Spark: Cluster Computing with Working Sets
Table of Contents
https://www.usenix.org/legacy/events/hotcloud10/tech/full_papers/Zaharia.pdf @ 2010
1. Abstract
主要针对两类计算:迭代计算和交互分析,而这些都是针对批处理设计出来的系统的软肋。
- MapReduce and its variants have been highly successful in implementing large-scale data-intensive applications on commodity clusters. However, most of these systems are built around an acyclic data flow model that is not suitable for other popular applications. This paper fo- cuses on one such class of applications: those that reuse a working set of data across multiple parallel operations. This includes many iterative machine learning algorithms, as well as interactive data analysis tools.(迭代计算和交互式分析)
- We propose a new framework called Spark that supports these applica- tions while retaining the scalability and fault tolerance of MapReduce. To achieve these goals, Spark introduces an abstraction called resilient distributed datasets (RDDs). An RDD is a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.(RDD是一个只读对象的集合,并且会被分割成为多个partition,分布在多个机器上。如果一个partition丢失的话可以重算这个partition)
- Spark can outperform Hadoop by 10x in iterative machine learning jobs, and can be used to interactively query a 39 GB dataset with sub-second response time.
2. Introduction
In this paper, we focus on one such class of applications: those that reuse a working set of data across multiple parallel operations. This includes two use cases where we have seen Hadoop users report that MapReduce is deficient:
- Iterative jobs: Many common machine learning algo- rithms apply a function repeatedly to the same dataset to optimize a parameter (e.g., through gradient de- scent). While each iteration can be expressed as a MapReduce/Dryad job, each job must reload the data from disk, incurring a significant performance penalty.
- Interactive analytics: Hadoop is often used to run ad-hoc exploratory queries on large datasets, through SQL interfaces such as Pig and Hive. Ideally, a user would be able to load a dataset of interest into memory across a number of machines and query it re- peatedly. However, with Hadoop, each query incurs significant latency (tens of seconds) because it runs as a separate MapReduce job and reads data from disk.
The main abstraction in Spark is that of a resilient dis- tributed dataset (RDD), which represents a read-only col- lection of objects partitioned across a set of machines that can be rebuilt if a partition is lost. Users can explicitly cache an RDD in memory across machines and reuse it in multiple MapReduce-like parallel operations. (RDD可以存储在内存中,并且可以重复使用)
RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough infor- mation about how it was derived from other RDDs to be able to rebuild just that partition.(RDD通过lineage来达到fault-tolerant. 一个RDD内部包含足够信息来重新构造自己。因为RDD是只读的,所以这个信息只需要是input + sequence of transformatios)
Although RDDs are not a general shared memory abstraction, they represent a sweet-spot between expressivity on the one hand and scalability and reliability on the other hand, and we have found them well-suited for a variety of applications.
3. Programming Model
3.1. Resilient Distributed Datasets (RDDs)
A resilient distributed dataset (RDD) is a read-only col- lection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
The elements of an RDD need not exist in physical storage; instead, a handle to an RDD contains enough information to compute the RDD starting from data in reliable storage. This means that RDDs can always be reconstructed if nodes fail.(每个RDD包含如何从data in reliable storage经过一系列变化转换过来)
In Spark, each RDD is represented by a Scala object. Spark lets programmers construct RDDs in four ways:(RDD能够通过下面4种方式来构造)
- From a file in a shared file system, such as the Hadoop Distributed File System (HDFS).(从HDFS中读取)
- By “parallelizing” a Scala collection (e.g., an array) in the driver program, which means dividing it into a number of slices that will be sent to multiple nodes.(将driver中的collection切片)
- By transforming an existing RDD. A dataset with ele- ments of type A can be transformed into a dataset with elements of type B using an operation called flatMap, which passes each element through a user-provided function of type A ⇒ List[B]. Other transforma- tions can be expressed using flatMap, including map (pass elements through a function of type A ⇒ B) and filter (pick elements matching a predicate).(经过transformation)
