MonetDB/X100: Hyper-Pipelining Query Execution
设计思路:
- Column-Wise Execution. 按照column组织和处理数据
- Volcano-Style Pipelining. 批量 获取和处理columns(chunk)
- Incremental Materialization. 运算上减少物化操作
Therefore, we argue to combine the column-wise ex- ecution of MonetDB with the incremental materializa- tion offered by Volcano-style pipelining. We designed and implemented from scratch a new query engine for the MonetDB system, called X100, that employs a vectorized query processing model. Apart from achieving high CPU efficiency, Mon- etDB/X100 is intended to scale out towards non main- memory (disk-based) datasets.
In this paper, we investigate why relational database systems achieve low CPU efficiencies on modern CPUs. It turns out, that the Volcano-like tuple-at-a-time exe- cution architecture of relational systems introduces in- terpretation overhead, and inhibits compilers from us- ing their most performance-critical optimization tech- niques, such as loop pipelining.
We also analyzed the CPU efficiency of the main memory database system MonetDB, which does not suffer from problems generated by tuple-at-a-time in- terpretation, but instead employs a column-at-a-time materialization policy, which makes it memory band- width bound.
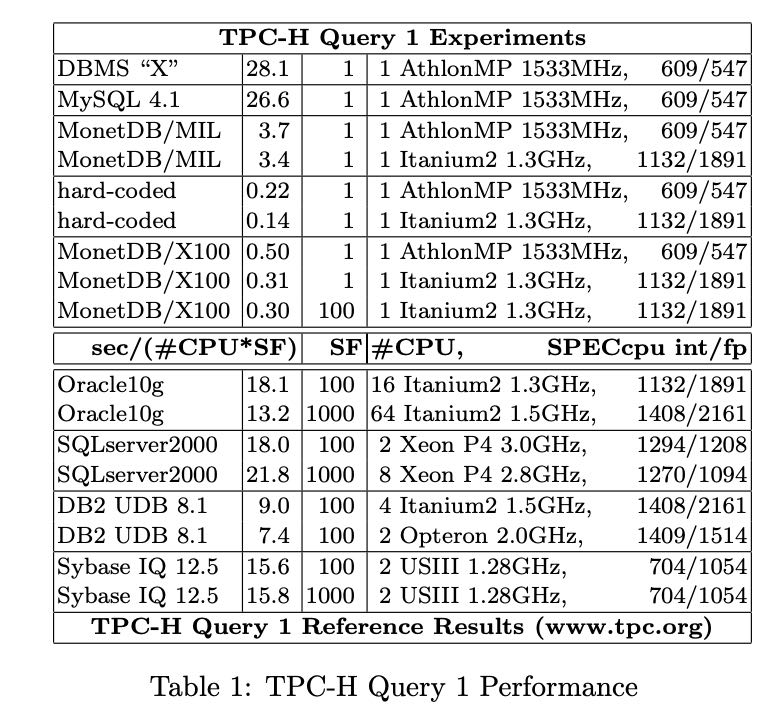
作者拿几个现有系统对TPCH-Q1进行了分析得到下面这样的结论:
- DBMS "X" /MySQL 开销比较大主要是主要还是tuple-at-a-time, 导致每个tuple都要调用函数,以及没有办法做loop-pipelining.
- MonetDB/MIL 避开了上面的开销,但是在物化上出现了内存读写瓶颈。
- MonetDB/X100 使用增量物化的方式避开了内存读写瓶颈,基本上达到了hard-coded的水平。
增量物化
关于前面两点我没有啥问题,这里说说最后一点减少物化操作。如果我们简单地将所有的运算都映射到vectorized primitives上的话,那么可能会产生许多memory load/stores. 以下面这个expression为例 A = (1-B) * (2 + C). 如果只是使用vectorized primitives(add,sub,mul)的话,那么操作会是
t0 = (1-B) t1 = (2+C) A = t0 * t1
可以看到t0/t1的load/store. 虽然我们有CPU cache的加持,但是对memory bandwidth开销还是很大的。Incremental Materialization则是通过定义compound vectorized primitives来解决,假设我们定义如下操作,首先f这个函数依然可以使用向量化技术,此外我们还减少了内存的读写压力。
def f(a, b, c, index, size):
for(i=0;i<size;i++):
j = index + i
c[j] = (1-a[i])*(2+b[i])
def F(a, b):
size = len(a)
tmp = new Column()
for(i=0;i<size;i+=batch_size):
f(a, b, tmp, i,batch_size)
return tmp
A = F(B, C)
关于CPU技术
摩尔定律是每18个月,晶体管尺寸会缩减1.4,这样单位面积内的晶体管数量会翻倍。人们会认为CPU MHz也会按照signal distance倒数(1.4)进行增加,但是实际上主频增加速度更快,提升的主频主要就是用来做流水线(pipelining). 之后的CPU为了继续提高性能,还引入了hyper-pipelining(超流水线), 不知道是不是CPU wide-issue?总之就是可以同时执行多条指令,前提是这些指令是相互独立的。
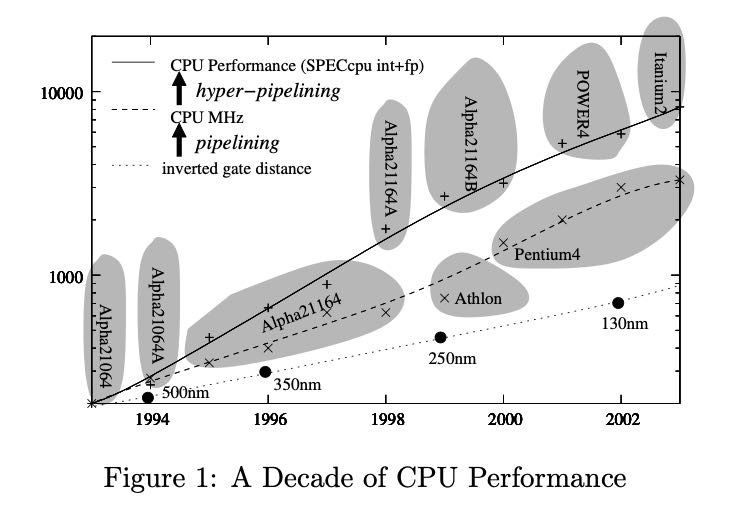
The root cause for CPU MHz improvements is progress in chip manufacturing process scales, that typically shrink by a factor 1.4 every 18 months (a.k.a. Moore’s law [13]). Every smaller manufacturing scale means twice (the square of 1.4) as many, and twice smaller transistors, as well as 1.4 times smaller wire distances and signal latencies. Thus one would expect CPU MHz to increase with inverted signal latencies, but Figure 1 shows that clock speed has increased even further. This is mainly done by pipelining: dividing the work of a CPU instruction in ever more stages. Less work per stage means that the CPU frequency can be increased. While the 1988 Intel 80386 CPU executed one instruction in one (or more) cycles, the 1993 Pentium already had a 5-stage pipeline, to be in- creased in the 1999 PentiumIII to 14 while the 2004 Pentium4 has 31 pipeline stages.
