NUMA (Non-Uniform Memory Access): An Overview
Table of Contents
http://queue.acm.org/detail.cfm?id=2513149
1. BACKGROUND
NUMA (non-uniform memory access) is the phenomenon that memory at various points in the address space of a processor have different performance characteristics.(对于一个处理器来说,访问不同内存地址性能特征是不同的)
Today, processors are so fast that they usually require memory to be directly attached to the socket that they are on. A memory access from one socket to memory from another has additional latency overhead to accessing local memory—it requires the traversal of the memory interconnect first. On the other hand, accesses from a single processor to local memory not only have lower latency compared to remote memory accesses but do not cause contention on the interconnect and the remote memory controllers. It is good to avoid remote memory accesses. Proper placement of data will increase the overall bandwidth and improve the latency to memory.(访问同一个插槽上的内存,不仅延迟更低,访问冲突也会更少)
NUMA systems today (2013) are mostly encountered on multisocket systems. A typical high- end business-class server today comes with two sockets and will therefore have two NUMA nodes. Latency for a memory access (random access) is about 100 ns. Access to memory on a remote node adds another 50 percent to that number.(常见商用级别服务器提供两个插槽,也就是提供了两个NUMA节点。随机访问本地内存延迟在100ns,而访问远端内存延迟增加50%)
Performance-sensitive applications can require complex logic to handle memory with diverging performance characteristics. If a developer needs explicit control of the placement of memory for performance reasons, some operating systems provide APIs for this (for example, Linux, Solaris, and Microsoft Windows provide system calls for NUMA). However, various heuristics have been developed in the operating systems that manage memory access to allow applications to transparently utilize the NUMA characteristics of the underlying hardware.(操作系统会提供特定的API来支持应用程序显式使用NUMA。 同时操作系统内部也会隐式地使用启发式方法来使用NUMA,提高内存访问性能,而不需要应用程序来控制)
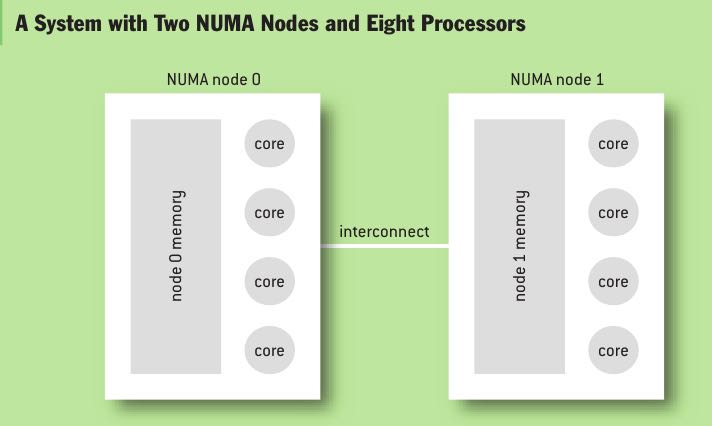
A NUMA system classifies memory into NUMA nodes (which Solaris calls locality groups). All memory available in one node has the same access characteristics for a particular processor. Nodes have an affinity to processors and to devices. These are the devices that can use memory on a NUMA node with the best performance since they are locally attached. Memory is called node local if it was allocated from the NUMA node that is best for the processor. For example, the NUMA system exhibited in Figure 1 has one node belonging to each socket, with four cores each.(NUMA系统将内存归类为NUMA节点,同一个节点内所有内存对于处理器来说, 访问速度是相同的。节点和处理器之间需要设置亲和性)
The process of assigning memory from the NUMA nodes available in the system is called NUMA placement. As placement influences only performance and not the correctness of the code, heuristic approaches can yield acceptable performance. In the special case of noncache-coherent NUMA systems, this may not be true since writes may not arrive in the proper sequence in memory. However, there are multiple challenges in coding for noncache-coherent NUMA systems. We restrict ourselves here to the common cache-coherent NUMA systems.(进程决定如何将内存分配给NUMA节点成为NUMA放置,这个只会影响到性能而不会影响到正确性。 但是对于noncache-coherent NUMA系统来说是不成立的,因为对于不同节点写入顺序不同会造成结果不同。我们这里只考虑cache-coherent NUMA系统)
2. HOW OPERATING SYSTEMS HANDLE NUMA MEMORY
There are several broad categories in which modern production operating systems allow for the management of NUMA: (总的来说操作系统使用NUMA的方式是下面5类)
- accepting the performance mismatch, (啥都不做,效果取决于运气)
- hardware memory striping, (将内存地址按照cache line size进行拆分,比如A是node0, A+64则是node1. 性能被均摊出去,可以认为就是平均性能有保证,但是平均性能差了)
- heuristic memory placement, (在哪个核上面运行,就从哪个核上面分配;或者是使用RR方式在node0/node1上交替分配)
- a static NUMA configurations,(将应用程序固定地从某个memory上分配)
- and application-controlled NUMA placement.(应用程序通过API方式自己控制分配来源)
