MillWheel: Fault-Tolerant Stream Processing at Internet Scale
Table of Contents
http://research.google.com/pubs/pub41378.html @ 2013
1. ABSTRACT
2. INTRODUCTION
MillWheel is such a programming model, tailored specifically to streaming, low-latency systems. Users write application logic as individual nodes in a directed compute graph, for which they can define an arbitrary, dynamic topology. Records are delivered con-tinuously along edges in the graph. MillWheel provides fault tol-erance at the framework level, where any node or any edge in the topology can fail at any time without affecting the correctness of the result. As part of this fault tolerance, every record in the system is guaranteed to be delivered to its consumers. Furthermore, the API that MillWheel provides for record processing handles each record in an idempotent fashion, making record delivery occur ex-actly once from the user’s perspective. MillWheel checkpoints its progress at fine granularity, eliminating any need to buffer pending data at external senders for long periods between checkpoints. # user-code满足idempotent, exactly-once-delivery语义,细粒度checkpoint机制
3. MOTIVATION AND REQUIREMENTS
文中以Google Zeitgeist产品举例,用于实时地发现一些搜索关键词热度变化。热度变化不能仅仅通过观察关键词搜索量的变化来判断,还要考虑关键词本身属性造成的随时间变化产生的波动(比如晚上搜索今晚电视节目预告就会比较多),所以热度变化需要考虑到关键词属性(模型)。
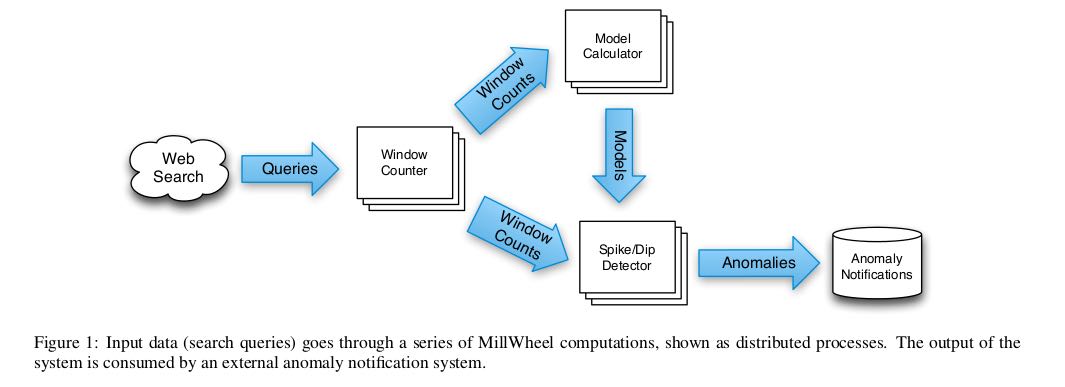
In order to implement the Zeitgeist system, our approach is to bucket records into one-second intervals and to compare the ac-tual traffic for each time bucket to the expected traffic that the model predicts. If these quantities are consistently different over a non-trivial number of buckets, then we have high confidence that a query is spiking or dipping. In parallel, we update the model with the newly received data and store it for future use. # 将记录按照1s进行分组,然后对比实际流量和预期流量。如果持续地在多个分组上差异很大,那么我们就可以相信这个检索量在增高或是降低,同时我们用这些记录来更新模型。
- Persistent Storage: It is important to note that this implementation requires both short- and long-term storage. A spike may only last a few seconds, and thus depend on state from a small window of time, whereas model data can correspond to months of continuous updates. # 持久存储,满足短期和长期需求
- Low Watermarks: Some Zeitgeist users are interested in detecting dips in traffic, where the volume for a query is uncharacteristically low (e.g. if the Egyptian government turns off the Internet). In a distributed system with inputs from all over the world, data ar-rival time does not strictly correspond to its generation time (the search time, in this case), so it is important to be able to distinguish whether a flurry of expected Arabic queries at t = 1296167641 is simply delayed on the wire, or actually not there. MillWheel ad-dresses this by providing a low watermark for incoming data for each processing stage (e.g. Window Counter, Model Calculator), which indicates that all data up to a given timestamp has been re-ceived. The low watermark tracks all pending events in the dis-tributed system. Using the low watermark, we are able to distin-guish between the two example cases – if the low watermark ad-vances past time t without the queries arriving, then we have high confidence that the queries were not recorded, and are not sim-ply delayed. This semantic also obviates any requirement of strict monotonicity for inputs – out-of-order streams are the norm. # 因为记录到达时间并不等于记录生成时间(搜索词到达MW时间并不等于检索时间),中间会存在部分延迟。但是我们很难区分说,某个搜索是延迟了还是根本没有产生。所以这里引入低水位概念,一旦LW超过t的话,我们就认为不会再有query timestamp > t的记录到来。
- Duplicate Prevention: For Zeitgeist, duplicate record deliveries could cause spurious spikes. Further, exactly-once processing is a requirement for MillWheel’s many revenue-processing customers, all of whom can depend on the correctness of the framework imple-mentation rather than reinventing their own deduplication mecha-nism. Users do not have to write code to manually roll back state updates or deal with a variety of failure scenarios to maintain cor-rectness. # 去重处理对于处理收入的应用是必须的,内置去重机制免去用户重新实现。
With the above in mind, we offer our requirements for a stream processing framework at Google, which are reflected in MillWheel:
