Mining Massive Datasets on Coursera
Table of Contents
https://class.coursera.org/mmds-002
感觉课程安排有点问题:每周课程似乎没有什么特别强的重点,一周可能会讲好几个topics然而之间关系不大,几个讲师之间的风格差别也很大。
1. Page Rank
PR的数学(矩阵)形式是Mx = x. 其中M表示链接权值系数矩阵,x则是我们希望求解页面权重矩阵。如果Ax = kx. 那么称x为A的eigenvector(特征向量), 而k则为eigenvalue(特征值). 如果A比较小的话那么可以使用高斯消元法求解,如果比较大的话则比较适合使用迭代方式(Power Iteration)求解:首先分配每个页面相同权重,然后不断迭代直到页面权重改变非常小。
PR也可以看做是random walk(p(t+1) = M*p(t), 一阶马尔科夫), 求解出的x就是stationary distribution. 可以证明,如果graph满足一定条件的话,那么stationary distribution是唯一的并且和t=0时候的分布无关。
那么graph需要满足什么条件呢?有两个问题会导致r不收敛:
- dead end pages. (have no out-links). 最终这些页面的权重会"leak out". dead ends问题可以通过teleport方式解决:我们认为这个页面有可能会跳转到所有可能页面。
- spider traps. (all out-links are within the group). 最终这个群组会吸收所有的权重。spier traps问题也可以通过teleport方式解决:我们分配概率p(0.8~0.9)会跳转到out-links,同时分配1-p会跳转到non-out-links.
更准确地说矩阵M应该是stochastic, irreducible, aperiodic
- stochastic: every column sums to 1. 在dead ends问题中teleport就是添加一些随机跳转链接满足这个条件。
- aperiodic: 某个状态x到状态s, 如果两次之间跳转次数之差,始终是某个k>1的倍数的话,那么就认为这个graph是periodic的。可以通过在自身状态上增加跳转链接来使得graph是aperiodic的。
- irreducible: 不要stuck在某一个状态上。spider traps问题就是可以通过归约SCC(strongly connected component)使得random walker一直在某个状态上。
如果我们不能把matrix或rank载入内存的话,那么可以使用block-based/block-strip方式来做迭代:每次只载入部分rank, 以及matrix中只和部分rank相关的子矩阵,然后在内存中做计算。
普通PR只是计算某个页面在所有页面中的权重;Topic-Specfic(Personalized)PR可以用于计算页面在某个Topic下的权重(只需在普通PR下做个简单修改,将teleport-set修改为那些和topic相关的pages); Link-Spam PR可以认为是Topic-Specific PR的一个特例,teleport-set修改为trusted pages。做Link Spam还有一个方法是,先使用Link-Spam PR计算出某个页面的权重p, 然后使用普通PR计算出权重p', 我们可以估计spam为这个页面贡献权重为p'-p, 比例(p'-p) / p称为Spam Mass. 我们可以找出那些spam-mass比较高的页面,将它从graph中去掉。
2. Finding Similiar Sets
查找相似集合这个问题,解决办法涉及到三个步骤:1. shingles 2. minhashing 3.locality-sensitive hashing(LSH). 这里我们以查找相似文档为例。
第一部分:抽取文档特征,每一个文档变为一个稀疏向量
shingles是将文档进行字符切分:k-shingle(k-gram)指将文档内连续k个字符抽取出来组成一个集合。比如k=2, doc=abcab, 那么2-shingles={ab, bc, ca}. 实际应用中k通常选择[5,10]. shingles的特点是,如果doc中某个word发生变化或者是出现段落重新排序的话,那么k-shingles差别是非常小的。为了节省存储和比较时间,我们可以对k-shingles得到的集合中元素进行hash(称为tokens). 这样最终结果我们得到的是set of tokens.
