网络文章@202405
揭穿 5 个顽固的系统性能神话 - JabPerf Corp — Debunking 5 Stubborn Systems Performance Myths - JabPerf Corp
- Myth #5: Tool Expertise == Performance Expertise
- Myth #4: Memory Consumption Tracking Is Enough
- Myth #3: Sampling Profilers Work Great for Multithreaded Apps
- Myth #2: CPU Clock Speed Is Paramount
- Myth #1: Big O Complexity == Performance
这个场景挺有意思的。
// Enqueues the element `e`, a friend of element `f`, // into the queue `q`. void enqueue(israeli_queue * q, element * e, element * f);
用于磁盘支持数据库的 2Q 缓存算法 — 2Q-cache algorithm for disk-backed databases
2Q完整版比简化版,多出来了一个A1-out. 这个A1-out里面几乎不占用任何内存,只是为了用于记录引用。而A1-in既维护内存,也维护引用。
零行代码的 Linux 沙箱 — Sandboxing in Linux with zero lines of code
挺好的科普文章,介绍了seccomp是如何工作的,另外就是提供了针对静态和动态链接库程序介入seccomp的方法。
Meta 正在关闭 Workplace — Meta is shutting down Workplace
The saying "nobody ever got fired for buying IBM" is at its essence about risk management. The traditional wisdom goes that if you buy from a big company, you're going to be safe. It may be more expensive, but big companies project an image of stability and reliability, so buying their wares is seen as the prudent choice. Except, it isn't. Certainly not any more. Meta killing Workplace is merely exhibit #49667. “没有人会因为购买 IBM 而被解雇”这句话的本质是风险管理。传统观点认为,如果你从大公司购买产品,你就会安全。它可能更贵,但大公司给人一种稳定可靠的形象,因此购买他们的产品被视为谨慎的选择。但事实并非如此。当然不再是了。元杀戮工作场所只是展览#49667。
This, right here, is the risk of buying anything from big tech like Meta and Google. Their main ad-based cash cows are so fantastically profitable that whether it's the millions of paying accounts on Workplace or the millions of live websites once hosted by Google Domains, it all just pales in comparison, and is thus one strategy rotation away from being labeled "non-core" and killed off. 这就是从 Meta 和 Google 等大型科技公司购买任何产品的风险。他们主要的基于广告的摇钱树利润如此之高,以至于无论是 Workplace 上数以百万计的付费账户,还是 Google Domains 托管的数百万个实时网站,相比之下都相形见绌,因此只需一次策略轮换就可以被贴上标签。 “非核心”并被消灭。
Buying from big isn't the sure bet they want you to believe. Buy from someone who actually needs your business to make the wheels go round. 从大公司购买并不是他们希望你相信的可靠赌注。从真正需要您的业务来运转的人那里购买。
濒临常态化的状态 — The endangered state of normality
This is the natural consequence of "centering the margins". Of making it socially desirable to be not normal and low status to be regular. And it's happening across everything from gender expression to neurodiversity. There's cachet of cool to be had in identifying with some margin. Preferably one that can claim to be oppressed by society via heteronormativity or neurotypicality or other big words for "normal". 这是“边缘居中”的自然结果。让不正常的人成为社会所希望的,让正常人的地位低下成为社会所希望的。从性别表达到神经多样性,这一切都在发生。与一些边缘的认同是有酷感的。最好是一个可以通过异性恋或神经典型性或其他“正常”的大词声称受到社会压迫的人。
And, as Abigail Shrier documents in Bad Therapy, there's a large industry of therapists and other "mental health professionals" eager to accommodate this flight to the margins. Eager to supply the diagnosis, the pills, the reassurance of how every phase of experimentation or misbehavior can be explained by some big word of pathology. 而且,正如阿比盖尔·施里尔(Abigail Shrier)在《糟糕的治疗》(Bad Therapy)中所记录的那样,有一个由治疗师和其他“心理健康专业人士”组成的庞大行业渴望适应这种边缘化的趋势。渴望提供诊断、药物、保证实验的每个阶段或不当行为都可以用一些病理学的大词来解释。
