七周七并发模型(Seven Concurrency Models in Seven Weeks)
Table of Contents
1. 并行和并发
并发程序含有多个逻辑上的独立执行块,它们可以独立的并行执行,也可以串行执行。并行程序解决问题的速度往往比串行程序快的多,因为其可以同时执行整个任务的多个部分。并行程序可能有多个独立执行体,也可能仅有一个。
我们还可以从另一种角度来看待并发和并行之间的差异。并发是问题域中的概念,程序需要被设计成能够处理多个同时(或者几乎同时)发生的事情,而并行则是方法域中的概念,通过将问题中的多个部分并行执行来加速解决问题。
Rob Pike的经典描述:
- 并发是同一时间应对(dealing with)多件事情的能力。
- 并行是同一时间动手(doing)做多件事情的能力。
几种并行架构:
- 位级(bit-level)并行,比如寄存器从32位升级到64位。
- 指令级(instruction-level)并行,比如CPU指令流水线,乱序执行和猜测执行。
- 数据级(data-level)并行,比如CPU的SIMD指令以及GPU向量计算指令。
- 任务级(task-level)并行,比如多处理器架构以及分布式系统架构。
2. 七个并发模型
线程与锁
- JVM中终止线程的手段是让run()函数返回(可能是抛出跑出InterruptedException).
- 我认为诊断多线程问题的感觉,非常类似于一级方程式赛车的工程师诊断引擎故障。引擎在正常运行几个小时后,突然在没有任何征兆的情况下发生严重故障,机油和零件散落一地狼狈不堪。大赛车被拖回维修厂后,可怜的工程师要面对一堆残骸,找出故障的原因,故障原因可能是很小的,一个坏的油泵轴承或阀门,但应该如何从一片混乱中找出原因呢?经常使用的方法是尽可能的完善对引擎数据的记录,并让赛车手使用新的引擎,希望下次发生故障时数据能提供一些有用的信息。
函数式编程:函数式代码消除了可变状态和副作用,从根本上是线程安全的,所以很容易并行执行。
Clojure-分离标识与状态
- 原子变量(atom). swap!执行CAS操作,但是操作可能会触发多次;reset!则直接设置值。
- 对某个标识name, 在t0时刻和t1时刻访问得到的数据(状态)可能是不同的,虽然访问的还是同一标识。
- 代理(agent)是将变量的更新提交到线程池异步执行,我们可以控制线程池来控制并发。
- 引用(ref)可以实现软件事务内存(Software Transactional Memory, STM). 可以在一个block内原子更新多个引用,如果期间引用发生变化,那么这个事务会重试。所以含有副作用的事务需要谨慎使用。
Elixir-actor模型
- 对于一个使用actor模型的程序,其错误处理内核是顶层的管理者,管理着子进程,对子进程进行启动停止重启的操作。程序的每个模块都有自己的错误处理内核,模块正确运行的前提是其错误处理内核必须正确运行。子模块也会有自己的错误处理内核,以此类推。这就构成了错误处理内核的层级树,较危险的操作都会被下放给底层的actor执行。
- 我们可以认为actot模型是面向对象模型在并发编程领域的扩展。actot模型精心设计的消息传输和封装的机制,强调了面向对象的精髓,所以说act模型非常”面向对象"。
通信顺序进程(Communicating Sequential Processes, CSP)
- 如果你和我一样是个车迷,很可能只会关注车辆本身,而忽略了它所要行驶的道路。大家都在喋喋不休的争论,涡轮增压与自然吸气孰优孰劣,让中置发动机布局与前置发动机布局一较高下,却忘记了最重要的方面其实与车辆本身无。你能去往何方,能多快到达目的地,首要的决定因素是道路网络而不是车辆本身。