我们可以使用Jaccard Similiarity来衡量两个set相似度指标:Sim(C1, C2) = Intersection(C1, C2) / Union(C1, C2). 如果我们用矩阵形式表示的话,row可以表示所有tokens, 而column则表示所有docs, M(i,j)则表示doc#j是否含有ith的token. M是一个布尔矩阵并且非常稀疏。如果要求解Sim(C1, C2)只需要抽取对应columns即可。
第二部分:将稀疏向量变为稠密向量,每一个文档对应一个稠密向量
然后我们引入minhashing. minhashing主要作用是特别稀疏vector通过hash函数转换成为稠密vector. 假设rows是随机排列的话,minhash function h(C)是这个column上有多少个1出现在row的第一个排列中(the number of the first(in the permuted order) row in which column C has 1). 我们可以使用h(C1)和h(C2)相似度来作为Sim(C1,C2). 可是rows的所有排列组合可能是(# of rows)!, 所以实际中通常我们选择k(k~=100)左右个随机排列组合,这样得到的minhash function h(C)实际上是100*1向量。下图给了一个求解minhash的例子. 我们看signature matrix第二行第三列为什么是4,这是因为第二个permutation中只有4th对应的row在第三列才出现第一个1.
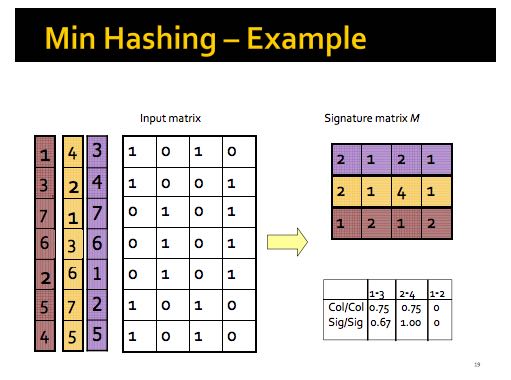
剩下的问题就是我们如何使用hash-function来模拟随机排列组合,下面是具体实现办法。其实我们更加关心的是两个r在同一个hash-function上的顺序。

第三部分:为这个文档(稠密向量)建立索引。局部敏感意思是,我们会关心两个稠密向量中的局部相似性。
最后我们相当于需要为这些vector建立"索引". 这个方法称为"LSH(局部敏感哈希)". 顾名思义就是将vector拆分称为多个小部分,针对每个部分进行hash. 如果一个C在某个小部分hash相同的话,那么这个C就可以作为候选(candidates). 最终我们会对这个C全量vector计算相似度。具体地来说,这些小部分称为band(b = # of band), 每个band里面有r个rows. 还有参数k来控制hash的bucket. 假设我们希望能够找出相似度为s的文档的话:
- 那么C1,C2在一个band上完全相同的概率是 s^b.
- 而C1,C2在所有band上都不相同的概率则是 (1-s^b) ^ r.
- C1,C2在任意一个band上相同概率是 1 - (1-s^b) ^ r.
我们希望的函数形状是:y=1.0 if sim >= s, 0.0 if sim < s. 这是一个阶梯函数。而实际上1-(1-s^b)^r这个函数是一个S形状函数。通过控制b, r参数可以控制函数形状来调整false-pos和false-neg概率。
3. Frequent Itemsets
我们先从购物篮问题开始:找到几种商品,它们经常会一起出现在购物篮中(比如diaper & beer问题)。这里我们再引入support(itemset) = k, 表示出现过k个这样的购物篮包含itemset. 然后再定义support threshold = s, 如果support(itemset)>=s的话那么itemset称为frequent itemsets.
这个问题的泛化问题,其实是finding associative rules(查找关联规则):如果我们的购物篮里面包含了x1,x2…, 那么非常有可能包含y. 这个可能性是通过上面提到的support threshold来定义的。不过support threshold只是定义了包含数量而不是比例。所以跟更准确的说我们应该需要的是一个probability/confidence = support(itemset) / # of baskets.
