Sparser: Raw Filtering for Faster Analytics over Raw Data
1. Paper
这个项目大致想法就是在正式解析数据之前,先使用代价比较小的filter去进行筛选(scan and search),并且可能会使用多个filters进行组合筛选,希望经过筛选之后的数据是highly selective的。 当然经过筛选之后的数据可能会出现false positive, 这时再使用full parser去解析,但是需要解析的数量已经大幅减少了,所以有很高的效率。
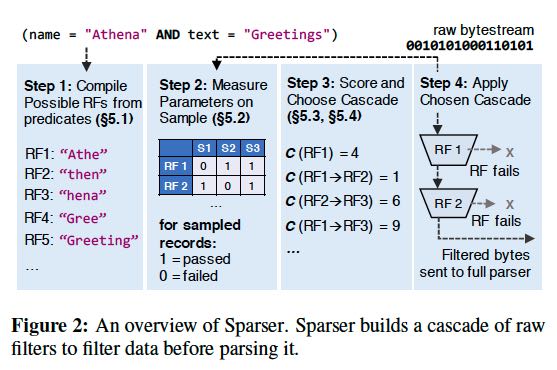
Because the best RF cascade is datadependent, we propose an optimizer that dynamically selects the combination of RFs with the best expected throughput, achieving within 10% of the global optimum cascade while adding less than 1.2% overhead. We implement these techniques in a system called Sparser, which automatically manages a parsing cascade given a data stream in a supported format (e.g., JSON, Avro, Parquet) and a user query. We show that many real-world applications are highly selective and benefit from Sparser. Across diverse workloads, Sparser accelerates state-of-the-art parsers such as Mison by up to 22X and improves end-to-end application performance by up to 9X.
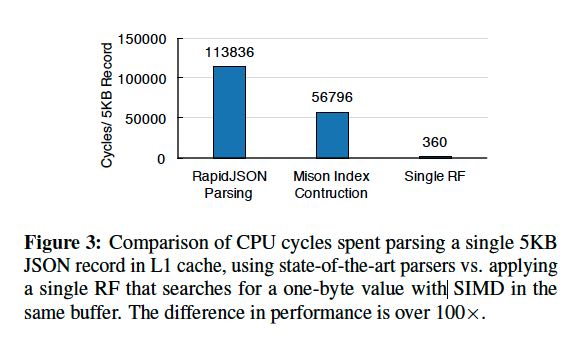
One such example is the Mison JSON parser, which uses SIMD instructions to find special characters such as brackets and colons to build a structural index over a raw JSON string, enabling efficient field projection without deserializing the record completely. This approach delivers substantial speedups: we found that Mison can parse highly nested in-memory data at over 2GB/s per core, over 5X faster than RapidJSON [49], the fastest traditional state-machine-based parser available [32]. Even with these new techniques, however, we still observe a large memory-compute performance gap: a single core can scan a raw bytestream of JSON data 10X faster than Mison parses it. Perhaps surprisingly, similar gaps can even occur when parsing binary formats that require byte-level processing, such as Avro and Parquet. (Milson使用SIMD指令来加速json parser, 可以达到每个core处理到2GB/s,是RapidJSON的5倍。但是即便如此,Milson和单纯的scan相比,依然相差很多)
Sparser occasionally recalibrates its cascade to account for data skew or sorting in the underlying input file. §7 shows that recalibration is important for minimizing parsing runtime over the entire input, because a cascade chosen at the beginning of the dataset may not be effective at the end. For instance, consider an RF that filters on a particular date, and the underlying input records are also sorted by date. The RF may be highly ineffective for one range of the file (e.g., the range of records that all match the given date in the filter) and very effective for other ranges. To address this issue, Sparser maintains an exponentially weighted moving average of its own parsing throughput. In our implementation, we update this average on every 100MB block of input data. If the average throughput deviates significantly (e.g., 20% in our implementation), Sparser reruns its optimizer algorithm to select a new RF cascade. (对每100MB block计算一下throughput, 然后使用EWMA来做修正。如果发现偏离太远的话,那么会重新挑选新的RFs层次)
2. Code
@201809
demo_repl 给出的例子是使用如下SQL
SELECT count(*)\n\ FROM tweets\n\ WHERE text contains \"Trump\" AND text contains \"Putin\"";
对应地这个SQL会有两个关键字符串在filter时候会用到
static const char **sparser_demo_query1(int *count) { static const char *_1 = "Trump"; static const char *_2 = "Putin"; static const char *predicates[] = {_1, _2, NULL}; *count = 2; return predicates; }
但是如果仅仅是使用关键字符串去scan的话,如果字符串很长那么开销依然很大,所以考虑是否可以只scan关键字符串的substring, 这些substring不能太长。 长度的话最好可以使用SIMD,所以类似长度为4/8/16字节比较好。所有可能的substring加上关键字符串都变成了rawfilters, 然后我们在从这些rawfilters中挑出最好的组合。
