Scala程序设计
1. 基础知识
1.1. 标识符
scala标识符分为3类:
- An alphanumeric identifier starts with a letter or underscore, which can be followed by further letters, digits, or underscores.
- Identifiers in user programs should not contain ‘\(’ characters, even though it will compile; if they do this might lead to name clashes with iden- tifiers generated by the Scala compiler. (尽可能避免\))
- Although underscores are legal in identifiers, they are not used that often in Scala programs, in part to be consistent with Java, but also because underscores have many other non-identifier uses in Scala code. As a result, it is best to avoid identifiers like to_string, init, or name_ . (尽可能避免_)
- "val name_:Int = 1" 会被认为是定义"name_:",所以必须在:之前添加空格 #note: 词法解析足够奇葩*
- An operator identifier consists of one or more operator characters. Oper- ator characters are printable ASCII characters such as +, :, ?, ~ or #.
- The Scala compiler will internally “mangle” operator identifiers to turn them into legal Java identifiers with embedded $ characters. For instance, the identifier :-> would be represented internally as $colon$minus$greater. If you ever wanted to access this identifier from Java code, you’d need to use this internal representation.
- A mixed identifier consists of an alphanumeric identifier, which is fol- lowed by an underscore and an operator identifier.
- unary_+ used as a method name defines a unary + operator.
- myvar_= used as method name defines an assignment operator.
- A literal identifier is an arbitrary string enclosed in back ticks. #note: 解决关键字问题
- You cannot write Thread.yield() because yield is a reserved word in Scala. However, you can still name the method in back ticks, e.g., Thread.`yield` ().
1.2. 原始类型
More generally, all of Java’s primitive types have corresponding classes in the scala package. And when you compile your Scala code to Java bytecodes, the Scala com- piler will use Java’s primitive types where possible to give you the perfor- mance benefits of the primitive types.
java原始类型已经全部导入了scala这个包里面,并且这个包是自动引入的。然后所有的原始类型全部变为大写字母开头比如Int,Float,Long等。这样存在一个好处就是从语法上完全统一了扩展类型和原始类型,并且对于这些原始类型scala在上面也做了一些扩展提供了方法,这样使得就更加模糊了扩展类型和原始类型之间的区别。但是scala在底层会尽可能地使用原始类型操作,在性能上不会存在损失。
scala> val a:Int=2 a: Int = 2 scala> a.toString() res0: String = 2 scala> a.to(4) res1: scala.collection.immutable.Range.Inclusive = Range(2, 3, 4)
#note: 实际上scala内部提供了隐式转换到其他类来提供扩展方法的,比如将Int->RichInt.
数组类型则是 Array[<type>] 比如
- Array[String]
- Array[Array[String]]
scala> val a = new Array[Array[String]](10)
a: Array[Array[String]] = Array(null, null, null, null, null, null, null, null, null, null)
scala> a[0]
<console>:1: error: identifier expected but integer literal found.
a[0]
scala> a(0)
res1: Array[String] = null
scala> a.apply(0)
res2: Array[String] = null
注意这里不能够在用[]这种方式来访问数组,而必须使用()的方式来访问。实际上scala将()调用方法定向到了apply这个函数,可以认为是操作符重载。
scala允许使用type关键字来为类型做别名,类型别名能够很大程度上简化代码
type Counter = Long; var id : Counter = 0;
1.3. 变量定义
Scala has two kinds of variables, vals and vars. A val is similar to a final variable in Java. Once initialized, a val can never be reassigned. A var, by contrast, is similar to a non-final variable in Java. A var can be reassigned throughout its lifetime.
scala提供了两种变量定义的方式,分别是val和var. 对于val来说一旦赋值便不能够更改,有点类似C++的引用或者是用const/final字段做修饰。而var则是类似普通变量赋值之后依然可以更改。定义变量形式如下
[val|var] <name> : <type> = <initializor>
因为scala有type inference功能,所以实际上<type>这个字段可以省略,直接通过<initializor>这个字段来推测类型。
scala> val a = 1 a: Int = 1 scala> val a = 1L a: Long = 1 scala> val a = 1.0 a: Double = 1.0 scala> val a = "Hello" a: String = Hello
如果没有赋初值的话那么相当只是声明而非定义。如果对于初值不感兴趣的话,那么可以使用_这个特殊的initializor. 但是注意只对var有效,这是因为val其实上必须设置有效的初值. 这个初始值语义上表示0,对于不同的类型有不同的初始值。比如int = 0, float = 0.0f, 引用类型 = null.
var a:Int = _; var b:Float = _; println(a); println(b);
1.4. 函数定义
a function defines an expression that results in a value.
大致形式如下
def <func>(<param1>:<type1>, <param2>:<type2>,..):<return-type> = {
// function body.
}
函数本质上就是求得一个表达式,所以在<function-body>部分最后一个表达式就function返回结果,不需要使用return来显示说明。同样这里也可以使用type inference, 所以如果scala可以从function-body推断的话,那么<return-type>这个部分也可以不用写。但是scala type inference依然比较简单,如果有显示return语句的话(有时候我们确实需要),那么依然需要指定返回类型。
scala> def foo(a:Int,b:Int):Int = {
| a+b
| }
foo: (a: Int, b: Int)Int
scala> def foo(a:Int,b:Int) = {
| a+b
| }
foo: (a: Int, b: Int)Int
scala> def foo(a:Int,b:Int) = {
| return a+b
| }
<console>:9: error: method foo has return statement; needs result type
return a+b
^
但是scala也允许定义没有任何返回值的函数.对于这类函数<return-type>=Unit, 类似java里面的void. 但是从概念上来说因为不返回值,所以没有必要加上=这个标签,这样看上去更像是一个过程
def printLine(a:String) {
println(a)
}
#note: 需要注意的是传入的param实际上都是以val来定义的,所以在funciton-body里面不允许做修改
所有函数都是继承于Function这个类的,比如(Int,Int) => Long那么继承于Function2[Int,Int,Long]并且实现了apply方法,所以如果想创建函数的话,实际上也可以使用创建对象方式来完成
val x = new Function2[Int,Int,Long] {
def apply(x:Int,y:Int) = x + y
}
#note@2013-11-04: much shorter code. Function2[Int,Int,Long] = (Int,Int)=>Long
object x extends((Int,Int)=>Long) {
def apply(x:Int,y:Int) = x + y
}
java里面使用…来表示参数列表比如
public static void main(String... args) {
System.out.println(args[0]);
}
而外部可以将类型为String[]的参数直接传入使用。
scala里面对应的表示如下,类型为String*
def foo(args:String*) {
for(arg <- args) {
println(arg);
}
}
但是和java不同的是没有办法直接传入数组,而必须使用:_*操作符展开。
val x = Array("Hello","World");
foo(x:_*)
函数调用上,如果没有参数的话可以省去(), 同时scala也支持指定参数传值而不是顺序传值
def printX() = println("X")
printX
def foo(x:Int,y:Int) = 2 * x + y
println(foo(x = 1, y = 1))
println(foo(y = 1, x = 1))
1.5. 控制结构
One thing you will notice is that almost all of Scala’s control structures result in some value. This is the approach taken by functional languages, in which programs are viewed as computing a value, thus the components of a program should also compute values.
从函数式编程角度出发,所有的控制结构都应该是能够产生值的。对于scala来说也是,基本上所有的控制结构都能够产生值。
- while # 不产生值
- foreach # args.foreach(<function>).
