Large-scale Incremental Processing Using Distributed Transactions and Notifications
Table of Contents
http://research.google.com/pubs/pub36726.html @ 2010
1. Abstract
- Updating an index of the web as documents are crawled requires continuously transforming a large repository of existing documents as new documents ar-rive. This task is one example of a class of data pro-cessing tasks that transform a large repository of data via small, independent mutations. These tasks lie in a gap between the capabilities of existing infrastructure.(主要解决的问题就是,在非常大的base repository上面有少量的mutation应该如何进行处理?就现有的基础设施并没有很好地解决这个问题)
- Databases do not meet the storage or throughput require-ments of these tasks: Google’s indexing system stores tens of petabytes of data and processes billions of up-dates per day on thousands of machines. (存储大小以及吞吐量并不适合使用db。g的索引系统存储了pb级别的数据,并且每天需要在上千机器上面完成处理工作)
- MapReduce and other batch-processing systems cannot process small up-dates individually as they rely on creating large batches for efficiency.(而mapreduce属于批处理系统,不能够单独处理这些小的更新)
- We have built Percolator, a system for incrementally processing updates to a large data set, and deployed it to create the Google web search index. (percolator能够处理大数据集合下面的增量修改,并且现在已经使用在google的搜索引擎上面了)
- By replacing a batch-based indexing system with an indexing system based on incremental processing using Percolator, we process the same number of documents per day, while reducing the average age of documents in Google search results by 50%.(每天处理相同量数据的documents,但是每个文档的平均年龄减少了50%。这个平均年龄应该是指从crawl下来到进入index system的时间?) #todo: 每天能够处理相同数据的文档,为什么年龄会减少呢?
2. Introduction
- Consider the task of building an index of the web that can be used to answer search queries. The indexing sys- tem starts by crawling every page on the web and pro- cessing them while maintaining a set of invariants on the index.(在indexing system里需要维护索引一些不变量)
- It’s easy to maintain invariants since MapReduce limits the paral-lelism of the computation; all documents finish one pro-cessing step before starting the next. (这种不变量的维护使用mapreduce非常好解决,因为mapreduce是一种顺序处理的模型,通过一系列mapreduce串联在一起可以解决这个问题)
- It’s not sufficient to run the MapReduces over just the new pages since, for example, there are links between the new pages and the rest of the web. The MapReduces must be run again over the entire repository, that is, over both the new pages and the old pages.(但是mapreduce不能够处理增量的页面,而必须重新处理整个repository)
- Given enough computing resources, MapReduce’s scalability makes this approach feasible, and, in fact, Google’s web search index was produced in this way prior to the work described here. However, reprocessing the entire web discards the work done in earlier runs and makes latency proportional to the size of the repository, rather than the size of an update.(虽然在google里面mapreduce的规模足够处理按照上面的方式进行运行,并且事实上google之前就是这么完成的。但是重新运行整个repo相当于将原来的工作直接丢弃,并且运行时间和整个repo成比例)
- The indexing system could store the repository in a DBMS and update individual documents while using transactions to maintain invariants. However, existing DBMSs can’t handle the sheer volume of data: Google’s indexing system stores tens of petabytes across thou-sands of machines .(可以将repo存放在dbms里面然后使用事务来保证不变量,但是dbms不能够承受住google的PB规模的数据)
- Distributed storage systems like Bigtable can scale to the size of our repository but don’t provide tools to help programmers maintain data invariants in the face of concurrent updates.(而bigtable虽然可以扩展到支撑这些数据,但是却没有提供功能来维护不变量)
- An ideal data processing system for the task of main-taining the web search index would be optimized for in-cremental processing; (我们需要的就是一个增量处理系统)
- that is, it would allow us to main-tain a very large repository of documents and update it efficiently as each new document was crawled.
- Given that the system will be processing many small updates concurrently, an ideal system would also provide mech- anisms for maintaining invariants despite concurrent up-dates and for keeping track of which updates have been processed.(对于这个增量系统需要提供的机制包括下面两个,这也是percolator主要关注的两个方面:1)提供机制来维护不变量 2)能够追踪那些updates已经被处理过)
The remainder of this paper describes a particular in-cremental processing system: Percolator.