启发式如何工作:
The most common assumptions made by the operating system are that the application will run on the local node and that memory from the local node is to be preferred. If possible, all memory requested by a process will be allocated from the local node, thereby avoiding the use of the cross- connect. The approach does not work, though, if the number of required processors is higher than the number of hardware contexts available on a socket (when processors on both NUMA nodes must be used); if the application uses more memory than available on a node; or if the application programmer or the scheduler decides to move application threads to processors on a different socket after memory allocation has occurred.(假设进程通常访问自己开辟的内存,因为在放置内存时候选择开辟内存线程所在的处理器所在单元。 但是某些情况下这个方法也行不通,比如应用程序使用超过单节点总量内存)
In general, small Unix tools and small applications work very well with this approach. Large applications that make use of a significant percentage of total system memory and of a majority of the processors on the system will often benefit from explicit tuning or software modifications that take advantage of NUMA.(通常来说Unix工具或者是小应用程序比较适合,但是需要占用大量内存的应用程序则不太适合)
Most Unix-style operating systems support this mode of operation. Notably, FreeBSD and Solaris have optimizations to place memory structures to avoid bottlenecks. FreeBSD can place memory round-robin on multiple nodes so that the latencies average out. This allows FreeBSD to work better on systems that cannot do cache-line interleaving on the BIOS or hardware level (additional NUMA support is planned for FreeBSD 10). Solaris also replicates important kernel data structures per locality group.(Linux应该也是使用RR方式来进行分配的,实际效果应该是也还不错)
3. HOW DOES LINUX HANDLE NUMA?
Linux manages memory in zones. In a non-NUMA Linux system, zones are used to describe memory ranges required to support devices that are not able to perform DMA (direct memory access) to all memory locations. Zones are also used to mark memory for other special needs such as movable memory or memory that requires explicit mappings for access by the kernel (HIGHMEM), but that is not relevant to the discussion here.(Linux使用zone方式来管理内存。对于non-NUMA系统来说,zone用来描述一段内存区域, 这段内存区域可以用来支持那些不支持DMA到所有内存区域的设备)
When NUMA is enabled, more memory zones are created and they are also associated with NUMA nodes. A NUMA node can have multiple zones since it may be able to serve multiple DMA areas. How Linux has arranged memory can be determined by looking at /proc/zoneinfo. The NUMA node association of the zones allows the kernel to make decisions involving the memory latency relative to cores.(对于NUMA系统来说,linux使用zone来管理NUMA节点。一个NUMA节点会分配多个zone, 这个映射关系可以从/proc/zoneinfo看到。根据nodes之间的距离,来将node划分到不同的zones上)
On boot-up, Linux will detect the organization of memory via the ACPI (Advanced Configuration and Power Interface) tables provided by the firmware and then create zones that map to the NUMA nodes and DMA areas as needed. Memory allocation then occurs from the zones. Should memory in one zone become exhausted, then memory reclaim occurs: the system will scan through the least recently used pages trying to free a certain number of pages. Counters that show the current status of memory in various nodes/zones can also be seen in /proc/zoneinfo. Figure 2 shows types of memory in a zone/node.(看上去每个zone都是独立管理内存区域)

4. MEMORY POLICIES
How memory is allocated under NUMA is determined by a memory policy. Policies can be specified for memory ranges in a process’s address space, or for a process or the system as a whole. Policies for a process override the system policy, and policies for a specific memory range override a process’s policy.(内存策略可以针对一段内存地址,也可以针对一个进程,也可以针对整个系统)
The most important memory policies are:(下面是两种最主要的内存策略)
- NODE LOCAL. The allocation occurs from the memory node local to where the code is currently executing. (分配在local于当前执行代码node上)
