Sequence Models
Table of Contents
1. RNN(Recurrent Neural Network)
序列模型针对输入是序列数据的应用,比如: 语音识别(Speech Recoginition) 音乐生成(Music Generation) DNA顺序分析(DNA Sequence Analysis) 机器翻译(Machine Translation)
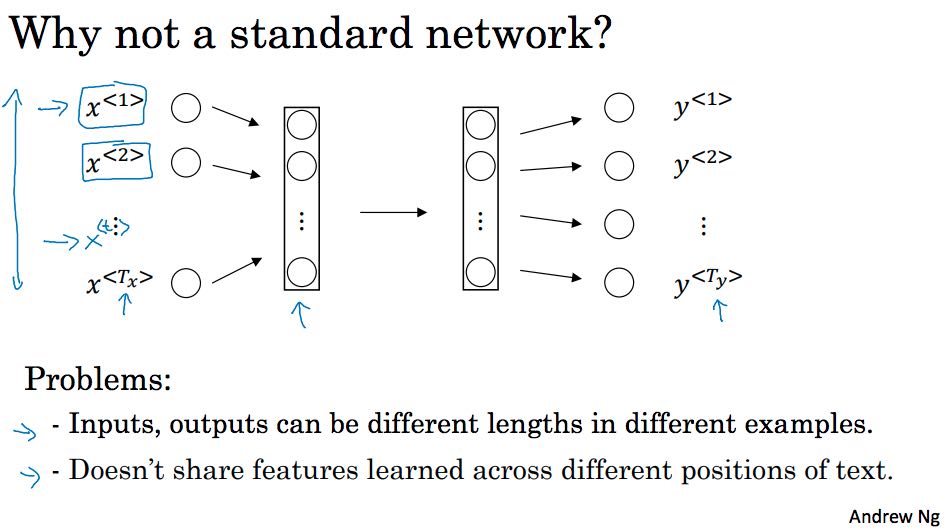
循环神经网络(模型Recurrent Neural Network Model)是一种序列模型。它仅仅是个模型,可以有许多中实现。标准的神经网络没有办法解决两个问题:1. 输入和输出要求是固定长度,虽然这个可以通过一些方法绕过去比如通过pad 2. 更重要的问题是没有办法分享在不同position上学习到的特征,因为序列数据也是存在相互关系的,而标准网络没有共享表示这些关系的参数,所以带来不必要的模型复杂度以及引入大量的无用参数。
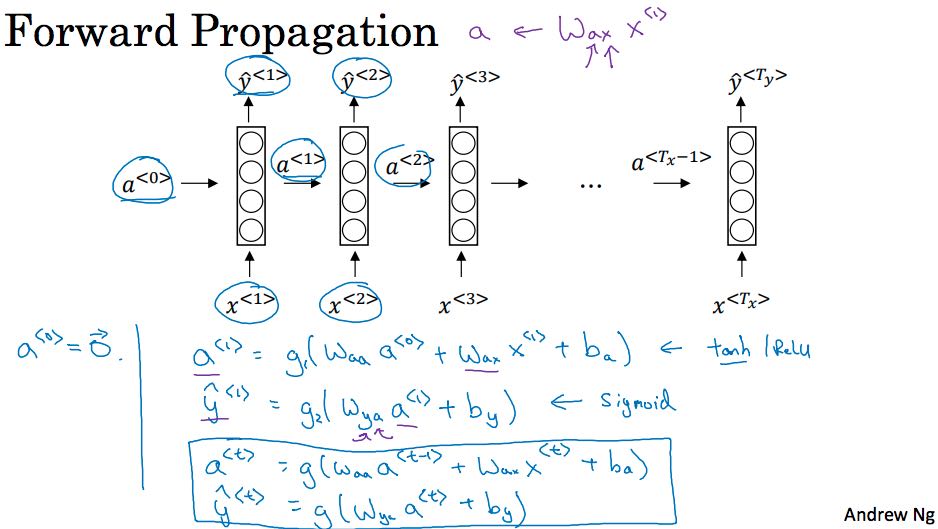
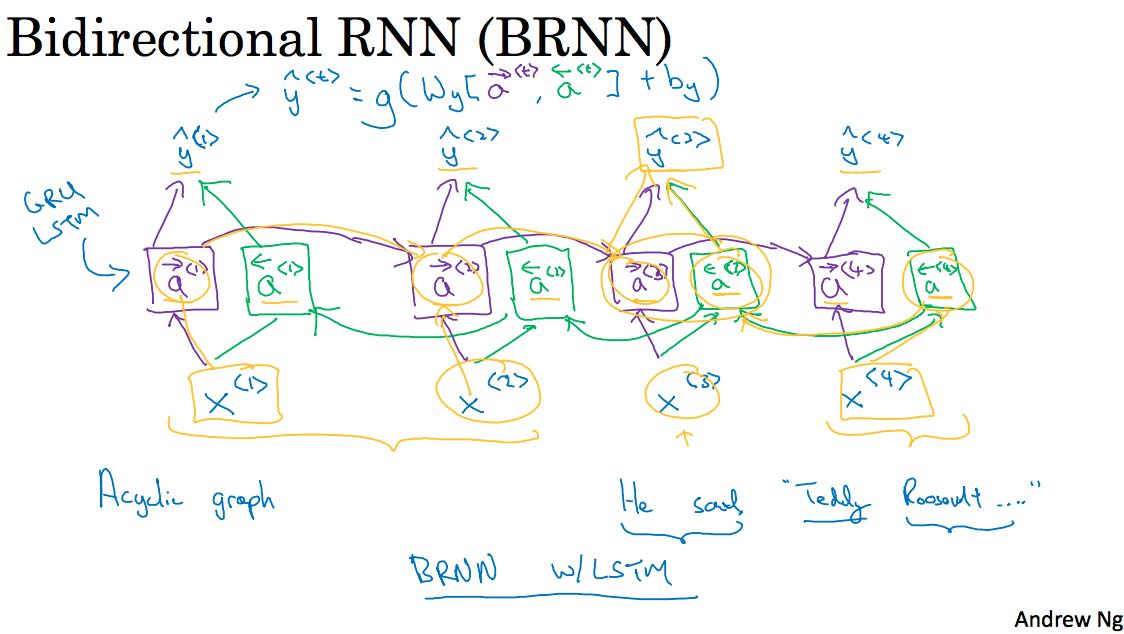