- Data should be available to consumers as soon as it is published (i.e. there are no system-intrinsic barriers to ingesting inputs and providing output data). # 数据自然流入流出
- Persistent state abstractions should be available to user code, and should be integrated into the system’s overall consistency model. # 提供持久化状态功能
- Out-of-order data should be handled gracefully by the system. # 系统可以优雅处理OOO数据
- A monotonically increasing low watermark of data timestamps should be computed by the system. # LW是单调递增并且由系统计算提供
- Latency should stay constant as the system scales to more ma-chines. # 关注延迟
- The system should provide exactly-once delivery of records. # exactly-once-delivery语义
4. SYSTEM OVERVIEW
At a high level, MillWheel is a graph of user-defined transfor-mations on input data that produces output data. We call these transformations computations, and define them more extensively below. Each of these transformations can be parallelized across an arbitrary number of machines, such that the user does not have to concern themselves with load-balancing at a fine-grained level. In the case of Zeitgeist, shown in Figure 1, our input would be a con-tinuously arriving set of search queries, and our output would be the set of queries that are spiking or dipping. # 节点上的计算称为computation. 计算可以分布在许多机器上并行,用户不需要关心负载均衡情况。(自动做负载均衡)
Abstractly, inputs and outputs in MillWheel are represented by (key, value, timestamp) triples. While the key is a metadata field with semantic meaning in the system, the value can be an arbi-trary byte string, corresponding to the entire record. The context in which user code runs is scoped to a specific key, and each com-putation can define the keying for each input source, depending on its logical needs. The timestamps in these triples can be assigned an arbitrary value by the MillWheel user (but they are typically close to wall clock time when the event occurred), and MillWheel will calculate low watermarks according to these val-ues. # 记录是三元组<k,v,ts>. k存储记录metadata,可以用来路由以及负载均衡等。ts通常设置成wall time, MW使用ts来计算LW
Collectively, a pipeline of user computations will form a data flow graph, as outputs from one computation become inputs for an-other, and so on. Users can add and remove computations from a topology dynamically, without needing to restart the entire sys-tem. In manipulating data and outputting records, a computation can combine, modify, create, and drop records arbitrarily. # 允许动态变化拓扑结构
MillWheel makes record processing idempotent with regard to the framework API. As long as applications use the state and com-munication abstractions provided by the system, failures and retries are hidden from user code. This keeps user code simple and under-standable, and allows users to focus on their application logic. In the context of a computation, user code can access a per-key, per-computation persistent store, which allows for powerful per-key aggregations to take place, as illustrated by the Zeitgeist example. The fundamental guarantee that underlies this simplicity follows: # MW让记录处理满足idempotent, 应用使用系统提供的状态和通信抽象,然后MW可以帮助应用屏蔽失败和重试具体细节。用户可以访问per-key, per-computation的持久化存储。再次之上MW就可以提供如下保证。
Delivery Guarantee: All internal updates within the MillWheel framework resulting from record processing are atomically check-pointed per-key and records are delivered exactly once. This guar-antee does not extend to external systems. # MW每次处理记录产生的更新都会被checkpointed, 所以记录只会被投递一次(通过checkpoint判断记录是否被处理过)
5. CORE CONCEPTS
5.1. Computations
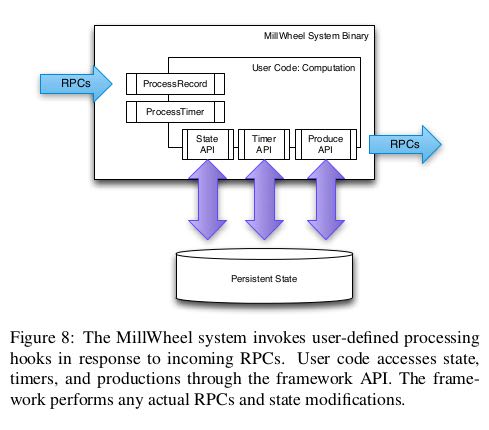
Application logic lives in computations, which encapsulate arbi-trary user code. Computation code is invoked upon receipt of input data, at which point user-defined actions are triggered, including contacting external systems, manipulating other MillWheel prim-itives, or outputting data. If external systems are contacted, it is up to the user to ensure that the effects of their code on these sys-tems is idempotent. Computation code is written to operate in the context of a single key, and is agnostic to the distribution of keys among different machines. As illustrated in Figure 4, processing is serialized per-key, but can be parallelized over distinct keys # 如果用户代码连接到外部系统需要自己保证idempotent.
