Nobody ever got fired for buying a cluster
Table of Contents
https://www.microsoft.com/en-us/research/publication/nobody-ever-got-fired-for-buying-a-cluster/ @ 2013
这篇文章主要是想说明,可能在很多时候,集群并不是那么地cost-effective(从performance / $ 上来对比)。所以在很多时候,scale-up方案可能是更好的选择,此外scale-up在实现上也会更加容易。
1. Asbtract
Hadoop/MapReduce是针对PB级别的数据来设计的,而很多时候的任务输入数据量在100GB左右。
Is this the right approach? Our measurements as well as other recent work shows that the majority of real- world analytic jobs process less than 100 GB of input, but popular infrastructures such as Hadoop/MapReduce were originally designed for petascale processing. We claim that a single “scale-up” server can process each of these jobs and do as well or better than a cluster in terms of performance, cost, power, and server density.
2. Introduction
MS和Yahoo的任务输入数据量的中位数是14GB, FB的90%的任务输入数据量在100GB以下。
First, evidence suggests that the majority of analytics jobs do not process huge data sets. For example, at least two analytics production clusters (at Microsoft and Ya- hoo) have median job input sizes under 14 GB, and 90% of jobs on a Facebook cluster have input sizes under 100 GB.
另外一些算法很难被实现成scale-out的方式。
Second, many algorithms are non-trivial to scale out efficiently. For example, converting iterative-machine learning algorithms to MapReduce is typically done as a series of MapReduce rounds. This leads to significant data transfer across the network between the map and re- duce phases and across rounds. Reducing this data trans- fer by changing the algorithm is expensive in terms of human engineering, may not be possible at all, and even if possible results in an approximate result.
作者对比scale-up和scale-out的方法也很有意思,是直接修改Hadoop框架让Hadoop可以更有效地在单机上运行,来对比scale-up/out的性能。
While vanilla Hadoop performs poorly in a scale-up configurations, a series of optimizations makes it com- petitive with scale-out. Broadly, we remove the initial data load bottleneck by showing that it is cost-effective to replace disk by SSDs for local storage. We then show that simple tuning of memory heap sizes results in dra- matic improvements in performance. Finally, we show several small optimizations that eliminate the “shuffle bottleneck”.
3. Job sizes and example jobs
这节作者选了几个比较典型的分析jobs,附上input/shuffle/output数据量大小。具体每个job在论文里面有详细的描述。
4. Optimizing for scale-up
如何针对Hadoop来做scale-up的优化,下面几点:
- 优化Storage(directly access local file system)
- Concurrency(thread vs. process,这个差别不大)
- Shuffle(取消并发限制并且直接访问本地文件,这个差别很大)
- 调整Heap size(更加有效地利用大内存但同时避免big overhead of GC)
Shuffle优化对scale-up性能影响很大。其他都不是特别重要,这点也说明了为什么scale-up方案在public cluster(cloud)上面也可以工作的很好。
In a cluster, this is a reasonable throttling scheme to avoid a single node getting overloaded by copy requests. However it is unnecessary in a scale-up config- uration with a fast local file system. Removing this limit substantially improves shuffle performance. Finally, we observed that the scale-up machine has substantial ex- cess memory after configuring for optimal concurrency level and heap size. We use this excess memory as a RAMdisk to store intermediate data rather than using an SSD or disk based file system.
5. Evaluation
6. Discussion
public cluster(cloud)和private cluster的区别主要是两个方面:
- 输入来源基本上不太可能是HDFS,而是类似云端存储系统比如S3
- 即便是本地文件系统通常也是网络磁盘比如EBS这样的东西
不过从上面可以知道,scale-up的瓶颈并不是在这两个方面。
The key difference from a private cluster is that in the cloud, HDFS is unlikely to be used for input data and the compute nodes, at least today, are unlikely to use SSD storage. Instead, input data is read over the net- work from a scalable storage back end such as Amazon S3 or Azure Storage. Intermediate data will be stored in memory and/or local disk.
