Neural Networks and Deep Learning
Table of Contents
连续花费了几天突击了这门 课程. 这门课程并不难学,但是里面提到了一些BP的推导,并且给出了DNN的完整实现,为NN/DL的学习提供了基础知识。如果你已经对NN/DL有一定的了解,而且也可以比较熟练地使用python numpy这套东西的话,基本上没有什么难度。
学习这门课程的前面几天,正好我在看 这本书 。看上去这本书没有什么名气,我也不知道从什么地方找到的。粗略地看了里面一些内容,觉得它对于BP的分析让我有点启发。正好这门课程也是关于NN/DL的基础知识,所以就干脆写在一起吧。
几个比较小的tricks:
- 初始化weight的时候,可以 *0.001。让初始A尽可能地小,这样学习起来更快。
- tanh比sigmoid好。如果z=0的话,sigmoid(z)=0.5, 还会触发后层,而tanh(z)=0更加如何直觉吧。
- relu(rectified linear unit) & leaky relu. 在x>0的时候导数保持常数而不会消失。
1. 规范符号
我觉得这门课程对我最大的帮助就是规范符号。作者总结了个 pdf 来总结和规范这些符号。
下面是我个人的笔记:
- 小写和大写字符。小写表示一个训练case, 大小表示多个训练cases.
- x, X
- z, Z
- a(activation), A
- nx表示# of features, m表示# of training examples