开源既不是社区也不是民主 — Open source is neither a community nor a democracy
That's good! Yes, elitism is good, when it comes to open source. You absolutely want projects to be driven by the people who show up to do the work, demonstrate their superior dedication and competence, and are thus responsible for keeping the gift factory churning out new updates, features, and releases. Productive effort is the correct moral basis of power in these projects. 那挺好的!是的,在开源方面,精英主义是好的。您绝对希望项目由参与工作的人员来推动,展示他们卓越的奉献精神和能力,从而负责让礼品工厂不断推出新的更新、功能和版本。生产性努力是这些项目中权力的正确道德基础。
But this elitism is also the root of entitlement tension. What makes you think you're better than Me/Us/The Community in setting the direction for this project?? Wouldn't it be more fair, if we ran this on democratic consensus?? And it's hard to answer these question in a polite way that doesn't aggravate the tension or offend liberal sensibilities (in the broad historic sense of that word – not present political alignments). 但这种精英主义也是权利紧张的根源。是什么让您认为您比我/我们/社区更好地为该项目设定方向?如果我们在民主共识的基础上进行这件事,不是更公平吗?很难以一种礼貌的方式回答这些问题,同时又不会加剧紧张局势或冒犯自由主义的情感(在这个词的广泛历史意义上——不存在政治结盟)。
You can't solve that tension, only acknowledge it. I've dealt with it for literally twenty years with my work on Rails and a million other open source projects. There's an ever-latent instinct in a substantial subset of open source users who will continuously rear itself to question why it's the people who do the most work or deliver the most value or start the most projects that get to have the largest say. 你无法解决这种紧张,只能承认它。我在 Rails 和其他一百万个开源项目中处理这个问题已经有二十年了。相当多的开源用户有一种潜在的本能,他们会不断地质疑为什么那些做最多工作、交付最多价值或启动最多项目的人拥有最大的发言权。
And when people talk about open source burnout, it's often related to this entitlement syndrome. Although it's frequently misdiagnosed as a problem of compensation. As if begging for a few dollars would somehow make the entitlement problem bearable. I don't think it would. Programmers frequently turn to the joy of open source exactly because it exists outside the normal employment dynamics of quid-pro-quo. That's the relief. 当人们谈论开源倦怠时,通常与这种权利综合症有关。尽管它经常被误诊为补偿问题。好像乞讨几美元就能在某种程度上让权利问题变得可以忍受。我认为不会。程序员经常转向开源的乐趣,正是因为它存在于交换的正常就业动态之外。这就是解脱。
系统测试失败 — System tests have failed
The stickiest point, however, is not testing business logic, which model and controller tests do better and cheaper, but testing UI logic. Which means testing JavaScript. And I'll say I'm not sure we're there yet on the automated front. 然而,最棘手的一点不是测试业务逻辑,模型和控制器测试做得更好、更便宜,而是测试 UI 逻辑。这意味着测试 JavaScript。我想说的是,我不确定我们是否已经到达自动化前沿。
