升级到MongoDB 3.4出现的性能问题
TL;DR 因为checkpoint出现了瞬时的大量磁盘写入导致响应时间出现了尖峰。可以修改wiredtiger的checkpoint写入策略,加快checkpoint写入频率可以让整个磁盘写入比较平顺,从而削平延迟尖峰。
问题描述
前段时间我们把数据库从mongodb 3.0 升级到了 3.4,希望这个版本可以解决内存使用问题。使用3.0的时候我们遇到了很多问题,尤其是内存增长问题,经常出现OOM. 在精简索引之后这个问题依然存在,所以试着升级到3.4看看,而且3.4增加了许多指标可以观察数据库内部情况。
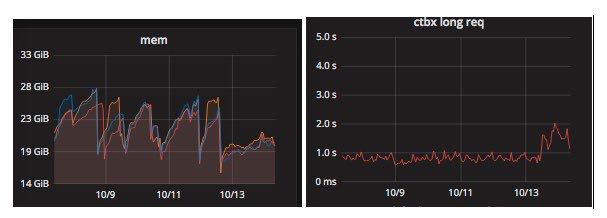
可以看到内存的确得到了控制,稳定在20G左右(在次之前的波动基本上都是因为内存增长太快所以手动重启避免OOM)。但是同样带来了另外一个问题就是延迟(90th percentile)增加了接近50%。
监控表现
因为这个延迟是在10minute统计出来的数值(我们使用stasd/graphite来收集延迟数据,rotate schema是10s:1h, 60s:1d, 10m:7d, 60m:60d),所以延迟的增加可能有两个原因:1. 每个请求的延迟都增加 2. 部分请求延迟出现尖峰。当然也可能是两个原因都存在。所以需要在更短的时间(30min)范围内延迟波动情况。我在写这篇文章的时候,之前并没有截图,然后现在数据也滚动过去了,所以没有办法提供当时的数据。不过结果是情况2,也就是部分请求延迟出现了尖峰。并且这个尖峰出现时机非常奇怪,大约是1min出现一个。
除此之外IO bytes以及CPU Idle也表现了同样的规律,并且primary和secondary都表现除了这样的情况,而不仅仅是primary. 因此当时猜测这种磁盘操作的尖峰,应该不是应用层的写入(不然secondary不会出现同样的pattern).
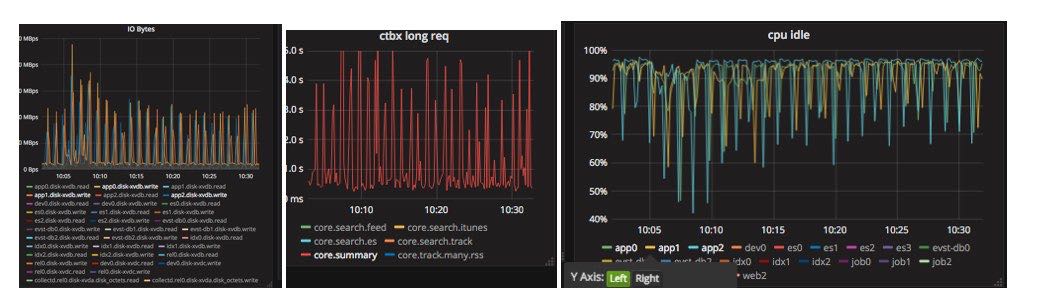
机器状况
接着我们希望上机器去观察进一步的情况,结合dsta和mongostat看看primary/secondary到底发生了什么事情
观察primary节点,每隔接近1min的时候,active writer会突然增长持续大约3s左右掉下去。然后观察dstat的这个时候情况,可以看到disk write大约写入了36M + 35M + 32M ~= 103M 数据,并且这个写入占据了很多sys cpu(也占用了部分usr cpu), 导致cpu idle掉了0. 这也可以解释为什么从监控面板上看cpu idle出现尖峰的情况。
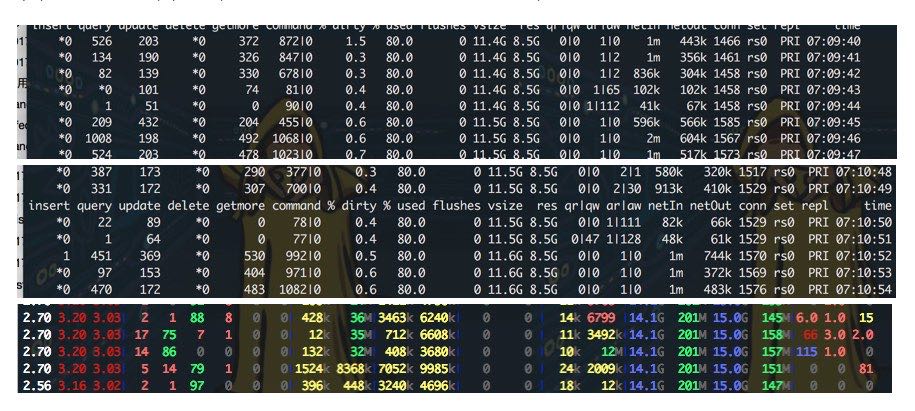
观察secondary节点也会有同样的情况,只不过这里不是active writer而是active reader会出现突然增长并且排队,然后3s之后恢复正常。
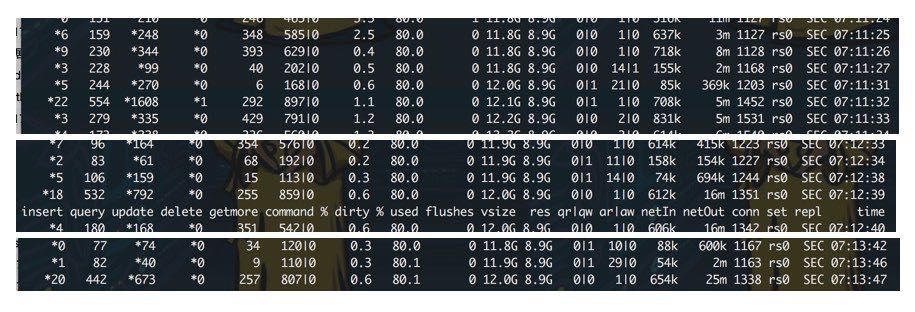
为了确认这些数据是mongodb写入的,我们还运行了一个 `iotop` 来观察记录当时的情况
