Pig Latin: A Not-So-Foreign Language for Data Processing
Table of Contents
- 1. ABSTRACT
- 2. INTRODUCTION
- 3. FEATURES AND MOTIVATION
- 4. PIG LATIN
- 5. IMPLEMENTATION
- 6. DEBUGGING ENVIRONMENT
- 7. USAGE SCENARIOS
- 8. RELATED WORK
- 9. FUTURE WORK
- 10. SUMMARY
http://research.yahoo.com/pub/2200 @ 2008
1. ABSTRACT
- We describe a new language called Pig Latin that we have designed to fit in a sweet spot between the declarative style of SQL, and the low-level, procedural style of map-reduce. The accompanying system, Pig, is fully implemented, and compiles Pig Latin into physical plans that are executed over Hadoop, an open-source, map-reduce implementation. 语言名称为Pig Latin, 系统为Pig. Pig Latin是在声明式的SQL和底层过程式的MR表达方式的折中。Pig将Pig Latin翻译成为physical plans也就是MapReduce.
2. INTRODUCTION
- These products however, can be prohibitively expensive at web scale. Besides, they wrench programmers away from their preferred method of analyzing data, namely writing imperative scripts or code, toward writing declara-tive queries in SQL, which they often find unnatural, and overly restrictive. 对于数据库系统来说很难达到web-scale,并且SQL不方便程序员来做数据分析
- What is appealing to programmers about this model is that there are only two high-level declarative primitives (map and reduce) to enable parallel processing, but the rest of the code, i.e., the map and reduce functions, can be written in any programming language of choice, and without worrying about parallelism. 程序员对于数据分析prefer的方式是,在高层使用声明式的原语可以并行化,而在底层可以使用过程式的语言来处理细节但是不必考虑并行问题。
- In effect, writing a Pig Latin program is similar to specify-ing a query execution plan (i.e., a dataflow graph), thereby making it easier for programmers to understand and control how their data processing task is executed.
- Pig Latin has several other unconventional features that are important for our setting of casual ad-hoc data analy-sis by programmers. These features include support for a flexible, fully nested data model, extensive support for user-defined functions, and the ability to operate over plain input files without any schema information. 提供了相当多的灵活性,比如嵌套数据模型,UDF,以及脱离schema信息依然那可以进行分析。
SQL
SELECT category, AVG(pagerank) FROM urls WHERE pagerank > 0.2 GROUP BY category HAVING COUNT(*) > 106
Pig Latin
good_urls = FILTER urls BY pagerank > 0.2; groups = GROUP good_urls BY category; big_groups = FILTER groups BY COUNT(good_urls)>106 ; output = FOREACH big_groups GENERATE category, AVG(good_urls.pagerank);
类比上可以考虑SQL有多层
- declarative language.
- logical plans.
- physical plans.
而Pig Latin相当于提供的是logical plans描述语言,但是这层描述语言非常thin.