- By changing the persistence of an existing RDD. By default, RDDs are lazy and ephemeral. That is, par- titions of a dataset are materialized on demand when they are used in a parallel operation (e.g., by passing a block of a file through a map function), and are dis- carded from memory after use. However, a user can alter the persistence of an RDD through two actions:
- The cache action leaves the dataset lazy, but hints that it should be kept in memory after the first time it is computed, because it will be reused. We note that our cache action is only a hint: if there is not enough memory in the cluster to cache all partitions of a dataset, Spark will recompute them when they are used. We chose this design so that Spark programs keep work- ing (at reduced performance) if nodes fail or if a dataset is too big. This idea is loosely analogous to virtual memory.(cache可以用来提示将RDD缓存在内存中,以便被后面计算重复使用。如果空间不够的话那么会丢弃而下次需要的时候重新计算,类似虚拟内存)
- The save action evaluates the dataset and writes it to a distributed filesystem such as HDFS. The saved version is used in future operations on it.(save可以用来将RDD持久化到磁盘上)
We also plan to extend Spark to support other levels of persistence (e.g., in-memory replication across multiple nodes). Our goal is to let users trade off between the cost of storing an RDD, the speed of accessing it, the proba- bility of losing part of it, and the cost of recomputing it.
3.2. Parallel Operations
Several parallel operations can be performed on RDDs:
- reduce: Combines dataset elements using an associa- tive function to produce a result at the driver program.
- collect: Sends all elements of the dataset to the driver program. For example, an easy way to update an array in parallel is to parallelize, map and collect the array.
- foreach: Passes each element through a user provided function. This is only done for the side effects of the function (which might be to copy data to another sys- tem or to update a shared variable as explained below).
We note that Spark does not currently support a grouped reduce operation as in MapReduce; reduce re- sults are only collected at one process (the driver). We plan to support grouped reductions in the future using a “shuffle” transformation on distributed datasets, as de- scribed in Section 7.(没有shuffle是显然不行的)
3.3. Shared Variables
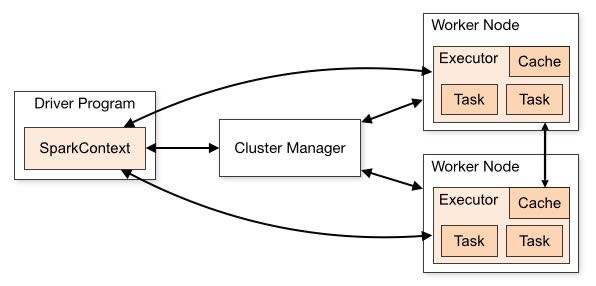
Programmers invoke operations like map, filter and re- duce by passing closures (functions) to Spark. As is typi- cal in functional programming, these closures can refer to variables in the scope where they are created. Normally, when Spark runs a closure on a worker node, these vari- ables are copied to the worker.(closure使用的变量会被复制到worker上)
However, Spark also lets programmers create two restricted types of shared vari- ables to support two simple but common usage patterns:
- Broadcast variables: If a large read-only piece of data (e.g., a lookup table) is used in multiple parallel op- erations, it is preferable to distribute it to the workers only once instead of packaging it with every closure. Spark lets the programmer create a “broadcast vari-able” object that wraps the value and ensures that it is only copied to each worker once.(广播变量,类似Hadoop的distributed cache)
- Accumulators: These are variables that workers can only “add” to using an associative operation, and that only the driver can read. They can be used to im- plement counters as in MapReduce and to provide a more imperative syntax for parallel sums. Accumu- lators can be defined for any type that has an “add” operation and a “zero” value. Due to their “add-only” semantics, they are easy to make fault-tolerant.(累加器,类似Hadoop的counter)
4. Examples
5. Implementation
5.1. RDD
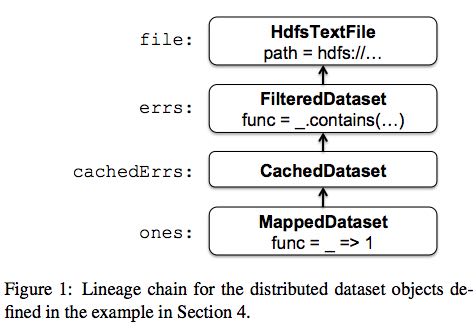
The core of Spark is the implementation of resilient dis- tributed datasets. As an example, suppose that we define a cached dataset called cachedErrs representing error messages in a log file, and that we count its elements us- ing map and reduce, as in Section 3.1:
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)
These datasets will be stored as a chain of objects cap- turing the lineage of each RDD, shown in Figure 1. Each dataset object contains a pointer to its parent and informa- tion about how the parent was transformed.
