OSTEP / Persistence-File
在文件空间分配上, 除了典型的pointer-based方法(在data block里面存储multi-level指针)外, 还有extent-based方法. 这种办法是可以为每个文件分配一个或多个称为extent的连续磁盘空间. 这个连续磁盘空间可以非常大(可能也是按照block来组织的, 这样便于cache & buffer), 利于大文件读写. 按照我的理解是对于小文件还是按照block进行分配, 对于大文件除去按照block分配的空间之外, 其他空间都是按照extent来分配, 这样兼顾大小文件存储效率.
extend-based有点类似虚拟内存里面的段式分配, pointer-based类似页式分配. 文件空间分配和内存分配行为模式上有很大差异, 所以很难照搬过来说哪种更好. 从上面的Wiki链接看, 一些比较知名的文件系统已经支持extent-based, 比如ext4, btrfs, ntfs.
下图是文件系统使用上的典型特征.
- 大量小文件占据少量空间, 大部分在2K (in a block)
- 少量大文件占据主要空间.
- 目录里的项目数量基本<20 (in a block)

Fast File System(FFS)
现代文件系统倾向于将cylinder(柱面)进行聚合称为cylinder group. 在Linux系统中也称为block group. 在一个block group里面读写数据只需要转动盘片而不需要移动磁头. 存取两个文件, 相比这两个文件放在不同的block group上, 放在一个block group上效率更高. 所以OS会尽可能地将路径举例比较进的文件存放在一个block group上面. 文件按照locality被sharding到不同的block group上, 出了super block. super block会在每个block group存上一份作为replication.
磁盘单位容量成本不断下降, 整体容量不断增加. 但相比容量而言, 磁头机械移动速度上却没有太多改进. 所以为了达到高吞吐, 现代操作系统都尽可能将block size设置更大, 让更多的时间花费在transfering而非positioning上, 用空间来换取时间. 不仅单机文件系统这么做, 分布式文件系统也是. GFS论文出来的时候block size是64MB, 而GFS的开源实现HDFS的block size默认是128MB, 实践中还会设置到256MB.
在一个磁道(track)上如何安排block id也是非常有意思的事情. 下图左边是最简单的实现.
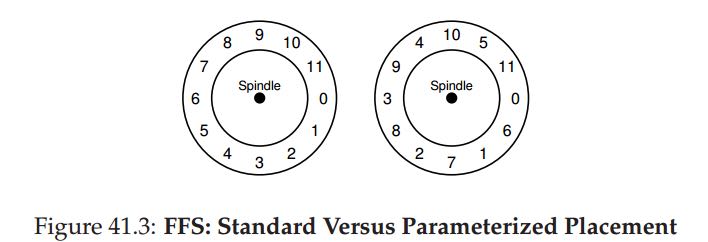
这个实现问题是, 如果我们想顺序访问所有block时候, 会发现rotation位置不对. 首先磁盘是不断旋转地, 当我们transfer block0的时候盘片依然在转动. 当我们要读取block1时, 磁头位置可能已经到了block3, 这就意味着还要等待一圈才能读block1. 所以合理的方式应该是, 将所有blocks, 按照tranfer block时间和rotate speed计算出的间隔, 均匀地分散开.
Crash Consistency
为了应对系统出现crash导致磁盘上数据出现不一致的问题,有两个解决办法:一个是事后检测并修复(fsck), 一个则是通过journal记日志的方式来做恢复。fsck大致思路是检查文件系统各个部分的一致性,比如inode节点如果使用的话,看这个inode节点是否有真实数据块。但是有时候会出现自相矛盾的情况,就需要用户自己来做判断,比较麻烦。另外一个不好的地方是每次修复需要扫描整个磁盘非常耗时,即便是一小部分出现不一致仍然要扫描整块盘。journal则是借鉴数据库系统事务实现的思想,每次做更新操作的话会将本次更新记录meta信息做成一个block写入日志块中,只有等待数据以及meta block完全写入磁盘才会添加上trx_end标记。具体实现上可以按照下面5个步骤进行:
- Data write: Write data to final location; wait for completion (the wait is optional; see below for details).
- Journal metadata write: Write the begin block and metadata to the log; wait for writes to complete.
- Journal commit: Write the transaction commit block (containing TxE) to the log; wait for the write to complete; the transaction (in- cluding data) is now committed.
- Checkpoint metadata: Write the contents of the metadata update to their final locations within the file system.
- Free: Later, mark the transaction free in journal superblock.