- INTERLEAVE. Allocation occurs round-robin. First a page will be allocated from node 0, then from node 1, then again from node 0, etc. Interleaving is used to distribute memory accesses for structures that may be accessed from multiple processors in the system in order to have an even load on the interconnect and the memory of each node.(按照page使用RR算法在各个nodes上进行分配)
The Linux kernel will use the INTERLEAVE policy by default on boot-up. Kernel structures created during bootstrap are distributed over all the available nodes in order to avoid putting excessive load on a single memory node when processes require access to the operating-system structures. The system default policy is changed to NODE LOCAL when the first userspace process (init daemon) is started.(Linux内核使用INTERLEAVE策略分配,避免在某个node上分配过多内存。用户进程使用NODE LOCAL策略分配)
The active memory allocation policies for all memory segments of a process (and information that shows how much memory was actually allocated from which node) can be seen by determining the process id and then looking at the contents of /proc/<pid>/numa_maps.
5. BASIC OPERATIONS ON PROCESS STARTUP
Processes inherit their memory policy from their parent. Most of the time the policy is left at the default, which means NODE LOCAL. When a process is started on a processor, memory is allocated for that process from the local NUMA node. All other allocations of the process (through growing the heap, page faults, mmap, and so on) will also be satisfied from the local NUMA node.(子进程内存策略继承于父进程, 但是如果所有进程都在一个处理器上的话会造成imbalance)
The Linux scheduler will attempt to keep the process cache hot during load balancing. This means the scheduler’s preference is to leave the process on processors that share the L1-processor cache, then on processors that share L2, and then on processors that share L3, with the processor that the process ran on last. If there is an imbalance beyond that, the scheduler will move the process to any other processor on the same NUMA node.(调度器在解决imbalance的同时也保持提高cache利用率,所以在分配处理器上会尽量保证和父进程使用同一个L1 Cache,然后是L2,L3 Cache. 这个策略是比较符合直觉的)
As a last resort the scheduler will move the process to another NUMA node. At that point the code will be executing on the processor of one node, while the memory allocated before the move has been allocated on the old node. Most memory accesses from the process will then be remote, which will cause the performance of the process to degrade.(最坏的情况是分配在处于其他NUMA node上的处理器,这样如何需要访问父进程内存的话就是remote access)
There has been some recent work in making the scheduler NUMA-aware to ensure that the pages of a process can be moved back to the local node, but that work is available only in Linux 3.8 and later, and is not considered mature. Further information on the state of affairs may be found on the Linux kernel mailing lists and in articles on lwn.net. (等NUMA node上内存空闲的时候在将部分进程和内存迁移回来,这个特性比较高级并且不太成熟。后面提到了可以手工进行迁移,并且对于普通用户只能迁移自己的进程,只有root用户可以迁移所有进程)
6. RECLAIM
Linux typically allocates all available memory in order to cache data that may be used again later. When memory begins to be low, reclaim will be used to find pages that are either not in use or unlikely to be used soon. The effort required to evict a page from memory and to get the page back if needed varies by type of page. Linux prefers to evict pages from disk that are not mapped into any process space because it is easy to drop all references to the page. The page can be reread from disk if it is needed later. Pages that are mapped into a process’s address space require that the page first be removed from that address space before the page can be reused. A page that is not a copy of a page from disk (anonymous pages) can be evicted only if the page is first written out to swap space (an expensive operation). There are also pages that cannot be evicted at all, such as mlocked() memory or pages in use for kernel data.(在可用内存比较少的时候系统会进行回收,根据页面类型不同回收策略也不同。 优先选择在内容在磁盘上存在但是没有被映射到进程空间,因为之后可以很容易读取上来。如果映射到进程空间的话,那么需要标记移除之后在能够被重新利用。如果这个页面没有在磁盘上备份的话,那么先需要被置换到swap上。某些页面比如mlocked或者是kernel数据结构是不能够被换出的)