可以看到运行在public/private cluster的scale-up方案,性能差别并不是很大(92%)
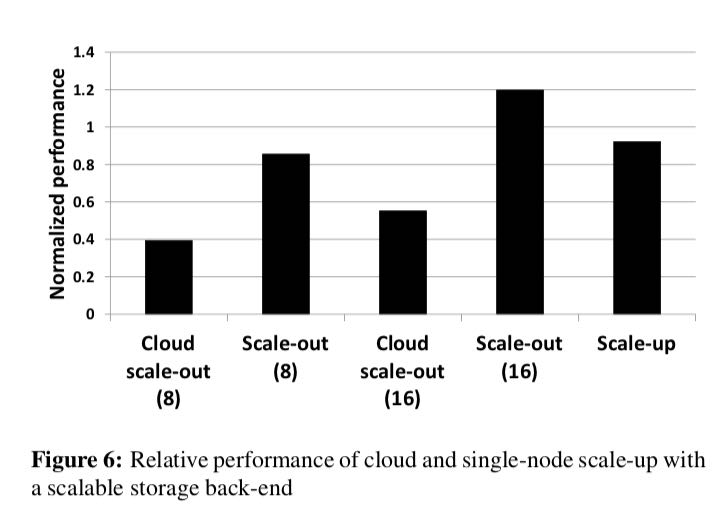
More importantly, the scale-up configuration when reading data from the network comes close (92%) to that of a scale-up configuration when using SSDs. Hence we believe that with a 10 Gbps NIC, and a scalable stor- age back-end that can deliver high bandwidth, our results from the private cluster also hold for the cloud.
scale-up的问题在于memory access会成为瓶颈,这个时候scale-out就会更加合适。并且随着输入数据量的增大,memory-bound就会成为问题,而这个时候scale-out的优势才会显现出来。
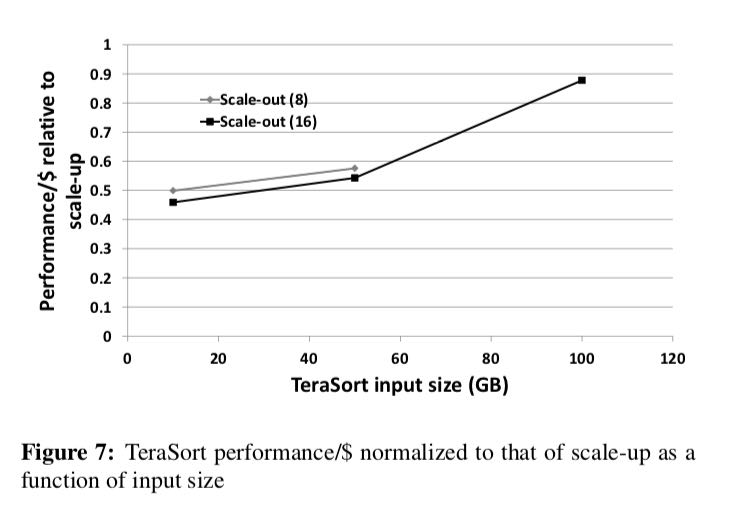
These results tell us two things. First, even with “big memory”, the scale-up configuration can become memory-bound for large jobs. However we would ex- pect this point to shift upwards as DRAM prices continue to fall and multiple terabytes of DRAM per machine be- come feasible. Second, for TeraSort, scale-out begins to be competitive at around the 100 GB mark with current hardware.
对scale-up有个很经典的误区在于,我们是否可以使用少数的high-end机器组成cluster, 来代替大量的low-end机器组成的cluster呢?这种方法效果并不是很好,因为它会牺牲shuffle的性能优化,使得performance / $ 下降。所以正确的部署方式是:a. 单台high-end server(scale-up) b. 多台low-end servers(scale-out).
We note that in theory it is also possible to scale out using large machines, i.e. combine scale-up and scale- out, and hence use fewer machines (e.g. 2 instead of 32). However this would sacrifice the 4x performance bene- fit of our shuffle optimizations (using the local FS, un- restricted shuffle, and a RAMdisk for intermediate data) while also losing the pricing advantage of the low-end machines. Thus at current price points it seems that the choice is effectively between scale-up on a large machine versus scale-out on a large number of low-end machines.