5.2. Keys
Keys are the primary abstraction for aggregation and comparison between different records in MillWheel. For every record in the system, the consumer specifies a key extraction function, which as- signs a key to the record. Computation code is run in the context of a specific key and is only granted access to state for that specific key. For example, in the Zeitgeist system, a good choice of key for query records would be the text of the query itself, since we need to aggregate counts and compute models on a per-query basis. Al-ternately, a spam detector might choose a cookie fingerprint as a key, in order to block abusive behavior. Figure 5 shows different consumers extracting different keys from the same input stream. # consumer来指定key-extractor, 来一条记录将key-extractor作用在这条记录上抽取key, 然后处理。
5.3. Streams
Streams are the delivery mechanism between different compu-tations in MillWheel. A computation subscribes to zero or more input streams and publishes one or more output streams, and the system guarantees delivery along these channels. Key-extraction functions are specified by each consumer on a per-stream basis, such that multiple consumers can subscribe to the same stream and aggregate its data in different ways. Streams are uniquely identified by their names, with no other qualifications – any computation can subscribe to any stream, and can produce records (productions) to any stream. # data-flow.
5.4. Persistent State
In its most basic form, persistent state in MillWheel is an opaque byte string that is managed on a per-key basis. The user provides serialization and deserialization routines (such as translating a rich data structure in and out of its wire format), for which a variety of convenient mechanisms (e.g. Protocol Buffers) exist. Per-sistent state is backed by a replicated, highly available data store (e.g. Bigtable or Spanner), which ensures data integrity in a way that is completely transparent to the end user. Common uses of state include counters aggregated over windows of records and buffered data for a join. # 持久化状态是一串二进制对应某个key. kv存储在高可用的数据系统中。通常状态包括一个时间窗口内记录聚合总数,或者等待做join的缓存数据。
5.5. Low Watermarks
The low watermark for a computation provides a bound on the timestamps of future records arriving at that computation. # LW用来给出未来会参与计算的记录的时间戳界限。
Definition: We provide a recursive definition of low watermarks based on a pipeline’s data flow. Given a computation, A, let the oldest work of A be a timestamp corresponding to the oldest un- finished (in-flight, stored, or pending-delivery) record in A. Given this, we define the low watermark of A to be
min(oldest work of A, low watermark of C : C outputs to A)
If there are no input streams, the low watermark and oldest work values are equivalent. # 简单地说就是此节点和上游节点未处理记录的最小时间戳(对于外部系统我们需要加上一个偏移量)
Low watermark values are seeded by injectors, which send data into MillWheel from external systems. Measurement of pending work in external systems is often an estimate, so in practice, com-putations should expect a small rate of late records – records behind the low watermark – from such systems. Zeitgeist deals with this by dropping such data, while keeping track of how much data was dropped (empirically around 0.001% of records). Other pipelines retroactively correct their aggregates if late records arrive. Though this is not reflected in the above definition, the system guarantees that a computation’s low watermark is monotonic even in the face of late data. # LW值是从injectors也就是输入源来的。因为外部系统的pending work只能给出个大概,所以实际计算中我们还是会碰到一些late record(时间戳在LW之前). 对于Zeitgeist会直接丢弃它记录下这个比率,而另外一些系统也尝试回退使用它修正数据。但是入沦如何,LW一定是单调递增的。
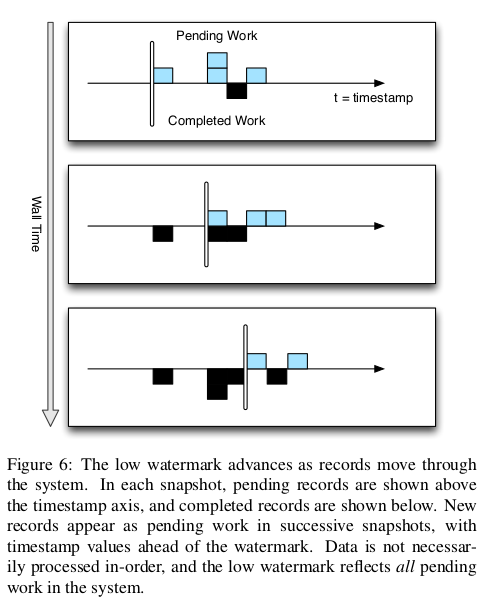
By waiting for the low watermark of a computation to advance past a certain value, the user can determine that they have a com- plete picture of their data up to that time, as previously illustrated by Zeitgeist’s dip detection. When assigning timestamps to new or aggregate records, it is up to the user to pick a timestamp no smaller than any of the source records. The low watermark reported by the MillWheel framework measures known work in the system, shownin Figure 6. # 一旦知道LW, 那么就可以认为timestamp < LW的记录全部到达。下图说明LW是如何变化的.
