MSR FaRM No compromises: distributed transactions with consistency, availability, and performance
https://pdos.csail.mit.edu/6.824/papers/farm-2015.pdf
我觉得这篇文章好像没有提出什么特别的新观点,只是给出了一个需要硬件配合的,基于对象的,乐观并发控制(optimistic concurrency control)的编程模型。
这个编程模型是需要特殊硬件配合的,包括non-volatile DRAM和RDMA. 事实上我觉得从原理上来说,这两个东西其实都可以不用。 将DRAM换成SSD,去掉RDMA,这个系统应该同样可以跑起来,只不过速度稍微慢一些。文章里面使用的non-volatile DRAM不是传统的 NVDIMM,而是DIMM+UPS. 在检查到掉电之后,UPS继续供电将内存里面的内容刷到多个SSDs上面。这样设计下来,成本是NVDIMM的1/3-1/5. 至于RDMA,这个东西能有效地将offload本来要处理NIC中断的CPU资源,实验测试如果使用infiniteband,可以将CPU完全用满,此时RDMA处理的速度是使用NIC的4倍。
这个编程模型将内存划分成为250regions,每个regions是2GB,这样算下来是500GB的内存。一个region由一系列机器进行托管,当然这些机器也可以托管其他的regions. 这一系列机器分为了primary + X backups. 所以最终集群可用物理内存,必须是500 * (1 + X). 然后在这个集群中有一个单点coordinator(CM), 它负责管理lease, 以及为object请求分配对应的 region(基于该region对应的机器). 这个实现里面还用到了zookeeper, 但是zookpeer仅仅是用来负责配置管理的,这个配置包括当前版本号,有哪些机器他们是怎么划分的,以及CM是谁。
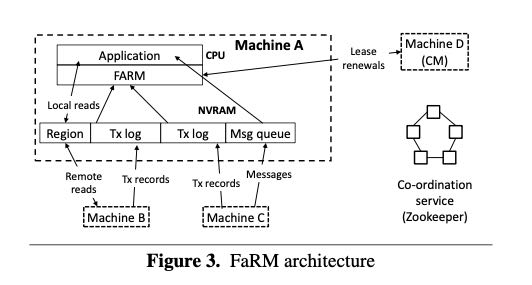
至于乐观并发控制体现在事务执行上。FaRM只保证原子读一个对象,不能保证原子性地读多个对象,至于这个一致性就需要用户自己去保证了。每个对象都都一个64bit version用于并发控制和复制。 一旦读取到了这个对象之后,在此次事务中这个对象内容就不在改变,直到最后提交事务。事务提交使用了一个比较奇怪的4阶段提交协议(4 phase commit protocol): lock, validation, commit backup, commit primary).文章有一节在证明这个提交协议的正确性,不过我没有仔细看。
为什么没有完全使用zookeeper呢?这个应该还是和性能有关系。CM只往上面存放配置信息,这些信息在大部分时间是不会变动的,出现变动也仅仅是在detect failure的时候。整个编程模型既然为了性能都全部用了DRAM以及RDMA,那么failure detection肯定也不能实现太慢。CM和所有交互的机器之间都在不断地交换lease, 文章说heavy load情况下面使用5ms lease不会出现任何false positive,这个让我很惊讶,因为如果这样的话clock drift要求肯定也比较严格。注意CM并不是特殊的机器,只是从某些机器中挑选了一台作为CM。一旦机器和CM发现lease超时的话,机器就会去和CM的k successors(in consisten hashing)去交互,确定是CM的问题还是自己的问题。如果是CM的话,那么就需要做reconfiguration & recovery,这个部分有点长我就直接忽略了。
总体下来,我不怀疑这个东西性能可以做很高,但是对它的稳定性有点担忧。另外我有个疑问是,这种编程模型适合什么样的场景。