The Snowflake Elastic Data Warehouse
Table of Contents
https://dl.acm.org/doi/pdf/10.1145/2882903.2903741
Snowflake是基于云的数据仓库服务,有几个设计上的亮点:
- 高可用性和伸缩性,这得益于在设计上将存储和计算分开
- 可以处理半结构化和schema-less的数据
- time travel和端到端的安全性
1. Abstract
Snowflake is a multi-tenant, transactional, secure, highly scalable and elas- tic system with full SQL support and built-in extensions for semi-structured and schema-less data. The system is offered as a pay-as-you-go service in the Amazon cloud. Users up- load their data to the cloud and can immediately manage and query it using familiar tools and interfaces. Implemen- tation began in late 2012 and Snowflake has been generally available since June 2015. Today, Snowflake is used in pro- duction by a growing number of small and large organiza- tions alike. The system runs several million queries per day over multiple petabytes of data.
In this paper, we describe the design of Snowflake and its novel multi-cluster, shared-data architecture. The paper highlights some of the key features of Snowflake: extreme elasticity and availability, semi-structured and schema-less data, time travel, and end-to-end security. It concludes with lessons learned and an outlook on ongoing work.
2. Introduction
Relational Snowflake has comprehensive support for ANSI SQL and ACID transactions. Most users are able to migrate existing workloads with little to no changes.
Semi-Structured Snowflake offers built-in functions and SQL extensions for traversing, flattening, and nest- ing of semi-structured data, with support for popular formats such as JSON and Avro. Automatic schema discovery and columnar storage make operations on schema-less, semi-structured data nearly as fast as over plain relational data, without any user effort.
Elastic Storage and compute resources can be scaled in- dependently and seamlessly, without impact on data availability or performance of concurrent queries.
Highly Available Snowflake tolerates node, cluster, and even full data center failures. There is no downtime during software or hardware upgrades.
Durable Snowflake is designed for extreme durability with extra safeguards against accidental data loss: cloning, undrop, and cross-region backups.
3. Storage vs. Compute
传统的share-nothing架构中,存储和计算是放在同一个节点上的,这个节点上有自己的存储存放部分数据。share-nothing这种架构有3个问题:
- Heterogeneous Workload While the hardware is homo- geneous, the workload typically is not. A system con- figuration that is ideal for bulk loading (high I/O band- width, light compute) is a poor fit for complex queries (low I/O bandwidth, heavy compute) and vice versa. Consequently, the hardware configuration needs to be a trade-off with low average utilization.
- Membership Changes If the set of nodes changes; either as a result of node failures, or because the user chooses to resize the system; large amounts of data need to be reshuffled. Since the very same nodes are responsible for both data shuffling and query processing, a sig- nificant performance impact can be observed, limiting elasticity and availability.
- Online Upgrade While the effects of small membership changes can be mitigated to some degree using repli- cation, software and hardware upgrades eventually af- fect every node in the system. Implementing online upgrades such that one node after another is upgraded without any system downtime is possible in principle, but is made very hard by the fact that everything is tightly coupled and expected to be homogeneous.
但是这些问题在on-premise环境下不是太大问题,但是在cloud环境下是绝对不行的。其实说白了还是on-premise这种利用效率不高,你指望着一个cluster可以跑各种类型的workload,本身说明配置就不是最优的。
In an on-premise environment, these issues can usually be tolerated. The workload may be heterogeneous, but there is little one can do if there is only a small, fixed pool of nodes on which to run. Upgrades of nodes are rare, and so are node failures and system resizing.
The situation is very different in the cloud. Platforms such as Amazon EC2 feature many different node types [4]. Tak- ing advantage of them is simply a matter of bringing the data to the right type of node. At the same time, node failures are more frequent and performance can vary dramatically, even among nodes of the same type [45]. Membership changes are thus not an exception, they are the norm. And finally, there are strong incentives to enable online upgrades and elastic scaling. Online upgrades dramatically shorten the software development cycle and increase availability. Elas- tic scaling further increases availability and allows users to match resource consumption to their momentary needs.