- 输入X的维度是(nx, m). 这样表示最方便计算
- 多个examples垂直地堆积起来
- W(l)的维度就是(L(l+1), L(l)), 这样可以直接W(l) * A(l-1)
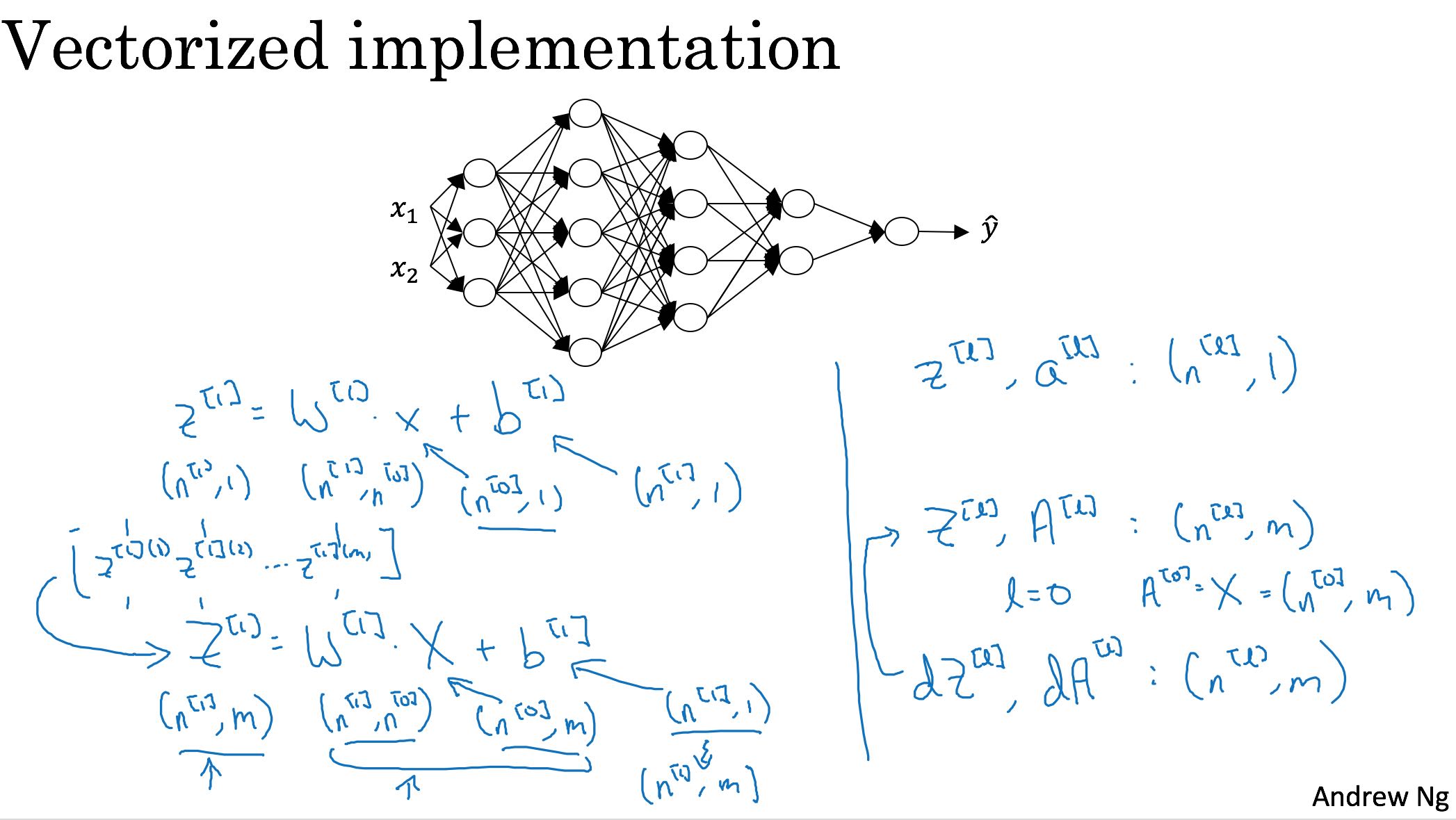
上图可以看到Z是在column(axis=1)轴上堆积起来的。这样规定维度推导起来就不用老惦记着转置了。
2. FP和BP的公式推导
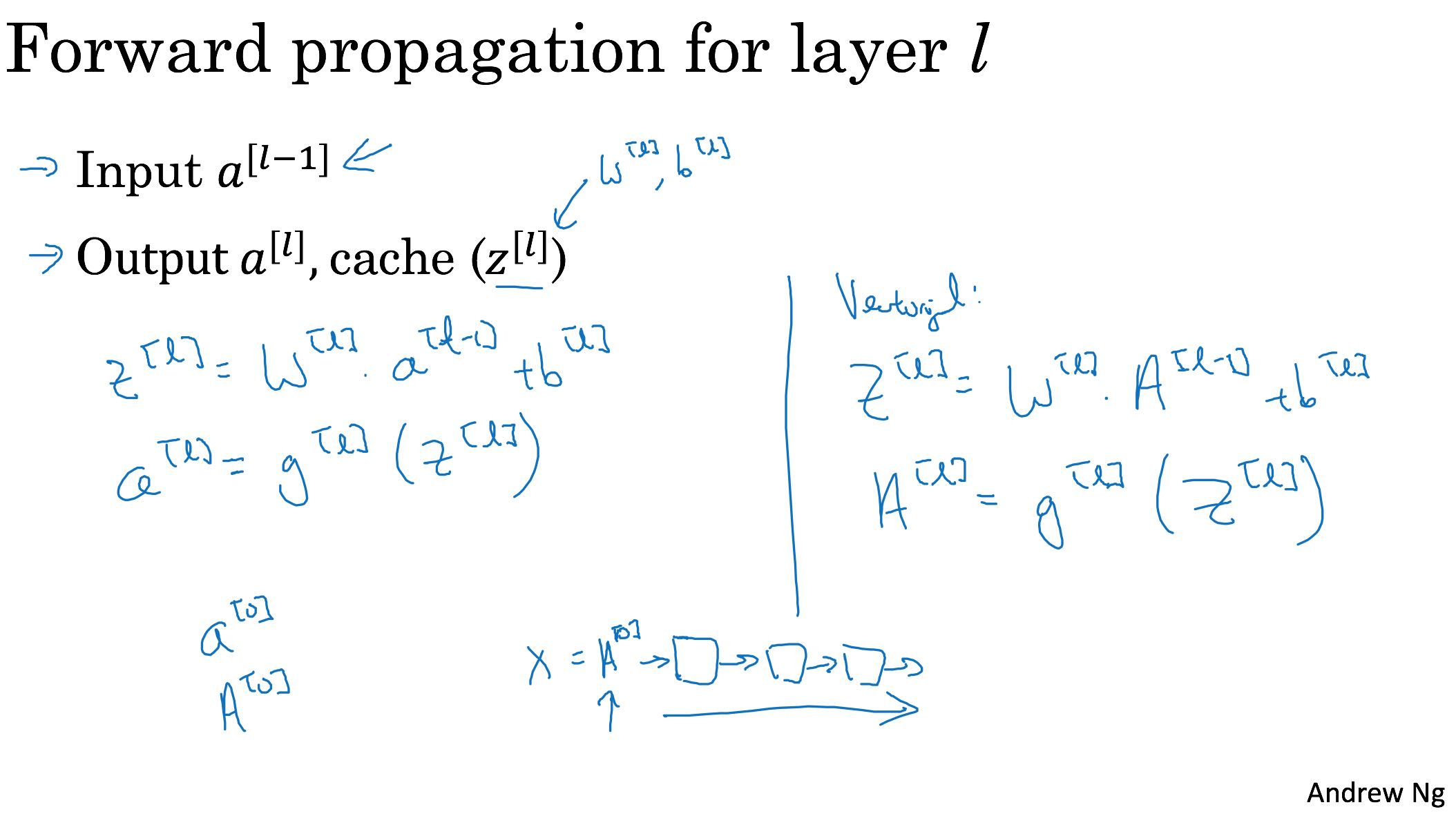

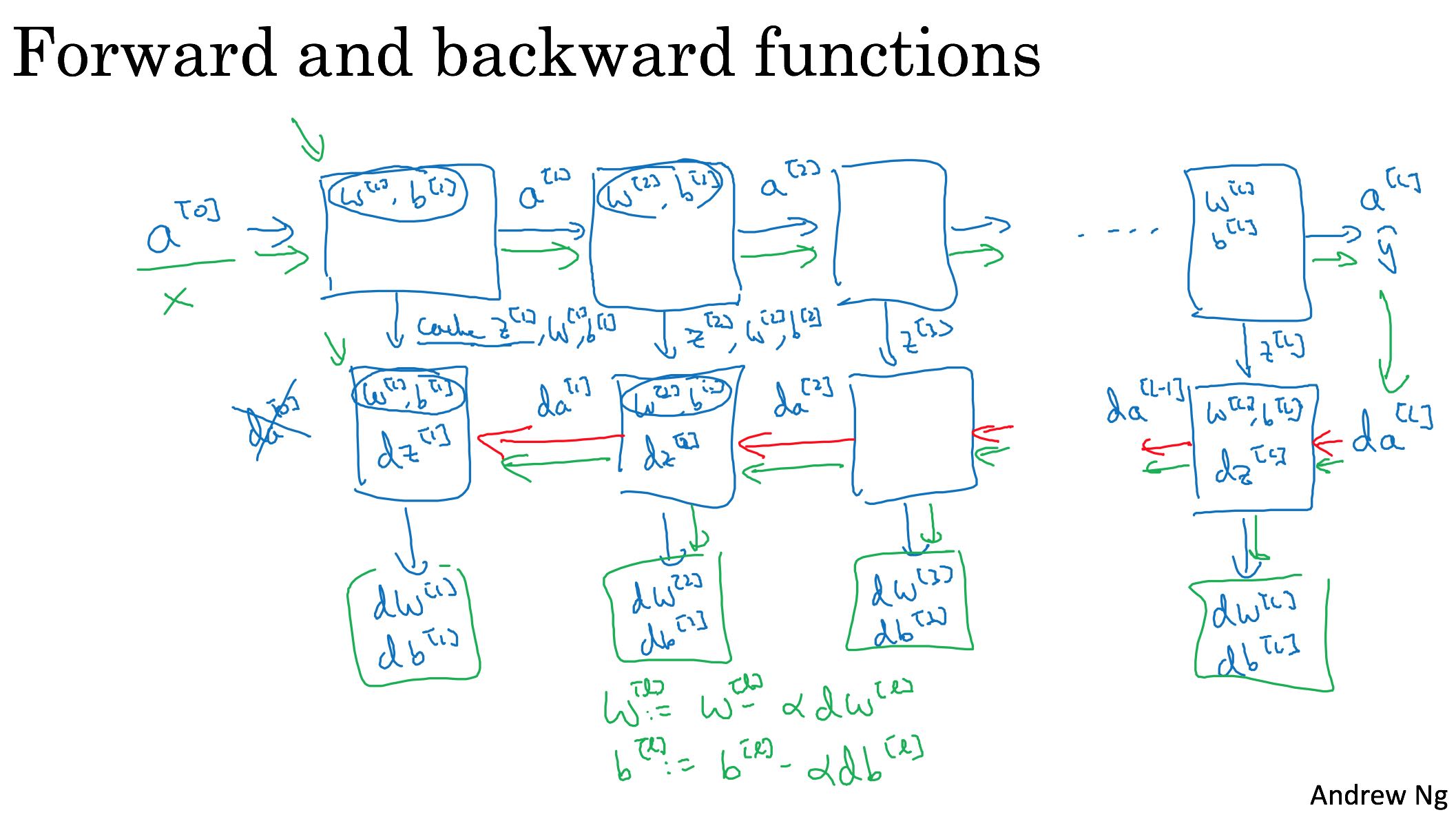