RNN会考虑序列数据前后之间的联系。下图是RNN的两种表示方法,右边的比较简单,左边的则更加接近于现实。一个NN处理序列数据中的一个元素,然后将这些NN全部连接起来,之间通过状态数据(途中的a)来传递序列所包含的上下文信息。如果序列信息传递方向是单向的话,那么就是标准的RNN,不过有时候传递信息是双向的,就需要引入BRNN(Bidirectional RNN). 比如图中举的例子,“Teddy”必须看到后面”President”或者是 “Bears” 才能知道是总统还是熊。RNN的前向传播入下图所示,a<t>以a<t-1>和X<t>作为输入. 然后Y<t>以a<t>作为输入。

按照输入和输出区分,RNN有下面这些类型
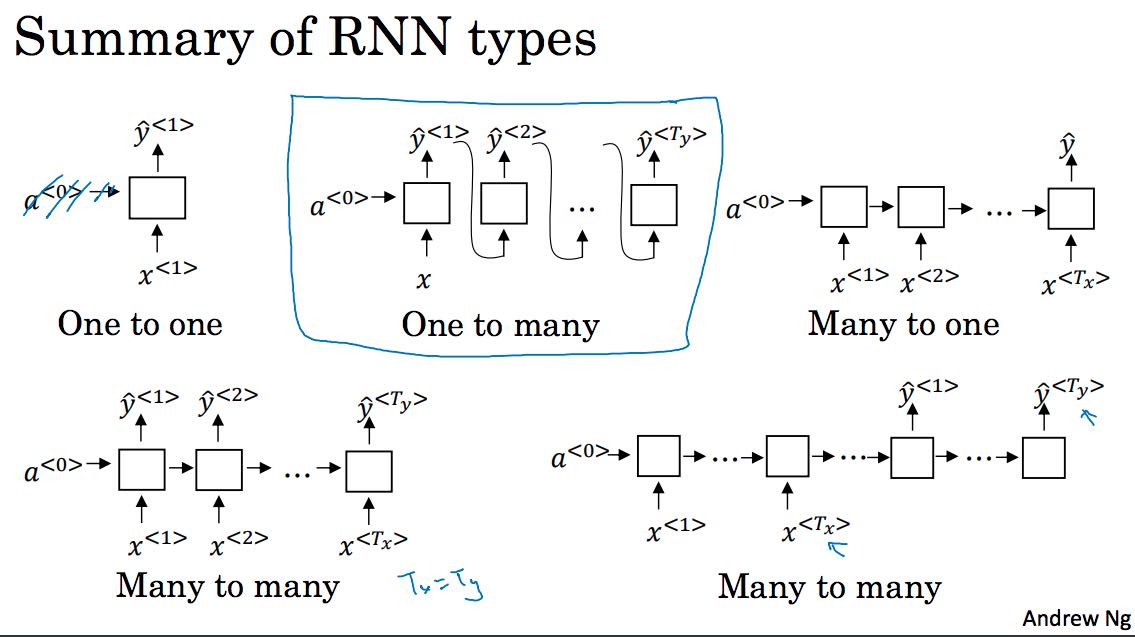
通常RNN的深度比较大,容易出现vanishing gradient的问题。为了解决梯度消失的问题,实践中很少使用上图中navie的实现,而是更精巧的实现。这些实现可以解决梯度小时问题,并且可以将状态传递到更远的距离,从而可以学习更长的序列数据。GRU(Gated Recurrent Unit)和LSTM(Long Short-Term Memory)就是这两种实现。历史上,LSTM出现的更早也更加复杂,GRU在LSTM上改进产生的也更加简单,计算量也就更小。如果没有特殊需求或者是偏好的话,使用LSTM是个不错的选择,除非计算量过大或者是GRU明显更加适用时才使用GRU。
