Spark SQL: Relational Data Processing in Spark
这个东西在Spark的生态中特别有用,尤其是在ML领域。读下来的感觉就是,这个东西的亮点主要是在接口设计上,计算实现则完全依赖于Spark计算引擎:
- 不像常见的OLAP提供的SQL界面,Spark SQL的界面是DataFrame API,这个东西在ML领域非常常见。
- SQL/Query优化引擎叫做Catalyst,它的特点就是非常地Extensible,允许用户编写带来来扩展数据源(data sources),优化规则(optimizations),以及数据类型(data types)
下面4点是Spark SQL的设计目标:
- Support relational processing both within Spark programs (on native RDDs) and on external data sources using a programmer- friendly API.
- Provide high performance using established DBMS techniques.
- Easily support new data sources, including semi-structured data and external databases amenable to query federation.
- Enable extension with advanced analytics algorithms such as graph processing and machine learning.
Spark SQL 在 Spark ecosystem中占据的位置:强化Spark作为底层执行引擎,而Spark SQL作为用户界面

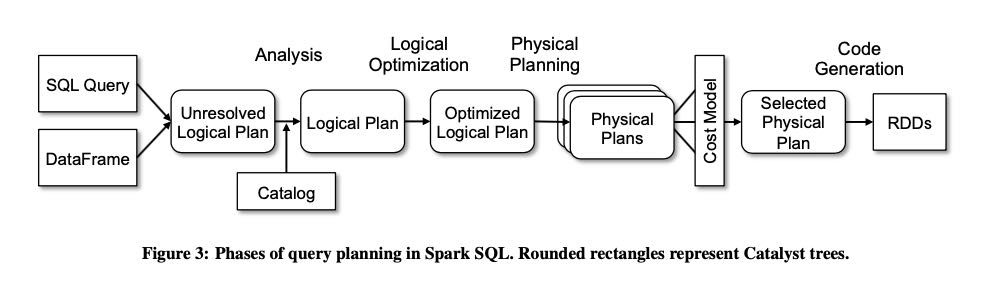
下图是Spark SQL的的执行过程,catalyst optimizers是里面所有圆形边角的长方形区域:
- logical optimization 主要靠pattern matching 对tree进行rule-based rewrite
- physical planning 将logical plan使用spark operator改写成为physical plan
- phyiscal optimization 则包含将projection以及filter尽可能地push down以及pipeline, 这是rule-based optimization. 而在选择join算法上使用cost-based optimization.
- 因为这个东西是JVM编写的,所以使用了一个叫做 `quasiquotes` 的库动态生成JVM code,就是code generation部分
- 现阶段用户的扩展点主要是在data source以及user-defined types上。扩展data source告诉catalyst如何scan, PrunedScan(选择特定columns), 以及PrunedFilteredScan(选择特定columns以及filter objects).