The method that gives me the most confidence that my UI logic is good to go is not system tests, but human tests. Literally clicking around in a real browser by hand. Because half the time UI testing is not just about "does it work" but also "does it feel right". No automation can tell you that. 让我最确信我的 UI 逻辑运行良好的方法不是系统测试,而是人工测试。从字面上看,是在真实的浏览器中手动单击。因为一半的时间 UI 测试不仅仅是“它是否有效”,而且是“它感觉是否正确”。没有自动化可以告诉你这一点。
HEY today has some 300-odd system tests. We're going through a grand review to cut that number way down. The sunk cost fallacy has kept us running this brittle, cumbersome suite for too long. Time to cut our losses, reduce system tests to a much smaller part of the confidence equation, and embrace the human element of system testing. Maybe one day we can hand that task over to AI, but as of today, I think we're better off dropping the automation. 嘿今天有大约 300 多个系统测试。我们正在进行一次重大审查,以减少这个数字。沉没成本谬论让我们长期运行这个脆弱、笨重的套件。是时候减少我们的损失,将系统测试减少到置信方程中更小的一部分,并接受系统测试的人为因素了。也许有一天我们可以将这项任务交给人工智能,但从今天开始,我认为我们最好放弃自动化。
No, the primary reason I appreciate aesthetics so much is its power to motivate. And motivation is the rare fuel that powers all the big leaps I've ever taken in my career and with my projects and products. It's not time, it's even attention. It's motivation. And I've found that nothing quite motivates me like using and creating beautiful things. 不,我如此欣赏美学的主要原因是它的激励力量。动力是一种稀有的燃料,它为我在职业生涯、项目和产品中所取得的所有重大飞跃提供动力。不是时间,甚至是注意力。这是动力。我发现没有什么比使用和创造美丽的东西更能激励我了。
I don't think that would come as any surprise to people of the past. The history of creation is in part a tale of pursuing beautiful outcomes and rewards. But in our age, we've managed to deconstruct and problematize so much of what is self-evidently beautiful that it's harder to take the chase for granted. 我认为这对于过去的人来说不会感到惊讶。创造的历史在某种程度上是一个追求美好结果和回报的故事。但在我们这个时代,我们已经成功地解构了许多不言而喻的美丽事物并提出了问题,因此很难将这种追逐视为理所当然。
And beauty isn't binary. It's the journey of a thousand little decisions and investments in making something marginally prettier than it was before. To resist the urge to just make it work, and not stop until you make it shine. Not for anyone else, even, although others will undoubtedly appreciate your care. But for yourself, your own motivation, and your own mission. 美并不是二元的。这是一个由一千个小决定和投资组成的旅程,目的是让东西比以前更漂亮。克制住让它发挥作用的冲动,不让它发光就不要停下来。甚至不适合其他任何人,尽管其他人无疑会感谢您的关心。但为了你自己,你自己的动力,你自己的使命。
SQLsmith: Randomized SQL testing in CockroachDB
CockroachDB如何使用SQLSmith来做测试,根据语法文件来产生可能的SQL表达式。
是不是可以在生成SQL表达式的时候,同时生成table定义;而不是先根据已有的table定义,去产生可以适配的SQL表达式。
Memory Management — Velox documentation
velox 如何进行内存管理的,我觉得框架还是很不错的,几个概念很重要:
- memory manager用来管理所有的内存申请
- query pool 是给每个query分配的
- 所以MM这里是可以看到每个query pool的使用的的(但是不一定看得到下面node pool/operator pool)
- 如果MM这边内存不够的话,那么就会使用memory arb来决定那个query pool需要进行释放
- query pool下面去寻找合适的operator pool去进行看那个operator可以spill出去
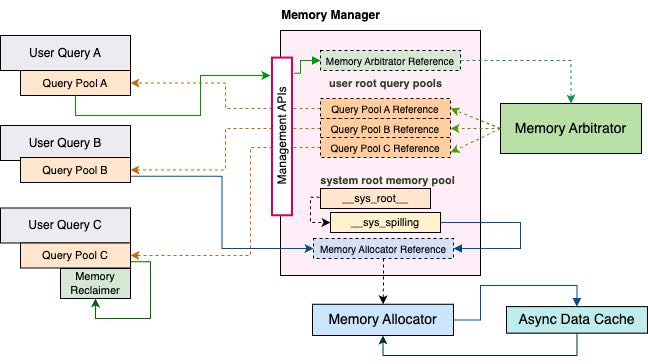
只有其中某些operator可以进行spill操作
Only spillable operators override that method: OrderBy, HashBuild, HashAggregation, RowNumber, TopNRowNumber, Window and TableWriter. As for now, we simply spill everything from the spillable operator’s row container to free up memory.