- Percolator pro-vides the user with random access to a multi-PB reposi-tory. Random access allows us to process documents in-dividually, avoiding the global scans of the repository that MapReduce requires. To achieve high throughput, many threads on many machines need to transform the repository concurrently, so Percolator provides ACID-compliant transactions to make it easier for programmers to reason about the state of the repository; we currently implement snapshot isolation semantics.(提供随即访问PB级别repo的能力,允许对数据进行随机访问。为了达到高并发在多个机器上面使用多个线程同时对repo进行更新,因此percolator也提供了ACID兼容的事务实现来满足维持不变量这个需求,事务实现是snapshot isolation的语义)
- In addition to reasoning about concurrency, program-mers of an incremental system need to keep track of the state of the incremental computation. To assist them in this task, Percolator provides observers: pieces of code that are invoked by the system whenever a user-specified column changes. Percolator applications are structured as a series of observers; each observer completes a task and creates more work for “downstream” observers by writing to the table. An external process triggers the first observer in the chain by writing initial data into the table.(为了能够追踪到哪些修改,percolator提供了observer,就是event-driven意思。percolator提供会监控哪些cell存在变化,如果存在变化就会调用关注这些cell的observer。这种效应是会不断触发的。而第一个触发通常是通过外部程序修改table来启动的)
- Percolator was built specifically for incremental pro-cessing and is not intended to supplant existing solutions for most data processing tasks. Computations where the result can’t be broken down into small updates (sorting a file, for example) are better handled by MapReduce. Also, the computation should have strong consistency requirements; otherwise, Bigtable is sufficient. Finally, the computation should be very large in some dimen-sion (total data size, CPU required for transformation, etc.); smaller computations not suited to MapReduce or Bigtable can be handled by traditional DBMSs.(percolator并不是要代替现有一些数据处理解决方案。如果计算不能够拆分成为小的update的话那么最好依然使用MR来完成,如果计算不要求强一致性的话那么使用bigtable来作为存储也是足够的,如果计算规模本身就不大的话那么使用传统的DBMS也是可以搞定的)
- Since cleanup is synchronized on the primary lock, it is safe to clean up locks held by live clients; however, this incurs a performance penalty since rollback forces the transaction to abort. So, a transaction will not clean up a lock unless it suspects that a lock belongs to a dead or stuck worker.(对于一个cleanup lock来说,我们必须判断造成这个lock存在的事务是否还在,如果这个事务属于一个已经挂掉的worker的话,那么就可以开始做cleanup lock的工作了)
- Percolator uses simple mechanisms to determine the liveness of another transaction. Running workers write a token into the Chubby lockservice to indicate they belong to the system; other workers can use the existence of this token as a sign that the worker is alive (the token is automatically deleted when the process exits). (percolator使用一种简单的方法判断事务是否存在,对于每个worker上面启动的事务来说,应该都会在chubby上面记录。同时每个worker也会在上面获得一个session)
- To handle a worker that is live, but not working, we additionally write the wall time into the lock; a lock that contains a too-old wall time will be cleaned up even if the worker’s liveness token is valid. To handle long- running commit operations, workers periodically update this wall time while committing.(为了防止worker只是live但是没有working,worker会每隔一段时间修改自己的active time,证明自己是在working的。判断某个事务由那个worker发起,同时判断这个worker是否在working,就可以判断这个transaction是否有效)
3. Design
- Percolator provides two main abstractions for per-forming incremental processing at large scale: (为增量处理提供了两种抽象)
- ACID transactions over a random-access repository and (在随机访问的repo上面提供了满足ACID的事务)
- ob-servers, a way to organize an incremental computation.(用来组织增量计算的observer)
- A Percolator system consists of three binaries that run on every machine in the cluster: a Percolator worker, a Bigtable tablet server, and a GFS chunkserver.(在每个计算机器上面都会运行percolator worker,worker是application但是底层使用了percolator library)
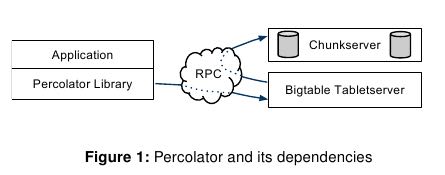
- The system also depends on two small services: the timestamp oracle and the lightweight lock service. The timestamp oracle pro-vides strictly increasing timestamps: a property required for correct operation of the snapshot isolation protocol. Workers use the lightweight lock service to make the search for dirty notifications more efficient.(系统还依赖两个service,timestamp oracle以及lock service)