如果我们要在cloud环境下面工作的话,最好就是将存储和计算分离,有专门的存储节点和计算节点。存储可以直接使用cloud service比如S3(很难想象在做个比S3更加稳定可靠的存储服务了),而计算节点则可以根据workload去动态申请,使用完成就立刻释放。计算节点上也有local disk, 但是只作为data cache使用。
For these reasons and others, Snowflake separates storage and compute. The two aspects are handled by two loosely coupled, independently scalable services. Compute is pro- vided through Snowflake’s (proprietary) shared-nothing en- gine. Storage is provided through Amazon S3 [5], though in principle any type of blob store would suffice (Azure Blob Storage [18, 36], Google Cloud Storage [20]). To reduce net- work traffic between compute nodes and storage nodes, each compute node caches some table data on local disk.
An added benefit of this solution is that local disk space is not spent on replicating the whole base data, which may be very large and mostly cold (rarely accessed). Instead, local disk is used exclusively for temporary data and caches, both of which are hot (suggesting the use of high-performance storage devices such as SSDs). So, once the caches are warm, performance approaches or even exceeds that of a pure shared-nothing system. We call this novel architecture the multi-cluster, shared-data architecture.
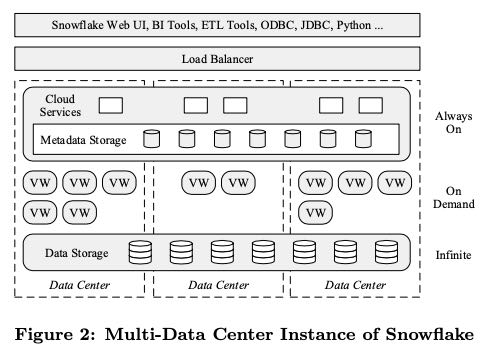
4. Architecture
整个架构分为3层
- Data Storage This layer uses Amazon S3 to store table data and query results.
- Virtual Warehouses The “muscle” of the system. This layer handles query execution within elastic clusters of virtual machines, called virtual warehouses.
- Cloud Services The “brain” of the system. This layer is a collection of services that manage virtual warehouses, queries, transactions, and all the metadata that goes around that: database schemas, access control infor- mation, encryption keys, usage statistics and so forth.
4.1. Data Storage
S3访问接口的限制也影响到了file format的设计。S3 PUT上传接口不支持追加或者是重写部分,GET下载接口可以指定偏移和大小访问。S3除了存放原始数据之外,也会存放计算中间数据。Cloud Services的Metadata Storage不是使用的S3, 它选用的是个分布式支持事务key-value db.
Compared to local storage, S3 naturally has a much higher access latency and there is a higher CPU overhead associated with every single I/O request, especially if HTTPS connec- tions are used. But more importantly, S3 is a blob store with a relatively simple HTTP(S)-based PUT/GET/DELETE interface. Objects i.e. files can only be (over-)written in full. It is not even possible to append data to the end of a file. In fact, the exact size of a file needs to be announced up-front in the PUT request. S3 does, however, support GET requests for parts (ranges) of a file.
These properties had a strong influence on Snowflake’s table file format and concurrency control scheme (cf. Sec- tion 3.3.2). Tables are horizontally partitioned into large, immutable files which are equivalent to blocks or pages in a traditional database system. Within each file, the values of each attribute or column are grouped together and heav- ily compressed, a well-known scheme called PAX or hybrid columnar in the literature [2]. Each table file has a header which, among other metadata, contains the offsets of each column within the file. Because S3 allows GET requests over parts of files, queries only need to download the file headers and those columns they are interested in.
Snowflake uses S3 not only for table data. It also uses S3 to store temp data generated by query operators (e.g. massive joins) once local disk space is exhausted, as well as for large query results. Spilling temp data to S3 allows the system to compute arbitrarily large queries without out-of- memory or out-of-disk errors. Storing query results in S3 enables new forms of client interactions and simplifies query processing, since it removes the need for server-side cursors found in traditional database systems.
Metadata such as catalog objects, which table consists of which S3 files, statistics, locks, transaction logs, etc. is stored in a scalable, transactional key-value store, which is part of the Cloud Services layer.
4.2. Virtual Warehouses
一个VW是由若干个ec2实例组成的,在内部叫做worker node.
