Scaling to Billions on Top of DigitalOcean
https://www.digitalocean.com/customers/io/
DigitalOcean的广告贴吧,可以了解一下如何在DO上搭建cluster的
服务的资源和各项指标。机器数量还是蛮多的,而且每天会有2个节点出现比较严重的问题,根据负载情况增加和减少10-20个节点。我怀疑搞不好这种auto-scaling功能还需要编写代码才能完成。
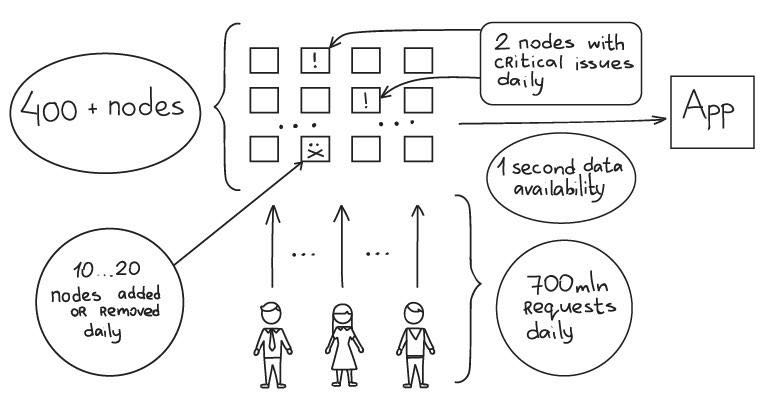
- 400+ nodes
- From 0 to 700 million requests a day in 6 months
- 20 billion events collected daily
- 10 - 20 nodes are added or removed every day
- 2 nodes experience critical issues every day
- Technologies: Nginx, Nodejs, Python, PHP, R, Mysql, Redis, Memcache
看起来这波人喜欢手撸,喜欢自己做一些工具来处理failover。
We knew that we would face scalability issues very soon, so we decided to build a growth focused system from the start. What it meant for us:
- No powerful server configurations. We use techniques like database sharding even for micro-nodes.
- All nodes should have at least one backup. If one goes down, the other is still up.
- We should be able to add nodes very fast. Sometimes every minute counts.
Our expenses could be reduced by 30% if we were to switch to powerful dedicated servers. But in this case we would have to pay for hardware failures and hire a system administrator (yes, we do not have one right now!) to deal with all this stuff.
为什么选择DO而不是AWS呢?好处有下面几个:
- 功能简单,并且有非常简单的API。相比aws ec2确实比较繁琐,但是强大。
- 低配置机器的开销非常少。同等低配置的机器费用,AWS是DO的3倍
- 费用计算方式简单。AWS计费方式尤其是S3的,基本上没有人搞得懂。
不过他们也使用了一些AWS服务比如Route53.
DO上如何选择机器配置呢?开始他们选择的是0.5GB-1core plan, 但是发现OS占用了很多内存,留给DB/MySQL的就很少了,所以最终选择1GB-1core plan给DB.
- Frontends — 2GB x 2-core
- Data storages — 1GB x 1-core
- AI nodes (r and python – anomaly detection subsystem) — 2GB x 2-core
默认是关闭SWAP的,所以需要非常注意内存使用情况避免OOM。节点之间通信使用private networking,这样可以避免外网流量。为了减少frontend高并发对DB的压力,DB前面做了一个proxy/aggregator, 我觉得可以认为是用来做保护的。
failover是如何来完成的呢?通过monitor监控所有节点的状态,来调用DO API来上线和下线。
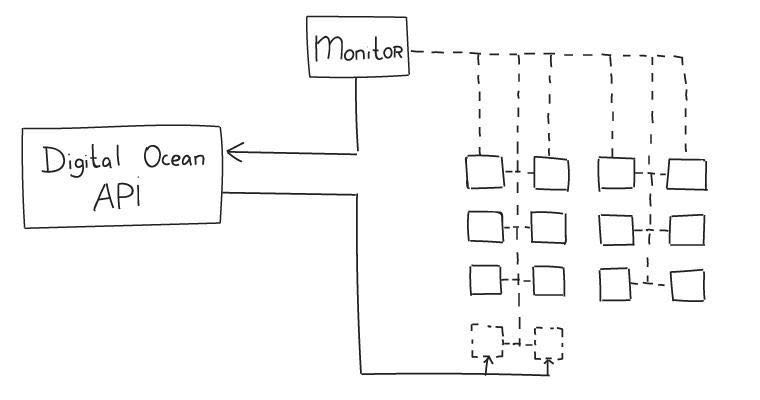
对于Shared Resources来说, Stolen CPU 是非常重要的指标。如何这个指标很高的话,说明资源共享做的不太好。