我觉得讨论Unit之前最好先看看实践中的网络是什么样的。
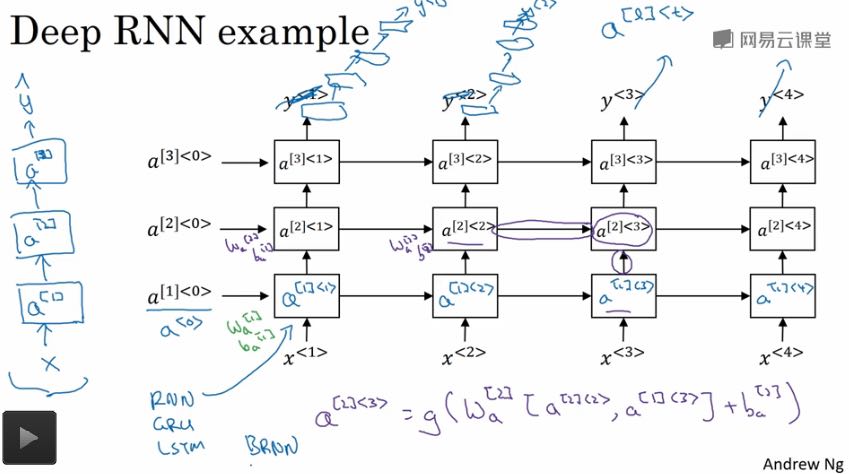
里面每个方格对应的是一个Unit,然后在每个时序对应的网络上,Unit是堆叠起来的。然后这个堆叠高度不能太大,否则数据量会非常大,通常控制在3层以内。我们可以选择性地将最上层的Unit作为输入,接入一个标准NN来得到最终的输出,而不是直接使用最上层的Unit作为输出。
下图是GRU的内部结构
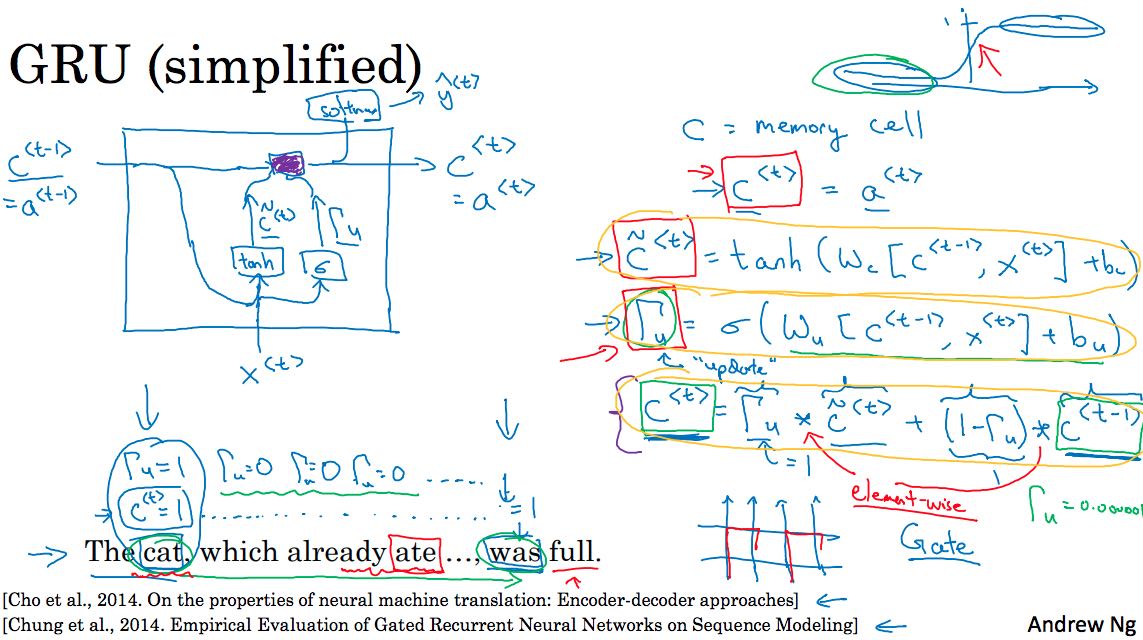

其中c是内部状态,Tu(update gate)表示如何根据当前状态和上个状态确定下一个状态,Y根据c计算得出,Tr(relevance gate)表示上个状态和当前状态的关系。
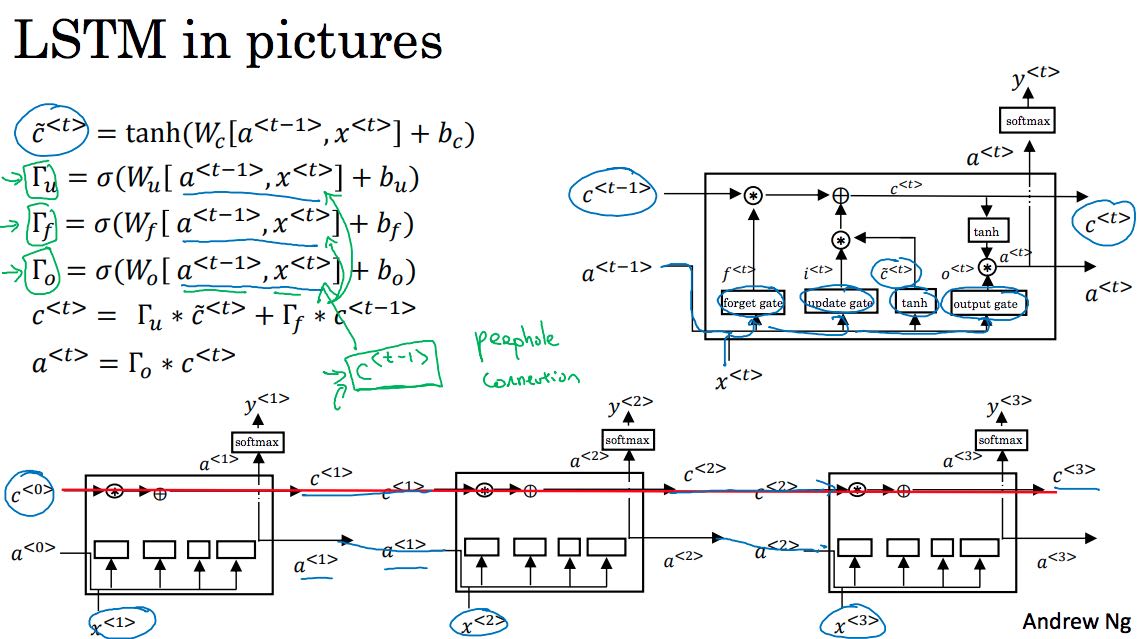
LSTM相比GRU则引入了更多的状态,除了Tu(update gate)还有Tf(forget gate)以及To(output gate)

