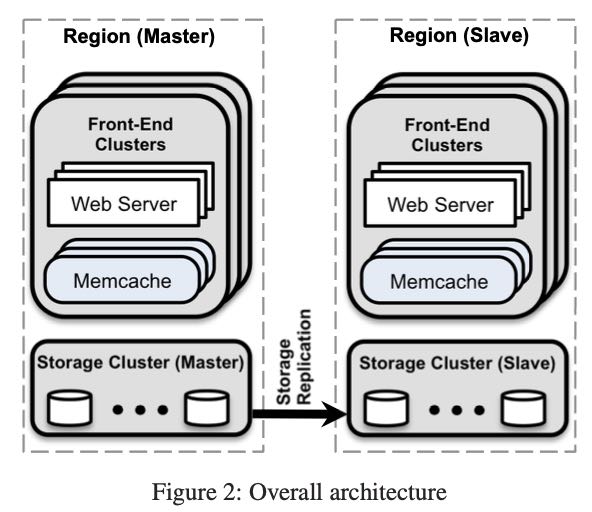
Scaling Memcache at Facebook
FB内部是如何利用和改进Memcache集群的。在FB内部,memcache被集中管理起来分为3个层次:
- cluster. 可以认为是一个机架内的集群
- region. 一个机房内多个cluster组成的集群
- across region. 跨区域的集群
文章下面分别从这3个层次讲了他们使用和改进的地方
在Cluster级别上如何减少延迟和负载:
- 在Get请求上使用UDP而不是TCP直接去拿. 如果出现丢包(80%)或者是顺序错误(20%)的话,那么直接认为失败然后从storage层取数据,但是不回写到cache上。如果出现丢包通常以为机架上网络比较拥塞了,所以可能去直接去storage上拿回更好。产品上只有0.25%拿不到结果,而延迟可以减少20%. Set/Delete 还是走TCP并且连接mcrouter.
- Incast Congestion改进,使用sliding window机制避免拥塞。Client一次可能会请求大量的keys, 可以将这些keys进行切分,然后分批进行发送并且用window size控制最大并发数。
- Lease机制确保cache中不会被更新到stale数据。memcache在某个key被请求的时候会生成一个lease交给client, client拿到结果更新cache的时候会带上lease. 如果不一致的话,可以认为不是最新的cache数据,lease的有效期是10s,这个和从后端取数据的时间要对上。lease机制还可以改善thundering herds情况,如果瞬时有许多client请求一个key的时候,如果这上面已经分配了lease的话,说明已经有个client在去后端要数据了,这个时候可以让其他client在等等。通常几个毫秒第一个client就可以拿到数据。
- 组成memcache pools. 根据keys的set size以及expiry time拆分成为多个pools,避免出现内存换出造成效率不够。这个论文中给出了两个pool的数据low-churn和high-churn. low-churn通常是是数据不怎么变,但是计算代价比较高,需要内存不多。而high-churn则数据更新特别频繁,可能占用内存比较多。如果这两类workload混布的话,high-churn可能会把low-churn的数据给挤出去。
- replication with pools. 如果keys都落在少数几台机器上,那么做replication可以有效减少带宽。
- Gutter 是cluster里面1%的memcache备用服务器,如果出现故障client拿不到cache数据的话,就会来gutter上拿cache数据或者是更新。到gutter上的数据expiry time都比较短,但是我估计也有10s左右,可能读到stale数据,主要是缓解服务器故障时候瞬时压力的。
Region级别上主要是做Replication工作。所有web servers以及memcache servers以及storage server都是在同一个DC下面。web+memcache组成frontend clusters, 下面是共享的storage server.
