Python程序性能分析
- pyflame (github)
- gprof2dot profile data to graph
- flamegraphs 火焰图对性能瓶颈发现非常直观
profiler 分为两类:a. Deterministic(确定性) b. Sampling(采样性).
Deterministic profiler 有比如profile/cProfile模块,原理是使用sys.settrace在函数调用的各个地方打点。好处是剖分信息非常准确,但是缺点也很多:
- High Overhead. 高开销,并且对那些执行很快但是次数很频繁的代码,统计并不准确。 Many engineers don’t use profiling information because they can’t trust its accuracy.
- Lack of Full Stack Information. ??应该不至于吧??
- Lack of Services Written for Profiling. 所有需要剖分的代码都需要explicitly instrumented. 所以如果想分析一段代码,需要修改代码重新上线部署。
Sampling profiler 原理是调用 POSIX Interval timer 每隔一段时间中端进程获取整个堆栈信息,以此来估计每个函数的执行时间和开销。好处是可以修改interval timer来对采样精度以及开销做tradeoff, 缺点是需要一个好的/高效的实现。pyflame / perf 工具就属于这类。
前段时间我们后端的爬虫也出现CPU开销比较大的问题。爬虫是后台长期运行的任务,所以想动态地启动/关闭profiler(所以在一定程度上也解决了explicitly instrumented这个问题)。可以通过启动一个进程定时地从一个地方(比如Redis)里面读取数据来打开和关闭Profiler
global_profiler = cProfile.Profile()
global_profiler.running = False
def dyn_check_profiler(interval=30):
host = conf.HOSTNAME
pid = base_util.get_current_pid()
output_file = os.path.join(conf.DEFAULT_LOGGING_FILE_PATH, '%s.%d.profile.data' % (host, pid))
while True:
tms = TinyMemoryStorage('task.%s.%s.profiler' % (host, pid))
data = tms.get()
if data:
if not global_profiler.running:
logger.debug('profiler enabled')
global_profiler.enable()
global_profiler.running = True
else:
if global_profiler.running:
global_profiler.disable()
global_profiler.running = False
logger.debug('profiler disabled. dump to %s' % output_file)
global_profiler.dump_stats(output_file)
time.sleep(interval)
我对爬虫观察了一段时间,然后使用 gprof2dot 这个工具对profile data图形化展现了出来。可以看到有很大部分时间花费在cookie整合上,不过其实我们并不需要cookie这个功能。
- L1 文件/行号/函数
- L2 累计花费时间(cumtime)
- L3 自身花费时间(tottime)
- L4 调用次数(calls)
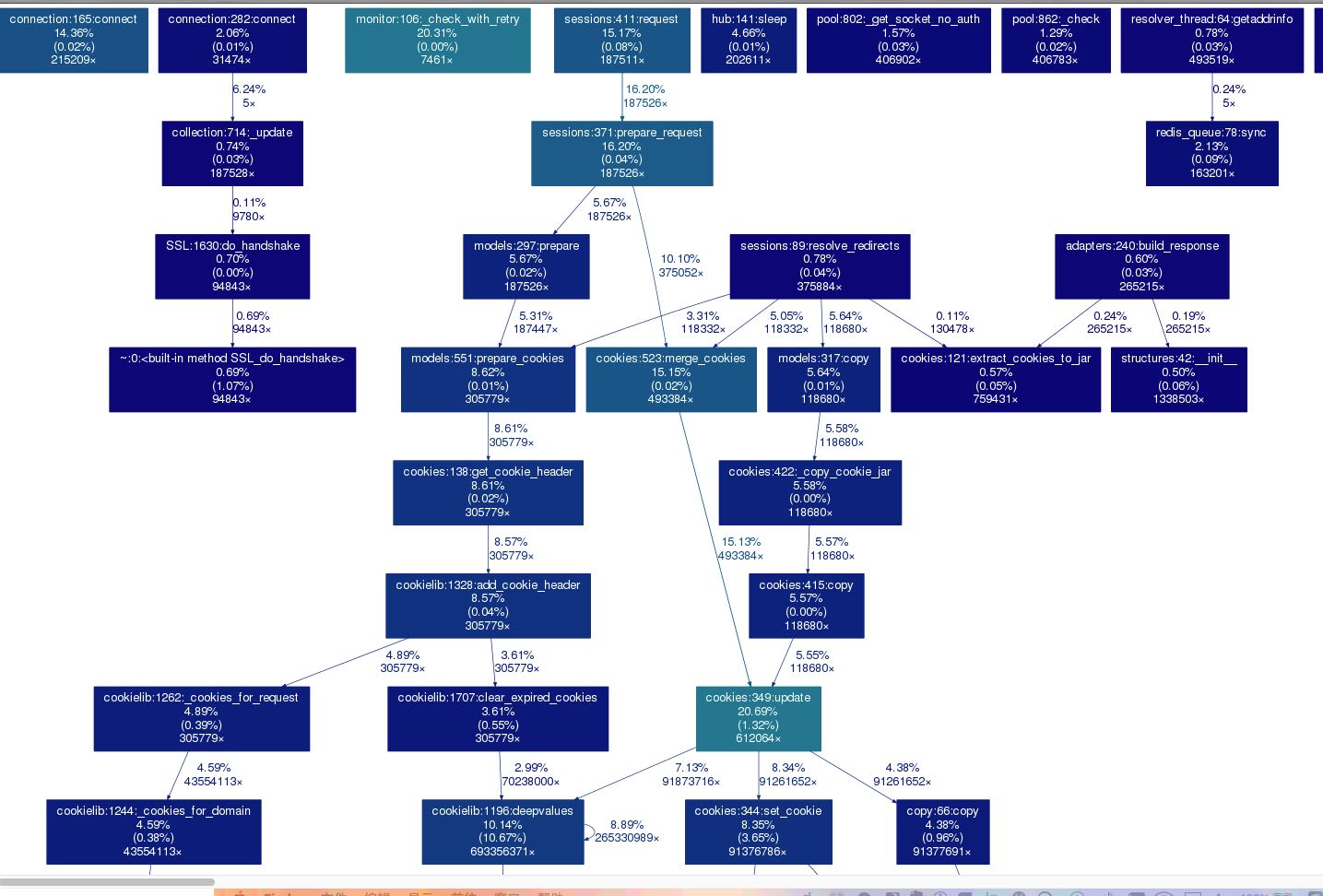
可以通过设置cookie policy来关闭cookie. 上线运行一段时间之后可以发现这个爬虫cpu不像原来那么高了。
class BlockAllCookiePolocy(cookielib.CookiePolicy):
return_ok = set_ok = domain_return_ok = path_return_ok = lambda self, *args, **kwargs: False
netscape = True
rfc2965 = hide_cookie2 = False
...
def disable_cookie(self):
self.proxy_ss.cookies.set_policy(BlockAllCookiePolocy())
self.my_ss.cookies.set_policy(BlockAllCookiePolocy())
...