双向RNN(BRNN)和RNN非常类似,只不过除了传递前向状态之外,还增加了后向状态传递,前后状态共同决定输出。比如下图中y<2>, 由正向a<3>和反向a<3>共同决定,而反向a<3>则由x<3>和反向a<4>决定,反向a<4>由x<4>决定。BRNN要求输入序列是完整并且长度固定,但是在一些场景比如连续语音识别上,除非有刻意停顿否则很难认为输入已经完全ready。
2. Word Embedding
相关链接:
- 淺談降維方法中的 PCA 與 t-SNE – D&D mag – Medium
- word2vec原理(一) CBOW与Skip-Gram模型基础 - 刘建平Pinard - 博客园
- word2vec原理(二) 基于Hierarchical Softmax的模型 - 刘建平Pinard - 博客园
- word2vec原理(三) 基于Negative Sampling的模型 - 刘建平Pinard - 博客园
word embedding就是将单词使用向量表示出来,比如使用OneHot表示。这种方法比较简单,但是有两个缺陷:1. 没有办法展现出单词之间的关系 2. 如果vocabulary过大的话,那么向量长度也非常大。好的表示应该解决这两个问题:向量可以体现单词潜在的语义展现单词之间的关系,并且向量长度可以根据需要进行调整。课程里面介绍了两种算法来计算表示:word2vec和GloVe.