3. FEATURES AND MOTIVATION
3.1. Dataflow Language
- Note that although Pig Latin programs supply an explicit sequence of operations, it is not necessary that the oper-ations be executed in that order. Pig并不一定按照pig latin操作顺序执行
3.2. Quick Start and Interoperability
- By operating over data residing in external files, and not taking over control over the data, Pig readily interoper-ates with other applications in the ecosystem. 相对于DBMS来说,Pig不需要导入数据这样的步骤,可以直接在数据上进行操作
- The reasons that conventional database systems do re-quire importing data into system-managed tables are three-fold: 传统DBMS需要导入数据主要是因为下面三个原因:
- to enable transactional consistency guarantees 系统满足ACID
- to enable effcient point lookups 索引等加快查找
- to curate the data on behalf of the user, and record the schema so that other users can make sense of the data. 设计schema修复数据
- Pig only supports read-only data analysis workloads, and those workloads tend to be scan-centric, so transactional consistency and index-based lookups are not required. Also, in our environment users often analyze a temporary data set for a day or two, and then discard it, so data curating and schema management can be overkill. #note: 感觉这点上Pig相比DBMS确实更加适合数据分析
- 数据都是read-only的,并且对于数据处理都只是scan而不需要point query. 因此ACID以及索引不需要
- 大部分的数据分析都只是处理有限次数,然后丢弃所以没有必要进行修复。 #note: 对于数据的修复完全可以跑一边MR处理,然后以后可以一直处理满足schema的数据
3.3. Nested Data Model
- There are several reasons why a nested model is more ap-propriate for our setting than 1NF: 1NF就是出现在数据库里面记录的存储方式,flatten data model
- A nested data model is closer to how programmers think, and consequently much more natural to them than nor- malization. 更加符合使用的习惯
- Data is often stored on disk in an inherently nested fash-ion. 这点主要和pig本身相关。因为pig/mapreduce都是操作磁盘上面的数据,并且没有import这个过程,因此格式上最好和磁盘上读取出来的数据格式接近。
- A nested data model also allows us to fulfill our goal of having an algebraic language (Section 2.1), where each step carries out only a single data transformation. 语言表达上就要求记录是nested data model比如按照某个non-atmoic field进行GROUP/FILTER等
- A nested data model allows programmers to easily write a rich set of user-defined functions, as shown in the next section.
3.4. UDFs as First-Class Citizens
- The input and output of UDFs in Pig Latin follow our flexible, fully nested data model. Consequently, a UDF to be used in Pig Latin can take non-atomic parameters as input, and also output non-atomic values. This flexibility is often very useful as shown by the following example.(UDF input/output 都是嵌套数据模)
3.5. Parallelism Required
- Consequently, we have only included in Pig Latin a small set of carefully chosen primitives that can be easily parallelized. Language primitives that do not lend them-selves to e cient parallel evaluation (e.g., non-equi-joins, correlated subqueries) have been deliberately excluded.(Pig在设计Pig Latin的时候确保primitives都是可以并行处理的,那些不能够并行处理的primitives都被排除)
3.6. Debugging Environment
4. PIG LATIN
4.1. Data Model
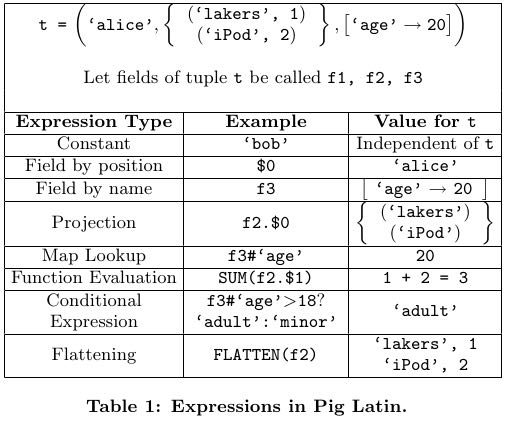
Pig has a rich, yet simple data model consisting of the following four types:
- Atom: An atom contains a simple atomic value such as a string or a number, e.g., ‘alice’.
- Tuple: A tuple is a sequence of fields, each of which can be any of the data types, e.g., (‘alice’, ‘lakers’).
- Bag: A bag is a collection of tuples with possible dupli-cates. The schema of the constituent tuples is flexible, not all tuples in a bag need to have the same number and type of fields,
- Map: A map is a collection of data items, where each item has an associated key through which it can be looked up. As with bags, the schema of the constituent data items is flexible, i.e., all the data items in the map need not be of the same type. However, the keys are re-quired to be data atoms, mainly for e ciency of lookups. (map的key必须是atomic的,但是value非常灵活)
4.2. Specifying Input Data: LOAD
queries = LOAD ‘query_log.txt’
USING myLoad()
AS (userId, queryString, timestamp);
- If no de-serializer is specified, a default one, that expects a plain text, tab-delimited file, is used. If no schema is specified, fields must be referred to by position instead of by name (e.g., $0 for the first field). 默认当作使用\t分开的text file载入,如果没有指定schema那么就需要使用position来进行访问
- The return value of a LOAD command is a handle to a bag which, in the above example, is assigned to the variable queries. 返回内容是bag
- No data is actually read, and no processing carried out, until the user explicitly asks for output. (see STORE command in Section 3.8).