- timestamp oracle主要就是为了提供timestamp snapshot isolation保证的,分配递增的timestamp
- lock service能够更有效地让查找dirty cell(所谓dirty cell就是说那些修改了但是却没有调用对应的observer的cell)
- The design of Percolator was influenced by the re-quirement to run at massive scales and the lack of a requirement for extremely low latency. (percolator设计需求是为了能够在大规模的机器上面运行但是不用考虑过低的延迟)
- Relaxed latency requirements let us take, for example, a lazy approach to cleaning up locks left behind by transactions running on failed machines. This lazy, simple-to-implement ap-proach potentially delays transaction commit by tens of seconds. (对于延迟的放松可以使得使用一种lazy的方式来清理之前失败的事务,通常会导致其他事务延迟分钟左右)
- This delay would not be acceptable in a DBMS running OLTP tasks, but it is tolerable in an incremental processing system building an index of the web.(这种延迟对于在DBMS上面运行OLTP的人物是不能够接受的)
- Percola-tor has no central location for transaction management; in particular, it lacks a global deadlock detector. This in-creases the latency of conflicting transactions but allows the system to scale to thousands of machines.(percolator没有中央位置来管理事务,尤其是没有全局死锁检测器,但是这种设计可以扩展到上千台机器)
3.1. Bigtable overview
percolator API封装了对于bigtable的访问,但是和bigtable api非常类似。封装主要原因一方面是底层可以更好地优化bigtable访问模式,另外主要的一方面是为了能够在bigtable上面实现multirow transactions,通过在原来的table schema上面增加了几个辅助的column:
| Column | Use |
|---|---|
| c:lock | An uncommitted transaction is writing this cell; contains the location of primary lock |
| c:write | Committed data present; stores the Bigtable timestamp of the data |
| c:data | Stores the data itself |
| c:notify | Hint: observers may need to run |
| c:ack O | Observer “O” has run ; stores start timestamp of successful last run |
这里稍微提前解释一下每个column的含义:(这个后面在阅读到percolator transaction pseudo code时候就会理解)
- lock // 哪个writer拿到了这个cell的lock
- write // 写入数据的时间(和bigtable本身提供的timestamp区分开)
- date // 写入的数据
- notify // 这个cell是否已经ditry,是否需要运行对应的observer
- ack_O // observer O上次成功运行的时间
3.2. Transactions
下面是使用percolator transactions功能一个example code
bool UpdateDocument(Document doc) { Transaction t(&cluster); t.Set(doc.url(), "contents", "document", doc.contents()); int hash = Hash(doc.contents()); // dups table maps hash → canonical URL string canonical; if (!t.Get(hash, "canonical-url", "dups", &canonical)) { // No canonical yet; write myself in t.Set(hash, "canonical-url", "dups", doc.url()); } // else this document already exists, ignore new copy return t.Commit(); }
还是非常简洁的,事务都是通过Transaction封装,只有三个简单的方法Get/Set/Commit。这里的Set并不会立刻写table,而是在Commit时候才会发起真正的写,这个在使用的时候需要注意。
关于snapshot isolation wikipedia上有专门的页面介绍 Snapshot isolation - Wikipedia, the free encyclopedia http://en.wikipedia.org/wiki/Snapshot_isolation
In databases, and transaction processing (transaction management), snapshot isolation is a guarantee that all reads made in a transaction will see a consistent snapshot of the database (in practice it reads the last committed values that existed at the time it started), and the transaction itself will successfully commit only if no updates it has made conflict with any concurrent updates made since that snapshot.
所谓snapshot isolation就是事务能够读取到某个database snapshot的数据,并且这个事务能够成功提交如果在这个事务处理的时候,没有其他事务同时或者是已经更新了这个事务将要修改的数据。
The main reason for its adoption is that it allows better performance than serializability, yet still avoids most of the concurrency anomalies that serializability avoids (but not always all). In practice snapshot isolation is implemented within multiversion concurrency control (MVCC), where generational values of each data item (versions) are maintained: MVCC is a common way to increase concurrency and performance by generating a new version of a database object each time the object is written, and allowing transactions' read operations of several last relevant versions (of each object).
采用snapshot isolation而不是serialiability,是因为使用这种方法可以获得更好的读性能,并且避免了大部分并发异常,通常使用MVCC来实现。
In a write skew anomaly, two transactions (T1 and T2) concurrently read an overlapping data set (e.g. values V1 and V2), concurrently make disjoint updates (e.g. T1 updates V1, T2 updates V2), and finally concurrently commit, neither having seen the update performed by the other. Were the system serializable, such an anomaly would be impossible, as either T1 or T2 would have to occur "first", and be visible to the other. In contrast, snapshot isolation permits write skew anomalies.