为了可以可视化单词之间的关系,我们需要将向量进行降维映射到2维平面上,PCA和clustering就是这类降维方法。在课程里面还提到另外一种方法t-SNE. 我理解这个方法相比PCA, clustering,更加适合非线性程度高的数据。
我们以word2vec来解释学习embedding的过程,这个过程输入数据称为context, 输出数据称为target. word2vec有两种不同的模型:
- 如果context是一个word, target是这个word的前后words的话,那么这个模型称为skip-gram
- 如果context是某个word的前后words,而target是这个word的话,那么这个模型称为continous bag-of-words
skip-gram和CBOW互为镜像。
继续深入skip-gram这个模型。它的输出是一个softmax层,其中分母的计算量会非常大。一个改进方式是用hierarchical softmax,将多个二分类器按照huffman tree的方式连接起来。更简单的方式是用negative sampling模型,输出不是softmax,而是多个二分类器。在选择negative sample上,我们可以尽可能避开使用stop-words作为负样例。文章里面给出了公式,如何将单词出现频率映射成为选择概率。
除了word2vec之外,还有个算法可以学习embedding. GloVe(global vectors for word representation). 算法比word2vec简单,我理解在大规模的语料库上训练的话,效果应该和word2vec同样的好。主要原理是根据(context, target)出现次数来学习embedding.
有了word embedding之后,就可以开始搞些NLP应用了,课程里面提到两个应用:
- 情感分类。处理这个问题上,不能仅仅从孤立的单词上去分类,还应该考虑上下文。所以最好用RNN来搞。
- 词嵌入除偏(debias). 这里的除偏是指消除人们文字语言里面的歧视比如性别歧视。大致原理是,使用几个和性别相关的词语对作为anchor, 比如man/woman, grandfather/grandmother,计算出bias direction. 然后将其他和性别歧视相关的词映射到non bias-direction上,最后调整这些性别相关的词语对,和性别其实相关词的距离。

3. Machine Translation
这节主要说的应用是机器翻译(MT, machien translation). 在最开始也提到了image captioning. 这两个应用非常相似,差别在于MT输入是自然语言,而后面一个应用输入是图像。使用的模型都是课程最开始提到的many-to-many RNN. 因为Tx != Ty, 所以确切地说是右下方的模型。
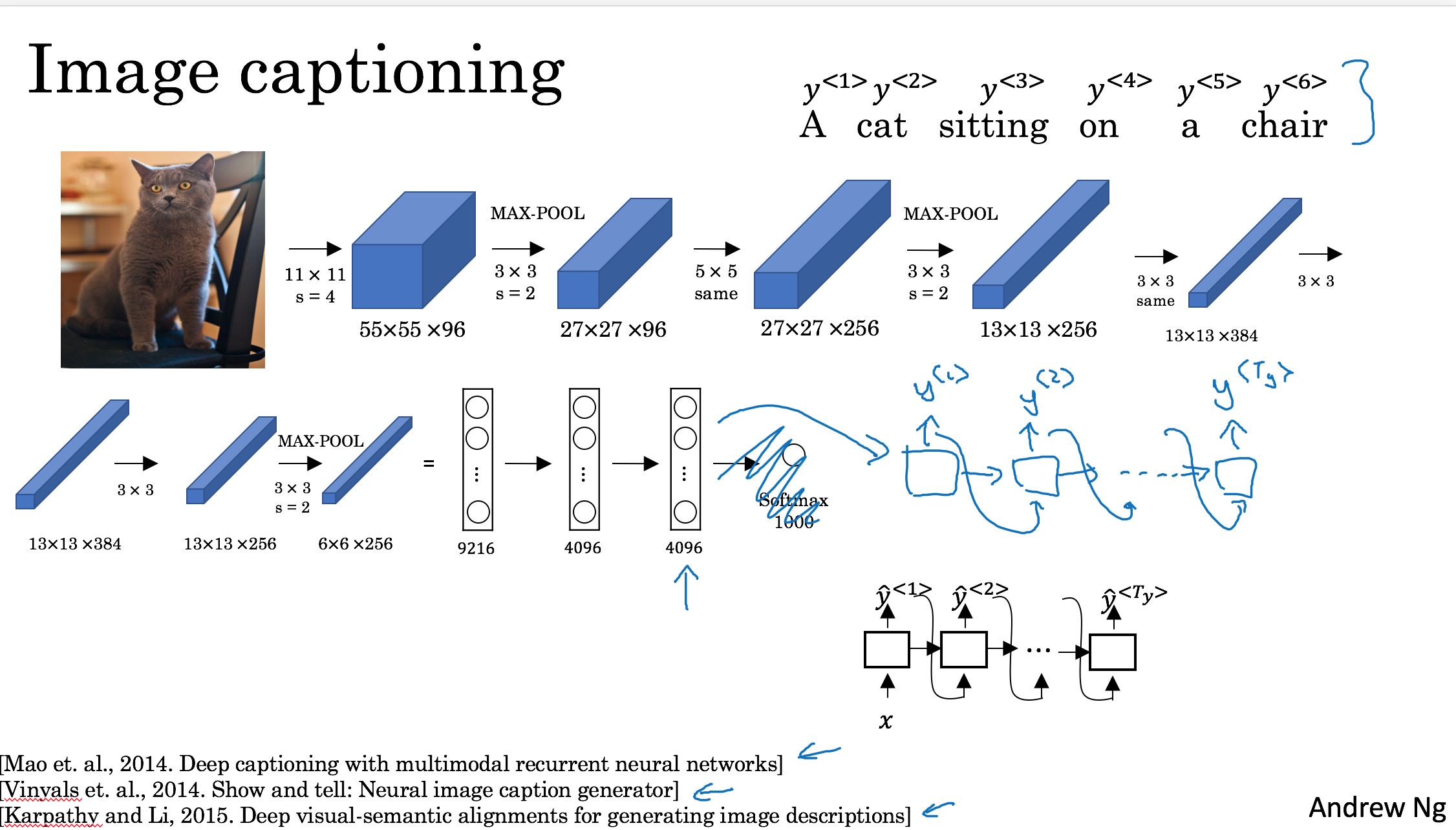
