Object Storage on CRAQ
https://pdos.csail.mit.edu/6.824/papers/craq.pdf
https://pdos.csail.mit.edu/6.824/notes/l-craq.txt
https://pdos.csail.mit.edu/6.824/papers/craq-faq.txt
CRAQ涉及到两个技术:
- CR: Chain Replication. 因为可以通过pipeline的方式发送数据,可以做到比较高的写吞吐。
- AQ: Apportioned Query. 可以向所有的节点发起读请求并且依然满足强一致性,做到比较高的读吞吐。
CR原始论文为了满足强一致性只能查询tail节点。因为到了write到了tail节点之后,说明所有的replicas就都可以committed了。但是这样会造成读的吞吐量上不去,毕竟只能查询tail节点。 AQ的方式是允许将读分摊到所有的节点上,而不仅仅是tail节点,同时保证强一致性。CRAQ处理failover的情况依赖于zookeeper, 它使用zookeeper来管理chain上的节点。
如何保证读任意节点依然满足强一致性呢?可以在CR协议的基础上稍加改进:
- node每次收到写入 `(key, value, version)`, 会将version加入到key下面的列表中,并且标记dirty状态。
- 所谓dirty状态就是这次写入还没有被tail节点所ack.
- 当tail节点收到写入之后,会将ack信息向前传播。所以node收到了 `(key, version, ack)` 信息的话,那么就可以清除dirty标记clean状态了。
- 于此同时,可以将这个version之前所有的版本都清楚掉。因为当前这个版本就是最新数据,对外没有必要提供历史数据。
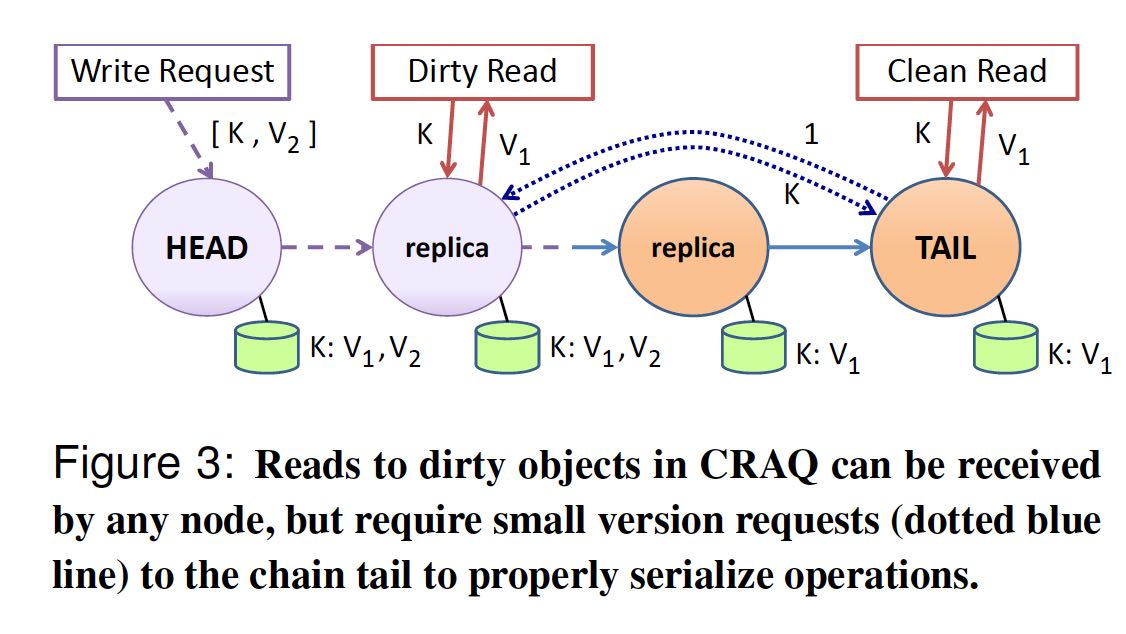
当client读取key的时候,如果当前有某个version处于dirty状态的话,那么说明当前有写入但是不确定是否到达了tail节点。这个时候节点可以和tail节点做一个通信,询问“你最新写入的key是什么version”, 然后使用这个tail写入的版本的数据返回给client.
注意这里node和tail之间通信只有“某个key对应的最新version”,而没有任何数据传输。将read分摊到所有节点上,可以让读吞吐线性增长。此外,还可以顺便满足最终一致性,以及满足某种条件的eventual consistency
Eventual Consistency with Maximum-Bounded Inconsistency allows read operations to return newly written objects before they commit, but only to a certain point. The limit imposed can be based on time (relative to a node’s local clock) or on absolute version numbers. In this model, a value returned from a read operation is guaranteed to have a maximum inconsistency period (defined over time or versioning). If the chain is still available, this inconsistency is actually in terms of the returned version being newer than the last committed one. If the system is partitioned and the node cannot participate in writes, the version may be older than the current committed one.