4.3. Per-tuple Processing: FOREACH
expanded_queries = FOREACH queries GENERATE
userId, expandQuery(queryString);
expanded_queries = FOREACH queries GENERATE
userId, FLATTEN(expandQuery(queryString));
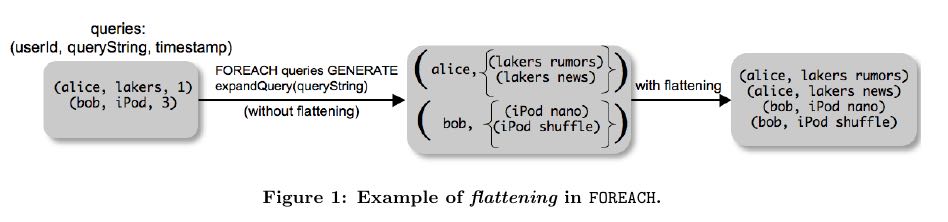
- One of the basic operations is that of applying some processing to every tuple of a data set. This is achieved through the FOREACH command. 遍历bag
- Flattening operates on bags by extracting the fields of the tuples in the bag, and making them fields of the tuple being output by GENERATE, thus removing one level of nesting. flatten将bags最近一层剥离,然后和GENERATE外面的fields做组合
4.4. Discarding Unwanted Data: FILTER
real_queries = FILTER queries BY userId neq ‘bot’;
- 过滤bag
4.5. Getting Related Data Together: COGROUP
grouped_data = COGROUP results BY queryString,
revenue BY queryString;
url_revenues = FOREACH grouped_data GENERATE
FLATTEN(distributeRevenue(results, revenue));
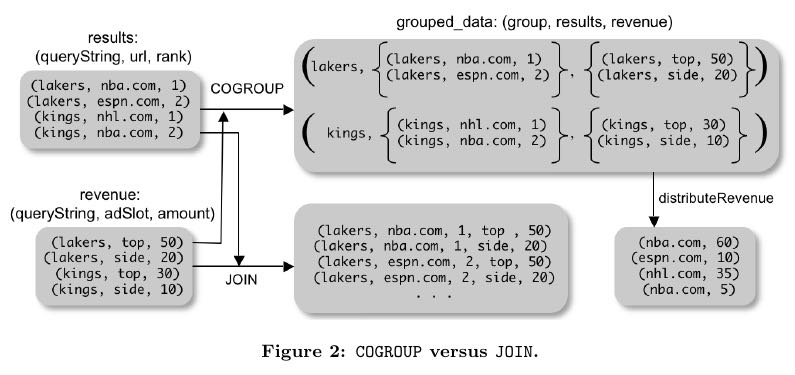
- In general, the output of a COGROUP contains one tuple for each group. 返回bag
- The first field of the tuple (named group) is the group identifier (in this case, the value of the queryString field). 第一个字段为group field,名字cogroup字段的名字 (或者是group吧?要是cogroup两个名字不同如何?)