这种many-to-many RNN分为两个部分:encoder-decoder. encoder是将输入编码,decoder部分则负责解析编码然后输出。
我们还是以MT为例,有几个问题需要解决:
- 在输出过程中,如果有多个选项,如何进行选择(beam search, length norm)
- 如何对错误分析,定位是encoder还是decoder问题(error analysis)
- 对结果如何评判好坏(Bleu, Bilingual evaluation understudy)
- 如何解决翻译长输入问题(attention model)
在输出阶段,如果每个step都是选择概率最大输出的话(greedy search), 并不能保证最终输出序列的概率最大。P(y<t> | x, y<1>, y<2>, … y<t-1>) 最大,不能保证P(y<Ty>, y<Ty-1> … y<1> | x)最大。我们可以使用beam search(束搜索)来改进,原理就是同时保持B个当前观察到的最大概率序列。很明显B越大,选择到最大概率的输出序列的几率也就越大,但是同时会耗费更多的计算和内存资源。通常产品中B=100左右,研究时选择B=1000 or 10000这样。
在beam search时,概率是相乘的,但是数值稳定性不好,所以可以改成log然后相加。此外,随着Ty越大,概率越小,所以为了可以平衡长语句的概率,用length norm操作。具体地说就是乘以 1 / (Ty ** alpha) 来平衡。默认alpha是1,如果我们希望输出长语句的话,可以将alpha减小比如0.7, 0.2这样。