关于检测节点可用性这件事情,CRAQ外包给了zookeeper。所有节点都会在zookeeper上面去注册所属的datacenter目录下面,并且关注这个目录下面的节点加入和删除,然后了解到整个dc里面有哪些nodes. 这些nodes组成了一个环,然后chain就通过一致性hash的方式映射到这些nodes上面去。我的理解是,相邻的几个nodes就组成了一个chain,至于几个nodes则是根据chain metadata指定的。
Although this approach requires that nodes keep track of the CRAQ node list of entire datacenters, we chose this method over the alternative approach in which nodes register their membership for each chain they belong to (i.e., chain metadata explicitly names the chain’s current members). We make the assumption that the number of chains will generally be at least an order of magnitude larger than the number of nodes in the system, or that chain dynamism may be significantly greater than nodes joining or leaving the system (recall that CRAQ is designed for managed datacenter, not peer-to-peer, settings). Deployments where the alternate assumptions hold can take the other approach of tracking per-chain memberships explicitly in the coordination service. If necessary, the current approach’s scalability can also be improved by having each node track only a subset of datacenter nodes: We can partition node lists into separate directories within nodes/dc_name according to node_id prefixes, with nodes monitoring just their own and nearby prefixes.
关于如何处理这个membership的变化,论文的5.3 Handling Memberships Changes里面有,我没有仔细阅读,好像是通过back-propagation来做数据同步的。这个membership变化还有点难, 因为read都要和tail节点做同步,所以tail节点是需要越稳定越好。新上来的节点放在tail上,它什么数据都没有,有点不太合适。
Back-propagation messages always contain a node’s full state about an object. This means that rather than just sending the latest version, the latest clean version is sent along with all outstanding (newer) dirty versions. This is necessary to enable new nodes just joining the system to respond to future acknowledgment messages. Forward propagation supports both methods. For normal writes propagating down the chain, only the latest version is sent, but when recovering from failure or adding new nodes, full state objects are transmitted.
Intuition for linearizability of CR?
When no failures, almost as if the tail were the only server.
Head picks an order for writes, replicas apply in that order,
so they will stay in sync except for recent (uncommitted) writes.
Tail exposes only committed writes to readers.
Failure recovery, briefly.
Good news: every replica knows of every committed write.
But need to push partial writes down the chain.
If head fails, successor takes over as head, no commited writes lost.
If tail fails, predecessor takes over as tail, no writes lost.
If intermediate fails, drop from chain, predecessor may need to
re-send recent writes.
CR这种方式很适合wide-area network。拓扑做好的话,dc之间传输只要一次。
That said, applications might further optimize the selection of wide-area chains to minimize write latency and reduce network costs. Certainly the naive approach of building chains using consistent hashing across the entire global set of nodes leads to randomized chain successors and predecessors, potentially quite distant. Furthermore, an individual chain may cross in and out of a datacenter (or particular cluster within a datacenter) several times. With our chain optimizations, on the other hand, applications can minimize write latency by carefully selecting the order of datacenters that comprise a chain, and we can ensure that a single chain crosses the network boundary of a datacenter only once in each direction.
Even with an optimized chain, the latency of write operations over wide-area links will increase as more datacenters are added to the chain. Although this increased latency could be significant in comparison to a primary/backup approach which disseminates writes in parallel, it allows writes to be pipelined down the chain. This vastly improves write throughput over the primary/ backup approach.
WAN部署方式对zookeeper要求很高,如果我没有理解错误的话,zookeeper使用的zab协议应该也是quorum的,对延迟还是比较敏感的,比较适合LAN和DC内部使用。 一种改进方式就是做成zookeeper的集群(OMG),每个DC部署一个zookeeper实例,DC之间选择一个representative来做协调和共享数据,DC内部的client 依然只会访问DC内部的zookeeper实例。不过论文也说了,这种方式还没有实现。
Membership management and chain metadata across multiple datacenters does introduce some challenges. In fact, ZooKeeper is not optimized for running in a multidatacenter environment: Placing multiple ZooKeeper nodes within a single datacenter improves Zookeeper read scalability within that datacenter, but at the cost of wide-area performance. Since the vanilla implementation has no knowledge of datacenter topology or notion of hierarchy, coordination messages between Zookeeper nodes are transmitted over the wide-area network multiple times. Still, our current implementation ensures that CRAQ nodes always receive notifications from local Zookeeper nodes, and they are further notified only about chains and node lists that are relevant to them. We expand on our coordination through Zookeper in §5.1.
To remove the redundancy of cross-datacenter ZooKeeper traffic, one could build a hierarchy of Zookeeper instances: Each datacenter could contain its own local ZooKeeper instance (of multiple nodes), as well as having a representative that participates in the global ZooKeeper instance (perhaps selected through leader election among the local instance). Separate functionality could then coordinate the sharing of data between the two. An alternative design would be to modify ZooKeeper itself to make nodes aware of network topology, as CRAQ currently is. We have yet to fully investigate either approach and leave this to future work.