Internally, each RDD object implements the same sim- ple interface, which consists of three operations:(RDD interface)
- getPartitions, which returns a list of partition IDs.(这个RDD有哪些partitions)
- getIterator(partition), which iterates over a partition.(遍历partition获取数据)
- getPreferredLocations(partition), which is used for task scheduling to achieve data locality.(这个partition存储在哪些地方,这样可以将人任务分发到上面提高data locality)
When a parallel operation is invoked on a dataset, Spark creates a task to process each partition of the dataset and sends these tasks to worker nodes. We try to send each task to one of its preferred locations using a technique called delay scheduling. Once launched on a worker, each task calls getIterator to start reading its partition.(通过将task放置到partition所在的位置称为延迟调度。一旦worker启动之后获取partition的遍历器来读取数据)
The different types of RDDs differ only in how they implement the RDD interface. For example,
- for a Hdfs- TextFile, the partitions are block IDs in HDFS, their pre- ferred locations are the block locations, and getIterator opens a stream to read a block.
- In a MappedDataset, the partitions and preferred locations are the same as for the parent, but the iterator applies the map function to ele- ments of the parent.
- Finally, in a CachedDataset, the getIterator method looks for a locally cached copy of a transformed partition, and each partition’s preferred loca- tions start out equal to the parent’s preferred locations, but get updated after the partition is cached on some node to prefer reusing that node.
This design makes faults easy to handle: if a node fails, its partitions are re-read from their parent datasets and eventually cached on other nodes.
Finally, shipping tasks to workers requires shipping closures to them—both the closures used to define a dis- tributed dataset, and closures passed to operations such as reduce. To achieve this, we rely on the fact that Scala clo- sures are Java objects and can be serialized using Java se- rialization; this is a feature of Scala that makes it relatively straightforward to send a computation to another machine. Scala’s built-in closure implementation is not ideal, how- ever, because we have found cases where a closure object references variables in the closure’s outer scope that are not actually used in its body. We have filed a bug report about this, but in the meantime, we have solved the issue by performing a static analysis of closure classes’ byte- code to detect these unused variables and set the corre- sponding fields in the closure object to null. We omit the details of this analysis due to lack of space.(通过对closure做序列化将task散布到worker上面)
5.2. Shared Variables
The two types of shared variables in Spark, broadcast variables and accumulators, are imple- mented using classes with custom serialization formats.
When one creates a broadcast variable b with a value v, v is saved to a file in a shared file system. The serialized form of b is a path to this file. When b’s value is queried on a worker node, Spark first checks whether v is in a local cache, and reads it from the file system if it isn’t. We initially used HDFS to broadcast variables, but we are developing a more efficient streaming broadcast system.(将HDFS当作共享文件系统,广播数据存储在HDFS上面,而广播变量就是HDFS的文件路径)
Accumulators are implemented using a different “se- rialization trick.” Each accumulator is given a unique ID when it is created. When the accumulator is saved, its serialized form contains its ID and the “zero” value for its type. On the workers, a separate copy of the accu- mulator is created for each thread that runs a task using thread-local variables, and is reset to zero when a task be- gins. After each task runs, the worker sends a message to the driver program containing the updates it made to var- ious accumulators. The driver applies updates from each partition of each operation only once to prevent double- counting when tasks are re-executed due to failures.(累加器变量由driver分配ID,然后各个worker汇报在自己在这个ID上的增量)