Real-Time Big Data Analytics: Emerging Architecture
Table of Contents
http://events.pentaho.com/Real-Time-Big-Data-Analytics.html
书相对简短,但是非常深刻地指出做realtime big data analytics需要面临的一些关键性问题,也给出了一些构建这样architecture现有可用的building blocks.
1. Introduction
- “Real-time big data isn’t just a process for storing petabytes or exabytes of data in a data warehouse,” says Michael Minelli, co-author of Big Data, Big Analytics. “It’s about the ability to make better decisions and take meaningful actions at the right time. It’s about detecting fraud while someone is swiping a credit card, or triggering an offer while a shopper is standing on a checkout line, or placing an ad on a website while someone is reading a specific article. It’s about combining and analyzing data so you can take the right action, at the right time, and at the right place.”(实时大数据分析本质是为了能够在合适的时间内做出更加合理的决策)
2. How Fast Is Fast?
3. How Real Is Real Time?
4. The RTBDA Stack
RTBDA = Real Time Big Data Analytics
David Smith writes a popular blog for Revolution Analytics on open source R, a programming language designed specifically for data an‐alytics. He proposes a four-layer RTBDA technology stack. Although his stack is geared for predictive analytics, it serves as a good general model:
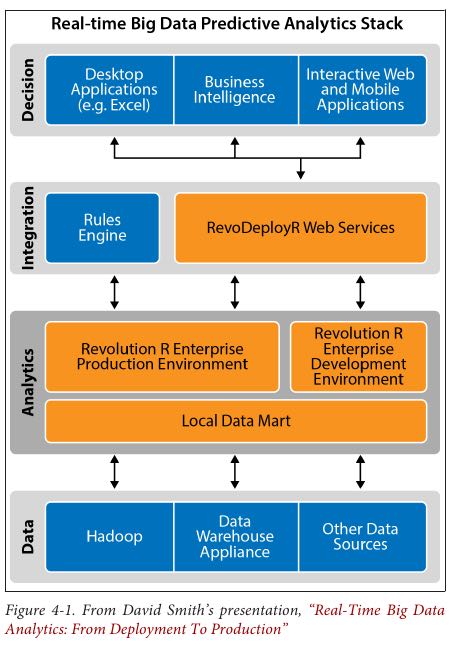
- At the foundation is the data layer. At this level you have structured data in an RDBMS, NoSQL, Hbase, or Impala; unstructured data in Hadoop MapReduce; streaming data from the web, social media, sen‐sors and operational systems; and limited capabilities for performing descriptive analytics. Tools such as Hive, HBase, Storm and Spark also sit at this layer. (Matei Zaharia suggests dividing the data layer into two layers, one for storage and the other for query processing) (data layer会做一些数据存储和预处理工作,可能比较偏批处理)
- The analytics layer sits above the data layer. The analytics layer in‐cludes a production environment for deploying real-time scoring and dynamic analytics; a development environment for building models; and a local data mart that is updated periodically from the data layer, situated near the analytics engine to improve performance.(analytics layer会做一些按照模型进行分析的工作,可能比较偏向实时。这里的local data mart我理解可能是类似RDBMS组件,定期从data layer load数据上来,访问这个local data mart非常快而且还支持随机访问等,当然也可能是Impala/Hive这样的东西数据依然存放在HDFS上)
- On top of the analytics layer is the integration layer. It is the “glue” that holds the end-user applications and analytics engines together, and it usually includes a rules engine or CEP engine, and an API for dynamic analytics that “brokers” communication between app developers and data scientists.(integration layer则是将分析数据按照规则和策略进行整合)
- The topmost layer is the decision layer. This is where the rubber meets the road, and it can include end-user applications such as desktop, mobile, and interactive web apps, as well as business intelligence soft‐ware. This is the layer that most people “see.” It’s the layer at which business analysts, c-suite executives, and customers interact with the real-time big data analytics system.(decision layer则是根据整合数据做出决策,需要提供一些可视化工具来辅助这个过程)
5. The Five Phases of Real Time
6. How Big Is Big?
- As suggested earlier, the “bigness” of big data depends on its location in the stack. At the data layer, it is not unusual to see petabytes and even exabytes of data. At the analytics layer, you’re more likely to en‐counter gigabytes and terabytes of refined data. By the time you reach the integration layer, you’re handling megabytes. At the decision layer, the data sets have dwindled down to kilobytes, and we’re measuring data less in terms of scale and more in terms of bandwidth.
- The takeaway is that the higher you go in the stack, the less data you need to manage. At the top of the stack, size is considerably less relevant than speed. Now we’re talking about real-time, and this is where it gets really interesting.
- stack上越高层的layer所需要处理的数据越少,这点是非常好理解的,因为到end-user这个层面对象通常就是human了,不像machine一样能够处理大量的数据,我们需要之是那些相对少量的能够用于决策的数据。
7. Part of a Larger Trend
- As information technology systems become less monolithic and more distributed, real-time big data analytics will become less exotic and more commonplace. The various technologies of data science will be industrialized, costs will fall and eventually real-time analytics will become a commodity.(实时大数据分析之后会变得非常平常,所需要的技术都会变得相对比较成熟以及工业化)
- At that point, the focus will shift from data science to the next logical frontier: decision science. “Even if you have the best real-time analyt‐ics, you won’t be competitive unless you empower the people in the organization to make the right decisions,” says Rajaram. “The creation of analytics and the consumption of analytics are two different things. You need processes for translating the analytics into good decisions. Right now, everyone thinks that analytics technology is sexy. But the real challenge isn’t transforming the technology — the real challenge is transforming the people and the processes. That’s the hard part.”(然后就会出现一个转变,从data science转变到decision science, 如何从通过data更好地做决策,这是一个流程而非技术上的转变,也是最困难的地方)