As a concrete example, imagine V1 and V2 are two balances held by a single person, Phil. The bank will allow either V1 or V2 to run a deficit, provided the total held in both is never negative (i.e. V1 + V2 ≥ 0). Both balances are currently $100. Phil initiates two transactions concurrently, T1 withdrawing $200 from V1, and T2 withdrawing $200 from V2.
If the database guaranteed serializable transactions, the simplest way of coding T1 is to deduct $200 from V1, and then verify that V1 + V2 ≥ 0 still holds, aborting if not. T2 similarly deducts $200 from V2 and then verifies V1 + V2 ≥ 0. Since the transactions must serialize, either T1 happens first, leaving V1 = -$100, V2 = $100, and preventing T2 from succeeding (since V1 + (V2 - $200) is now -$200), or T2 happens first and similarly prevents T1 from committing.
Under snapshot isolation, however, T1 and T2 operate on private snapshots of the database: each deducts $200 from an account, and then verifies that the new total is zero, using the other account value that held when the snapshot was taken. Since neither update conflicts, both commit successfully, leaving V1 = V2 = -$100, and V1 + V2 = -$200.
write skew的意思是指,如果两个事务同时写两个不同变量(但是这两个变量之间存在某种重叠的话),那么snapshot isolation是没有办法限定write顺序的,这就是写偏序的意思。上面还举了一个例子,V1,V2是两个变量但是存在一定的关联,如果出现write skew的话那么就会存在一定的问题,这种情况只能够使用串行化来解决。
wikipedia最后面还提到了使用snapshot isolation转换成为serializability的实现方式,并且PostgreSQL里面就已经这么实现了。
With additional communication between transactions, the anomalies that snapshot isolation normally allows can be blocked by aborting one of the transactions involved, turning a snapshot isolation implementation into a full serializability guarantee. This implementation of serializability is well-suited to multiversion concurrency control databases, and has been adopted in PostgreSQL 9.1, where it is referred to as "Serializable Snapshot Isolation", abbreviated to SSI. When used consistently, this eliminates the need for the above workarounds. The downside over snapshot isolation is an increase in aborted transactions. This can perform better or worse than snapshot isolation with the above workarounds, depending on workload.
#note: 事务失败如何处理?如果是因为和server断开的话,那么就应该重新尝试。相反如果是因为其他transaction造成冲突的话,那么是否重试就应该根据应用来判断。
Snapshot isolation does not provide serializability,这个问题以下面的pseduo code来说明还是比较清楚的:
- 假设T1(1),T2(2)分别在1,2时刻发起了事务,cell原有数据为10
- T1准备写cell数据为30,而T2准备读取cell数据。
- 但是T1写cell数据时刻为3,因此只有在3时候以后在才会在cell上面加lock
- 而T2在2时刻读取cell时候发现没有lock,那么直接读取到了数据10
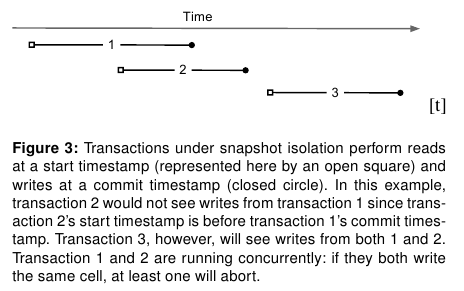
整个过程,按照我们的理解:既然T1首先发起了,那么T2读取的数据应该是30才对。但是如果按照这种逻辑来说,整个读的延迟就非常大了,而"The main advantage of snapshot isolation over a serializable proto-col is more efficient reads.". 其实"Snapshot isolation pro-tects against write-write conflicts: if transactions A and B, running concurrently, write to the same cell, at most one will commit. " 主要还是为了解决write-write conflicts。下图就是一个解决了ww conflict的例子:
下面是Transaction具体实现,关于一些说明会以注释的形式标记在代码上面。 #todo: BackoffAndMaybeCleanupLock如何实现?