- for # for(arg <- args). 注意这里的arg以val定义所以不能够修改
- if/else # val x = if (<pred>) <value1> else <value2>
- match/case # pattern matching.
- try/catch/finally # exception handling.
- #note: 没有break/continue语句
对于for来说分为两个部分,一个是循环部分,一个是执行部分。
循环部分的大致语法就是arg <- args. 但是允许在后面接上过滤条件,然后允许多重嵌套用;分开。比如下面一段代码
for(i <- 0 to 4
if i%2 == 0
if i%4 == 0;
j <- 0 to 5
if j%2 == 1) {
println("i=" + i + ",j=" + j);
}
但是这样的方式是不产生值的,即使执行部分最后返回值,所以结果为(),如果需要产生值的话那么必须使用yield关键字。yield生成的效果非常类似list comprehension, 将执行部分返回值组成一个collection. 比如下面一段代码
val x =
for(i <- 0 to 4) yield {
i
}
println(x) // Vector(0, 1, 2, 3, 4)
上面这段代码效果和python list comprehension非常类似
a = [x+2 for x in range(0,4) if x %2 == 0]
#note: 在书中“For Expressions Revisited”这节其实可以认为for是语法糖衣,将map/filter/anonymous-function包装起来.事实上缺少break/continue这样的控制语句,将for转换成为函数式计算也相对比较简单 Coursera Reactive Programming
- for(x<-e1) yield e2 => e1.map(x => e2)
- for(x<-e1 if f; s) yield e2 => for(x<-e1 withFilter f;s) yield e2
- for(x<-e1; y<-e2; s) yield e3 => e1.flatMap(x => for(y<-e2; s) yield e3)
异常的触发和java类似都是throw new Exception(). catch部分可以通过模式匹配来完成。finally则主要用于处理清理资源释放等问题。
def f() {
throw new Exception("hello");
}
def g():Int = {
try {
f()
2
} catch {
case e:Exception => 3
case _:Throwable => 4
} finally {
}
}
finally里面的返回值会被忽略,除非使用return来强制返回。但是建议不要这么做,finally所存在的主要理由应该是用来做cleanup的工作而不是参与计算(The best way to think of finally clauses is as a way to ensure some side effect happens, such as closing an open file.)可以认为fianlly不是表达式的一部分.
One difference from Java that you’ll quickly notice in Scala is that unlike Java, Scala does not require you to catch checked exceptions.(不强制捕获检查异常)
match和switch非常类似,但是有下面两个比较重要的差别:
- One is that any kind of constant, as well as other things, can be used in cases in Scala, not just the integer-type and enum constants of Java’s case statements.
- Another difference is that there are no breaks at the end of each alternative. Instead the break is implicit, and there is no fall through from one alternative to the next.
下面是一段示例代码
val x = "hello";
val y =
x match {
case "world" => 2;
case "hello" => 3;
case _ => 4;
}
1.6. 等值比较
scala下==的和java是不同的。 在java下==是比较引用相等性,而scala下==则是比较值相等性,也就是说会调用equal来做比较
使用eq,ne来判断引用相当,但是判断引用相等仅限于引用类型
val a = Array("1");
val b = Array("2");
println(a eq b)
val c = b
println(c eq b)
1.7. operator
- a op b -> a.op(b)
- a(b) -> a.apply(b)
- a(b)=c -> a.update(b,c)
- a op: b -> b.op(a) # If the method name ends in a colon, the method is invoked on the right operand.
- #note: 但是evaluation的顺序依然先是a,然后是b
var Id = 0 // for identification.
class Op() {
val id = Id;
Id += 1;
def + (x: Op) {
println("operation by Op#" + id);
}
def +: (x: Op) {
println("operation by Op#" + id);
}
def apply(p: Int) {
println("apply with " + p)
}
def update(p: Int, c:Int) {
println("update with " + p + ", " + c);
}
}
val a = new Op(); // Op#0
val b = new Op(); // Op#1
a + b;
a +: b;
a(0);
a(0)=1;
1.8. 前提断言
- require(expression)
- assert(expression)
- assert(experession,explaination)
1.9. package
scala提供了两种定义package的方式,一种是java的,一种是类似C++ namespace的,关键字_root_来引用到最外层package
package A {
class X {
}
package B {
class X {
}
}
package C {
object Hello extends App {
val x = new A.X() // new _root_.A.X()
val x2 = new B.X()
}
}
}
import有下面几种常用方法 http://www.scala-lang.org/old/node/119.html
| The clause | makes available without qualification.. |
|---|---|
| import p._ | all members of p (this is analogous to import p.* in Java). |
| import p.x | the member x of p. |
| import p.{x => a} | the member x of p renamed as a. |
| import p.{x => _} | the member x of p removed. |
| import p.{x, y} | the members x and y of p. |
| import p1.p2.z | the member z of p2, itself member of p1. |
Futhermore the clause import p1._, p2._ is a shorthand for import p1._; import p2._. A catch-all ‘_’. This imports all members except those members men-tioned in a preceding clause. If a catch-all is given, it must come last in the list of import selectors.
cacth-all只能够用在最后一个selector上面,过滤之前所有的条件之后的部分,也就是说import p.{x=>_,_}导入p的除x之外的所有members, import p.{x=>a,_}则是导入p所有的members但是将x重命名为a.
scala import相比java import更加灵活
- may appear anywhere // 类似Python的import.
- may refer to objects (singleton or regular) in addition to packages
- let you rename and hide some of the imported members
def showFruit(fruit: Fruit) {
import fruit._
println(name +"s are "+ color)
}
Implicitly imported into every compilation unit are, in that order:
- the package java.lang,
- the package scala,
- and the object scala.Predef.
1.10. 模式匹配
模式匹配pattern matching在scala里面是一个重量级的功能,依赖于pm可以优雅地实现很多功能。大致格式如下
selector match {
pattern1 => <body1>
pattern2 => <body2>
...
}
pattern总结起来大约以下几类:
- Wildcard patterns // _ 统配
- Constant patterns // 常量
- Variable patterns // 变量
- Constructor patterns // 构造函数
- Sequence patterns // 比如List(,). 如果需要匹配剩余的话使用List(0,_*)
- Tuple patterns // (a,b,c)
- Typed patterns // 使用类型匹配 case a:Map[_,_]
- asInstanceOf[<type>]
- isInstanceOf[<type>]
- #note: 这里需要注意容器类型擦除. Array例外因为这个是java内置类型*
实际上我们还能够使用pattern完成下面事情:
- Patterns in variable definitions // val (a,b) = ("123","345");
- Case sequences as partial functions
- 直接使用pattern来构造函数.以参数为match对象,在body里面直接编写case.
- Each case is an entry point to the function, and the parameters are specified with the pattern. The body of each entry point is the right-hand side of the case.
- Patterns in for expressions // for ((country, city) <- capitals)
// case sequences as partial function.
val foo : Option[String] => String = {
case Some(e) => e
case None => "???"
}
val a = Option[String]("hello")
println(foo(a))
val b = None
println(foo(b))
pattern matching过程中还有下面几个问题需要注意:
- Patterns are tried in the order in which they are written.