我们在做错误分析时,假设输出是y^, 而人类的标准是y*,那么我们可以对比P(y^|x)和 P(y*|x)来确定是encoder or decoder需要改进:
- 如果P(y^|x) > P(y* |x)的话,说明我们认为选择比人类的要好(而事实上是不可能的),所以我们倾向认为encoder部分没有学习到足够的特征
- 如果P(y^|x) < P(y*|x)的话,那么说明事实上我们存在更好的选择序列,但是却没有找到,是decoder部分的问题,所以应该加大B值。
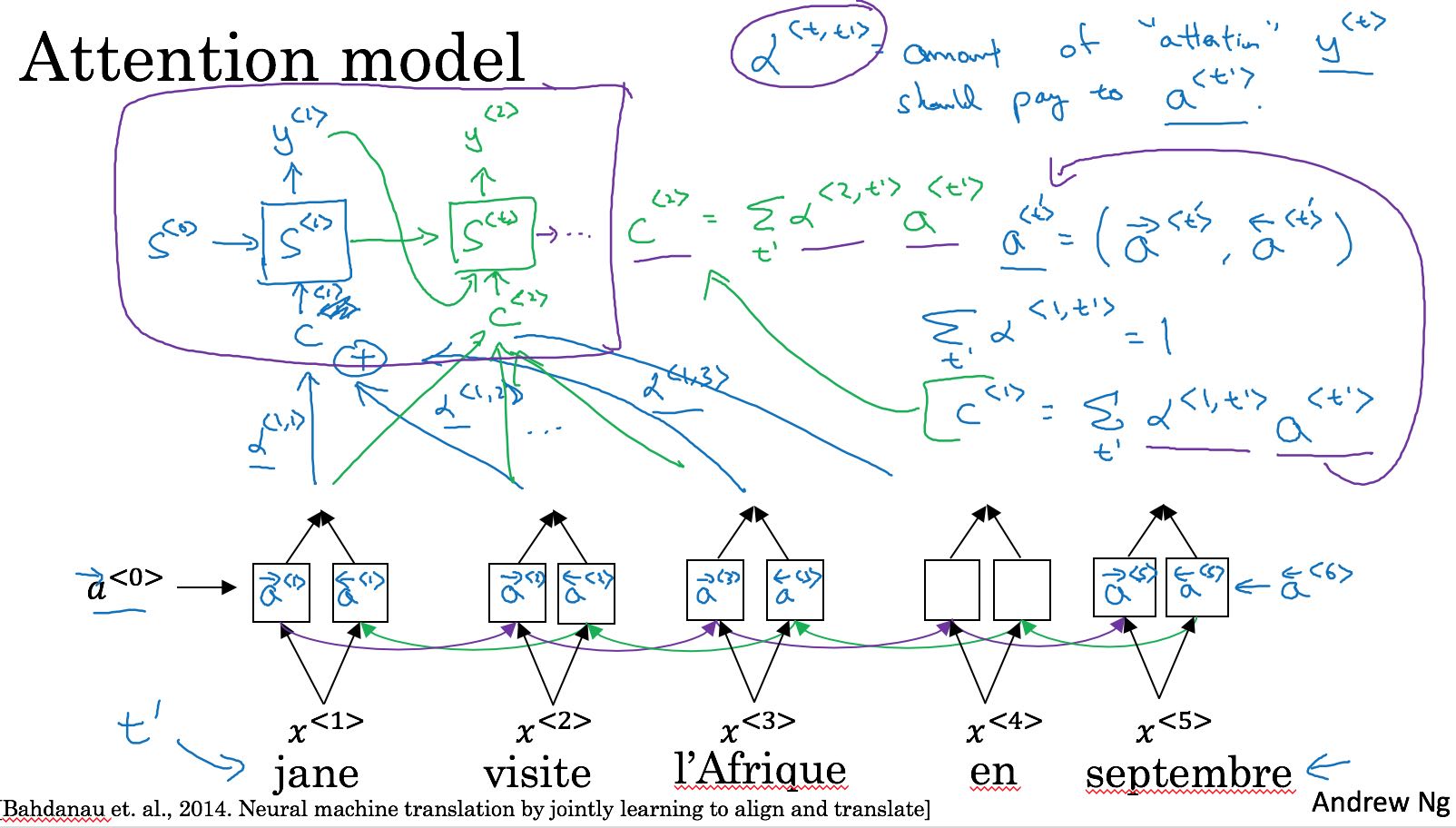
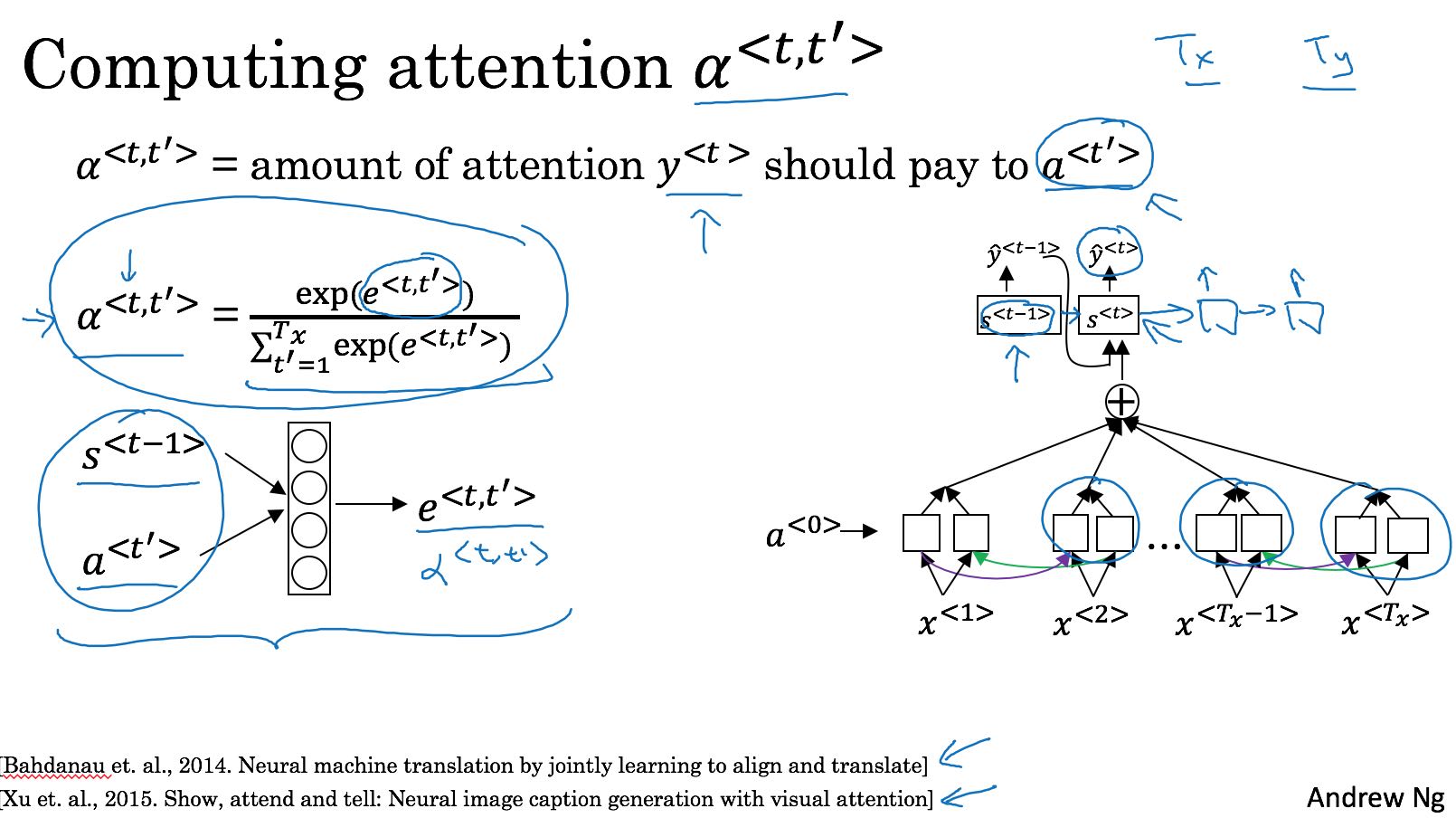
我理解这种encoder/decoder有个很大的问题,就是如果encoder阶段输出状态不够大,或者是没有办法将序列性质(比如某个词的翻译可能和前后几个词相关)包含进去的话,那么在输出长句时效果会很差。Attention Model 将decoder放在encoder之上,而不是之后,来解决翻译长句的问题。以下图为例,encoder是一个BRNN, decoder每个unit的输入包含多个附近的encoder的输出。其中alpha<t, t’> 表示 encoder的a<t’>对 y<t>的影响因子。