我如何提高自己的技能:r/dataengineering — How can I upskill myself : r/dataengineering
Plus there are not a lot of Senior Data Engineer from whom I can learn anything. I mean there are many people senior than me but its just that they are not that great. 另外,我能从中学到东西的高级数据工程师并不多。我的意思是,有很多人比我年长,但他们都没有那么伟大。
There is a really strong assumption that people become good from learning from other people. I think being able to teach yourself stuff is a far more important and valuable skill. 有一个非常强烈的假设,即人们通过向他人学习而变得优秀。我认为能够自学是一项更重要、更有价值的技能。
I am really trying to move to a company where I can grow with time and learn things from experience 我真的很想搬到一家可以随着时间成长并从经验中学习东西的公司
How often do you come up with new ideas which work and also benefit your current company? Asking because a lot of the time, people in a similar position to yourself will often say "I don't get to do anything exciting. I only get the boring jobs", expecting exciting work to come from up top. Interesting work is rarely handed out. In my experience, the limit really is down to how quickly and well an engineer/dev can complete their boring BAU work followed by their ability to create interesting solutions for problems. 您多久会提出一些既有效又有益于当前公司的新想法?之所以这么问,是因为很多时候,与你处境相似的人经常会说“我无法做任何令人兴奋的事情。我只做无聊的工作”,期待令人兴奋的工作来自高层。有趣的作品很少被分发出去。根据我的经验,限制实际上取决于工程师/开发人员能够多快、多好地完成他们无聊的 BAU 工作,以及他们为问题创建有趣的解决方案的能力。
In all this scenario how can I make a plan for 3-5 months so that I might be able to clear interviews while also learning things on the side to constantly upskill myself. 在这种情况下,我该如何制定3-5个月的计划,以便能够顺利通过面试,同时还能学习一些东西来不断提高自己的技能。
The assumption here is your problem is technical and you need guidance. Like most people who want to upskill, the problem is that all of this is in your head. 这里的假设是您的问题是技术性的,您需要指导。像大多数想要提高技能的人一样,问题是所有这些都在你的脑海中
============
I strongly suggest you focus on learning process oriented skills. For example: you may know how to create a data model but how to initiate that process, who will be the correct person to initiate the process, how to communicate with the business, proper documentation, governance. All these skills will help you get bigger roles. 我强烈建议你专注于学习面向过程的技能。例如:您可能知道如何创建数据模型,但知道如何启动该流程、谁是启动该流程的正确人选、如何与业务部门沟通、适当的文档、治理。所有这些技能将帮助您获得更大的角色。
Remember, the one who talks to the business will always get more money & power. 请记住,与企业交谈的人总是会获得更多的金钱和权力。
这个检测过程写的挺清楚的。CSV自动探测的价值也非常高,因为用户去搞清楚这个csv schema通常也比较麻烦,倾向于先读取上来然后做些处理。
No Memory? No Problem. External Aggregation in DuckDB – DuckDB
我的感觉就是整个memory chunk上粒度更小了,然后可以在更小的粒度上控制内存和磁盘交换。
《晚明》- 天命
文明不是书本,文明是代代相传的薪火,是潜移默化的自尊自信,是辉煌的艺术和文学,是汉武横扫大漠的雄风,是崖山蹈海的壮烈,是留发不留头的血性,没有了这些骄傲的人,何谈文明,哪一个国家的统治者能说出留头不留发,能说出宁与洋人不与家奴,能说出量中华物力博与国欢心这样的屁话,只有殖民者可以,殖民统治下的国家如何能奢谈文明。几百年后,又有几人会去从一堆故纸堆中看文明的辉煌
《晚明》- 军情
会议结束后,军官们全部起立敬礼,按次序退出会议室,陈新揉揉额头,他没有打算去大凌河,按原来历史上的情况,后金是摆明的围城打援,有了去年掳掠的人口,后金已经真正具有了战略优势,大凌河之战证明后金已经能保持较长时间的动员状态,其正在由兵民一体向职业军队转化。