- Variable binding // 有时候我们希望匹配的变量包含外层结构
- A(1,B(x)) => handle(B(x))
- A(1, p @ B(_)) => handle(p) # p绑定了B(x)这个匹配
- A(1, p @ B()) => handle(p) # B是可以包含unapply从type(p) => Boolean的类,做条件判断
- Pattern guards // 有时候我们希望对pattern做一些限制性条件
- A(1,e,e) 比如希望后面两个元素相等,但是这个在pm里面没有办法表达
- A(1,x,y) if x == y => <body> // 通过guard来完成
scala为了方便扩展pm对象的case, 提供case class这个概念。case class和普通class大致相同,不过有以下三个区别,定义上只需要在class之前加上case即可:
- 提供factory method来方便构造object
- class parameter隐含val prefix
- 自带toString,hashCode,equals实现
case class A(x:Int) {} // implicit val x:Int
val a = A(1); // factory method.
println(a.x);
println(a); // toString = A(1)
case class最大就是可以很方便地用来做pattern matching.
如果我们能够知道某个selector所有可能的pattern的话,那么就能够在编译期做一些安全性检查。但是selector这个过于宽泛,如果将selector限制在类层次上的话,那么还是可以实现的。举例如下:
abstract class A; // sealed abstract class A
case class B(a:Int) extends A;
case class C(a:Int) extends A;
case class D(a:Int) extends A;
val a:A = B(1);
a match {
case e @ B(_) => println(e)
case e @ C(_) => println(e)
}
在match a这个过程中,实际上我们可能存在B,C,D三种子类,但是因为我们这里缺少检查。使用sealed关键字可以完成这个工作。sealed class必须和subclass在同一个文件内。A sealed class cannot have any new subclasses added except the ones in the same file. 如果上面增加sealed的话,那么编译会出现如下警告,说明我们没有枚举所有可能的情况。
/Users/dirlt/scala/Hello.scala:8: warning: match may not be exhaustive.
It would fail on the following input: D(_)
a match {
^
one warning found
有三个方式可以解决这个问题,一个是加上对D的处理,一个是使用unchecked annotation, 一个则是在最后用wildcard匹配
(a : @unchecked) match {
case e @ B(_) => println(e)
case e @ C(_) => println(e)
}
a match {
case e @ B(_) => println(e)
case e @ C(_) => println(e)
case _ => throw new RuntimeException("??");
}
模式匹配除了能够直接作用在case class上之外,也可以作用在普通的class上面,但是需要普通的class提供一些辅助的方法将转换成为case class或者是constant/string上面。这个机制在scala里面称为 extractor
下面是一个例子
class A(val a:String,
val b:String) {
}
val a = new A("hello","world");
a match {
case A(x,y) => println(x + "," + y);
case _ => println("!match");
}
这段代码不能够运行,原因在于没有办法告诉scala,如果将A实例和A(x,y)来做匹配。对于case classes来说实现可能相对简单,因为case class的class parameters都是val定义的,也就是说构造参数没有办法改变,编译器内部处理case classes的话可以保存这个构造参数,而general class却不能够像case class一样。所以需要用户提供辅助函数来帮助scala做pattern matching. 用户需要在companion object提供unapply函数
object A {
def apply(a:String,b:String) = new A(a,b)
def unapply(x:A) = Some((x.a,x.b))
}
unapply和apply通常是配对的函数。apply将参数构造成为一个对象,而unapply将对象解构成为参数。the apply method is called an injection, because it takes some arguments and yields an element of a given set. The unapply method is called an extrac- tion, because it takes an element of the same set and extracts some of its parts. 而companion object则称为extractor.
unapply的过程可以认为是将unapply参数最用在expression上,抽取出这个expression的构造参数 比如上面过程可以认为类似
object A {
def apply(a:String,b:String) = new A(a,b)
def unapply(a: A) = Some((a.a,a.b))
}
val a = new A("hello","world");
A.unapply(a) match {
case Some((x,y)) => println(x + "," + y);
case _ => println("!match");
}
使用上面的unapply方法不能够匹配带有_*这种sequence variable的pattern.允许匹配这种pattern的话,那么需要实现unapplySeq方法,返回参数必须是Option[Seq[T]]这个类型
object A {
def apply(a:String,b:String) = new A(a,b)
def unapplySeq(a: A):Option[Seq[String]] = Some(List(a.a,a.b))
}
val a = new A("hello","world");
a match {
case A(x,_*) => println(x);
case _ => println("!match");
}
1.11. annotation
Unlike comments, they have structure, thus making them easier to machine process. There are many things you can do with a program other than compiling and running it. Some examples are:
- Automatic generation of documentation as with Scaladoc.
- Pretty printing code so that it matches your preferred style.
- Checking code for common errors such as opening a file but, on some control paths, never closing it.
- Experimental type checking, for example to manage side effects or ensure ownership properties.
Such tools are called meta-programming tools, because they are pro- grams that take other programs as input. Annotations support these tools by letting the programmer sprinkle directives to the tool throughout their source code. Such directives let the tools be more effective than if they could have no user input. (所谓元编程就是能够编写以程序为输入的程序)
annotation作用方式通常有两种:
- @annotation [val|var|def|class|object] // 作用在声明和定义上
- (expression : @annotation) // 作用在表达式上
@deprecated class QuickAndDirty {}
(e: @unchecked) match {}
annotation通常格式如下
@annot(exp1, exp2, ...) {val name1=const1, ..., val namen=constn}
其中annot是名字,exp是对应参数,而后面部分一些可选命名参数,没有顺序要求。
一些常用的annotation包括
- @deprecated
- @volatile
- @serializable
- @SerialVersionUID(1234) # 实际上就是相当为这个className定义UID,这样在反序列化的时候会进行检查
- @transient
- @unchecked # pm的时候不要考虑遗漏情况
2. 面向对象
2.1. 单例对象
单例对象很好地解决了Java的两个问题,一个是是单例模式没有集成到语言当中去导致代码编写冗余,一个是静态字段和静态方法嵌入在类定义中导致代码结构不清晰。下面是一段Java代码
/* coding:utf-8
* Copyright (C) dirlt
*/
public class Hello {
public static final kConstant = 10;
private static instance;
public static void init() {
instance = new Hello();
}
public static Hello getInstance() {
return instance;
}
public void method() {
}
}
而scala引入单例对象方式解决这个问题。单例对象使用object来定义,使用时候直接拿名称引用即可。
object Hello {
val kConstant = 10;
def method() {
}
}
Hello.method();
println(Hello.kConstant);
When a singleton object shares the same name with a class, it is called that class’s companion object. You must define both the class and its companion object in the same source file. The class is called the companion class of the singleton object. A class and its companion object can access each other’s private members. A singleton object that does not share the same name with a companion class is called a standalone object. You can use standalone objects for many purposes, including collecting related utility methods together, or defining an entry point to a Scala application.
如果定义了和这个单例对象名称相同的类的话,那么
- 这两个定义必须放在同一份文件
- 这个类称为这个单例对象的 共生类
- 这个单例对象称为这个类的 共生对象
共生对象和共生类可以相互访问private members
2.2. 构造函数
scala将构造函数和类定义合并,相比java方式更加简洁。下面是一段Java代码
/* coding:utf-8
* Copyright (C) dirlt
*/
public class Hello {
private int n;
private int d;
public Hello(int n,int d) {
this.n = n;
this.d = d;
}
public Hello(int n) {
this(n,0);
}
{
System.out.println("initializing...(" + n + "," + d + ")");
}
}
可以看到,实际上整个类的初始化是由两个部分来完成的,一个部分是构造函数部分,一个是类初始化执行代码。但是本质上它们都是为初始化类来服务的,或许我们就不应该将它们分开。此外构造函数重新赋值部分显得有点蹩脚,将传入的参数重新赋值到类内部字段上,略显得有点多余。
而下面是则是scala对应的代码
class Hello(pn: Int, pd: Int) {
private val n = pn;
private val d = pd;
println("initializing...(" + n + "," + d + ")");
def this(pn:Int) = this(pn,0);
}
scala将构造函数和初始化代码融合,只是使用初始化代码来作为构造函数,这样我们也不用在纠结到底是构造函数先执行还是初始化代码先执行。这个构造函数成为 primary constructor , 传入的参数称为 class parameters 注意这里parameters可以看做也是以val来定义的. 构造函数this(pn:Int)称为 auxiliary constructor .