5.6. Timers
Timers are per-key programmatic hooks that trigger at a specific wall time or low watermark value. Timers are created and run in the context of a computation, and accordingly can run arbitrary code. The decision to use a wall time or low watermark value is dependent on the application – a heuristic monitoring system that wants to push hourly emails (on the hour, regardless of whether data was delayed) might use wall time timers, while an analytics system performing windowed aggregates could use low watermark timers. Once set, timers are guaranteed to fire in increasing times-tamp order. They are journaled in persistent state and can survive process restarts and machine failures. When a timer fires, it runs the specified user function and has the same exactly-once guaran-tee as input records. A simple implementation of dips in Zeitgeist would set a low watermark timer for the end of a given time bucket, and report a dip if the observed traffic falls well below the model’s prediction. # 定时器是和key绑定的,触发条件可以是wall time也可以是LW. 一旦timer被触发的话同样会在持久化状态上记录下来,确保exactly-once-delivery语义。
The use of timers is optional – applications that do not have the need for time-based barrier semantics can skip them. For example, Zeitgeist can detect spiking queries without timers, since a spike may be evident even without a complete picture of the data. If the observed traffic already exceeds the model’s prediction, delayed data would only add to the total and increase the magnitude of the spike. # 定时器是可选的,比如zeitgeist完全可以不靠timer来做anamoly detection.
6. API
class Computation {
// Hooks called by the system.
void ProcessRecord(Record data); // 处理记录
void ProcessTimer(Timer timer); // 处理定时器
// Accessors for other abstractions.
void SetTimer(string tag, int64 time);
void ProduceRecord(
Record data, string stream); // 产出记录
StateType MutablePersistentState(); // 持久化状态
};
6.1. Computation API
6.2. Injector and Low Watermark API
At the system layer, each computation calculates a low water-mark value for all of its pending work (in-progress and queued de-liveries). Persistent state can also be assigned a timestamp value (e.g. the trailing edge of an aggregation window). This is rolled up automatically by the system in order to provide API semantics for timers in a transparent way – users rarely interact with low water-marks in computation code, but rather manipulate them indirectly through timestamp assignation to records. # 用户一般不用计算LW, 只需要关注定时器
Injectors: Injectors bring external data into MillWheel. Since in-jectors seed low watermark values for the rest of the pipeline, they are able to publish an injector low watermark that propagates to any subscribers among their output streams, reflecting their poten-tial deliveries along those streams. For example, if an injector were ingesting log files, it could publish a low watermark value that cor-responded to the minimum file creation time among its unfinished files, as shown in Figure 10. # LW实现上应该是上游向下游发送,然后每个计算节点更新LW
An injector can be distributed across multiple processes, such that the aggregate low watermark of those processes is used as the injector low watermark. The user can specify an expected set of in-jector processes, making this metric robust against process failures and network outages. In practice, library implementations exist for common input types at Google (log files, pubsub service feeds, etc.), such that normal users do not need to write their own injec-tors. If an injector violates the low watermark semantics and sends a late record behind the low watermark, the user’s application code chooses whether to discard the record or incorporate it into an up-date of an existing aggregate.