The Virtual Warehouses layer consists of clusters of EC2 instances. Each such cluster is presented to its single user through an abstraction called a virtual warehouse (VW). The individual EC2 instances that make up a VW are called worker nodes. Users never interact directly with worker nodes. In fact, users do not know or care which or how many worker nodes make up a VW. VWs instead come in abstract “T-Shirt sizes” ranging from X-Small to XX-Large. This abstraction allows us to evolve the service and pricing independent of the underlying cloud platform.
Elasticity and Isolation
一个query只会跑在一个VW上,所以query之间使用的计算资源是完全隔离的。因为input都是immutable files, 并且output也是一个private place, 如果期间worker出现故障的话,完全可以重试整个query. 暂时还不支持部分重试。
Each individual query runs on exactly one VW. Worker nodes are not shared across VWs, resulting in strong perfor- mance isolation for queries. (That being said, we recognize worker node sharing as an important area of future work, because it will enable higher utilization and lower cost for use cases where performance isolation is not big concern.)
When a new query is submitted, each worker node in the respective VW (or a subset of the nodes if the op-timizer detects a small query) spawns a new worker pro-cess. Each worker process lives only for the duration of its query . A worker process by itself, even if part of an up- date statement, never causes externally visible effects, be- cause table files are immutable, cf. Section 3.3.2. Worker failures are thus easily contained and routinely resolved by retries. Snowflake does not currently perform partial retries though, so very large, long-running queries are an area of concern and future work.
Local Caching and File Stealing
每个worker node上使用自己的local disk当做数据缓存。为了提高缓存效率,在安排任务的时候,会将使用相同input file sets的task,尽可能地安排在一个worker node上。然后这种安排是使用consistent hashing技术,这样如果一个worker node挂掉的话,可以确保其他的worke nodes上的cache data依然有效而不需要shuffle. 另外为了处理skew handling的情况,也会使用file stealing技术。使用这个技术的前提是,skew handling的原因是因为worker node出现某种故障造成性能下降,而不是因为数据分布不均匀造成的。
Each worker node maintains a cache of table data on local disk. The cache is a collection of table files i.e. S3 objects that have been accessed in the past by the node. To be precise, the cache holds file headers and individual columns of files, since queries download only the columns they need.
To improve the hit rate and avoid redundant caching of individual table files across worker nodes of a VW, the query optimizer assigns input file sets to worker nodes using con- sistent hashing over table file names [31]. Subsequent or concurrent queries accessing the same table file will there- fore do this on the same worker node.
Besides caching, skew handling is particularly important in a cloud data warehouse. Some nodes may be executing much slower than others due to virtualization issues or net- work contention. Among other places, Snowflake deals with this problem at the scan level. Whenever a worker process completes scanning its set of input files, it requests addi- tional files from its peers, a technique we call file stealing. If a peer finds that it has many files left in its input file set when such a request arrives, it answers the request by transferring ownership of one remaining file for the dura- tion and scope of the current query. The requestor then downloads the file directly from S3, not from its peer. This design ensures that file stealing does not make things worse by putting additional load on straggler nodes.
Execution Engine
单机引擎的效率还是蛮关键的:列式存储,向量化,push-based. 向量化这个名字我觉得有点奇怪,从文章解释来看是省去了物化中间结果步骤,而是配合push-based方式将整个执行过程管道化。
- Columnar storage and execution is generally considered superior to row-wise storage and execution for analytic workloads, due to more effective use of CPU caches and SIMD instructions, and more opportunities for (light- weight) compression [1, 33].
- Vectorized execution means that, in contrast to MapRe- duce for example [42], Snowflake avoids materialization of intermediate results. Instead, data is processed in pipelined fashion, in batches of a few thousand rows in columnar format. This approach, pioneered by Vector- Wise (originally MonetDB/X100 [15]), saves I/O and greatly improves cache efficiency.
- Push-based execution refers to the fact that relational op- erators push their results to their downstream oper- ators, rather than waiting for these operators to pull data (classic Volcano-style model [27]). Push-based ex- ecution improves cache efficiency, because it removes ontrol flow logic from tight loops [41]. It also enables Snowflake to efficiently process DAG-shaped plans, as opposed to just trees, creating additional opportunities for sharing and pipelining of intermediate results.