- web server如果是update的话,那么会给自己的local cluster发送一个invalidation. 如果继续在这个cluster上访问的话,就可以做到read-after-write一致性,而没有做到across cluster级别的一致性。
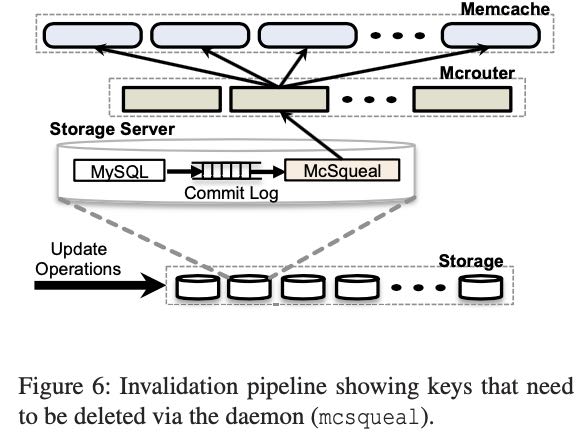
- 对于delete数据做到了across cluster级别的一致性(主要还是delete这个场景很tricky,你不知道是取不到还是没有数据)。这个实现方式很有意思,就是在storage server(具体是MySQL) 上拿到commit log. 如果commit log里面有delete操作的话,那么会发送给mcrouter, 通知所有的cluster去做invalidation. 具体可以看下图。大约有4%的删除操作。
- regional pool. 把多个cluster上的memcache组成pool. 因为多个cluster pool之间是replication的,所以内存利用率会较低。组成regional pool的话可以减少replication factor提高利用率,但是跨机架的带宽是单机架的40%左右,会有点稍高的延迟。
- cold cluster warmup. 如何对一个cold cluster做wamup, 可以将恢复过程从几天压缩到几个小时。思路就是client从从cold cluster拿不到的话,则从warmup cluster中拿到数据后回写一份到cold cluster上。但是里面有一致性问题。如果client在cold cluster上更新db,但是这个db数据并没有反应到wamup cluster上的话,那么写入cold cluster的数就是stale数据(我觉得也还好吧,最终还是会回来的,除非是delete操作)。解决办法就是,在cold cluster这个key上增加一个hold off time(2s), 在hold off time期间是不允许更新的。其实这个hold off time可以认为,这个delete propagation造成invalidation的时间是2s. 一旦cold cluster的hit rate到达一定标准,就认为warmup完成,就可以开始走正常逻辑了。
Across Regions 里面有点很有意思,就是如果是从non-master region发起的写(删除)操作的话,db数据到达non-master region db上需要一定的延迟。如果这个时候client开始读non-master region cache的话,就会出现不一致的问题。解决办法是如果删除k的话,首先在local cache上删除k并且增加一个kR(key redirect) 这个意味着,如果要访问k一定要读取master region db. 当删除操作到达了non-master region db, 之前的mcsquel就会把k和kR一起invalidation. 此时数据完全达到一致。
FB在单机版本上也做了不少优化:
- HashTable 进行伸缩避免O(n^2)时间复杂度
- 使用了更加细粒度的全局锁来减少冲突
- 给每个线程分配UDP port来减少上下文切换
- adaptive slab allocator.
- transient item cache.
- shared memory to reduce memcache upgrade. 如果使用shared memory的话,那么在升级memcache的时候就不会有cold cache的问题
Transient Item cache这个优化是针对short-lived item. 因为现在evict是lazy操作,这样short-lived item在内存中会存放很久,直到内存不够才会被清除掉。从外部上看,内存使用就是一直增长,直到某个点突然下跌。一个办法就是后台有个线程不断地检查超时item, 我们可以把这些short-lived item专门放到一个circular buffer of linked list上,circular buffer有点类似时钟,每秒转到下一个slot检查下面的linked list是否有超时。这样下来内存使用量会更加平顺。
adaptive slab allocator要解决的问题,如果突然某一类size的allocation增多的话,如何给这个slab分配更多的对象,尤其是在内存空间不足的情况。解决办法就是,将某个最近使用次数最少的slab全部回收,然后分配给这个hot slab. 那么如何判断某个hot slab呢?如果这个slab next evicted item(将要被剔除)的次数超过其他slab平均使用次数的20%的话,那么就认为这个slab是hot的。这样的话就要统计两个东西:1. slab下面items的访问次数总和以及items总数 2. 某个item的访问次数总和。