查找关联规则最常用的算法是A-Priori, 大致思想上是首先找到frequent 1-item set. 然后后在这个set上查找出frequent 2-item set(如果元素不在frequent 1-item set的话,那么肯定也不会出现在frequent 2-item set). 如果要查找到frequent k-item set的话那么需要经过k passes. 至于这个算法具体细节以及优化版本,从视频和ppt中我实在是没有看懂。不过这些算法以及优化途径,就是通过搭配使用hash和bitmap来减少memory footprint和减少下一轮所需要筛选元素个数。
#note: 看了这门课程对应教材之后大致理解了。PCY算法是在第一轮的时候就对pair进行hash然后记录在hash-table中。第一遍完成之后将这个hash-table转换成为bitmap结构。然后在第二遍的时候统计pair之前,对pair进行hash查询bitmap判断是否为frequent, 这样又可以过滤一片。
4. Community Detection in Graph
这个问题就是尝试从social graph中查找出来多个community, 这些community内部的membership比较密集。community之间可以overlap或者是相互包含。下面解决这个问题的方法是假设community是事先存在(or 虚构)的,然后我们通过G(V,E)来分解出member和community的关系(矩阵分解…)
AGM(Affiliation Graph Model)用来表示member和community之间关系的,整个结构类似二部图:如果member和community之间有关系,那么w(m, c)就是1否则为0. 每个community自身还有一个概率p(c)(我猜想这个概率是这个community自身存在的强弱表示)。那么两个members(u,v)之间关系强度P(u,v) = 1 - ∏ ({u,v分别属于cu和cv之间的交集c'} (1 - p(c')). 如果两者交集C'越大,那么P(u,v)越大。
AGM模型可以稍作简化成为BIGCLAM. 我们不要为每个community定义p, 而是定义w(m,c)为某个概率.(AGM中这个值只有0,1). 我们定义这个矩阵叫做community membership strength matrix记为F. 两个mebers(u,v)之间关系强弱从某一个communityA上看,P(A, u, v) = 1 - exp(-F(u,A) * F(v, A)). 如果考虑所有的communities的话,那么就得到一个非常简单的形式P = 1 - exp(-F * F').
那么问题就是如果我们给定G(V,E), 我们如何估计上面的F. 这里我们要做极大似然的是这个式子 ∏ {如果u,v属于E} P(u,v) * ∏ {如果u,v不属于E} (1-P(u,v)). 我们可以针对这个式子做log. 那么就是∑ {如果uv属于E} P(u,v) + ∑ {如果uv不属于E} (1-P(u,v)). 使用梯度下降来求解这个问题。因为这个G是稀疏矩阵,所以可以做一些形式上的变换来优化。(非常类似推荐系统中的矩阵分解).
5. Cluster Detection in Graph
这个问题和上面一样,只不过使用另外一种方法来求解。
首先我们要定义什么是我们希望的cluster? 我们先引入cut/割这个概念:我们将所有属于图G内的点看做是单一点,这个单一点和其他点有n条边相连,那么cut(G)=n. 如果图G被分割称为两个子图G1,G2的话,那么很明显cut(G1)=cut(G2). 有了cut这个概念之后,我们希望寻找的cluster就是让cut越小越好,因为cut越小的话那么说明两个子图之间联系是最少的,这样的cut称为最优割(optimal cut). 不过这样的定义并不完整,因为如果G被只分出1个节点的话,虽然cut是1,但是两个子图却并不均匀。cut只是考虑子图之间的联系,但是却没有考虑子图内部的联系。我们一方面要让cut尽可能小,另一方面要让两个子图尽可能均匀。综合起来我们使用conductance(传导率)来衡量:cdc(G) = cut(G) / min(vol(G), 2m-vol(G)). 其中vol(G)表示这个图内部每个点的degree之和,m表示整个graph里面有多少条边。min函数是为了能确保两个子图的传导率一样。