对于大部分构造函数来说传入的参数都想留存一份下来。为此scala引入了 parametric fields 这个概念。只需要在class parameters上面稍作扩展即可
class Hello(private val pn: Int, private val pd: Int) {
println("initializing...(" + pn + "," + pd + ")");
def this(pn:Int) = this(pn,0);
}
在class parameter之前添加[private|protected|override] [val|var]即可,这样既定义了类构造函数参数也定义了对应的字段。scala访问修饰符只有private/protected,默认是public. The way you make members public in Scala is by not explicitly specifying any access modifier. Put another way, where you’d say “public” in Java, you simply say nothing in Scala. Public is Scala’s default access level. #note: 默认是public val
如果面向对象角度相比于java,上面这种方式确实简化不少。而scala本意应该是更想到达函数式类构造效果,构造生成对象称为 functional object . 我们之所以想保存这些参数是因为在编写java时候这些参数只能够在构造函数中获得,而在scala里面实际上在整个类里面都是可以获得的,因此对于上面情况来说我们根本没有必要保存这些类参数。在下面closure代码里面我们实际上可以直接引用pn,pd来参与计算。
class Hello(pn: Int, pd: Int) {
def n = pn
def d = pd
def closure(ratio:Float) = {
ratio * pn + pd;
}
}
val h = new Hello(2,1);
println(h.closure(2.0f));
2.3. override
scala提供了override这个关键字可以确保复写错误几率降低。对于java来说@Override这个注解是可选的,但是对于scala来说override关键字是必须的。如果B继承A复写其方法但是没有提供override关键字的话,就会出现编译错误,这样就强制要求在复写方法的时候提供override。一旦强制写override的话我们就能够发现一些我们原本希望复写某方法但是却没有复写的情况。
class Hello(pn: Int, pd: Int) {
def toString() = "n = " + pn + ", d = " + pd;
}
编译出现错误
/Users/dirlt/scala/Hello.scala:2: error: overriding method toString in class Object of type ()String;
method toString needs `override' modifier
def toString() = "n = " + pn + ", d = " + pd;
^
one error found
可以复写的不仅有方法也包括字段。字段复写相对来说就比较简单只是覆盖基类字段,但是也可能会影响到函数调用。
class Hello {
val x = 0;
def echoX() {
println(x);
}
}
class Hello2 extends Hello {
override val x = 1;
}
val x:Hello = new Hello2();
x.echoX(); // 1
2.4. 隐式转换
scala可以通过提供隐式转换函数来完成,函数需要添加关键字implicit作为前缀. 注意这个隐式转换函数必须放在类外部来定义。
class Hello(p:Int) {
private val x = p;
def op(h:Hello) {
println("op(" + x + "," + h.x + ")");
}
}
implicit def intToHello(x:Int) = {
println("do implicit conversion");
new Hello(x);
}
val h = new Hello(1);
h op 2;
Because im- plicit conversions are applied implicitly by the compiler, not explicitly writ- ten down in the source code, it can be non-obvious to client programmers what implicit conversions are being applied. 隐式转换这个东西还是尽量少用比较好。
关于隐式转换有下面几个通用规则 Implicit conversions are governed by the following general rules:
- Marking Rule: Only definitions marked implicit are available. 必须显示指明implicit.
- Scope Rule: An inserted implicit conversion must be in scope as a single identifier, or be associated with the source or target type of the conver- sion. 隐式转换函数必须能够以单个id来访问,或者是在转换类型共生对象内部有定义
- Non-Ambiguity Rule: An implicit conversion is only inserted if there is no other possible conversion to insert. 无歧义否则编译出现如下错误“implicit conversions are not applicable because they are ambiguous”
- One-at-a-time Rule: Only one implicit is tried. 只会尝试做一次隐式转换
- Explicits-First Rule: Whenever code type checks as it is written, no implicits are attempted. 如果类型匹配就不会做隐式转换
这里主要说说第2点,举个例子
class C(val x:Int) {
def op(c:C) {
}
}
object X {
implicit def intToC(x:Int) = new C(x)
}
// import X._
// works.
val x = new C(1)
x op 10
运行时候出现如下错误
/Users/dirlt/scala/Hello.scala:12: error: type mismatch;
found : Int(10)
required: this.C
x op 10
^
one error found
也就是说找不到隐式转换函数,因为隐式转换函数只能够以单个id存在,而现在需要使用X.intToC才能够使用。所以解决办法是import X._将intToC这个函数导入到外部。
存在一个特例,就是这个类型的共生对象(companion object)提供隐式转换函数也可以正常工作。
class C(val x:Int) {
def op(c:C) {
}
}
class D(val y:Int) {
}
object D {
implicit def D2C(d:D):C = {
println("called...");
new C(d.y)
}
}
val x = new C(1)
val y = new D(2)
x op y
隐式转换会发生在下面三个地方:
- conversions to an expected type,
- conversions of the receiver of a selection, and
可以理解为其中1是作用在operand上,而2是作用在receiver上。1这个类型转换过程相对比较好理解,2的话稍微有点麻烦,以下面为例
class A(val x:Int) {
def op(a:A) {
}
}
val a = new A(2)
1 op a
上面这段程序肯定是不能够成功的. 对于scala来说其实要找的隐式转换函数式这样的:“能够将int转换成为某个type, 这个type有op(A)这样的方法". 所以如果添加IntToA这样的隐式转换函数即可。
2.5. 隐式参数
关于隐式参数有点类似C++的缺省参数,但是从实现上来看还不太一样。scala的隐式参数实现和隐式转换有点类似,要求隐式参数必须能够使用单个id访问到。下面是使用隐式参数例子
def foo(x:Int)(implicit a:String,b:String) {
println(x + "," + a + "," + b);
}
implicit作用在后面所有的参数上,需要和explicit参数分开编写。
隐式参数的提供有点类似全局变量方式
implicit val defaultString:String = "hello" foo(1) // 1,hello,hello
这里需要注意的是,隐式参数的匹配不是靠名字而是靠类型来匹配的。又因为这个方式有点类似全局变量,所以隐式参数类型定义上一定要选择比较unique的,这样才不容易出现冲突。As a style rule, it is best to use a custom named type in the types of implicit parameters.
Note that when you use implicit on a parameter, then not only will the compiler try to supply that parameter with an implicit value, but the compiler will also use that parameter as an available implicit in the body of the method!