- Each of the next fields is a bag, one for each input being cogrouped, and is named the same as the alias of that input. The ith bag contains all tuples from the ith input belonging to that group. 然后tuple里面可以直接使用cogroup来源名字来访问每个bag
4.5.1. Special Case of COGROUP: GROUP
grouped_revenue = GROUP revenue BY queryString;
query_revenues = FOREACH grouped_revenue GENERATE
queryString,
SUM(revenue.amount) AS totalRevenue;
- A common special case of COGROUP is when there is only one data set involved. In this case, we can use the alter-native, more intuitive keyword GROUP. COGROUP的特殊情况就是如果只有一路数据的话,那么可以使用GROUP
- #note: 这里的SUM可以操作bag. revenue.amount这里已经在revenue bag上面做了projection产生bag
4.5.2. JOIN in Pig Latin
join_result = JOIN results BY queryString, revenue BY queryString;
temp_var = COGROUP results BY queryString,
revenue BY queryString;
join_result = FOREACH temp_var GENERATE
FLATTEN(results), FLATTEN(revenue);
- JOIN可以通过COGROUP来完成,上面两个语句生成的效果是等价的
#note: 上面JOIN那个图输出结果是错误的,我们可以使用下面的例子做验证
---sample1.txt--- hello world dirlt ---sample2.txt--- hello love cjy
grunt> s1 = LOAD 'sample.txt' AS (key,v1,v2); grunt> s2 = LOAD 'sample2.txt' AS (key,v1,v2); grunt> s1 = LOAD 'sample1.txt' AS (key,v1,v2); grunt> sj = JOIN s1 BY key, s2 BY key; grunt> DUMP sj; (hello,world,dirlt,hello,love,cjy)
4.5.3. Map-Reduce in Pig Latin
4.6. Other Commands
Pig Latin has a number of other commands that are very similar to their SQL counterparts. These are:
- UNION: Returns the union of two or more bags.
- CROSS: Returns the cross product of two or more bags.
- ORDER: Orders a bag by the specified field(s).
- DISTINCT: Eliminates duplicate tuples in a bag. This command is just a shortcut for grouping the bag by all fields, and then projecting out the groups.
4.7. Nested Operations
grouped_revenue = GROUP revenue BY queryString;
query_revenues = FOREACH grouped_revenue{
top_slot = FILTER revenue BY
adSlot eq ‘top’;
GENERATE queryString,
SUM(top_slot.amount),
SUM(revenue.amount);
};
- When we have nested bags within tuples, either as a result of (co)grouping, or due to the base data being nested, we might want to harness the same power of Pig Latin to process even these nested bags 嵌套操作主要是为了嵌套bag服务的
- To allow such processing, Pig Latin allows some commands to be nested within a FOREACH command. At present, we only allow FILTER, ORDER, and DISTINCT to be nested within FOREACH. In the future, as need arises, we might allow other constructs to be nested as well. FOREACH 只是允许FOREACH上面做嵌套操作并且内部只能做一些比较简单的操作(#note: 这些操作都是可以在foreach对应的reduce时候附带上的而不需要额外操作)
4.8. Asking for Output: STORE
STORE query_revenues INTO ‘myoutput’
USING myStore();
- As with LOAD, the USING clause may be omitted for a default serializer that writes plain text, tab-delimited files.
5. IMPLEMENTATION
- Pig Latin is fully implemented by our system, Pig. Pig is architected to allow different systems to be plugged in as the execution platform for Pig Latin. Pig Latin底层可以转换成为多种任务执行,这个是可扩展和可定制的。
- Our current imple-mentation uses Hadoop , an open-source, scalable imple-mentation of map-reduce , as the execution platform. Pig Latin programs are compiled into map-reduce jobs, and exe-cuted using Hadoop. 现在实现是在Hadoop系统上。
- We first describe how Pig builds a logical plan for a Pig Latin program. 首先为Pig Latin构造logical plans.
