Processing a Trillion Cells per Mouse Click
Table of Contents
http://vldb.org/pvldb/vol5/p1436_alexanderhall_vldb2012.pdf @ 2012
1. Abstract
2. Introduction
3. Basic Approach
As mentioned previously, the main advantage column-stores have over traditional row-wise storage, is that only a fraction of the data needs to be accessed when process-ing typical queries (accessing often only ten or less out of thousands of columns). Another important benefit is that columns compress better and therefore reduce the I/O and main memory usage. # 列式存储优势: 减少查询数据. 提高压缩比率, 进而减少IO和内存使用.
A common characteristic of these system is that they are in most cases highly optimized for efficient full scans of data. In data mining use cases, such as ours, the queries are too diverse for traditional indices being used effectively. The where clause can be free form, allowing to restrict on arbi-trary dimensions or even computated values (e.g., all web-searches that contain the term “cat”). As a rule of thumb, even in large database systems if more than a certain, often small percentage of the data is touched, a full scan is performed as opposed to using any indices. The obvious benefits being less random access I/O, simpler, easier to optimize inner loops, and very good cache local-ity. # 同时这些列式存储系统需要非常高效实现full-scan, 一个是因为传统索引可能比较稀疏, 另外一个是因为查询字段请求可以是任意form. 比如字段A包含"XXX", 这个很难通过有效的索引方式解决. 并且full-scan对于磁盘IO以及cache-locality更加友好.
The logical next step is to try to combine the benefits of an index data-structure (making it possible to skip data) with the power of full scans. This can be achieved by splitting the data into chunks during import and providing data-structures to quickly decide which chunks can be skipped at query processing time. # power-drill本质是列式存储, 同时通过partition分出多个chunk来减少full-scan的代价.
Partitioning the Data
Most modern database systems provide multiple options for partitioning tables, see (28) for an overview. In our case we perform a "composite range partitioning" (28) to split the data into chunks during the import. # 使用composite-range-partitioning方法来完成split.
Put simply, the user chooses an ordered set of fields which are used to split the data iteratively into smaller and smaller chunks. At the start the data is seen as one large chunk. Suc-cessively, the largest chunk is split into two (ideally evenly balanced) chunks. For such a split the chosen fields are con-sidered in the given order. The first field with at least two remaining distinct values is used to essentially do a range split, i.e., a set of ranges are chosen for the field which de-termine the first and the second chunk. The iteration is stopped once no chunk with more rows than a given thresh-old, e.g., 50’000, exists. # 开始只有一个chunk然后不断分裂. 因为我们有an ordered set of fields可供选择, 但是使用first field来确定是否需要split. 保持每个chunk的行数在50k. #note: 应该和bigtable/hbase分裂方案类似.
Principally, any other technique of splitting up the data would work as well. In the production system the data is also pre-split into shards as a first step." 分裂技术选择其实没有太大影响. 实际生产中也会预先分片而不是这种惰性分片.
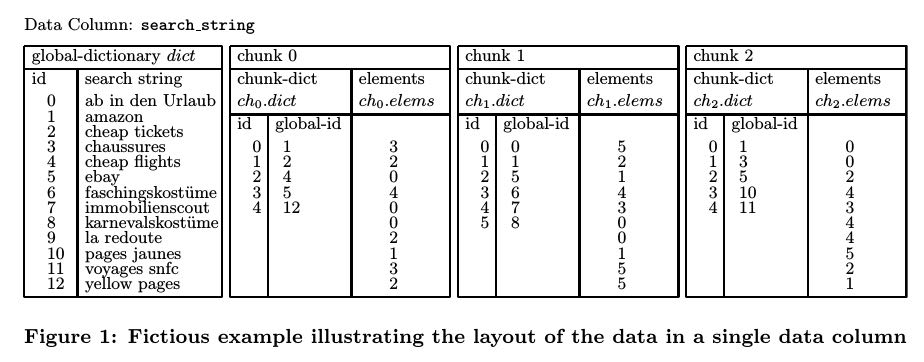
Basic Data-Structures
数据结构是这样的:
- global_dict: 有序地存储列上面所有可能值并且分配global_id.
- chunk#idx: 按照first field分裂出来的一个数据单元块. 作用是可以有效地减少full-scan所touch的数据量.
- chunk_dict: # chunk_id <-> global_id 映射(global_id有序). 增加这个映射有两个好处:
- 能够迅速了解当前chunk所有出现过的values.
- 将global_id映射成为值范围更小的chunk_id可以提高elements压缩比率.
- elements: # 和rows顺序相同. 表明这个row上的field对应的chunk_id.
- rows: # 整行的完整数据. 每个chunk应该只有一份. 这个数据应该存储在磁盘上.
- chunk_dict: # chunk_id <-> global_id 映射(global_id有序). 增加这个映射有两个好处:
除了rows这个部分, 其他所有数据应该都是存储在内存里面的.
4. Key Optimizations
减少memory_footprint, 这样系统可以将更多的chunk_metadata放入内存.
- Partitioning the Data into Chunks.
- Optimize Encoding of Elements in Columns.
- Optimize Global-Dictionaries. # keys have long common prefixes -> handcrafted trie tree.
- Generic Compression Algorithm. # Snappy 来压缩不常用的chunk部分.
- Reordering Rows.
5. Distributed Execution
6. Extensions
7. Performance in Production
Our productionized system is running on well over 1000 machines, the distributed servers altogether using over 4T of main memory. # 1k节点, 4T内存.
In a typical use case, a user triggers about 20 SQL queries with a single mouse click in the UI. On average these queries process data corresponsing to 782 billion cells from the un-derlying table in 30–40 seconds; under 2 seconds per query. An individual server on average spends less than 70 millisec-onds on a sub-query. These measurements and those given below are collected over all queries processed during the last three months of 2011. # 平均一个请求20 SQL queries, 30~40s处理完成, 每个请求时间在2s左右, 每个服务器上sub-query时间在70ms.
On average 92.41% of underlying records were skipped and 5.02% served from cached results, leaving only 2.66% to be scanned. # no. of records. 92.41%没有被touch, 5.02%直接被load(比如chunk所有rows都满足条件), 2.66%被scan.
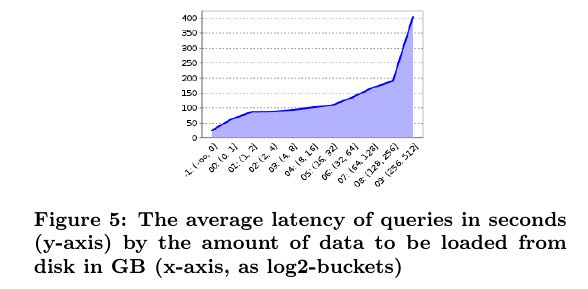
Another interesting question to ask is how many queries could be answered from data-structures which were in mem-ory. On average over 70% of the queries do not need to ac-cess any data from disk. They have an average latency of 25 seconds. 96.5% of the queries access only 1 GB or less (cumulative over all servers) of data on disk. The average latency naturally increases with the amount of data which needs to be read from disk into memory. # 70%请求不需要接触磁盘, 96.5%请求数据量在1GB以下. 平均影响时间在25s.