使用隐式参数的话,编译器不仅仅会在外部调用时候使用这个参数,在函数体内也会使用这个参数,以下面代码为例
def maxList[T](elements: List[T])
(implicit orderer: T => Ordered[T]): T =
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxList(rest) // (orderer) is implicit
if (x > maxRest) x // orderer(x) is implicit
else maxRest
}
函数体内部默认地都是用了两个隐式参数。但是注意在函数体内实际上这个隐式参数根本没有使用。
Because this pattern is common, Scala lets you leave out the name of this pa- rameter and shorten the method header by using a view bound. 因为这个模式非常通用,所以scala提出了一个 view bound (视界) . 上面代码可以写为
def maxList[T <% Ordered[T]](elements: List[T]): T = elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxList(rest) // (orderer) is implicit
if (x > maxRest) x // orderer(x) is implicit
else maxRest
}
这里对T做了view bound. You can think of “T <% Ordered[T]” as saying, “I can use any T, so long as T can be treated as an Ordered[T].” 也就是说T可以被认为是Ordered[T]这个类型传入,只要外部提供了T => Ordered[T]的隐式转换函数。 关于视界和边界(bound)差异可以看"bound(边界)"一节.
2.6. ()method
parameterless vs. empty-paren method. 对于函数来说如果没有任何参数的话,那么可以将()取消:
- def foo() = 1 // empty-paren
- def foo = 1 // parameterless
本质上这两者没有任何差别,但是在习惯上我们通常做出如下选择: 如果这个方法存在side-effect的话,那么选用foo()这种方式,否则选用foo方式
这样的选择有个好处就是可以统一method和field访问,使得代码更加简洁。考虑在Java经常需要编写getter方法导致冗长的代码
public class Hello {
private int n;
private int d;
public Hello(int n,int d) {
this.n = n;
this.d = d;
}
public int squareN() {
return n*n;
}
public int doubleD() {
return 2*d;
}
public static void usage() {
Hello h = new Hello(1,2);
h.squareN();
h.doubleD();
}
}
而scala代码相对简洁,并且访问squareN和doubleD更像是访问字段而不是在调用方法。
class Hello(private val n:Int,
private val d:Int) {
def squareN = n * n;
def doubleD = d * d;
}
val h = new Hello(1,2);
println(h.squareN)
println(h.doubleD)
2.7. 类型继承
使用extends关键字来继承,然后在继承的声明里面可以对父类做初始化。父类实例使用super来引用。
class A(n:Int) {
println("init A with n = " + n);
}
class B(n:Int) extends A(n) {
println("init B with n = " + n);
}
val b = new B(10);
抽象类中存在没有实现的方法(只给出声明),在class之前使用abstract关键字指示
abstract class Hello {
def echo()
}
抽象类不能够用来创建实例,类必须继承实现方法才能够创建实例。 注意对于字段和方法来说一定要给出定义,否则会认为是声明,这样就会产生抽象的字段和方法。
与抽象类相对应的是final类,这个类不能够再被继承。同时final字段还能够用在方法和字段上面这样可以不被override.
2.8. 类型层次
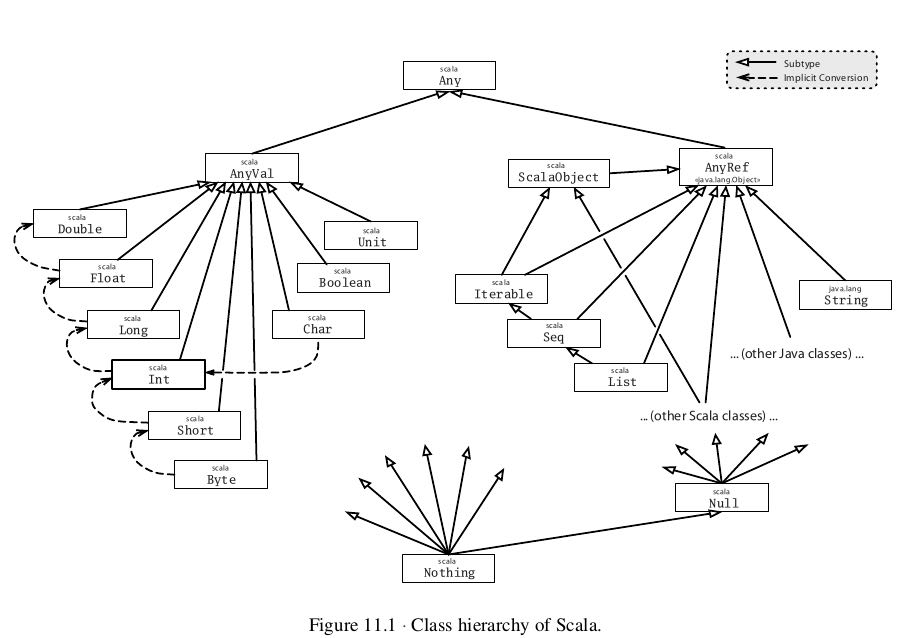
所有的基类是Any,定义了下面这些方法
final def ==(that: Any): Boolean final def !=(that: Any): Boolean def equals(that: Any): Boolean def hashCode: Int def toString: String
注意这里我们不需要实现==,!=,它们会调用equals这个方法,这个才是我们需要复写的。
The root class Any has two subclasses: AnyVal and AnyRef. AnyVal is the parent class of every built-in value class in Scala. There are nine such value classes: Byte, Short, Char, Int, Long, Float, Double, Boolean, and Unit. The first eight of these correspond to Java’s primitive types, and their values are represented at run time as Java’s primitive values. The instances of these classes are all written as literals in Scala. As mentioned previously, on the Java platform AnyRef is in fact just an alias for class java.lang.Object. So classes written in Java as well as classes written in Scala all inherit from AnyRef.
AnyVal是所有的内置类型基类,包括8种对应的java基本类型以及Unit(对应void类型),AnyRef是所有引用类型的基类。对于scala内置类型而言,值是通过字面量来创建的,也就是说不能够通过比如new Int这样的方法来创建,而Unit对应的value为(). 在JVM平台上面,AnyRef是Object的alias,但是如果可以的话尽可能地使用AnyRef而不要使用Object. 因为AnyRef上定义了eq和ne两个方法,所以只有引用类型才能够调用
Scala classes are different from Java classes in that they also inherit from a special marker trait called ScalaObject. The idea is that the ScalaObject contains methods that the Scala compiler defines and implements in order to make execution of Scala programs more efficient. Right now, Scala object contains a single method, named $tag, which is used internally to speed up pattern matching.
继承ScalaObject主要是用来加速pattern matching.
Class Null is the type of the null reference; it is a subclass of every reference class (i.e., every class that itself inherits from AnyRef). Type Nothing is at the very bottom of Scala’s class hierarchy; it is a sub- type of every other type. However, there exist no values of this type whatso-ever.
Null是所有引用类型的子类,其实例对象是null. 而Nothing是所有类型的子类,但是没有实例对象。对于Nothing没有实例对象需要了解Nothing的引入。Nothing引入是为了将异常融入类型系统的,比如下面scala代码
def error(message: String): Nothing = throw new RuntimeException(message)
定义了error这个函数来报告错误,然后我们在使用的时候
def divide(x: Int, y: Int): Int =
if (y != 0) x / y
else error("can't divide by zero")
我们必须确保类型能够统一,所以error类型必须和Int兼容,因此Nothing在设计上必须是所有类型的子类。
Option type能够很好地解决java里面null的问题. 举个例子我们在java里面处理map.get("hello")返回值的时候,都需要判断是否为null然后在做处理,否则可能会出现NullPointerException. 同样在scala里面,map.get("hello")返回一个Option对象,这个对象必然是一个有效的引用对象。对于一个Option对象而言:
- Some(x). 表示其value是x
- None. 表示缺失value.
可以通过模式匹配来判断是否为None以及获取value.
def show(x: Option[String]) = x match {
case Some(s) => s
case None => "?"