只要花点时间,还是可以自己推导出来的。在实现bp的时候,需要拿到A(l-1)以及A(l)这些数据,所以在做fp的时候,需要把每层得到的数据都缓存(caches)起来。
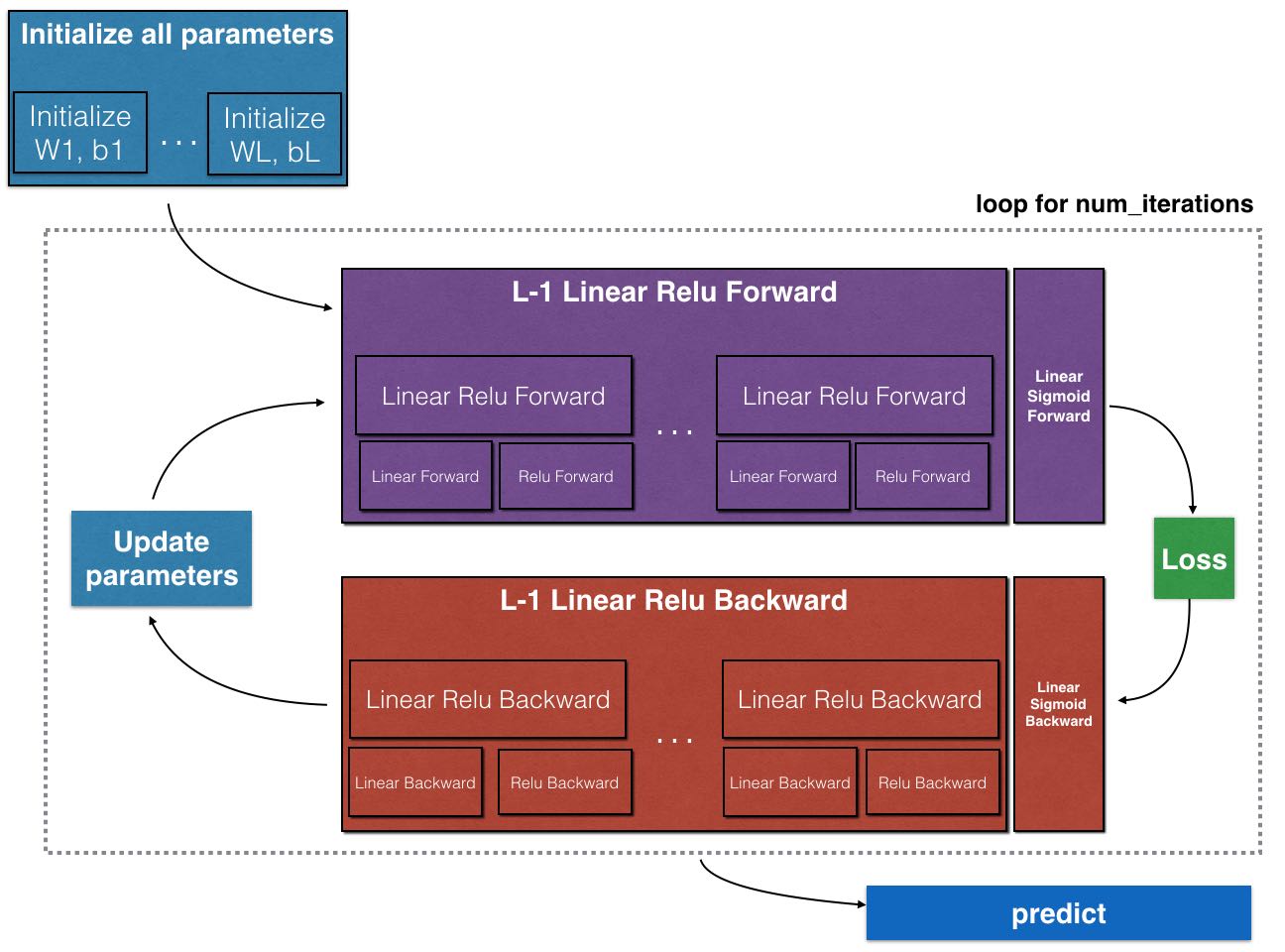
iteration flow如下图:
- 初始化parameters
- 迭代下面几步
- fp并且保存每层的cache
- 计算cost, 并且计算dAL
- 根据dAL,结合每层的cache,做bp
- 在bp的过程中得到每层的parameters的delta
- 更新parameters
3. Chain Rule.
微积分的连锁律,很符合直觉。比如z = g(f(x))的话,那么dz/dx = dg/df * df/dx.
