OpenTSDB
Table of Contents
- Homepage: http://opentsdb.net/index.html
- Overview: http://opentsdb.net/overview.html
- Manual: http://opentsdb.net/manual.html
1. Overview
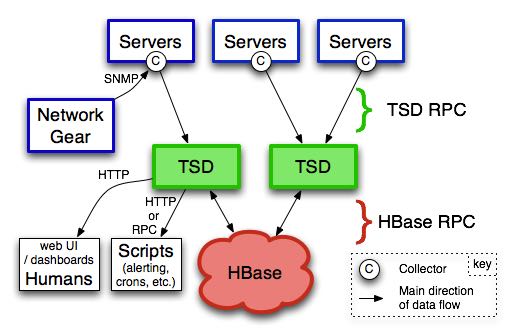
从上图来看整个架构还是比较简单的
- Collector as agent. (python framework tcollector https://github.com/OpenTSDB/tcollector)
- TSD as server.
- HBase as database.
collector在每个机器上面做数据采集,采集数据点称为data point. 包含下面几个部分:
- A metric name.
- A UNIX timestamp (seconds since Epoch).
- A value (64 bit integer or double-precision floating point value).
- A set of tags (key-value pairs) that annotate this data point. tags非常重要,能够提供描述信息
mysql.bytes_received 1287333217 327810227706 schema=foo host=db1 mysql.bytes_sent 1287333217 6604859181710 schema=foo host=db1 mysql.bytes_received 1287333232 327812421706 schema=foo host=db1 mysql.bytes_sent 1287333232 6604901075387 schema=foo host=db1 mysql.bytes_received 1287333321 340899533915 schema=foo host=db2 mysql.bytes_sent 1287333321 5506469130707 schema=foo host=db2
不管对于metrics,tag name,tag value都是通过索引的方式来建立的,最多使用3 bytes(也就是24bits)来建立索引,因此在数目上也有所限制。
New tags, on the other hand, are automatically registered whenever they're used for the first time. Right now OpenTSDB only allows you to have up to 2^24 = 16777216 different metrics, 16777216 different tag names and 16777216 different tag values. This is because each one of those is assigned a UID on 3 bytes. Metric names, tag names and tag values have their own UID spaces, which is why you can have 16777216 of each kind. The size of each space is configurable but there is no knob that exposes this configuration parameter right now. So bear in mind that using user ID or event ID as a tag value will not work right now if you have a large site.
2. Schema
以下面的data point为例
myservice.latency.avg 1292148123 42 reqtype=foo host=web42
row表示格式为: 每个数字对应1 byte
- [0, 0, -69] metric ID
- [77, 4, -99, 32] base timestamp = 1292148000
- timestamps in the row key are rounded down to a 60 minute boundary
- 也就是说对于同一个小时的metric + tags相同的数据都会存放在一个row下面
- [0, 0, 1] "reqtype" index
- [0, 1, 11] "foo" index
- [0, 0, 2] "host" index
- [0, -7, 42] "web42" index
#note: 可以看到,对于metric + tags相同的数据都会连续存放,且metic相同的数据也会连续存放,这样对于scan以及做aggregation都非常有帮助
column qualifier占用2 bytes,表示格式为:
- 12 bits delta in seconds.(相对row表示的小时的delta, 最多2^ 12 = 4096 > 3600因此没有问题)
- 4 bits
- 1 bit (long or double)
- 3 bits (reserved)
value使用8bytes存储,既可以存储long,也可以存储double.
$ ./tsdb scan 2010/11/07-23:00 sum test
[0, 0, -69, 76, -41, -94, 72, 0, 0, 1, 0, 0, -15] test 1289200200 (Sun Nov 07 23:10:00 PST 2010) {host=face}
[3, -89] [108, 61] 58 l 27709 1289200258 (Sun Nov 07 23:10:58 PST 2010)
[3, -73] [48, 125] 59 l 12413 1289200259 (Sun Nov 07 23:10:59 PST 2010)
但是hbase存储的时候,每个cell都会存储row,column qualifier,这样空间不会很节省,因此后台会定期地进行compaction. 所谓的compaction非常简单,就是将两个qualifier连续存放,数据也连续存放。最终的情况会是在row下面只是存在一个cell. 以上面的example为例,compaction之后的结果为
$ ./tsdb scan 2010/11/07-23:00 sum test
[0, 0, -69, 76, -41, -94, 72, 0, 0, 1, 0, 0, -15] test 1289200200 (Sun Nov 07 23:10:00 PST 2010) {host=face}
[3, -89, 3, -73] [108, 61, 48, 125] 58 l 27709 1289200258 (Sun Nov 07 23:10:58 PST 2010)
59 l 12413 1289200259 (Sun Nov 07 23:10:59 PST 2010)
关于schema后期改进有一下几点:
- variant length coding 来表示value
- run length encoding 来压缩column qialifier以及value. 因为qualifier之间非常近似,因此压缩效果会非常明显。
3. Query
下面是整个query的过程:
- A metric name for which to retrieve data;
- A start time;
- A stop time (optional, if not set, assumed to be "now");
- A possibly empty set of tags to filter the data (e.g. host=foo, or wildcards such as host=*); 可以根据tag做筛选,放在time range之后是schema design导致的
- An aggregation function (e.g. sum or avg); 所谓的聚合是将相同tags下面数据进行聚合
- Whether or not to get the "rate of change" the data (in mathematical terms: the first derivative).
- Optionally: a downsampling interval (e.g. 10 minutes) and downsampling function (e.g. avg) downsampling就是下采样
具体实现如下:
- Open a scanner, set with a start key composed of the metric requested and the start time.
- The scanner is configured to stop at a key corresponding to the stop time and to filter out rows containing data with tags that don't match the tags we're looking for.
- If any multiple choice tags (e.g. host=foo|bar) or wildcard tags are used (e.g. host=*, which is akin to a GROUP BY in SQL), sort the rows in groups accordingly. 按照tags进行排序,因此内部tag应该也是排好序的
- For each group, repeated the remaining steps:
- Apply the downsample function, if there is one. For instance 10m-avg will collapse each consecutive chunk of 600 second worth of data down to one data point using the average.
- Aggregate the values of the different time series together (for instance sum will sum up all the time series that wound up being together in this group &ldash; this requires that you understand how to perform such operations on time series in a sound fashion, see below).
- If the rate of change was requested, compute that using the previous value returned.