// The length of produced substrings. #define REGSZ 4 typedef struct ascii_rawfilters { // The ascii_rawfilters strings. Each pointer points into region. const char **strings; // The source of the string. const int *sources; const int *lens; // Region where strings are allocated. char *region; // Number of strings created. int num_strings; } ascii_rawfilters_t; // Decomposes each string into substrings of length REGSZ or less as search // tokens. NOTE(yan): trump -> trump, trum, rump ascii_rawfilters_t decompose(const char **predicates, int num_predicates) { int num_ascii_rawfilters = 0; int region_bytes = 0; for (int i = 0; i < num_predicates; i++) { int len = (int)strlen(predicates[i]); // How many REGSZ-length substrings are possible from this string? int possible_substrings = len - REGSZ > 0 ? len - REGSZ + 1 : 1; // Include the full string in the count. num_ascii_rawfilters += possible_substrings + 1; region_bytes += (possible_substrings * 5); } const char **result = (const char **)malloc(sizeof(char *) * num_ascii_rawfilters); int *sources = (int *)malloc(sizeof(int) * num_ascii_rawfilters); int *lens = (int *)malloc(sizeof(int) * num_ascii_rawfilters); char *region = (char *)malloc(sizeof(char) * region_bytes); // index into result. int i = 0; // pointer into region. char *region_ptr = region; for (int j = 0; j < num_predicates; j++) { // Add the first string. result[i] = predicates[j]; lens[i] = strlen(predicates[j]); sources[i] = j; i++; int pred_length = strlen(predicates[j]); for (int start = 0; start <= pred_length - REGSZ; start++) { if (pred_length == REGSZ && start == 0) continue; memcpy(region_ptr, predicates[j] + start, REGSZ); region_ptr[REGSZ] = '\0'; printf("add region: %s, predication #%d\n", region_ptr, j); result[i] = region_ptr; sources[i] = j; lens[i] = REGSZ; region_ptr += 5; i++; } } ascii_rawfilters_t d; d.strings = result; d.sources = sources; d.lens = lens; d.region = region; d.num_strings = i; return d; }
接下来要考虑的是如何评估每个rawfilter的开销,最好的办法就是在真实数据集合上跑一把。不仅仅需要评估rawfilter的开销,还要考虑full parser的开销,以便后面挑选最优组合。 这个函数叫做 `sparser_calibrate`. 代码有点长,但是还算是清晰易懂
- MAX_SAMPLES=1000 评估rawfilter的样本数量
- MAX_SUBSTRINGS=32 只选择前面32个substrings/rawfilters进行评估
- PARSER_MEASUREMENT_SAMPLES=10 评估fullparser的样本数量
- passthrough_masks 每个rawfilter匹配到了那些sample records, 这个在挑选最优组合时有用
- calibrate_timing
- sampling_total. 前期sampling花费时间,包括RF grepping的的时间
- grepping_total. 使用rawfilters做grepping花费时间
- cycles_per_parse_avg 执行full parser的平均CPU cycles
- searching_total. 挑选最优组合所花费时间
- cycles_per_schedule_avg 挑选最优组合花费的平均CPU cycles
- processed/skipped. 评估最优组合的数量
- total 执行calibrate的时间
/** Returns a search query given a sample input and a set of predicates. The * returned search query * attempts to jointly minimize the search time and false positive rate. * * @param sample the sample to test. * @param length the length of the sample. * @param predicates a set of full predicates. * @param count the number of predicates to test. * @param callback the callback, which specifies whether a query passes. * * @return a search query, or NULL if an error occurred. The returned query * should be returned with free(). */ sparser_query_t *sparser_calibrate(BYTE *sample, long length, BYTE delimiter, ascii_rawfilters_t *predicates, sparser_callback_t callback, void *callback_arg) { struct calibrate_timing timing; memset(&timing, 0, sizeof(timing)); bench_timer_t start_e2e = time_start(); // Stores false positive mask for each predicate. // Bit `i` is set if the ith false positive record was *passed* by the // predicate. bitmap_t passthrough_masks[MAX_SUBSTRINGS]; for (int i = 0; i < MAX_SUBSTRINGS; i++) { passthrough_masks[i] = bitmap_new(MAX_SAMPLES); } // The number of substrings to process. int num_substrings = predicates->num_strings > MAX_SUBSTRINGS ? MAX_SUBSTRINGS : predicates->num_strings; // Counts number of records processed thus far. long records = 0; long parsed_records = 0; long passed = 0; unsigned long parse_cost = 0; bench_timer_t start = time_start(); // Now search for each substring in up to MAX_SAMPLES records. char *line, *newline; size_t remaining_length = length; while (records < MAX_SAMPLES && (newline = (char *)memchr(sample, delimiter, remaining_length)) != NULL) { // Emulates behavior of strsep, but uses memchr's faster implementation. line = sample; sample = newline + 1; remaining_length -= (sample - line); bench_timer_t grep_timer = time_start(); // NOTE(yan): 使用各种substring去尝试匹配每行原始字符串,记录匹配到哪些记录 for (int i = 0; i < num_substrings; i++) { const char *predicate = predicates->strings[i]; SPARSER_DBG("grepping for %s...", predicate); if (memmem(line, newline - line, predicate, predicates->lens[i])) { // Set this record to found for this substring. bitmap_set(&passthrough_masks[i], records); SPARSER_DBG("found!