class Transaction { struct Write { Row row; Column col; string value; }; vector<Write> writes ; int start ts ; Transaction() : start ts (oracle.GetTimestamp()) {} // 初始化会从oracle获得一个timestamp,表明这个transaction对应的时间。 void Set(Write w) { writes .push back(w); } // 所有的写都会缓存下来,而不是立刻写入table bool Get(Row row, Column c, string* value) { while (true) { bigtable::Txn T = bigtable::StartRowTransaction(row); // todo:?? // Check for locks that signal concurrent writes. if (T.Read(row, c+"lock", [0, start ts ])) { // 如果在这个timestamp之前存在lock,说明在这个ts之前肯定存在commit但是还没有提交成功(可能在运行,也可能直接fail) // There is a pending lock; try to clean it and wait BackoffAndMaybeCleanupLock(row, c); // 对于这个pending lock,我们会选择等待,或者可能是删除。 continue; } // Find the latest write below our start timestamp. latest write = T.Read(row, c+"write", [0, start ts ]); // 说明之前的commit以前提交完成,那么看最近一次的write是在什么时候。所谓最近是指写入的时间是后面的commit_ts. if (!latest write.found()) return false; // no data int data ts = latest write.start timestamp(); // 然后最近写入write的发起时间,也就是start_ts.这个需要结合后面的prewrite和commit来理解。 *value = T.Read(row, c+"data", [data ts, data ts]); return true; } } // Prewrite tries to lock cell w, returning false in case of conflict. bool Prewrite(Write w, Write primary) { Column c = w.col; bigtable::Txn T = bigtable::StartRowTransaction(w.row); // Abort on writes after our start timestamp . . . if (T.Read(w.row, c+"write", [start ts , INFINITY])) return false; // start_ts之后是否有新的提交。如果存在新的提交的话,这就意味这本次T的失败。 // 这个地方非常重要,因为我们读取的数据是start_ts之前的数据,因此如果start_ts之后存在数据写入的话,那么说明存在多个事物正在提交 // 是write-write conflicts. //. . . or locks at any timestamp. if (T.Read(w.row, c+"lock", [0, INFINITY])) return false; // 如果这个cell被lock的话,那么意味着本地T也是失败的。注意这里对lock时间没有任何限制。 T.Write(w.row, c+"data", start ts , w.value); // 写入数据,注意这里的时间戳是start_ts T.Write(w.row, c+"lock", start ts , // 写入lock,内容是primary row和col {primary.row, primary.col}); // The primary’s location. return T.Commit(); } bool Commit() { Write primary = writes [0]; vector<Write> secondaries(writes .begin()+1, writes .end()); if (!Prewrite(primary, primary)) return false; for (Write w : secondaries) if (!Prewrite(w, primary)) return false; int commit ts = oracle .GetTimestamp(); // 预先写入内容之后准备进行提交,提交时间为commit_ts // Commit primary first. Write p = primary; bigtable::Txn T = bigtable::StartRowTransaction(p.row); if (!T.Read(p.row, p.col+"lock", [start ts , start ts ])) // 重新检查之前的锁是否还在?如果还在的话那么写入数据并且删除掉锁。这个必须是一个事务操作,而这个点就是commit point return false; // 之后提交数据,修改write时间并且将lock清除掉。 // aborted while working T.Write(p.row, p.col+"write", commit ts, start ts ); // Pointer to data written at start ts . T.Erase(p.row, p.col+"lock", commit ts); if (!T.Commit()) return false; // commit point // Second phase: write out write records for secondary cells. for (Write w : secondaries) { bigtable::Write(w.row, w.col+"write", commit ts, start ts ); bigtable::Erase(w.row, w.col+"lock", commit ts); } return true; } } // class Transaction
#todo: page5,6这个部分的异常处理没有太看懂
- Transaction processing is complicated by the possibil-ity of client failure (tablet server failure does not affect the system since Bigtable guarantees that written locks persist across tablet server failures). If a client fails while a transaction is being committed, locks will be left be-hind. Percolator must clean up those locks or they will cause future transactions to hang indefinitely. (考虑到client出现failure的情况的话,那么这个问题就稍微有点复杂,因为client可能会出现一些锁遗留下来没有清除。而percolator必须清除它,这样后面的事务才不会被阻塞住)
- Percolator takes a lazy approach to cleanup: when a transaction A encounters a conflicting lock left behind by transaction B, A may determine that B has failed and erase its locks(percolator采取一种lazy的办法,就是只有当A遇到遗留锁的时候,A才决定是否需要清除掉遇到的锁,这个锁可能是正在被某些事务持有的,也可能是遗留的)
- It is very difficult for A to be perfectly confident in its judgment that B is failed; as a result we must avoid a race between A cleaning up B’s transaction and a not-actually-failed B committing the same transaction.(上面这个问题也是比较难以确定的,对于A来说没有办法完全确定是哪种情况)