The impact of reclaim on the system can therefore vary. In a NUMA system multiple types of memory will be allocated on each node. The amount of free space on each node will vary. So if there is a request for memory and using memory on the local node would require reclaim but another node has enough memory to satisfy the request without reclaim, the kernel has two choices:(如果当前node不够使用的话,那么有两种策略,尝试回收local node, 或者是使用remote node)
- Run a reclaim pass on the local node (causing kernel processing overhead) and then allocate node-local memory to the process.
- Just allocate from another node that does not need a reclaim pass. Memory will not be node local, but we avoid frequent reclaim passes. Reclaim will be performed when all zones are low on free memory. This approach reduces the frequency of reclaim and allows more of the reclaim work to be done in a single pass.
For small NUMA systems (such as the typical two-node servers) the kernel defaults to the second approach. For larger NUMA systems (four or more nodes) the kernel will perform a reclaim in order to get node-local memory whenever possible because the latencies have higher impacts on process performance.(对于小NUMA系统比如2nodes来说偏向使用remote node, 而对于大NUMA系统来说偏向使用reclaim local node先,因为remote access会太高)
There is a knob in the kernel that determines how the situation is to be treated in proc/sys vm/zone_reclaim. A value of 0 means that no local reclaim should take place. A value of 1 tells the kernel that a reclaim pass should be run in order to avoid allocations from the other node. On boot- up a mode is chosen based on the largest NUMA distance in the system.(0表示进行不使用local reclaim过程,而1则是优先使用local reclaim)
If zone reclaim is switched on, the kernel still attempts to keep the reclaim pass as lightweight as possible. By default, reclaim will be restricted to unmapped page-cache pages. The frequency of reclaim passes can be further reduced by setting /proc/sys/vm/min_unmapped_ratio to the percentage of memory that must contain unmapped pages for the system to run a reclaim pass. The default is 1 percent. (zone reclaim打开之后后台也会启动轻量回收线程,只回收那些没有被映射到进程空间的page,并且这种page占用内存比率超过一定数量才会开始回收)
Zone reclaim can be made more aggressive by enabling write-back of dirty pages or the swapping of anonymous pages, but in practice doing so has often resulted in significant performance issues.
7. BASIC NUMA COMMAND-LINE TOOLS
The main tool used to set up the NUMA execution environment for a process is numactl. Numactl can be used to display the system NUMA configuration, and to control shared memory segments. It is possible to restrict processes to a set of processors, as well as to a set of memory nodes. Numactl can be used, for example, to avoid task migration between nodes or restrict the memory allocation to a certain node.
Another tool that is frequently used for NUMA is taskset. It basically allows only binding of a task to processors and therefore has only a subset of numactl’s capability. Taskset is heavily used in non-NUMA environments, and its familiarity results in developers preferring to use taskset instead of numactl on NUMA systems.
The information about how memory is used in the system as a whole is available in proc meminfo. The same information is also available for each NUMA node in sys/devices/system node/node<X>/meminfo. Numerous other bits of information are available from the directory where meminfo is located. It is possible to compact memory, get distance tables, and manage huge pages and mlocked pages by inspecting and writing values to key files in that directory.