7. FAULT TOLERANCE
7.1. Delivery Guarantees
Much of the conceptual simplicity of MillWheel’s programming model hinges upon its ability to take non-idempotent user code and run it as if it were idempotent. By removing this requirement from computation authors, we relieve them of a significant implementa-tion burden. # 让user-code提供idempotent保证就是要确保所有的changes以及state能够atomically checkpointed以及recovered.
7.2. Exactly-Once Delivery
Upon receipt of an input record for a computation, the MillWheel framework performs the following steps:
- The record is checked against deduplication data from previous deliveries; duplicates are discarded.
- User code is run for the input record, possibly resulting in pend-ing changes to timers, state, and productions. # 所有修改会形成pending-changes, 包括发送给下游的records
- Pending changes are committed to the backing store. # 原子性地提交修改
- Senders are ACKed. # 告诉sender OK
- Pending downstream productions are sent. # 向下游发送records.
As an optimization, the above operations may be coalesced into a single checkpoint for multiple records. Deliveries in MillWheel are retried until they are ACKed in order to meet our at-least-once requirement, which is a prerequisite for exactly-once. We retry be-cause of the possibility of networking issues and machine failures on the receiver side. However, this introduces the case where a re-ceiver may crash before it has a chance to ACK the input record, even if it has persisted the state corresponding to successful pro-cessing of that record. In this case, we must prevent duplicate pro-cessing when the sender retries its delivery. # 为了提高吞吐可以批量完成后面3步,以上步骤可以保证exactly-one-delivery
The system assigns unique IDs to all records at production time. We identify duplicate records by including this unique ID for the record in the same atomic write as the state modification. If the same record is later retried, we can compare it to the journaled ID, and discard and ACK the duplicate (lest it continue to retry in-definitely). Since we cannot necessarily store all duplication data in-memory, we maintain a Bloom filter of known record finger-prints, to provide a fast path for records that we have provably never seen before. In the event of a filter miss, we must read the backing store to determine whether a record is a duplicate. Record IDs for past deliveries are garbage collected after MillWheel can guarantee that all internal senders have finished retrying. For injectors that frequently deliver late data, we delay this garbage collection by a corresponding slack value (typically on the order of a few hours). However, exactly-once data can generally be cleaned up within a few minutes of production time. # 所有record都会分配唯一id.(computation_name + monotonic id).是一种实现。但是对于receiver所看到的unique ID并不是单调的,所以必须记录所有处理过的unique ID. 用bloom filter来做优化,然后定时(1分钟左右)可以对unique IDs做GC.
7.3. Strong Productions
#note: SP + exactly-one-delivery才能满足user-code idempotent需求
Since MillWheel handles inputs that are not necessarily ordered or deterministic, we checkpoint produced records before delivery in the same atomic write as state modification. We call this pat- tern of checkpointing before record production strong productions. # 发送之前先把productions做checkpoint. 注意这里state和productions一起做checkpoint的。
We use a storage system such as Bigtable, which efficiently implements blind writes (as opposed to read-modify-write opera-tions), making checkpoints mimic the behavior of a log. When a process restarts, the checkpoints are scanned into memory and replayed. Checkpoint data is deleted once these productions are successful. # 下游收到productions上游的checkpoint data才会删除。
7.4. Weak Productions and Idempotency
如果user-code已经满足idempotent的话,那么就没有必要满足SP和exactly-one-delivery了。exactly-one-delivery功能可以非常容易关闭(deduplication), 但是取消SP就有一些潜在问题要考虑。SP另外一种方式就是WP.
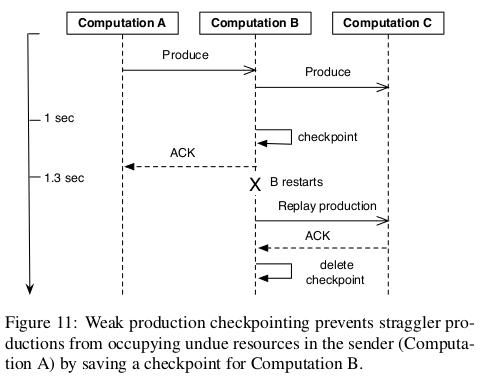
WP是向下游发送时候,在持久化状态和productions之前,乐观地先往下面发送records并且等待ACK. 如果接受ACK的话那么我们没有必要持久化productions. 可是如果整个pipeline非常深的话,如果其中一个computation没有回复ACK的话那么整个pipeline都会stall. 解决办法就是如果发现等待ACK时间太长的话,先在本地做好checkpoint(productions)然后ACK上层。
7.5. State Manipulation
In implementing mechanisms to manipulate user state in Mill-Wheel, we discuss both the “hard” state that is persisted to our backing store and the “soft” state which includes any in-memory caches or aggregates. We must satisfy the following user-visible guarantees: # 包括持久化状态和内存状态
- The system does not lose data.