}
By contrast, Scala encourages the use of Option to indicate an optional value. This approach to optional values has several advantages over Java’s. First, it is far more obvious to readers of code that a variable whose type is Option[String] is an optional String than a variable of type String, which may sometimes be null. But most importantly, that programming error described earlier of using a variable that may be null without first checking it for null becomes in Scala a type error. If a variable is of type Option[String] and you try to use it as a String, your Scala program will not compile.
Option基本接口是这样的
trait Option[T] {
def isDefined: Boolean
def get: T
def getOrElse(t: T): T
}
2.9. Traits
所谓的traits就是特征,在面向对象里面就是指代这个类或者是这个对象的特征。scala trait和java interface非常相似,其引入都是为了解决多重继承的问题。 trait包含方法和字段,没有类参数(class parameter)和构造函数。(#note: 我觉得这点设计让trait回归到了本意,同时简化了设计和使用) trait的定义和class类似,mixin trait上也是通过关键字extends来完成的,如果需要mixin多个trait的话用with关键字
trait A {
def foo();
}
trait B {
def bar();
}
class C extends A with B {
def foo() {
println("foo");
}
def bar() {
println("bar");
}
}
trait的引入解决了一些多重继承的问题,最重要的问题就是如何解释super. 多重继承里面最麻烦的就是菱形继承问题A->B,A->C,B->D,C->D. 下面是一段C++代码
/* coding:utf-8 * Copyright (C) dirlt */ #include <cstdio> class A { public: void foo() { printf("A\n"); } }; class B:public A { public: void foo() { A::foo(); printf("B\n"); } }; class C:public A { public: void foo() { A::foo(); printf("C\n"); } }; class D:public B, public C { public: void foo() { B::foo(); C::foo(); printf("D\n"); } }; int main() { D d; d.foo(); return 0; }
这里D想调用A,B,C的foo各一次,但是最终调用了A两次。因为在C++里面允许多重继承没有super这个概念,所以只指定哪些父类,但是即使存在super这个概念也比较难以解决这个问题。比较难以解决这个问题的根本是,super这个parent-child关系是静态确定的,也就是说一旦出现菱形继承这样的情况,能够选择其中一条parent-child链执行。而如果语言能够在语言级别的层面上,根据当前继承关系动态地给出一个包含所有节点parent-child链的话,就可以解决这个问题。scala就是这个做法。
scala这种动态确定关系链的技术叫做linearization, 也就是将继承关系线性化得到一个linear order。以下面这个继承关系为例
class Animal trait Furry extends Animal trait HasLegs extends Animal trait FourLegged extends HasLegs class Cat extends Animal with Furry with FourLegged
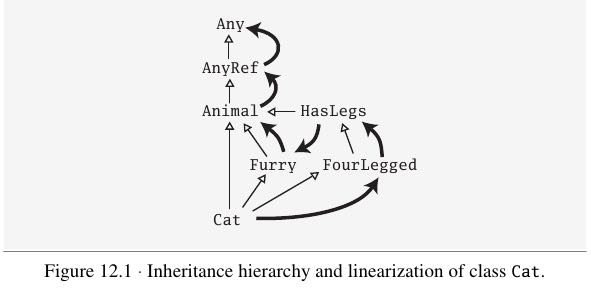
以Cat直接继承和混入类型, 从左向右分析
- Animal linear order = Animal -> AnyRef -> Any
- Flurry linear order = Furry -> Animal -> AnyRef -> Any
- FourLegged linear order = HasLegs -> Animal -> AnyRef -> Any
优先级别上1>2>3. 1和2结合结果为
- Furry -> Animal -> AnyRef -> Any
然后和3结合结果为
- FourLegged -> HasLegs -> Furry -> Animal -> AnyRef -> Any
所以最后的linear order为此,以此顺序调用super.
#note: 这种动态执行的效果就是,你不能够确定super到底是哪个,取决于context.
和java inteface一样,scala也允许构造匿名对象实现trait. 不过因为trait相比interface引入了字段,所以也引入了一些问题。这个问题主要是字段初始化顺序问题。下面是一个例子
trait A{
val a: Int;
val b: Int;
println("A..." + a + "," + b);
}
val b = new A {
val a = 1;
val b = 2;
println("B...");
}
上面这段代码里面,构造了一个匿名trait A的实现。但是注意运行的时候A在B之前初始化,也就是说虽然我们给了a,b定义,但是在执行到A初始化的时候,a,b实际上还是没有任何值的。对于这个问题scala给出了两种解决办法。
一种是显式地说在A初始化之前就给出值的定义,这种方式称为pre-initialized field.
trait A{
val a: Int;
val b: Int;
println("A..." + a + "," + b);
}
val b = new {
val a = 1;
val b = 2;
} with A;
另外一种是对值做惰性初始化,这种方式称为lazy-evaluation. 这种方式和定义函数非常类似,但是有个好处就是一旦初始化一次之后就不会再次evaluation.
trait A{
val a: Int;
val b: Int;
lazy val c = a;
lazy val d = b;
def say() {
println(c + "," + d);
}
}
val b = new A{
val a = 1;
val b = 2;
}
b.say
但是lazy不允许只有声明必须有定义,这个定义对应expression表示这个lazy value计算方式。
2.10. 访问权限
The way you make members public in Scala is by not explicitly specifying any access modifier. Put another way, where you’d say “public” in Java, you simply say nothing in Scala. Public is Scala’s default access level.
scala访问修饰符只有private/protected,默认是public. 访问权限上和java非常类似。
但是scala还提供了更细粒度的访问权限控制scope of protection. 也就是说访问权限是按照作用域来设置的。基本语法如下:
[private|protected][X]
A modifier of the form private[X] or protected[X] means that access is private or protected “up to” X, where X designates some enclosing package, class or singleton object. 可以用来修饰class, field, method. 其含义是private/protected属性最多作用到X以外,X以内均可以作为public来进行访问。 其中X还有一个特例就是this,那么标明这个字段只能够在这个实例里面访问。下面是一个例子。
class A(private val x:Int) {
def foo(o:A) {
println(x + o.x); // works.
}
}
class B(private[this] val x:Int) {
def foo(o:A) {
println(x + o.x); // can not access o.x
}
}
2.11. Enumeration
创建枚举类型非常简单.对于枚举类型来说通常都是单例所以直接使用object较多。You can find more information in the Scaladoc comments of class scala.Enumeration.
object X extends Enumeration {
val A,B,C = Value; // print as A,B,C
val E = Value("hello");
val F = Value("???"); // print as ???