- Per-colator handles this by designating one cell in every transaction as a synchronizing point for any commit or cleanup operations. This cell’s lock is called the primary lock. Both A and B agree on which lock is primary (the location of the primary is written into the locks at all other cells). Performing either a cleanup or commit op-eration requires modifying the primary lock; since this modification is performed under a Bigtable row transac-tion, only one of the cleanup or commit operations will succeed.(percolator解决这个问题就比较巧妙,percolator指定了一个primary lock,这个primary lock就是lock字段等于自身的(row,column)的cell。而对于一个cell来说cleanup和commit是一个atomic操作,这点由bigtable来保证,因此可以通过是否已经加上primary lock来决定一个transaction是否成功)
- When a client crashes during the second phase of commit, a transaction will be past the commit point (it has written at least one write record) but will still have locks outstanding. We must perform roll-forward on these transactions. A transaction that encounters a lock can distinguish between the two cases by inspecting the primary lock:(如果一个client crash的话,那么根据一个commit point的点来判断是进行roll forward还是roll back,如果超过commit point的话那么就roll forward)
- if the primary lock has been replaced by a write record, the transaction which wrote the lock must have committed and the lock must be rolled forward, oth-erwise it should be rolled back (since we always commit the primary first, we can be sure that it is safe to roll back if the primary is not committed)(什么时候超过commit point呢?是在primary lock删除之后,如果primary lock没有删除的话,那么就认为没有超过commit point那么就要回滚)
- To roll forward, the transaction performing the cleanup replaces the stranded lock with a write record as the original transaction would have done.(如果需要roll forward的话,那么会在cleanup cell这个时候来完成)
3.3. Timestamps
- The timestamp oracle is a server that hands out times-tamps in strictly increasing order. Since every transaction requires contacting the timestamp oracle twice, this ser-vice must scale well. (因为每个transaction都需要和oracle通信两次,所以扩展性是非常重要的)
- The oracle periodically allocates a range of timestamps by writing the highest allocated timestamp to stable storage; given an allocated range of timestamps, the oracle can satisfy future requests strictly from memory. If the oracle restarts, the timestamps will
jump forward to the maximum allocated timestamp (but will never go backwards).(oracle每次都会分配一个范围的timestamp,然后将这个最高的timestamp记录下来。这样如果下次oracle重启的话直接从最大的编号开始分配即可。这种分配方式保证了递增但是没有保证连续)
- To save RPC overhead (at the cost of increasing transaction latency) each Percolator worker batches timestamp requests across transactions by maintaining only one pending RPC to the oracle. As the oracle becomes more loaded, the batching naturally increases to compensate. Batching increases the scalabil-ity of the oracle but does not affect the timestamp guar-antees. (同时为了减少RPC overhead,对于ts的请求会进行batch)
- Our oracle serves around 2 million timestamps per second from a single machine.(单个机器可以支撑到2millions/s请求)
3.4. Notifications
- In Percolator, the user writes code (“observers”) to be triggered by changes to the ta-ble, and we link all the observers into a binary running alongside every tablet server in the system. Each ob-server registers a function and a set of columns with Per-colator, and Percolator invokes the function after data is written to one of those columns in any row.(observer在实现上是link进入worker的binary里面的。observer会将一个function和一组columns关联起来,如果column内容变化的话就会触发observer)
- Percolator applications are structured as a series of ob-servers; each observer completes a task and creates more work for “downstream” observers by writing to the table. (percolator应用程序实际上就是注册一些系列的observer,每个observer会完成一些小任务修改一些cell。而这些修改会触发其他的observer)
- In our indexing system, a MapReduce loads crawled doc-uments into Percolator by running loader transactions, which trigger the document processor transaction to in-dex the document (parse, extract links, etc.). The docu-ment processor transaction triggers further transactions like clustering. The clustering transaction, in turn, trig-gers transactions to export changed document clusters to the serving system.(在google的indexing system里面,外部存在一个mapreduce程序将抓取的页面写入到bigtable里面,如果修改的话那么percolator会触发相应的的动作)
- Notifications are similar to database triggers or events in active databases , but unlike database triggers, they cannot be used to maintain database invariants. In particular, the triggered observer runs in a separate trans-action from the triggering write, so the triggering write and the triggered observer’s writes are not atomic. No-tifications are intended to help structure an incremental computation rather than to help maintain data integrity.(notifaction本身和数据库的触发器非常类似,但是它的作用仅仅是为了提供增量处理这个机制而并不是为了帮助维护数据一致性)