➜ utils numactl --hardware available: 1 nodes (0) node 0 cpus: 0 1 2 3 4 5 6 7 node 0 size: 8067 MB node 0 free: 4437 MB node distances: node 0 0: 10 ➜ utils numactl --show policy: default preferred node: current physcpubind: 0 1 2 3 4 5 6 7 cpubind: 0 nodebind: 0 membind: 0
8. FIRST-TOUCH POLICY
What matters, therefore, is the memory policy in effect when the allocation occurs. This is called the first touch. The first-touch policy refers to the fact that a page is allocated based on the effective policy when some process first uses a page in some fashion.
The effective memory policy on a page depends on memory policies assigned to a memory range or on a memory policy associated with a task. If a page is only in use by a single thread, then there is no ambiguity as to which policy will be followed. However, pages are often used by multiple threads. Any one of them may cause the page to be allocated. If the threads have different memory policies, then the page may as a result seem to be allocated in surprising ways for a process that also sees the same page later.
First-touch phenomena limit the placement control that a process has over its data. If the distance to a text segment has a significant impact on process performance, then dislocated pages will have to be moved in memory. Memory could appear to have been allocated on NUMA nodes not permitted by the memory policy of the current task because an earlier task has already brought the data into memory.
内存策略只在这块内存初次分配(使用)时有效,所以也会造成一些看起来比较诡异的性能问题。比如某些C library最开始在node0上面进行分配, 那么意味着所有在node1上运行的进程,如果要使用C library的话都需要cross-node的访问。对于这种shared text segment的话,如果可以在两个node都存储一份就会很好。
9. MOVING MEMORY
Linux has the capability to move memory. The virtual address of the memory in the process space stays the same. Only the physical location of the data is moved to a different node. The effect can be observed by looking at /proc/<pid>/numa_maps before and after a move.(虚拟地址保持不变而物理地址移动到其他node上去)
Migrating all of a process’s memory to a node can optimize application performance by avoiding cross-connect accesses if the system has placed pages on other NUMA nodes. However, a regular user can move only pages of a process that are referenced only by that process (otherwise, the user could interfere with performance optimization of processes owned by other users). Only root has the capability to move all pages of a process.(迁移pages涉及到权限问题)
It can be difficult to ensure that all pages are local to a process since some text segments are heavily shared and there can be only one page backing an address of a text segment. This is particularly an issue with the C library and other heavily shared libraries.(一些正文段可能不仅仅被一个进程共享,所以迁移起来会有点麻烦)
Linux has a migratepages command-line tool to manually move pages around by specifying a pid and the source and destination nodes. The memory of the process will be scanned for pages currently allocated on the source node. They will be moved to the destination node.
10. NUMA SCHEDULING
The Linux scheduler had no notion of the page placement of memory in a process until Linux 3.8. Decisions about migrating processes were made based on an estimate of the cache hotness of a process’s memory. If the Linux scheduler moved the execution of a process to a different NUMA node, the performance of that process could be harmed because its memory now needed access via the cross-connect. Once that move was complete the scheduler would estimate that the process memory was cache hot on the remote node and leave the process there as long as possible. (numa scheduling是根据进程在某个node上执行cache命中率,来决定是否需要将进程移动到其他node上执行)
As a result, administrators who wanted the best performance felt it best not to let the Linux scheduler interfere with memory placement. Processes were often pinned to a specific set of processors using taskset, or the system was partitioned using the cpusets feature to keep applications within the NUMA node boundaries.
In Linux 3.8 the first steps were taken to address this situation by merging a framework that will eventually enable the scheduler to consider the page placement and perhaps automatically migrate pages from remote nodes to the local node. However, a significant development effort is still needed, and the existing approaches do not always enhance load performance. This was the state of affairs in April 2013, when this section was written. More recent information may be found on the Linux kernel mailing list on http://vger.kernel.org or in articles on Linux Weekly News (http://lwn.net). See, for example, http://lwn.net/Articles/486858/. (kernel如果可以自动做页面迁移就非常好,但是似乎这个工作有许多细节问题)