他在辽西只认识孙承宗,与祖大寿这样的派系还关系十分恶劣,更重要的是关宁军大多是转进大师,自己跟他们一起去远征,等于和两个敌人打仗,建奴反而以逸待劳,任谁也不愿意去。
当然陈新不会告诉那些军官自己不愿去大凌河,战争为政治服务,但军人不能去热衷政治,所以他很多时候是选择性的讲,皇太极建立乌真超哈的目的之一是牵制满八旗,这类政治目的他就不会跟军官分析,以免他们想得太多,失去文登营一直保持着的质朴。
并发加载和查询 |雪花数据仓库博客 — Concurrent Load and Query | Snowflake Data Warehousing Blog
Warehouse来做工作负载的隔离,这种实现方式要求产品具有弹性伸缩能力,以及中央元数据系统。
来自我们的创始人 - 博客 — From Our Founders - Blog
If you were to build a database for data warehousing from scratch today, what would it look like? Here are the key principles it would need to address: 如果您今天要从头开始构建一个用于数据仓库的数据库,它会是什么样子?以下是它需要解决的关键原则:
- First of all, users–not data–should be the focus. Users should only have to put their data in and run queries to get value out; the system would do the rest and make this happen really fast. 首先,用户——而不是数据——应该成为焦点。用户只需将数据输入并运行查询即可获取价值;系统会完成剩下的工作并让这一切很快发生。
- It should be able to store all the data you want. It should provide unlimited storage capacity at such a low cost that no one would ever have to think again about throwing out data. 它应该能够存储您想要的所有数据。它应该以如此低的成本提供无限的存储容量,以至于没有人需要再考虑丢弃数据。
- It should be designed and optimized from the ground up to store and efficiently process any data in any shape, from pure relational structures like CSV to semi-structured such as JSON, Avro, and XML. 它应该从头开始设计和优化,以存储和有效处理任何形状的任何数据,从纯关系结构(如 CSV)到半结构化(如 JSON、Avro 和 XML)。
- It should deliver quick and easy access to all the relevant data inside and outside your organization. 它应该能够快速、轻松地访问组织内部和外部的所有相关数据。
- It should be truly elastic–able to grow, shrink and evolve its storage and compute resources as well as capacity to support concurrent users within minutes to adapt to any processing demand, even going all the way back to zero when no queries are running. That elasticity is critical to enabling you to scale up on down on the fly so that you can run diverse workloads concurrently without having them compete for resources. 它应该具有真正的弹性——能够在几分钟内增长、缩小和发展其存储和计算资源以及支持并发用户的能力,以适应任何处理需求,甚至在没有查询运行时完全回到零。这种弹性对于您能够动态扩展至关重要,这样您就可以同时运行不同的工作负载,而无需让它们争夺资源。
- Finally, the dream warehouse would always be available: no downtime, no data loss, fully accessible from anywhere, fully secure. All that with nothing to do on the administrator or user’s part: it would just happen. 最后,梦想的仓库将始终可用:无停机、无数据丢失、可从任何地方完全访问、完全安全。所有这一切与管理员或用户无关:它就会发生。
Many people hoped that Hadoop would be that revolution. By using “free” software and commodity hardware, it allowed easy and relatively cost-efficient storage as well as processing of vast amounts of data. But “free” comes with huge costs. Hadoop systems are often orders of magnitude less efficient than traditional warehouse systems. The interfaces are geared towards data specialists, leaving millions of users behind. And Hadoop is not a product, it’s an ecosystem, meaning it is both very complex and very expensive. And while more flexible, it is still restricted by the hardware that you use.