}
Value这里是一个比较特殊的类型path-dependent type.所谓path-dependent type是指这个类型随着路径不同而不同。在X里面,那么Value type全称是X.Value, 这样就可以和其他枚举类型的Value区分开来。
scala提供的枚举类型也相对比较灵活,也可以很容易地访问整个枚举类型内部,也可以很容易地构造出枚举类型
for (a <- X) { // todo: seems don't work now!.
println(a)
}
val x = X(1) // easy construction.
println(x.id + "," + x)
val y = X(4)
println(y.id + "," + y)
3. 面向函数
3.1. 匿名函数
#note: aka. function literal
(<param1>:<type1>,<param2>:<type2>,...) => { <funciton-body> }
匿名函数不允许指定return-type,也就是说匿名函数必须通过type inference确定返回类型。
#note: 实际上匿名函数也可以指定return-type. 参考 http://stackoverflow.com/questions/2088524/is-it-possible-to-specify-an-anonymous-functions-return-type-in-scala
- syntax支持
- 匿名实例(因为所有函数都是继承Function这个类的)
val x = (x : Int) => { x + 1 } : Int
val y = new Function1[Int,Int] {
def apply(x:Int): Int = x + 1
}
#note@2013-11-04: 匿名函数也可以有下面的表达方式
{ (<param1>:<type1>,<param2>:<type2> ...) => <function-body> }
// if only one parameter
{ param: type => <function-body> }
相对上面的写法似乎更加漂亮
val c = { a:Int => a + 1 }
但是在某些特殊情况则不需要指定parameter-type, 因为parameter-type可以通过上下文推导出来。
val x = (0 to 4).filter((x:Int) => x > 2) val y = (0 to 4).filter(x => x > 2)
This is called target typing , because the targeted usage of an expression is allowed to influence the typing of that expression
使用placeholder syntax也可以构造一些简单的函数,_相当于一个函数参数占位符。但是因为_之间没有办法做区分,所以就函数功能来说非常有限。
val y = (0 to 4).filter(_ > 2) val f = (_:Int) + (_:Int) // (x:Int,y:Int) => x + y
3.2. 偏应用函数
偏应用函数(partially applied function)允许我们将部分参数作用在函数上形成特化函数。
def foo1(x:Int)(y:Int) = x + y def foo2(x:Int,y:Int) = x + y val pFoo1 = (y:Int) => foo1(1)(y) val pFoo2 = (y:Int) => foo2(1,y)
placeholder syntax提供了更简单的方法,并且_能够作为后续多个参数的占位符。
def foo1(x:Int)(y:Int) = x + y def foo2(x:Int,y:Int) = x + y // val pFoo1 = foo1(_) // also OK. val pFoo1 = foo1(1)(_) val pFoo2 = foo2(1,_:Int)
注意这里partial applied function和PartialFunction没有任何关系. partial applied function还是Function对象, PartialFunction是Function子类.
3.3. closure
function literal内部取值通常有三种:
- constant # 常量
- bound variable # 函数参数
- free variable # 外部变量
以下面两个function literal为例
- (x:Int) => x + 1 + y
- x as bound variable
- 1 as constant
- y as free variable
对于一个function literal来说的话,内部没有free variable的话,那么称为closed term. 否则称为open term.
open term因为free variable被captured住之后形成的function value称为closure. The resulting function value, which will contain a reference to the captured more variable, is called a closure, therefore, because the function value is the end product of the act of closing the open term.
注意 closure capture的不是variable的值而是variable本身 ,所以如果variable变化的话那么closure本身行为也是会变化的。
var y = 10 val foo = (x:Int) => x+y println(foo(1)) // 11 y = 0 println(foo(1)) // 1
3.4. 函数组合
- compose # f compose g = f(g(x))
- andThen # f andThen g = g(f(x))
def foo(x: Int) = x + 1
def bar(x: Int) = x * 2
val foo_bar = foo _ compose bar _ // foo(bar(x))
val bar_foo = foo _ andThen bar _ // bar(foo(x))
println("foo_bar(2) = " + foo_bar(2))
println("bar_foo(2) = " + bar_foo(2))
4. 面向泛型
静态类型的一个传统反对意见是,它有大量的语法开销。Scala通过类型推断(type inference)来缓解这个问题。在函数式编程语言中,类型推断的经典方法是 Hindley Milner算法,它最早是实现在ML中的。Scala类型推断系统的实现稍有不同,但本质类似:推断约束,并试图统一类型。
4.1. 类型参数化
scala将类型参数化的语法为C[T]. 但是和Java不同的是,scala必须指定类型参数。
scala底层使用jvm所以还是面临类型擦除的问题。下面是一段示例代码
class A[T] {
}
def foo(x: A[String]) {
}
def foo(x: A[Int]) {
}
对于上面这段程序,编译器会认为A[String]和A[Int]是相同的,所以不能够做函数重载
/Users/dirlt/scala/Hello.scala:7: error: double definition:
method foo:(x: this.A[Int])Unit and
method foo:(x: this.A[String])Unit at line 4
have same type after erasure: (x: A)Unit
def foo(x: A[Int]) {
scala对于类型参数化的检查也只是在compile阶段而非runtime阶段完成。不过相比java而言scala做了更多的工作。
4.2. variance(变性)
如果T1和T2存在某种关系的话,那么C[T1]和C[T2]之间存在的关系则称为C的variance. 对于Java和C++来说,C[T1]和C[T2]之间在编译期间是完全不兼容的类型,而scala则定义了三种关系:如果T1 extends T2的话
- C[T1] extends C[T2]的话,那么C是covariant.
- C[T2] extends C[T1]的话,那么C是contravariant.
- C[T1] 和 C[T2] 不兼容的话,那么C是nonvariant.
默认而言scala也是nonvariant的,也就是说对于C[Any]和C[T]之间是相互不兼容的。
| 含义 | Scala | 标记 |
|---|---|---|
| 协变covariant | C[T1]是 C[T2] 的子类 | [+T] |
| 逆变contravariant | C[T2] 是 C[T1]的子类 | [-T] |
| 不变invariant | C[T1] 和 C[T2]无关 | [T] |
这和Java则有点不同,Java class泛型可以不指定类型参数。
import java.util.*;
public class Hello {
public static void main(String[] args) {
Map<String,String> a = new HashMap<String,String>();
Map b = a;
}
}
上面代码是可以编译的,但是如果放在scala的话
class A[T] {
}
val x = new A[Int];
val y:A[Any] = x;
那么出现如下编译错误
/Users/dirlt/scala/Hello.scala:5: error: type mismatch;
found : this.A[Int]
required: this.A[Any]
Note: Int <: Any, but class A is invariant in type T.
You may wish to define T as +T instead. (SLS 4.5)
val y:A[Any] = x;
^
one error found
如果希望covariant的话,那么在定义时候形式如C[+T], 如果希望是contravariant的话,那么定义时候形式如C[-T].
class A[+T] {
}
val x = new A[Int];
val y:A[Any] = x;
#note: 初看contravariant似乎没有太大作用,后面会说到
当然出了改变variance之外,还能够像java一样做强制类型转换,通过asInstanceOf,isInstanceOf来操作
class A[T] {
}
val x = new A[Int];
val y:A[Any] = x.asInstanceOf[A[Any]];
为什么需要contravariant? 看这么一个例子
class A[+T] {
def foo(x:T) {
}
}
val x = new A[String];
val y:A[Any] = x;
y.foo("hello");
其实y是不允许调用"hello"的,我们的问题出在y=x和foo函数定义上。原因是因为A里面包含了一个foo方法需要传入参数T,而如果转换到更general类型的话,那么foo方法调用时候可能出现类型错误。 scala会在编译期间对潜在造成类型错误的操作做检查
这个问题如果仔细考虑的话会是这样的:对于传入参数而言要求类型应该是T的子类,而对于传出参数而言要求类型应该是T的超类。这样在转换到general类型的时候,才不会出现潜在类型错误。这也就是需要contravariant的原因。
class X
class Y extends X
class Z extends Y
class A[-P] {
def foo(x:P) {
}
}
val x = new A[X];
val y:A[Y] = x;
y.foo(new Y());
然后在看看Function1定义 trait Function1 [-T1, +R] extends AnyRef. 假设val foo : Function1[Int, Int] = { x => y }
- x类型必须是Int父类(或Int). 否则调用参数时, 传入一个Int子类, 那么{x=>y}内部是无法handle这个子类的.