其中1,2完全可以同时进行,只需要保证在3执行之前1,2已经完成。
Log-structured File Systems
基于日志实现的存储系统,可以利用内存来buffer write, 将random write聚合成为sequential write提高磁盘写入吞吐。通过合理的索引结构又能保持良好的读性能。所面临的问题包括写入放大和垃圾回收。很早之前想看看LFS论文,但是可能是出于时间原因,更可能出于对LSM缺乏基本认识,所以很快就放弃了。正好这小章说了以下LFS中一些具体实现细节。
To achieve this end, LFS uses an ancient technique known as write buffering. Before writing to the disk, LFS keeps track of updates in memory; when it has received a sufficient number of updates, it writes them to disk all at once, thus ensuring efficient use of the disk. The large chunk of updates LFS writes at one time is referred to by the name of a segment.
Here is an example, in which LFS buffers two sets of updates into a small segment; actual segments are larger (a few MB). The first update is of four block writes to file j; the second is one block being added to file k. LFS then commits the entire segment of seven blocks to disk at once. The resulting on-disk layout of these blocks is as follows:
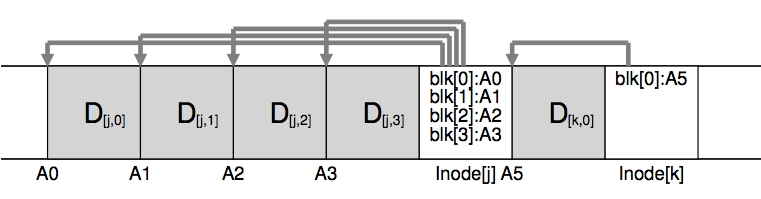
LFS会将多个data block写入聚合在一起写下,一次写入生成一个segment. segment里面不仅仅包括data blocks, 还可能包括对应的inode block, 以及inode map. 因为每次更新inode block都会在新的地方重写一份,inode block位置在不断发生变化。inode map里面记录了这个信息,记录了inode no到inode block address的映射关系。最终会存储在一个checkpoint-region(CR)的地方。这个CR会定期flush下去,虽然这个写入是随机写,但是因为间隔时间比较长所以不会影响性能。
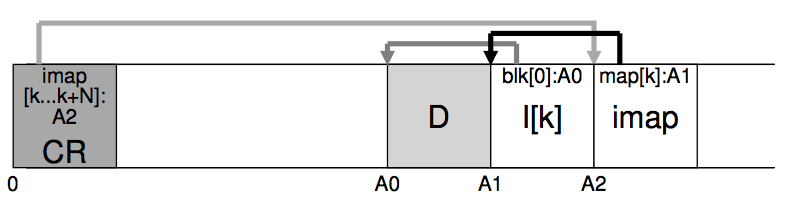
目录存储结构和文件存储结构很类似。在一个目录下面创建一个文件需要写入5个block. (file data block, file inode block, dir data block, dir inode block, imap).
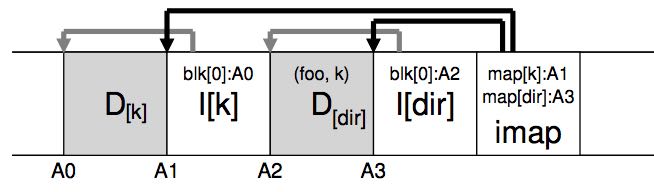
Specifically, LFS includes, for each data block D, its inode number (which file it belongs to) and its offset (which block of the file this is). This information is recorded in a structure at the head of the segment known as the segment summary block.
每个segment里面每个data block都会包含inode no以及offset, 这些信息聚合在一起放在segment开头处称为segment summary block. 这个block用途是为了在GC时候可以知道那些data block是in-use的,而哪些data block是可以被回收的。
TIP: TURN FLAWS INTO VIRTUES
Whenever your system has a fundamental flaw, see if you can turn it around into a feature or something useful. NetApp’s WAFL does this with old file contents; by making old versions available, WAFL no longer has to worry about cleaning, and thus provides a cool feature and re- moves the LFS cleaning problem all in one wonderful twist.
如果你富有创造力的话,可以将缺陷变为有优势。比如可以将那些原来老版本data block作为文件历史版本使用,而由用户来决定什么时候删除老版本而不用自己决定GC时间。
TIP: MEASURE THEN BUILD (PATTERSON’S LAW)
One of our advisors, David Patterson (of RISC and RAID fame), used to always encourage us to measure a system and demonstrate a problem before building a new system to fix said problem. By using experimen- tal evidence, rather than gut instinct, you can turn the process of system building into a more scientific endeavor. Doing so also has the fringe ben- efit of making you think about how exactly to measure the system before your improved version is developed. When you do finally get around to building the new system, two things are better as a result: first, you have evidence that shows you are solving a real problem; second, you now have a way to measure your new system in place, to show that it actually improves upon the state of the art. And thus we call this Patterson’s Law.
改进系统,先进行测量,然后再构建。一方面你可以确定问题出在什么地方,另外一方面对比观察改进效果。