09:35:46 2979 be/3 root 0.00 B/s 64.93 K/s 0.00 % 1.58 % [jbd2/xvdb-8] 09:35:46 2505 be/3 root 0.00 B/s 0.00 B/s 0.00 % 0.12 % [jbd2/xvda1-8] 09:35:46 6964 be/4 ec2-user 2.63 M/s 104.81 M/s 0.00 % 0.01 % mongod --storageEngine wiredTiger --port 27017 --dbpath /srv/mongodb --wiredTigerCacheSizeGB 30 --logpath /srv/mongodb/log --pidfilepath /home/ec2-user/nova/deploy/mongod-27017.pid --fork --journal --replSet rs0 --setParameter replWriterThreadCount=1 09:35:46 3889 be/4 nginx 0.00 B/s 15.28 K/s 0.00 % 0.00 % nginx: worker process 09:35:46 3890 be/4 nginx 0.00 B/s 19.10 K/s 0.00 % 0.00 % nginx: worker process
在尖峰时期从mongodb log里面可以看到出现了很多slow query log, 这些slow query大部分时间都花费在acquire global lock上面。所以我们的猜测是这样的:
- primary/secondary 每隔60s 左右会出现一些IO操作
- 这些IO操作会block住当前read/write requests
- 这些requests出现排队所以响应延迟会比较高
- 等到IO操作完成之后,这些排队的requests很快被消化掉
- 正常情况下面requests可以很快被处理。
确定问题
在想到解决办法之前,我们考虑过是否因为mongodb 3.0 -> 3.4发生了一些策略的变化,导致出现这些问题。通读了3.0, 3.2, 3.4 release notes之后,发现了几个可能的地方。试着修改过之后都发现没有效果:
- journal commit interval https://docs.mongodb.com/manual/reference/configuration-options/#storage.journal.commitIntervalMs
- sync delay https://docs.mongodb.com/manual/reference/configuration-options/#storage.syncPeriodSecs
- write concern policy https://docs.mongodb.com/manual/reference/write-concern/
我们想到获取可以google “mongodb 60 seconds” 碰碰运气看看还有那些参数默认值是1min的。除了sync delay这个参数之外,还有一个就是checkpoint的策略了。 https://docs.mongodb.com/manual/core/wiredtiger/#snapshots-and-checkpoints
MongoDB configures WiredTiger to create checkpoints (i.e. write the snapshot data to disk) at intervals of 60 seconds or 2 gigabytes of journal data.