在执行过程中不需要考虑事务管理,然后因为大量操作都是扫描数据,所以也不需要buffer pool这样的东西。但是要解决内存不够用的情况,这个时候需要将数据spill到local disk上甚至是s3上,不然这个系统也就是个玩具。
At the same time, many sources of overhead in traditional query processing are not present in Snowflake. Notably, there is no need for transaction management during execu- tion. As far as the engine is concerned, queries are executed against a fixed set of immutable files. Also, there is no buffer pool. Most queries scan large amounts of data. Using mem- ory for table buffering versus operation is a bad trade-off here. Snowflake does, however, allow all major operators (join, group by, sort) to spill to disk and recurse when main memory is exhausted. We found that a pure main-memory engine, while leaner and perhaps faster, is too restrictive to handle all interesting workloads. Analytic workloads can feature extremely large joins or aggregations.
4.3. Cloud Services
这里主要介绍的是Optimizer和Transaction Manager
Query Management and Optimization
对Query优化不是特别熟悉,后面可以多了解下
Snowflake’s query optimizer follows a typical Cascades- style approach [28], with top-down cost-based optimization. All statistics used for optimization are automatically main- tained on data load and updates. Since Snowflake does not use indices (cf. Section 3.3.3), the plan search space is smaller than in some other systems. The plan space is further reduced by postponing many decisions until execu- tion time, for example the type of data distribution for joins. This design reduces the number of bad decisions made by the optimizer, increasing robustness at the cost of a small loss in peak performance. It also makes the system easier to use (performance becomes more predictable), which is in line with Snowflake’s overall focus on service experience.
Once the optimizer completes, the resulting execution plan is distributed to all the worker nodes that are part of the query. As the query executes, Cloud Services continuously tracks the state of the query to collect performance counters and detect node failures. All query information and statis- tics are stored for audits and performance analysis. Users are able to monitor and analyze past and ongoing queries through the Snowflake graphical user interface.
Concurrency Control
因为table以及table files都是immutable的,上面都带了版本号,所以可以很容易实现snapshot isolation来做并发控制。此外也可以很容易做snapshot来做time travel.
Pruning
根据table files里面的数据分布来做做剪枝。静态剪枝可以在query optimization阶段完成,而动态剪枝则要在query execution阶段完成。
An alternative technique has recently gained popularity for large-scale data processing: min-max based pruning, also known as small materialized aggregates [38], zone maps [29], and data skipping [49].
Besides this static pruning, Snowflake also performs dy- namic pruning during execution. For example, as part of hash join processing, Snowflake collects statistics on the dis- tribution of join keys in the build-side records. This informa- tion is then pushed to the probe side and used to filter and possibly skip entire files on the probe side. This is in addi- tion to other well-known techniques such as bloom joins [40].
5. Feature Highlights
5.1. Continuous Availability
考虑到VW之间是需要通信而且是无状态的,所以只有这个是不跨AZ的。S3的SLA也是挺吓人的。
Replication across AZs al- lows S3 to handle full AZ failures, and to guarantee 99.99% data availability and 99.999999999% durability. Matching S3’s architecture, Snowflake’s metadata store is also dis- tributed and replicated across multiple AZs.
5.2. Semi-Structured and Schema-Less Data
除去标准的SQL type之外,还引入了额外的三种类型,其中VARIANT是最通用的类型。所有数据类型都是自描述的,支持类型判断,比较,hasing以及查找。
ARRAY and OBJECT are just restrictions of type VARIANT. The internal representation is the same: a self-describing, compact binary serialization which supports fast key-value lookup, as well as efficient type tests, comparison, and hash-ing. VARIANT columns can thus be used as join keys, group-ing keys, and ordering keys, just like any other column.
使用一种混合列式存储格式。在使用relational data存储的同时,会自动地对path/column使用情况进行统计分析。如果某些path查询非常频繁的话,那么对应的columns则会被单独存储。
As mentioned in Section 3.1, Snowflake stores data in a hybrid columnar format. When storing semi-structured data, the system automatically performs statistical analysis of the collection of documents within a single table file, to perform automatic type inference and to determine which (typed) paths are frequently common. The corresponding columns are then removed from the documents and stored separately, using the same compressed columnar format as native relational data. For these columns, Snowflake even computes materialized aggregates for use by pruning (cf. Section 3.3.3), as with plain relational data.