许多人希望 Hadoop 能够成为这场革命。通过使用“免费”软件和商用硬件,它可以轻松且相对经济高效地存储以及处理大量数据。但“免费”也伴随着巨大的成本。 Hadoop 系统的效率通常比传统仓库系统低几个数量级。这些界面面向数据专家,而将数百万用户抛在后面。 Hadoop 不是一个产品,而是一个生态系统,这意味着它非常复杂且非常昂贵。虽然更加灵活,但它仍然受到您使用的硬件的限制。
Snowflake Vision Emerges as Industry Benchmark - Blog
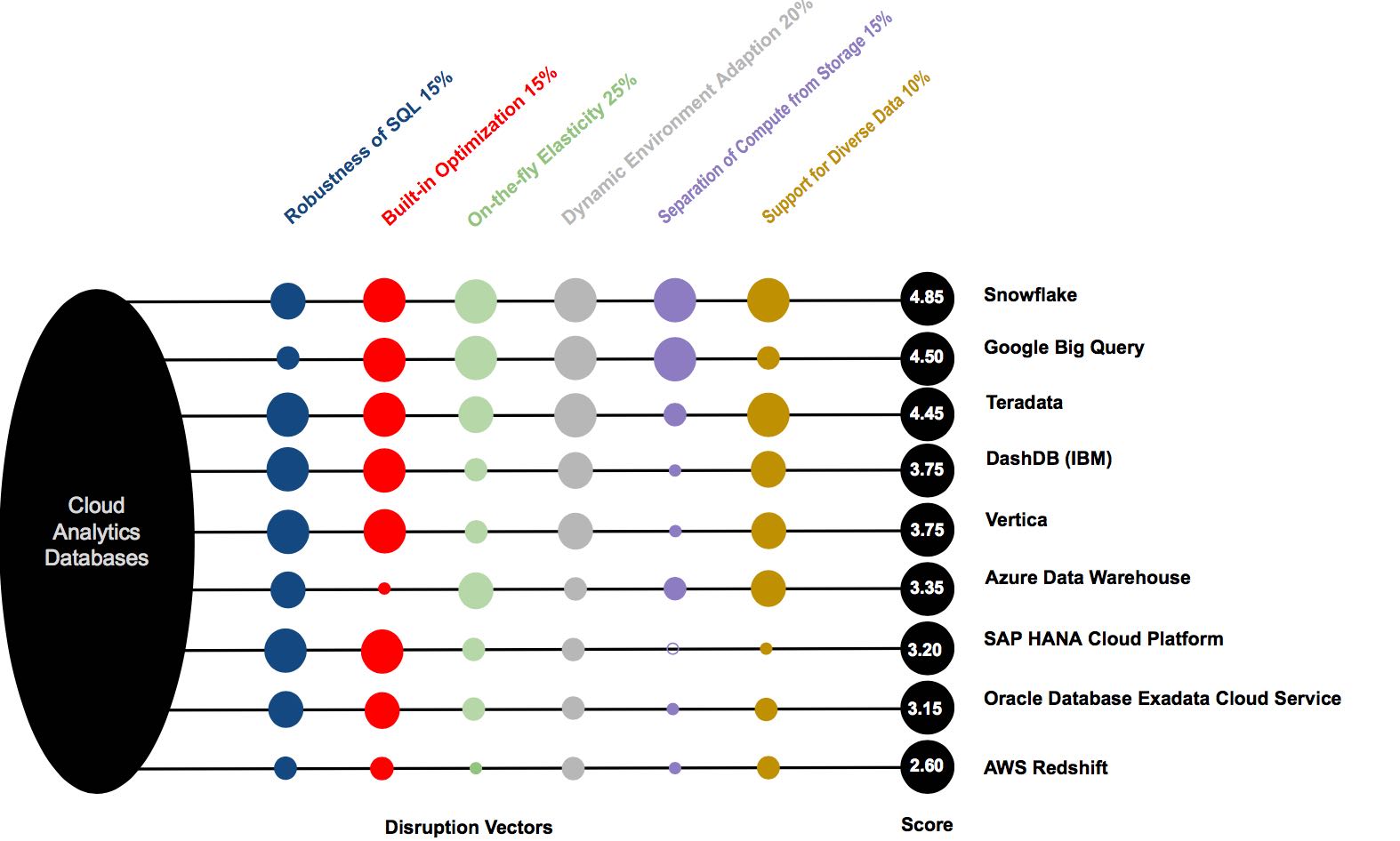
The six vectors we have identified are:
- Robustness of SQL
- Built-in optimization
- On-the-fly elasticity
- Dynamic Environment Adaption
- Separation of compute from storage
- Support for diverse data
行业基准和诚信竞争 - 博客 — Industry Benchmarks and Competing with Integrity - Blog
Twenty years ago, the game of leapfrogging benchmark results every few months was a priority for the database industry and both of us were on the front line fighting the benchmark war. Posted results kept getting better and new world records were being set on a regular basis. Most in the industry started adding configuration knobs, special settings, and very specific optimizations that would improve a benchmark by a fraction of a percent. Unfortunately, many such changes translated into additional complexity for customers and, worse, most of them had little or even negative impact on customers’ day-to-day workloads. The negative results compound: Development teams are distracted from focusing on what really matters to customers, and users are left underserved with more complex technology. Anyone who has been in the industry long enough can likely attest to the reality that the benchmark race became a distraction from building great products for customers. There is a reason why all the relevant players in the database industry, those that are running the majority of customer workloads, have largely stopped publishing new results.
二十年前,每隔几个月就超越基准测试结果的游戏是数据库行业的首要任务,我们都站在基准战的第一线。公布的成绩不断好转,新的世界纪录不断被创造。业内大多数人开始添加配置旋钮、特殊设置和非常具体的优化,这些优化可以将基准测试提高百分之几。不幸的是,许多此类变化给客户带来了额外的复杂性,更糟糕的是,大多数变化对客户的日常工作负载几乎没有影响,甚至产生负面影响。负面结果更加复杂:开发团队无法专注于对客户真正重要的事情,而更复杂的技术却无法为用户提供服务。任何在这个行业工作了足够长的时间的人都可以证明基准竞赛已经成为为客户打造优质产品的干扰因素。数据库行业的所有相关参与者(那些运行大部分客户工作负载的参与者)基本上停止发布新结果是有原因的。
明智地选择开放 - 博客 — Choosing Open Wisely - Blog
陷入手段与目的混淆的陷阱并不罕见。在某些情况下,目标是根据特定的预期结果设定的,随着时间的推移,目标的原因被遗忘,其追求本身就变成了目标,忘记了最初的目的。
We believe this is the case with the pursuit of “open” platforms in our industry. We see strong opinions for and against open, we see table pounding demanding open and chest pounding extolling open, often without much reflection on benefits versus downsides for the customers they serve. We hear mischaracterizations about the negative consequences of the alternatives. Some companies would want everyone to believe that open is what really matters whereas what matters is security, performance, costs, simplicity, and innovation. Using open should be at the service of these goals, not a goal unto itself at customers’ expense.