- We do provide one guarantee: at most one observer’s transaction will commit for each change of an observed column. The conquote is not true, however: multiple writes to an observed column may cause the correspond-ing observer to be invoked only once. We call this feature message collapsing, since it helps avoid computation by amortizing the cost of responding to many notifications. For example, it is sufficient for http://google.com to be reprocessed periodically rather than every time we discover a new link pointing to it.Note that if Percolator accidentally starts two transac-tions concurrently for a particular notification, they will both see the dirty notification and run the observer, but one will abort because they will conflict on the acknowl-edgment column. We promise that at most one observer will commit for each notification. (#todo: 这里我不太理解的一点是,这里at most one observer‘transaction will commit的意思是,如果这个cell下面挂了O1和O2,是只有O1/O2其中一个执行呢?还是说如果两个O1在不同线程触发,只有一个O1实例会成功提交?)另外如果一个column存在多次写的话,那么会将这些触发消息聚合在一起,仅仅触发observer一次。这点还是非常现实的,好比google这么大规模的网站可能经常会更新,如果每次更新都频繁触发的话代价还是非常大的。
- To provide these semantics for notifications, each ob-served column has an accompanying “acknowledgment” column for each observer, containing the latest start timestamp at which the observer ran. When the observed column is written, Percolator starts a transaction to pro- cess the notification. The transaction reads the observed column and its corresponding acknowledgment column. If the observed column was written after its last acknowl-edgment, then we run the observer and set the acknowl-edgment column to our start timestamp. Otherwise, the observer has already been run, so we do not run it again.(每个column都会带上一个ack字段,表示这个observer最后一次run的时间。percolator会对比这个column write字段和ack字段,如果发现write字段更大的话,那么说明最近存在一次write行为,因此有必要调用observer代码并且修改ack) #note: 不太明白这段和后面一段中notify字段的关系。我的理解是使用这种方式需要读取很多不相关的内容,不能够有效地发现dirty cell,而使用notify则相对可以提高效率
- To identify dirty cells, Percolator maintains a special “notify” Bigtable column, containing an entry for each dirty cell. When a transaction writes an observed cell, it also sets the corresponding notify cell. The workers perform a distributed scan over the notify column to find dirty cells. After the observer is triggered and the transac-tion commits, we remove the notify cell. Since the notify column is just a Bigtable column, not a Percolator col-umn, it has no transactional properties and serves only as a hint to the scanner to check the acknowledgment col-umn to determine if the observer should be run.(使用notify字段的话,可以在每次修改cell时候同时写如notify这个字段,而这些notify字段可以作为一个column family存在。这样worker在进行scan的时候就可以很快。当observer被触发之后,那么这个notify字段就可以被移除了)
- To make this scan efficient, Percolator stores the notify column in a separate Bigtable locality group so that scan-ning over the column requires reading only the millions of dirty cells rather than the trillions of total data cells. Each Percolator worker dedicates several threads to the scan. For each thread, the worker chooses a portion of the table to scan by first picking a random Bigtable tablet, then picking a random key in the tablet, and finally scan-ning the table from that position. (通过将notify作为一个column family存放在一起可以使得扫描更有效率。worker是多线程进行扫描的,每个线程都会随机从bigtable随机选择一个table,然后从这个table随机选择一个范围进行扫描)
- Since each worker is scanning a random region of the table, we worry about two workers running observers on the same row con-currently. While this behavior will not cause correctness problems due to the transactional nature of notifications, it is inefficient. To avoid this, each worker acquires a lock from a lightweight lock service before scanning the row. This lock server need not persist state since it is advisory and thus is very scalable.(但是如果让worker随即选择范围的话,那么对于同一个column可能会被两个worker扫描到,那么这样就会出现问题在两个地方有相同的observer运行,虽然这不是什么问题因为最后会因为transaction冲突失败,但是这样是没有效率的。为了避免这种情况,需要worker在lock service上面进行注册)
- The random-scanning approach requires one addi-tional tweak: when it was first deployed we noticed that scanning threads would tend to clump together in a few regions of the table, effectively reducing the parallelism of the scan.(如果实现random-scanning的方法话,会出现clump现象,这种现象在现实生活中很常见,作者后面还打了比方。好比有公交车1,2,3,公交车1有点慢,虽然提前开出来但是很快在被2,3都追上了,但是公交车1必须在前面走,这就使得整个车队都非常慢)
