相似。在其他因素都相同的情况下,这种分布应该会在各个地区都形成相对固定的系统性能,不管该组的领头人被放在了何处。
地理位置的分布可能会给这种做法造成一定难处,尤其是当跨大陆与跨大西洋和跨太平洋的流量对比的时候。如果考虑跨越北美洲和欧洲部署的某个系统:试图平均分布副本是不可能的,系统中永远会有一段延迟高的链路,因为跨大西洋的路要比跨大洲的链路速度慢。无论如何在某个区域中的操作,都要跨越大西洋进行一次共识操作。
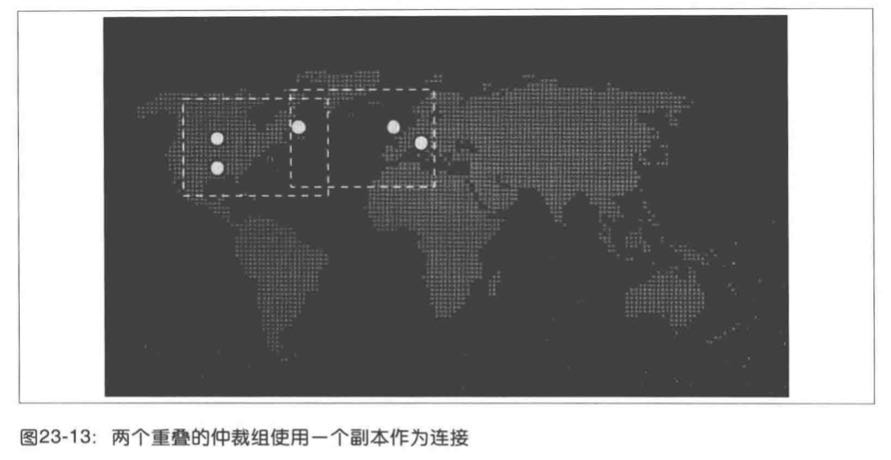
然而如下图所示,为了将系统流量分布得更均匀,系统设计者可以考虑采用5个副本,将其中两个副本放置于美国中心地带,一个放置于东海岸,另外两个放置于欧洲。这样分布可基本保证共识过程中,在北美洲副本上完成,而不需要等待欧洲的回复。而从欧洲起始的共识过程,可以仅仅跟美国东海岸的副本完成。东海岸的副本就像两个可能的仲裁局的关键,将两个组连接在一起。
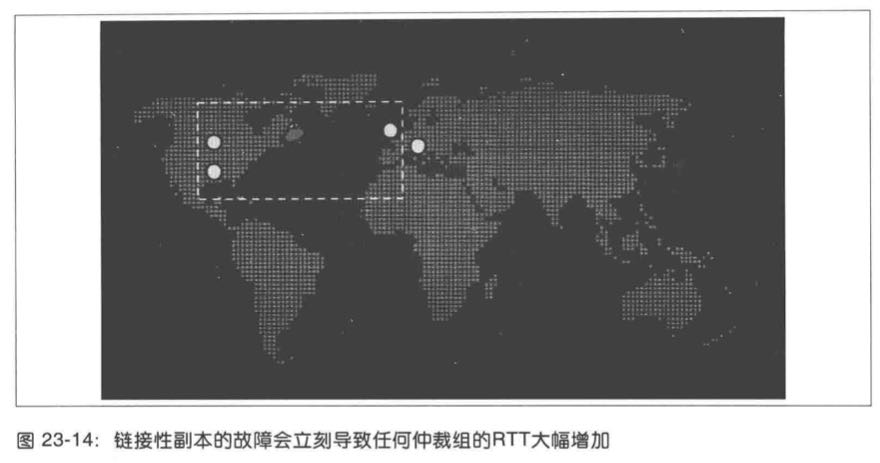
如下图所示,该副本的故障可能会导致系统延迟大幅改变。以前系统主要是受美国中部到东部的RTT影响,或者欧洲到东海岸的RTT影响,现在则会成为受欧洲到美国中部的RTT影响,也就是比之前有50%的增加。这种情况下,距离最近的中仲裁组的物理距离和网络延迟都会受到很大影响。
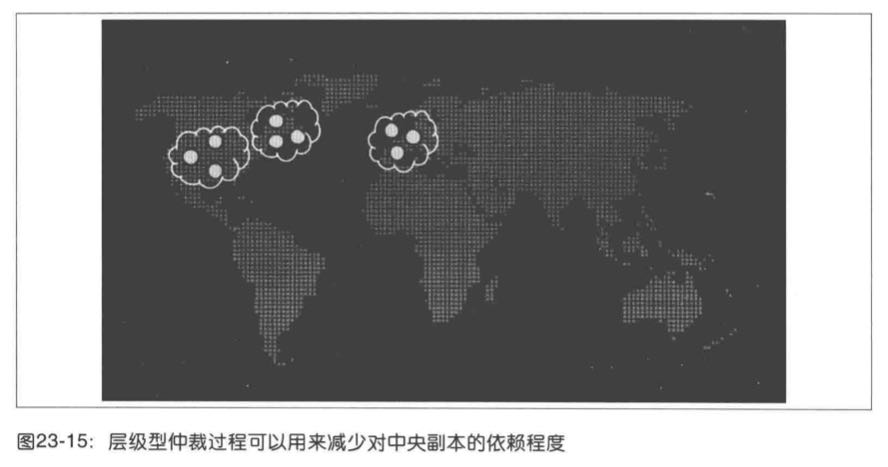
这种情况是简单多数型仲裁过程,在成员RTT非常不同的时候的一个关键弱点。这种情况下,层级型的仲裁过程可能更为有用。如下图所示,9个副本可能会被部署为三组,每组三个,仲裁过程可以由多数组完成,而每个组只有在多数成员可用的情况下才可用。这意味着一个副本可以在中央组中出现故障,而不会对系统整体性能产生影响,因为中央组织有两个可用副本仍可以参与仲裁。
5. 第26章 数据完整性:读写一致
安排一些开发者来开发一套数据校验流水线,可能会在短期内降低业务功能开发的速度,然而在数据校验方面投入的工程资源,可以在更长时间内保障其他业务开发可以进行得更快。因为工程师可以放心数据损坏的bug没那么容易流入生产环节。和在项目早期引入单元测试效果类似,数据校验流水线可以在整个软件开发过程中起到加速作用。
带外数据校验比较难以正确实验。当校验规则太严格的时候,一个简单的合理的修改就会触发校验逻辑而失败,这样一来工程师就会抛弃数据校验的逻辑。如果规则不够严格,那么就可能漏过一些数据可见问题。为了在两者之间取得恰当的平衡,我们应该仅仅校验那些对用户来说具有毁灭性的数据问题。
大规模部署带外检测器成本较高。Gmail计算资源的很大一部分都会用来支持每日数据检测的运行。使这个问题变得更加严重的是,本身可能会造成软件服务器缓存命中率的下降,这就会造成用户可见响应速度的下降。为了避免这种问题,Gmail提供了一系列针对校验器的限速机制,同时定期重构这些校验器,以降低磁盘压力。在某一次重构工作,我们降低了60%磁盘磁头的使用率,同时没有显著降低校验器覆盖的范围。虽然大部分Gmail检测器每天运行一次,但是压力最大的校验器被分为10~14个分片,每天只运行一个分片。