- We then describe our current compiler, that compiles a logical plan into map-reduce jobs executed using Hadoop. 然后利用当前编译器将logical plans编译成为Hadoop MR
- Last, we describe how our implementation avoids large nested bags, and how it handles them if they do arise. 一些问题比如很大的嵌套bags
5.1. Building a Logical Plan
- the Pig interpreter first parses it, and verifies that the input files and bags be-ing referred to by the command are valid. 检查输入文件以及定义bag是否合法
- Pig builds a logical plan for every bag that the user defines. 针对输出bags来定义logical plan #note: 对于logical plan是和bag关联的,每个bag都会有一个产生这个bag的logical plan
- Note that no processing is carried out when the logical plans are constructed. Processing is triggered only when the user invokes a STORE command on a bag. At that point, the logical plan for that bag is compiled into a physical plan, and is executed. logical plan不会执行一直到出发STORE这个命令,然后在这个时候才会将logical plan编译成为physical plan然后执行
- This lazy style of execution is beneficial because it permits in-memory pipelining, and other opti-mizations such as filter reordering across multiple Pig Latin commands. 这种lazy style非常适合做in-memory pipelining来做optimization.
- Pig is architected such that the parsing of Pig Latin and the logical plan construction is independent of the execu-tion platform. Only the compilation of the logical plan into a physical plan depends on the specific execution platform chosen. (解析pig latin以及构造logical plan都是独立平台的,只有将logical plan转换成为physical plan是和平台相关的)
5.2. Map-Reduce Plan Compilation
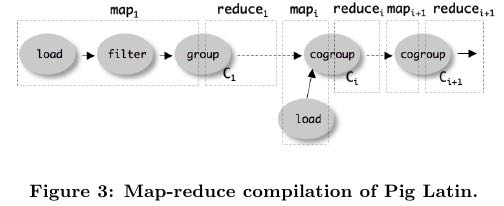
- The map-reduce primitive essentially provides the ability to do a large-scale group by, where the map tasks assign keys for grouping, and the reduce tasks process a group at a time. Our compiler begins by converting each (CO)GROUP command in the logical plan into a distinct map-reduce job with its own map and reduce functions.(以COGROUP为分界线,COGROUP的前部分使用map来处理,COGROUP的后部分使用reduce来处理)
- The map function for (CO)GROUP command C initially just assigns keys to tuples based on the BY clause(s) of C; the reduce function is initially a no-op. The map-reduce bound-ary is the cogroup command
- The sequence of FILTER, and FOREACH commands from the LOAD to the first COGROUP op-eration C1, are pushed into the map function corresponding to C1 (see Figure 3). 在第一个COGROUP之前的command都放在mapper完成
- The commands that intervene between subsequent COGROUP commands Ci and Ci+1 can be pushed into either (a) the reduce function corresponding to Ci, or (b) the map function corresponding to Ci+1. 在上一个COGROUP到下一个COGROUP之间都放在reduce里面完成。当然也可以放在下一个mapper里面完成
- Pig currently always follows option (a). Since grouping is often followed by aggregation, this approach reduces the amount of data that has to be materialized between map-reduce jobs. 但是现在使用第一种因为这样可以有效减少map-reduce物化结果
- The ORDER command is implemented by compiling into two map-reduce jobs. ORDER使用两个MR来完成
- The first job samples the input to determine quantiles of the sort key. 第一个阶段统计key的分布
- The second job range-partitions the input according to the quantiles (thereby en-suring roughly equal-sized partitions), followed by local sort-ing in the reduce phase, resulting in a globally sorted file. 第二个阶段按照key分布进行均分,然后在reduce phase进行排序 #note: 按照part-r-00000,part-r-00001这样排序的
- #note: 注意ORDER其实对于MR是没有影响的,只是对于最终output结果会有影响。如果ORDER没有对应的STORE的话,那么ORDER是可以不需要执行的
5.3. Efficiency With Nested Bags
- To cope with these cases, our implementation allows for nested bags to spill to disk. Our disk-resident bag implementation comes with database-style external sort algorithms to do operations such as sorting and duplicate elimination of the nested bags #note: nested operations里面支持ORDER BY以及DISTINCT操作。对于large nested bag需要spill到磁盘上,并且Pig有专门为在磁盘存储bag的实现,这种实现允许在上面有效地做sort和distinct操作