- To solve this problem, we modified our system in a way that public transportation systems can-not: when a scanning thread discovers that it is scanning the same row as another thread, it chooses a new random location in the table to scan. To further the transporta-tion analogy, the buses (scanner threads) in our city avoid clumping by teleporting themselves to a random stop (lo-cation in the table) if they get too close to the bus in front of them.(解决上面问题的办法,就是如果两个线程如果扫描位置存在重叠的话,那么后面的线程随机选择另外一个位置进行扫描,避免出现clump)
3.5. Discussion
- One of the inefficiencies of Percolator relative to a MapReduce-based system is the number of RPCs sent per work-unit. While MapReduce does a single large read to GFS and obtains all of the data for 10s or 100s of web pages, Percolator performs around 50 individual Bigtable operations to process a single document.(percolator在数量上面相对于MR多许多,MR从GFS一次读取就可以得到10-100个webpage所需要的全部信息,而percolator处理单个文档就需要调用50个bigtable操作)
- One source of additional RPCs occurs during commit. When writing a lock, we must do a read-modify-write operation requiring two Bigtable RPCs: one to read for conflicting locks or writes and another to write the new lock. To reduce this overhead, we modified the Bigtable API by adding conditional mutations which implements the read-modify-write step in a single RPC. (修改bigtable的API,将prewrite阶段的2次RPC合并成为1个RPC)
- Many con-ditional mutations destined for the same tablet server can also be batched together into a single RPC to fur-ther reduce the total number of RPCs we send. We create batches by delaying lock operations for several seconds to collect them into batches. Because locks are acquired in parallel, this adds only a few seconds to the latency of each transaction; we compensate for the additional la-tency with greater parallelism. Batching also increases the time window in which conflicts may occur, but in our low-contention environment this has not proved to be a problem.(将RPC进行batch,虽然batch会提高一些延迟,但是却可以提高并行度,行batch潜在地造成更多的冲突,但是因为应用下面本身冲突就非常少因此也不是什么问题)
- We also perform the same batching when reading from the table: every read operation is delayed to give it a chance to form a batch with other reads to the same tablet server. This delays each read, potentially greatly increasing transaction latency. (为了提高读取效率,也进行了batch read,但是增加了延迟)
- A final optimization miti-gates this effect, however: prefetching. Prefetching takes advantage of the fact that reading two or more values in the same row is essentially the same cost as reading one value. In either case, Bigtable must read the entire SSTable block from the file system and decompress it. Percolator attempts to predict, each time a column is read, what other columns in a row will be read later in the transaction. This prediction is made based on past be-havior. Prefetching, combined with a cache of items that have already been read, reduces the number of Bigtable reads the system would otherwise do by a factor of 10.(最终的read优化解决方案是使用prefetch。prefetch是根据过去的行为来进行预测的,并且因为bigtable底层使用的sstable格式本身就是将很多字段紧凑地存放在一起的,因此overhead相对较小。通过preftech并且配合cache,将读取bigtable的次数减少到了1/10)
- Early in the implementation of Percolator, we decided to make all API calls blocking and rely on running thou-sands of threads per machine to provide enough par-allelism to maintain good CPU utilization. We chose this thread-per-request model mainly to make application code easier to write, compared to the event-driven model. Forcing users to bundle up their state each of the (many) times they fetched a data item from the table would have made application development much more difficult. Our experience with thread-per-request was, on the whole, positive: application code is simple, we achieve good uti-lization on many-core machines, and crash debugging is simplified by meaningful and complete stack traces. We encountered fewer race conditions in application code than we feared. (使用线程阻塞方式来充分使用CPU,相对于使用event-driven model,是一个正确的选择,开发和调试相对更加容易)
- The biggest drawbacks of the approach were scalability issues in the Linux kernel and Google infrastructure related to high thread counts. Our in-house kernel development team was able to deploy fixes to ad-dress the kernel issues. (最大的限制就在于扩展性因为线程数量的问题,但是很明显google自己的kernel development可以做优化来解决这个问题)
#note: 在提高分布式系统底层效率的时候,减少RPC数量,batch RPC请求,以及prefetch+cache data都是比较有效且常用的手段