我们相信这就是我们行业追求“开放”平台的情况。我们看到支持和反对开放的强烈意见,我们看到敲桌子要求开放和拍胸赞扬开放,通常没有太多反思他们所服务的客户的好处和坏处。我们听到对替代方案负面后果的错误描述。一些公司希望每个人都相信开放才是真正重要的,而重要的是安全、性能、成本、简单性和创新。使用开放应该为这些目标服务,而不是以牺牲客户为代价来实现目标本身。
Where the discussion on file formats takes a turn for the worse is around the belief that those open formats are the optimal way to represent data during processing. To make things even worse, the belief expands to portraying direct file access as a key characteristic of a data platform. Supporters of the argument state that direct file access to standard formats is the best way to enable interoperability and prevent vendor lock-in. We disagree with this premise and, more importantly, history has precedents that have informed our perspective.
关于文件格式的讨论变得更糟的地方在于人们相信这些开放格式是在处理过程中表示数据的最佳方式。更糟糕的是,这种信念扩展到将直接文件访问描述为数据平台的关键特征。该论点的支持者指出,直接文件访问标准格式是实现互操作性和防止供应商锁定的最佳方式。我们不同意这个前提,更重要的是,历史有先例告诉我们观点。
At first glance, the idea of any data consumer or any application being able to directly access files in a standard, well-known format sounds appealing. Of course that is until a) the format needs to evolve, b) the data needs to be secured and governed, c) the data requires integrity and consistency, and/or d) the performance of the system needs to improve. What about an enhancement in the file format that enables better compression or better processing? How do we coordinate across all possible users and applications to understand the new format? Or what about a new security capability where data access depends on a broader context? How do we roll out a new privacy capability that reasons through a broader semantic understanding of the data to avoid re-identification of individuals? How do we ensure transactional integrity of data sets made by multiple applications? What about performance optimizations that can be achieved with additional information derived from the data files? Is it necessary to coordinate all possible users and applications to adopt these changes in lockstep? What happens if one of these is missed?
乍一看,任何数据消费者或任何应用程序都能够直接访问标准的、众所周知的格式的文件的想法听起来很有吸引力。当然,直到 a) 格式需要发展,b) 数据需要得到保护和管理,c) 数据需要完整性和一致性,和/或 d) 系统性能需要提高。是否可以增强文件格式以实现更好的压缩或更好的处理?我们如何协调所有可能的用户和应用程序以理解新格式?或者数据访问取决于更广泛的上下文的新安全功能怎么样?我们如何推出一种新的隐私功能,通过对数据更广泛的语义理解进行推理,以避免个人的重新识别?我们如何确保多个应用程序生成的数据集的事务完整性?通过从数据文件中获取的附加信息可以实现性能优化吗?是否有必要协调所有可能的用户和应用程序以同步采用这些更改?如果错过其中一项会发生什么?
We enjoy taking complex technology and simplifying it so our customers can spend the bulk of their time getting value out of data rather than managing infrastructure. We remain committed to open sourcing components that get deployed in customer premises or security perimeters, and to import and export open formats. We remain committed to standards-based APIs and programming models. Above all, we remain committed to continue to innovate, to continue to raise the bar of what’s possible, and to elevate standards for our industry with no other goal than increasing the data capability of our customers.
我们喜欢采用复杂的技术并将其简化,这样我们的客户就可以将大部分时间花在从数据中获取价值而不是管理基础设施上。我们仍然致力于开源部署在客户端或安全边界的组件,并导入和导出开放格式。我们仍然致力于基于标准的 API 和编程模型。最重要的是,我们仍然致力于继续创新,继续提高可能的标准,并提高我们行业的标准,除了提高客户的数据能力外没有其他目标。