In addition, hyper-pipelined CPUs offer the possi- bility to take multiple instructions into execution in parallel if they are independent. That is, the CPU has not one, but multiple pipelines. Each cycle, a new in- struction can be pushed into each pipeline, provided again they are independent of all instructions already in execution. With hyper-pipelining, a CPU can get to an IPC (Instructions Per Cycle) of > 1. Figure 1 shows that this has allowed real-world CPU performance to increase faster than CPU frequency.
主频高并不意味性能就一定好。不断提升主频可以引入更深入的流水线,但是如果指令本身并行性就不高的话,那么大部分CPU大量的时间也都是处于stall状态,这点可以从Itanium 2和Pentium4对比看到。Itanium 2虽然主频不高,流水线不深,但是它是VLIM(Very Large Instruction Word)架构,在编译阶段就可以静态地发现指令之间的并行性(以及安排好指令执行),于是在设计上使用了更高的Wide-issue, 但是在资源使用率上比Pentium 4却要好。
Modern CPUs are balanced in different ways. The Intel Itanium2 processor is a VLIW (Very Large In- struction Word) processor with many parallel pipelines (it can execute up to 6 instructions per cycle) with only few (7) stages, and therefore a relatively low clock speed of 1.5GHz. In contrast, the Pentium4 has its very long 31-stage pipeline allowing for a 3.6GHz clock speed, but can only execute 3 instructions per cycle. Either way, to get to its theoretical maximum through- put, an Itanium2 needs 7x6 = 42 independent instruc- tions at any time, while the Pentium4 needs 31x3 = 93. Such parallelism cannot always be found, and there- fore many programs use the resources of the Itanium2 much better than the Pentium4, which explains why in benchmarks the performance of both CPUs is similar, despite the big clock speed difference.
文章中还给出了一个例子来说明这个差异,就是对比一段程序branch version和predicated version, 分别在Itanium 2以及Athlon MP上的运行时间。可以看到Itanium 2几乎不受到branch pattern的影响,主要就是在编译期间指令安排上发现并行性,所以比predicated version要好(有多余的计算)。而对于Athlon MP来说,这个并行性是在执行期间使用OOO来发现的,所以性能取决于branch pattern。
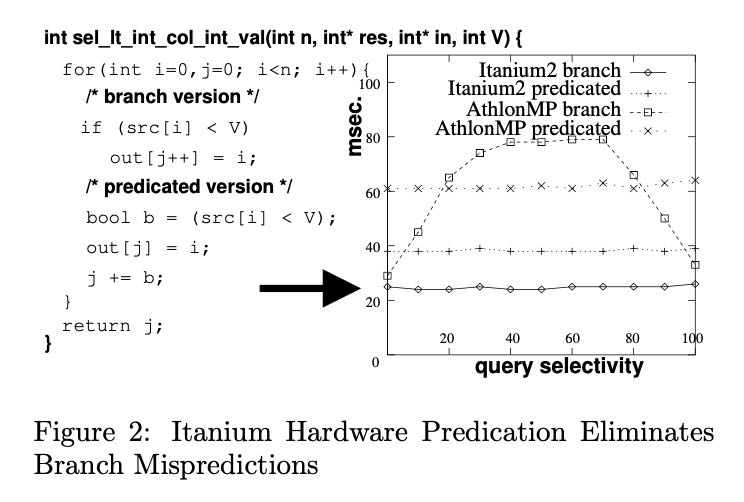
In the case of the Itanium2 processor, the impor- tance of the compiler is even stronger, as it is the compiler who has to find instructions that can go into different pipelines (other CPUs do that at run-time, using out-of-order execution). As the Itanium2 chip does not need any complex logic dedicated to find- ing out-of-order execution opportunities, it can contain more pipelines that do real work. The Itanium2 also has a feature called branch predication for eliminating branch mispredictions, by allowing to execute both the THEN and ELSE blocks in parallel and discard one of the results as soon as the result of the condition becomes known. It is also the task of the compiler to detect opportunities for branch predication.