为了验证的确是checkpoint造成的问题,我写了一个脚本定期观察wiredtiger的checkpoint写盘数据量
#!/usr/bin/env python
# coding:utf-8
# Copyright (C) dirlt
import time
import pymongo.database
from common.logging_util import logger
client = pymongo.MongoClient()
db = pymongo.database.Database(client, 'test')
def get_bm_data():
status = db.command('serverStatus')
wt = status['wiredTiger']
bm = wt['block-manager']
return bm
bm = get_bm_data()
ckpt_key = 'bytes written for checkpoint'
total_key = 'bytes written'
b2m = 1.0 / (1024 * 1024)
logger.debug('ckpt bytes = %.2fMB, total bytes = %.2fMB' % (bm[ckpt_key] * b2m, bm[total_key] * b2m))
while True:
time.sleep(1)
bm2 = get_bm_data()
ckpt_diff = bm2[ckpt_key] - bm[ckpt_key]
total_diff = bm2[total_key] - bm[total_key]
logger.debug('ckpt bytes diff = %.2fMB, total bytes diff = %.2fMB' % (ckpt_diff * b2m, total_diff * b2m))
运行脚本可以看到,的确每分钟都会写checkpoint, 并且数据量和之前观察到的磁盘写入量级基本一致

解决办法
确定了是checkpoint瞬时写入造成的问题之后,我们就需要修改checkpoint策略。一种是降低写入频率(增加wait值),另外一种是增加写入频率(降低wait值)。如果是增加wait值的话,可以预见的是会在某个时间点突然有一个更大量的磁盘写入,造成抖动,所以这似乎并不是一个很好的策略。相反如果加快写入频率的话,可以保证每次写入量不是很大,不会出现抖动。修改参数之后其实可以通过运行上面那段脚本来进行验证,并且观察监控面板确定那种策略更加适合自己的业务。
在mongodb启动参数里面可以修改wiredtiger的配置 –wiredTigerEngineConfigString "checkpoint=(wait=10,log_size=2GB)"
如果对比mongodb 3.0 和 3.4 的wiredtiger默认参数的话,其实差别非常小,checkpoint wait 值完全一样。所以猜测 wiredtiger 3.4 生成的checkpoint 体积相比3.0要大很多,才造成升级之后会感知到磁盘的瞬间写入。
mongodb 3.0 2017-08-20T13:51:13.516+0000 I STORAGE [initandlisten] wiredtiger_open config: create,cache_size=2G,session_max=20000,eviction=(threads_max=4),statistics=(fast),log=(enabled=true,archive=true,path=journal,compressor=snappy),file_manager=(close_idle_time=100000),checkpoint=(wait=60,log_size=2GB),statistics_log=(wait=0), mongodb 3.4 2017-10-20T09:26:55.931+0000 I STORAGE [initandlisten] wiredtiger_open config: create,cache_size=30720M,session_max=20000,eviction=(threads_min=4,threads_max=4),config_base=false,statistics=(fast),log=(enabled=true,archive=true,path=journal,compressor=snappy),file_manager=(close_idle_time=100000),checkpoint=(wait=60,log_size=2GB),statistics_log=(wait=0),