- 与actor模型类似,通信顺序进程模型也是由独立的并发执行的实体所组成,实体之间也是通过发送消息进行通信。但两种模型的重要差别是,CSP模型不关注发送消息的实体,而是关注发送消息时使用的channel通道. channel是第1类对象,它不像进程那样和信箱是紧耦合的,而是可以单独创建和读写,并在进程之间传递。
数据级并行, GPGPU(General Purpose computing on the GPU)编程
- 现代GPU是异常复杂但十分强力的并行处理器,其一秒钟可以处理几十亿个三角形。虽然设计GPU的主要目的是为了满足图形计算的需要,但是GPU也可用于更广的领域。
- 为了获得更好的性能,现实中的GPU会综合使用流水线,多ALU以及许多本书上未提及的技术,这就增加了进一步理解GPU的难度。更遗憾的是,不同的(即使是同一厂商生产的)GPU之间的共性是很少的。如果我们必须针对某个架构开发代码,GPGPU编程不是最佳选择。
- OpenCL适用于CPU,这是很多人没有想到的。事实上,现代CPU支持数据并行指令已经很长时间了。例如英特尔处理器就支持流式SIMD扩展指令集(Streaming SIMD Extensions)和高级矢量扩展指令集(Advanced Vector Extensions, AVX)。OpenCL可以高效的使用这些指令集合和多核CPU。
- GPU不仅是强大的数据并行处理器,在能耗方面也表现出众,比传统的CPU有更优秀的GFLOPS/watt指标。世界上最快的超级计算机都广泛使用GPU或专用数据并行协处理器,其中能耗指标低是一个重要的原因。
- GPGPU框架还包括CUDA, DirectCompute以及RenderScript Computation.
Lambda架构,Batch+Realtime
3. 内存模型
多线程之间观察几个变量的更新顺序会出现乱序情况,可能有下面几个原因:
- 编译器的静态优化可以打乱代码的执行顺序
- JVM的动态优化也会打乱代码的执行顺序
- 硬件可以通过乱序执行来优化性能
Java Memory Model http://www.cs.umd.edu/~pugh/java/memoryModel/ keyword: William Pugh Java Memory Model
值得一提的是,虽然我们仅讨论了Java的内存模型,但是会对内存访问进行乱序执行的却不止Java。大多数语言没有对内存模型做出完善的定义,没有明确的说明乱序执行何时发生以及如何发生。在这方面Java是先驱者,是第一个完整定义内存模型的主流语言,C和C++是在C11和C++11的标准中才补充了内存模型。
4. OpenCL知识
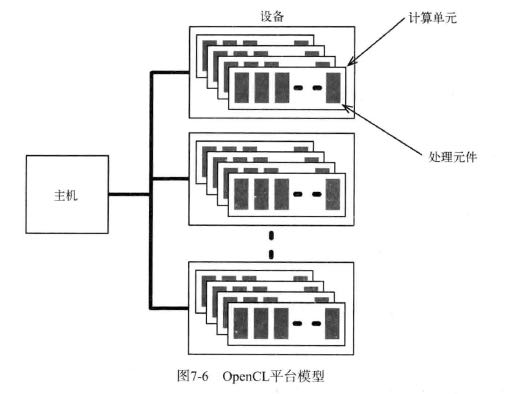
OpenCL执行过程如下:
- 通过将任务分成工作项,OpenCL可以将任务并行化。
- 通过编写内核,指定了单个工作项是如何工作的。
- 要执行内核主机程序,必须遵循以下步骤:
- 创建上下文,内核和命令队列都将在运行在这个上下文中;
- 编译内核;
- 创建输入数据的缓存区和输出数据的缓存区;
- 像命令队列中输入一个命令,让每一个工作项上都运行一次内核程序;
- 获取结果。
工作项是在处理元件中执行的,在同一个计算单元中执行的工作下的集合称为工作组。几个工作组中的工作项共享使用局部内存。工作项执行内核程序时,会访问四种不同的内存区域:
- 全局内存 global memory: 同一个设备上执行的所有工作项都可以使用的内存。
- 常量内存 constant memory: 全局内存的一部分,在执行内核时保持不变。
- 局部内存 local memory: 工作组私有的内存,可用于工作组中不同工作项之间的通信。
- 私有内存 private memory: 工作项私有的内存。