很长一段时间内,我对下图没有办法通过公式推导出来. 如果out=A*B的话,那么dout/da = B, 那么da = dout / B才对
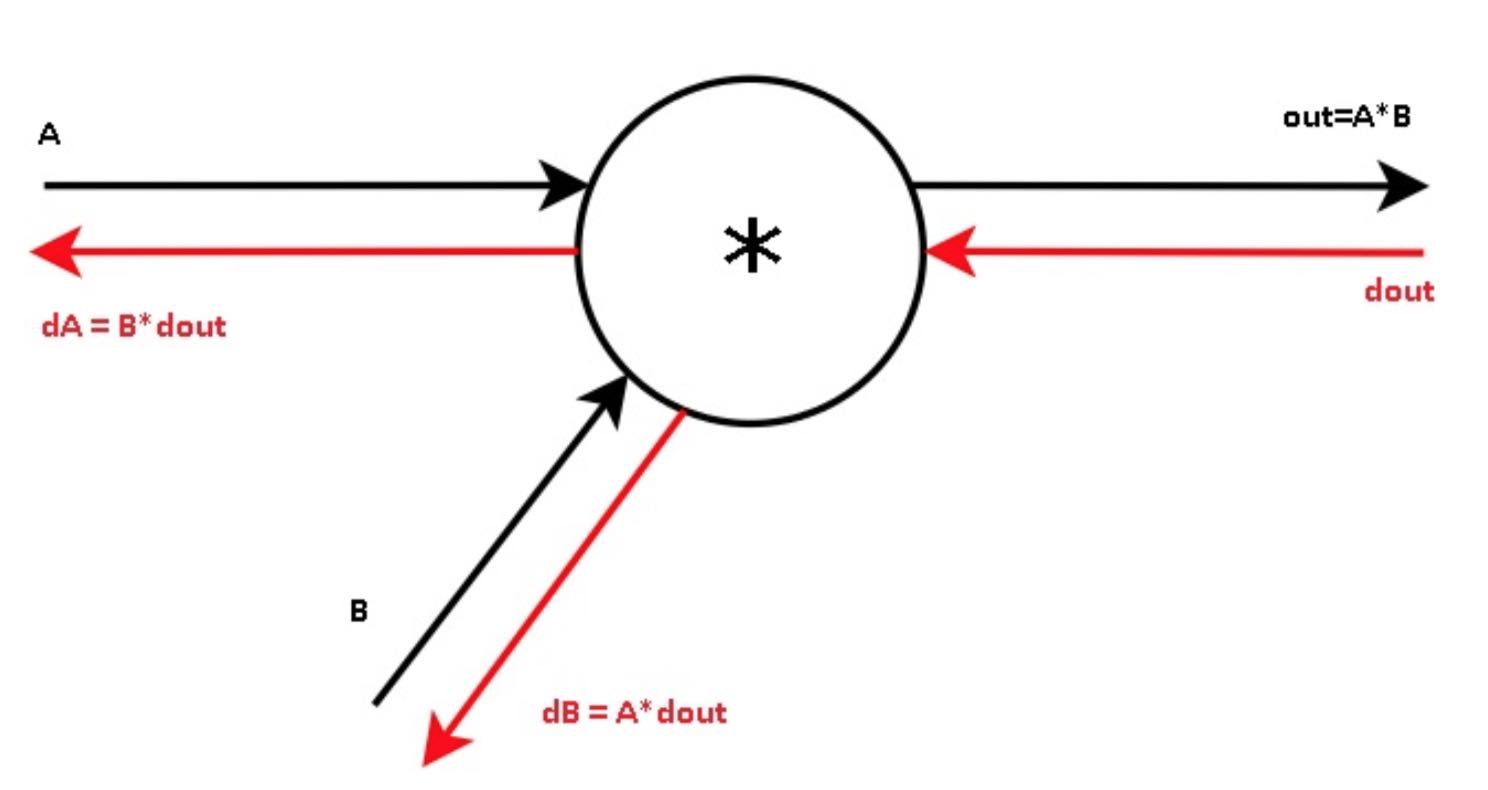
上来这门课程才知道,原来dout是(dL/dout,这里的d可以认为是偏微分)的缩写,相当于是损失函数在out这个变量上的导数。所以dout开头这个d并不是偏微分,而应该理解为delta.
如果这样的话就好理解了。da = dL/da = dL/dout * dout/da = dout * B. (这里大家注意区分d是delta还是偏微分符号).
按照上面的原理,我们就可以得到很多函数的bp公式了:
- ReLU(x) = max(x, 0). 那么dx = dout if x >=0 else 0
- Dropout(x) = x * p. 其中p可以认为是开关。那么dx = dout * p