DC内部还可以使用multicast来优化网络传输减少写入延迟,这个对于大对象来说有点不太可行,此外还需要考虑UDP数据包丢失以及membership changes造成数据没有收到的情况。不过无论如何,这的确是个有趣的点。
CRAQ can take advantage of multicast protocols [41] to improve write performance, especially for large updates or long chains. Since chain membership is stable between node membership changes, a multicast group can be created for each chain. Within a datacenter, this would probably take the form of a network-layer multicast protocol, while application-layer multicast protocols may be bettersuited for wide-area chains. No ordering or reliability guarantees are required from these multicast protocols.
Then, instead of propagating a full write serially down a chain, which adds latency proportional to the chain length, the actual value can be multicast to the entire chain. Then, only a small metadata message needs to be propagated down the chain to ensure that all replicas have received a write before the tail. If a node does not receive the multicast for any reason, the node can fetch the object from its predecessor after receiving the write commit message and before further propagating the commit message.
Additionally, when the tail receives a propagated write request, a multicast acknowledgment message can be sent to the multicast group instead of propagating it backwards along the chain. This reduces both the amount of time it takes for a node’s object to re-enter the clean state after a write, as well as the client’s perceived write delay. Again, no ordering or reliability guarantees are required when multicasting acknowledgments—if a node in the chain does not receive an acknowledgement, it will reenter the clean state when the next read operation requires it to query the tail.
Q&A
处理Byzantine Fault Tolerant(BFT)需要实现几个东西:
- 身份识别,比如确认某个机器的确是属于这个集群的。
- 数据自身完整性,通常可以使用checksum以及hash sign来解决。
- 数据语义正确性,比如要求必须最新数据。
Why can CRAQ serve reads from replicas linearizably but Raft/ZooKeeper/&c cannot?
Relies on being a chain, so that *all* nodes see each
write before the write commits, so nodes know about
all writes that might have committed, and thus know when
to ask the tail.
Raft/ZooKeeper can't do this because leader can proceed with a mere
majority, so can commit without all followers seeing a write,
so followers are not aware when they have missed a committed write.
Does that mean CRAQ is strictly more powerful than Raft &c?
No.
All CRAQ replicas have to participate for any write to commit.
If a node isn't reachable, CRAQ must wait.
So not immediately fault-tolerant in the way that ZK and Raft are.
CR has the same limitation.
How can we safely make use of a replication system that can't handle partition?
A single "configuration manager" must choose head, chain, tail.
Everyone (servers, clients) must obey or stop.
Regardless of who they locally think is alive/dead.
A configuration manager is a common and useful pattern.
It's the essence of how GFS (master) and VMware-FT (test-and-set server) work.
Usually Paxos/Raft/ZK for config service,
data sharded over many replica groups,
CR or something else fast for each replica group.
Lab 4 works this way (though Raft for everything).
Q: The paper's Introduction mentions that one could use multiple
chains to solve the problem of intermediate chain nodes not serving
reads. What does this mean?
A: In Chain Replication, only the head and tail directly serve client
requests; the other replicas help fault tolerance but not performance.
Since the load on the head and tail is thus likely to be higher than
the load on intermediate nodes, you could get into a situation where
performance is bottlenecked by head/tail, yet there is plenty of idle
CPU available in the intermediate nodes. CRAQ exploits that idle CPU
by moving the read work to them.
The Introduction is referring to this alternate approach. A data
center will probably have lots of distinct CR chains, each serving a
fraction (shard) of the objects. Suppose you have three servers (S1,
S2, and S3) and three chains (C1, C2, C3). Then you can have the three
chains be:
C1: S1 S2 S3
C2: S2 S3 S1
C3: S3 S1 S2
Now, assuming activity on the three chains is roughly equal, the load on
the three servers will also be roughly equal. In particular the load of
serving client requests (head and tail) will be roughly equally divided
among the three servers.
This is a pretty reasonable arrangement; CRAQ is only better if it
turns out that some chains see more load than others.
Q: Is the failure model for CRAQ non-Byzantine?
A: CRAQ cannot handle Byzantine failures. Just fail-stop failures.
Few systems have a good story for Byzantine failures, and typically
have to make sacrifices in performance or flexibility when they do.
There are two main approaches I'm aware of. First, systems derived
from a paper titled Practical Byzantine Fault Tolerance (PBFT) by
Castro and Liskov; PBFT is like Raft but has more rounds of
communication and uses cryptography. Second, systems in which clients
can directly check the correctness of results that servers return,
typically by use of cryptographic hashes or signatures. This can be
tricky because clients need to defend against a server that returns
data whose signature or hash is correct, but is not the latest value.
Systems like this include SUNDR and Bitcoin.