- y类型必须是Int子类(或Int). 这样在返回对象上可以得到一个更加具体的类.
简单地总结就是, 对于参数使用逆变, 而返回值使用协变. 而容器类型通常都是协变的.
4.3. bound(边界)
这里的bound主要就是指泛型中的类型限定,其实类型限定这个东西还是因为提供了泛型类型上的类型层次系统导致的。以C++实现泛型来说就没有类型限定,因为类型参数都是duck-type,所有类型检查都是在编译阶段将代码展开来完成的,所以差别最主要的原因还是因为实现考虑和折中。bound语法如下:
- U >: T # U is required to be a supertype of T. upper bound
- U <: T # U is required to be a subtype of T. lower bound
def foo[T <: Ordered[T]](x:T,y:T) = x < y
class A (private val v:Int) extends Ordered[A] {
def compare(x: A) = v - x.v
}
val x = new A(10);
val y = new A(20);
println(foo(x,y));
println(foo(10,20)); // compile error.
和边界相似的概念是视界(view bound). 要求传入类型必须能够转到到某个要求类型. 使用%<来定义. 下面例子中就要求视界是Int.
def foo[A <% Int](x : A) = x + 123
println(foo(2))
implicit def strToInt(s: String) = s.toInt
println(foo("200"))
视界里面并不要求传入类型和要求类型存在任何继承关系, 只要求两个类型之间存在隐式转换. 视界在"隐式参数一节中也有提到"
5. 互操作性
- http://twitter.github.io/scala_school/zh_cn/coll2.html#java Java和Scala集合之间相互转换.
- http://twitter.github.io/scala_school/zh_cn/sbt.html 快速上手SBT
- http://twitter.github.io/scala_school/zh_cn/java.html Java + Scala
Scala is implemented as a translation to standard Java bytecodes. As much as possible, Scala features map directly onto the equivalent Java features. Scala classes, methods, strings, exceptions, for example, are all compiled to the same in Java bytecode as their Java counterparts. scala实现上是将代码翻译成为bytecode,并且这个映射大部分来说都是相对比较直接的
To make this happen required an occasional hard choice in the design of Scala. For example, it might have been nice to resolve overloaded methods at run time, using run-time types, rather than at compile time. Such a design would break with Java’s, however, making it much trickier to mesh Java and Scala. In this case, Scala stays with Java’s overloading resolution, and thus Scala methods and method calls can map directly to Java methods and method calls. 为此scala实现做了很多折中,比如将重载方法的解析放在了编译时期而非运行时期,但是这样换来的好处就是scala方法调用可以很直接地映射到java方法调用上。
For other features Scala has its own design. For example, traits have no equivalent in Java. Similarly, while both Scala and Java have generic types, the details of the two systems clash. For language features like these, Scala code cannot be mapped directly to a Java construct, so it must be encoded using some combination of the structures Java does have. 但是scala也有一些java没有的特性或者说存在冲突的特性,导致这些特性不能够直接映射到java结构上,而需要一些约定和组合办法来解决。
For these features that are mapped indirectly, the encoding is not fixed. There is an ongoing effort to make the translations as simple as possible, so by the time you read this, some details may be different than at the time of writing. You can find out what translation your current Scala compiler uses by examining the “.class” files with tools like javap. 但是对这些靠约定和组合的解决办法,并不保证固定可能在之后的版本发生变化,最可靠的办法还是使用javap来分析生成的class文件
5.1. simplest example
这个例子里面给出了 1. 类常量 2. 类变量 3. 类方法 4. 异常 使用方法
import scala.throws
import java.io.IOException
import scala.reflect.{BeanProperty, BooleanBeanProperty}
class TestCase[T](
@BeanProperty val x: Int,
@BeanProperty var y: T) { // 可以生成getter/setter方法
def run(z: Int) = x + z
@throws(classOf[IOException])
def except() {
throw new IOException("ioexception")
}
}
使用 `javap TestCase` 查看, 可以看到TestCase有哪些接口
➜ ~ javap TestCase
Compiled from "test.scala"
public class TestCase<T> {
public int x();
public T y();
public void y_$eq(T);
public void setY(T);
public int run(int);
public void except() throws java.io.IOException;
public int getX();
public T getY();
public TestCase(int, T);
}
5.2. singleton object
For every Scala singleton object, the compiler will create a Java class for the object with a dollar sign added to the end. For a singleton object named App, the compiler produces a Java class named App$. This class has all the methods and fields of the Scala singleton object. The Java class also has a single static field named MODULE$ to hold the one instance of the class that is created at run time.
对于singleton object而言,产生的类名是<class-name>$. 注意其中字段和方法都不是static的. 为了可以使用其中字段和方法, 这个类会创建一个实例MODULE$, 我们可以通过它来引用. 编译这个singleton object时候, 也会编译出对应的class. 如果class中重载了object中定义的函数, 那么就使用重新定义的函数, 否则使用object中函数(static).
object C {
def foo() {
System.out.println("C$::foo");
}
def bar() {
System.out.println("C$::bar");
}
}
class C {
def foo() {
System.out.println("C::foo");
}
}
`javap C$`
Compiled from "test2.scala"
public final class C$ {
public static final C$ MODULE$;
public static {};
public void foo();
public void bar();
}
`javap C`
Compiled from "test2.scala"
public class C {
public static void bar();
public void foo();
public C();
}
下面是Java使用例子
class UseTestCase {
public static void main(String[] args) {
C$.MODULE$.foo();
C$.MODULE$.bar();
C c = new C();
c.foo();
c.bar();
}
}
运行结果如下
➜ ~ java UseTestCase C$::foo C$::bar C::foo C$::bar
5.3. traits as interfaces
Implementing a trait in Java is another story. In the general case it is not practical. One special case is important, however. If you make a Scala trait that includes only abstract methods, then that trait will be translated directly to a Java interface, with no other code to worry about. Essentially this means that you can write a Java interface in Scala syntax if you like.
如果trait里面都只有抽象方法的话,那么直接翻译称为java interface. 而如果是其他情况的话则比较难处理。
trait TestCase {
def foo();
def bar();
}
编译出来的TestCase接口如下
➜ ~ javap TestCase
Compiled from "test.scala"
public interface TestCase {
public abstract void foo();
public abstract void bar();
}
5.4. annotation
- @deprecated
- @volatile # volatile修饰符
- @serializable # 实现java serializable接口
- @SerialVersionUID(1234L) # 增加字段 private final static long SerialVersionUID = 1234L
- @throws(classOf[IOException]) # scala默认不生成exception declaration. 但是如果使用此注解的话bytecode会声明抛出IOExceptin.
- jvm执行bytecode本身是不检查exception的,但是javac在编译时候会从bytecode从得到异常声明信息做检查
- @BeanProperty # 为var变量提供getter/setter接口
5.5. existential types
大部分Java类型在scala里面都有对应表示,但是对于一些特殊类型没有对应表示比如
- Iterator<?>
- Iterator<? extends Component>
Existential types are a fully supported part of the language, but in practice they are mainly used when accessing Java types from Scala.
语法格式如下
type forSome { declarations }
对于上面Java类型的话是
- Iterator[T] forSome { type T }
- Iterator[T] forSome { type T :< Component }
为了方便书写scala还引入了使用placeholder的简写
- Iterator[_]
- Iterator[_ :< Component ]
#note: 大部分时候使用不到,主要还是为了能够比较好理解compile error message