有了衡量指标之后,我们看如何寻找cluster. 即使我们只需要将G分为两个子图G1,G2, 直接寻找最优传导率也是NP-Hard问题。所以我们换一个角度来思考,假设每个点都有某个属性的话定义为x,每个点属性值是和它相连接的点的属性值之和. 如果A是图的adjacency matrix,那么Ax = k*x. 因此我们要求解实际是A的特征向量,以及特征值(=k). (eigen-decomposition, 特征分解) 这种模型是基于spectral graph theory(图谱理论? / 特征分解也称为谱分解),一个graph的spectrum是这个G的所有特征向量,这些特征向量按照特征值由小到大排序(k1 < k2 < … kn) #note: 不太明白这个spectrum含义. 隐约地觉得和SVD之间存在某种关系。
接着我们引入lapacian matrix(L)来作为G的矩阵表示:L = D-A. 其中D表示G的degree matrix表示,A表示G的adjacency matrix表示。L有下面这些性质:1. n*n的对称矩阵(对称矩阵才能做特征分解) 2. 如果每个点属性相同的话,那么特征值k=0. 3. 特征值是non-negative real numbers 4. 特征向量是都是实数并且正交(orthogonal, x1 .* x2 = 0). 如果只是想求解分割称为2个部分的话,那么可以取k2以及x2来做划分。但是如果想扩展到k个部分的话,虽然我们可以递归地划分但是不稳定效率也不高,有效的办法是求解x2,x3,x4..多个这样的特征向量,这样每个点从一个属性值变为一个属性向量,然后使用clustering比如k-means方法来做聚合。#note: 从这个角度上看的话,我们可以认为特征向量spectrum代表了每个点在空间聚合上的某种属性。
6. Dimensionality Reduction
如果矩阵A可以通过n个线性无关的向量通过线性组合表示的话,那么秩rank(A) = n. 如果将数据集合表示称为矩阵的话,那么rank就是数据集合的维度(dimensionality). 维度降解则可以认为是,我们通过忍受数据上的一些误差(微小地变动矩阵上的一些值), 来将rank降低。做维度降解除了加快学习速度,更加适合可视化,以及方便数据压缩之外,还有一个好处就是可以去除数据中部分噪音。
如果把文档/短语表示做成矩阵A(m*n)的话,通过SVD(singular value decomposition)我们可以发现一些有意思的事情:A(m*n) = U(m*r) * R(r*r) * V(r*n). 其中r是一个隐式属性比如topics. U(left sigular vectors)表示文章和topics之间的关系,V(right sigular vectors)表示topics和短语之间的关系,R(sigular values)是一个对角矩阵表示这些topics之间相对强弱关系,并且r就是rank(A). 下面这图给出了一些新的东西,整个矩阵实际上是被分为两个部分,取决于我们在R上选择多少个column. 然后这里还给出了SVD的一些特性,得到分解矩阵非常漂亮。
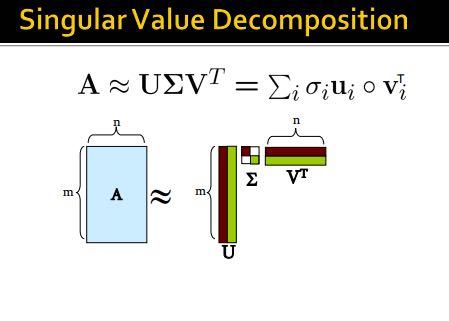

注意到上面R矩阵中越在右下角的值越小,又因为R表示某个隐式变量的强度,所以维度降解就是要忽略右下角的值(设置为0):忽略的值越多,那么维度下降的越多。同时我们可以证明用这种方法近似是最优的近似(optimal low-rank approximation)。完成忽略操作之后我们就得到了R'矩阵,然后可以使用这个R'矩阵计算A'=(U*R'*V),然后使用Frobenius norm来计算A和A'之间的差异(对每个元素差值做平方然后求和)。
SVD的几何意义就是要将原来数据通过线性模型方式映射到topics所描述的平面上去并且满足距离上的最小二乘,从这点上看和线性回归有点类似,只不过差别是线性回归问题中我们直接使用input属性来描述超平面而SVD中我们要自己找出这个照平面。这个R实际上是这些数据在这些超平面的各个维度上分布的方差:方差越小所蕴含信息也就越少,我们就可以越可以忽略它来完成维度降解。我们可以使用R和R'差异来衡量因为维度降解造成信息损失的程度,使用sum(R'^2) / sum(R^2) 来衡量信息保持的程度,通常要保证在80-90%左右。下图给出了SVD和eigen-decomposition之间的联系

SVD计算复杂度在O(n^2 * m) / O(m^2 * n). 如果输入矩阵是稀疏的话,SVD分解之后得到的三个矩阵却可能是非常稠密的。同时SVD得到的topics维度是非常难以解释的。CUR算法可以解决这些问题,大致思想是分解称为CUR三个矩阵,C是从A矩阵中选择k'个代表列构成的(n*k'),R则是从A矩阵中选择k'个代表行构成的(k'*m),时间复杂度控制在O(n*m)上。它是一个概率型算法通过控制k'来控制和最优解之间的误差。