\n"); } else { SPARSER_DBG("not found.\n"); } } double grep_time = time_stop(grep_timer); timing.grepping_total += grep_time; // To estimate the full parser's cost. // NOTE(yan): 前面一部分的records进行完全解析 if (records < PARSER_MEASUREMENT_SAMPLES) { unsigned long start = rdtsc(); // NOTE(yan): callback是完全解析. // 如果substring匹配的话,尝试去完全解析 passed += callback(line, callback_arg); unsigned long end = rdtsc(); parse_cost += (end - start); parsed_records++; } records++; timing.cycles_per_parse_avg = parse_cost; // NOTE(yan): 总体parse时间 } timing.sampling_total = time_stop(start); start = time_start(); SPARSER_DBG("%lu passed\n", passed); // The average parse cost. parse_cost = parse_cost / parsed_records; search_data_t sd; memset(&sd, 0, sizeof(sd)); sd.num_records = records; sd.passthrough_masks = passthrough_masks; sd.full_parse_cost = parse_cost; sd.best_cost = 0xffffffff; sd.joint = bitmap_new(MAX_SAMPLES); // temp buffer to store the result. int result[MAX_SCHEDULE_SIZE]; // Get the best schedule. // NOTE(yan): 枚举length = i的最佳开销 for (int i = 1; i <= MAX_SCHEDULE_SIZE; i++) { search_schedules(predicates, &sd, i, 0, result, i); } timing.searching_total = time_stop(start); timing.cycles_per_schedule_avg = sd.total_cycles / sd.processed; timing.processed = sd.processed; timing.skipped = sd.skipped; static char printer[4096]; printer[0] = 0; for (int i = 0; i < sd.schedule_len; i++) { strcat(printer, predicates->strings[sd.best_schedule[i]]); strcat(printer, " "); } SPARSER_DBG("Best schedule: %s\n", printer); // NOTE(yan): 为sparser_query_t 添加 best_scheduler信息 sparser_query_t *squery = sparser_new_query(); memset(squery, 0, sizeof(sparser_query_t)); for (int i = 0; i < sd.schedule_len; i++) { sparser_add_query(squery, predicates->strings[sd.best_schedule[i]], predicates->lens[sd.best_schedule[i]]); } for (int i = 0; i < MAX_SUBSTRINGS; i++) { bitmap_free(&passthrough_masks[i]); } timing.total = time_stop(start_e2e); print_timing(&timing); bitmap_free(&sd.joint); return squery; }
在 `calibrate` 函数里面还有个 `search_schedules` 的函数,就是要找出rawfilters的最佳组合,通过枚举的方式来找到最佳组合。 这里面最重要的逻辑就是评估rawfilters组合的cost. 在寻找rawfilters组合的时候,还考虑了这些RFs的顺序,因为不同的顺序带来scan 的开销是不同的。一个RF的开销很简单,就是 `8.0 * len`.
/** Cost in CPU cycles of a raw filter which searches for a term of length * `len`. */ double rf_cost(const size_t len) { return len * 8.0; } // search_schedules. // NOTE(yan): 模拟每一个filter带来的开销 int first_index = result[0]; bitmap_t *joint = &sd->joint; bitmap_copy(joint, &sd->passthrough_masks[first_index]); // First filter runs unconditionally. double total_cost = rf_cost(predicates->lens[first_index]); for (int i = 1; i < result_len; i++) { int index = result[i]; uint64_t joint_rate = bitmap_count(joint); double filter_cost = rf_cost(predicates->lens[index]); double rate = ((double)joint_rate) / sd->num_records; SPARSER_DBG("\t Rate after %s: %f\n", predicates->strings[result[i - 1]], rate); total_cost += filter_cost * rate; bitmap_and(joint, joint, &sd->passthrough_masks[index]); } // NOTE(yan): 模拟full parser带来的开销 // Account for full parser. uint64_t joint_rate = bitmap_count(joint); double filter_cost = sd->full_parse_cost; double rate = ((double)joint_rate) / sd->num_records; SPARSER_DBG("\t Rate after %s (rate of full parse): %f\n", predicates->strings[result[result_len - 1]], rate); total_cost += filter_cost * rate; SPARSER_DBG("\tCost: %f\n", total_cost); if (total_cost < sd->best_cost) { assert(result_len <= MAX_SCHEDULE_SIZE); memcpy(sd->best_schedule, result, sizeof(int) * result_len); sd->schedule_len = result_len; } long end = rdtsc(); sd->processed++; sd->total_cycles += end - start;