7. Latent-Factor Models
通常我们使用RMSE(root-mean-square-error, = 1.0/N * sqrt((r'-r)^2). 其中N表示测试集合大小,r'表示预测评分,r表示实际评分)来衡量推荐系统好坏。实际的推荐系统还需要考虑 1. 多样性(diversity) 2. 用户环境(context) 3. 物品推荐顺序等。RMSE只能说这个模型可以很好地拟合当前rating情况,但是并不意味着是我们真正想要的。
推荐系统通常在下面几个层面上建模:1. global 2. factorization 3. collaborative filtering(CF). 其中global从全局上考虑这个用户和平均用户的偏差,CF则使用NN(nearest neighbor)方法来预测评分:假设我们想知道u对i的评价,我们可以先找到k个和item i比较接近(kNN, 使用相似度做度量, sij)并且是u已经评价过的items, 然后使用这些ratings使用相似度做加权。如果综合考虑的话就可以给出一个工作得还不错的模型。

Latent-Factor Model也就是factorization则是尝试做矩阵分解:将user和movie信息映射到一个超平面上,然后通过计算内积来计算user和movie之间的相似度也就是rating. 如果我们再把latent-factor model加入的话,那么整个模型应该就是这样的。使用这个模型相比没有增加latent-factor model效果要好很多。


8. Clustering
clustering方法分为两类:1. Hierarchical(层次关系,细分为agglomerative/bottom-up和divisive/top-down两种) 2. Point assignment(k-means). 在做clustering的时候需要使用一个点来表示代表一个cluster,有两种办法: 1. centroid(取平均值) 2. clustroid(选择其中一个代表点,这个点离其他点的距离最近).
在做hierarchical clustering时候有两种办法来停停止继续聚合:1. 达到所希望的cluster数量 2. cluster之间达不到某个cohesion. 所谓cohension就是来衡量cluster的好坏:如果两个clusters合并称为一个cluster之后,这个cluster本身聚合能力就不强的话,那么表明这个cluster本身就不好。衡量cohesion也有几种方法:1. diameter(这个集群最远两个点距离)2. radius(和centroid/clustroid最大距离)3. density(cluster内data points数量除以这个cluster的容量). Hierarchical clustering不太适合大规模的数据集合。
k-means一个变种是BFR算法,这种算法假设数据点在各个维度上都服从正态分布,然后扫描一遍数据集合就可以求得最终结果,所以比较适合大规模数据集合。CURE(clustering using representatives)是一个two-passes算法,和k-means以及BFR不同的是使用一系列代表点(representatives)来代表一个cluster.
9. Bipartite Graph Matching
Bipartite Graph Matching(二部图匹配)问题是说:有两个子图G1,G2之间有若干edges相连,我们如何选择选择部分edges(matching), 同时确保两个图中任意一个点只能在一个edge上。如果一个matching选择了k条边的话,那么称C(M) = cardinality of matching = k. 如果k等于min(# of G1, # of G2)的话那么则称为完美匹配(perfect matching). 当然有些图可能不存在完美匹配,那么我们就需要寻找最大匹配(maximum matching). 对于离线二部图最大匹配问题已经有多项式的算法,但是没有在线的方法。不过可以证明,对于在线问题如果我们使用greedy算法的话,competitive ratio = C(greedy algoirhtm matching) / C(optimal algorithm matching) >= 0.5. 这个competitive ration是对于所有可能的input cases而言的。