- Updates to state must obey exactly-once semantics.
- All persisted data throughout the system must be consistent at any given point in time.
- Low watermarks must reflect all pending state in the system.
- Timers must fire in-order for a given key.
To avoid inconsistencies in persisted state (e.g. between timers, user state, and production checkpoints), we wrap all per-key up-dates in a single atomic operation. This results in resiliency against process failures and other unpredictable events that may interrupt the process at any given time. As mentioned previously, exactly-once data is updated in this same operation, adding it to the per-key consistency envelope. # 所有状态写入是atomic
As work may shift between machines (due to load balancing, failures, or other reasons) a major threat to our data consistency is the possibility of zombie writers and network remnants issuing stale writes to our backing store. To address this possibility, we attach a sequencer token to each write, which the mediator of the backing store checks for validity before allowing the write to com-mit. New workers invalidate any extant sequencers before start-ing work, so that no remnant writes can succeed thereafter. The sequencer is functioning as a lease enforcement mechanism, in a similar manner to the Centrifuge system. Thus, we can guaran-tee that, for a given key, only a single worker can write to that key at a particular point in time. # zombie writer存在会导致两个writer同时更新状态,解决办法就是发放token. 新的worker会将原来所有的token强制失效,然后使用自己的token进行更新。
8. SYSTEM IMPLEMENTATION
8.1. Architecture
MillWheel deployments run as distributed systems on a dynamic set of host servers. Each computation in a pipeline runs on one or more machines, and streams are delivered via RPC. On each ma-chine, the MillWheel system marshals incoming work and manages process-level metadata, delegating to the appropriate user compu-tation as necessary.
Load distribution and balancing is handled by a replicated mas-ter, which divides each computation into a set of owned lexico-graphic key intervals (collectively covering all key possibilities) and assigns these intervals to a set of machines. In response to in-creased CPU load or memory pressure (reported by a standard per-process monitor), it can move these intervals around, split them, or merge them. Each interval is assigned a unique sequencer, which is invalidated whenever the interval is moved, split, or merged. # LB是通过replicated master来完成的,master知道key distribution然后将key space划分成为多个interval,每个interval分配一个sequencer(上节提到的state管理用到). 因为computation是以key为最小管理单元的并且满足idempotent, 所以可以很容易调整并发度。
For persistent state, MillWheel uses a database like Bigtable or Spanner , which provides atomic, single-row updates. Timers, pending productions, and persistent state for a given key are all stored in the same row in the data store.
MillWheel recovers from machine failures efficiently by scan-ning metadata from this backing store whenever a key interval is assigned to a new owner. This initial scan populates in-memory structures like the heap of pending timers and the queue of check-pointed productions, which are then assumed to be consistent with the backing store for the lifetime of the interval assignment. # 每个computation实例分配到一个连续的key space, 所以恢复状态的时候只需要扫描一个range即可。
8.2. Low Watermarks
注意LW是对应于computation而非key的,所以虽然每个computation节点可以自己推测出自己的LW, 但是这个LW仅仅是局部的(无效的). 所以计算LW只能由master或者是中央节点来完成。
In order to ensure data consistency, low watermarks must be im-plemented as a sub-system that is globally available and correct. We have implemented this as a central authority (similar to OOP), which tracks all low watermark values in the system and jour-nals them to persistent state, preventing the reporting of erroneous values in cases of process failure. # 一个中央节点来追踪LW并且持久化在全局可见的存储系统中.
When reporting to the central authority, each process aggregates timestamp information for all of its owned work. This includes any checkpointed or pending productions, as well as any pending timers or persisted state. Each process is able to do this efficiently by de-pending on the consistency of our in-memory data structures, elim-inating the need to perform any expensive queries over the backing data store. Since processes are assigned work based on key inter-vals, low watermark updates are also bucketed into key intervals, and sent to the central authority. # 每个计算节点都会计算出自己的LW value然后汇报给中心节点
To accurately compute system low watermarks, this authority must have access to low watermark information for all pending and persisted work in the system. When aggregating per-process updates, it tracks the completeness of its information for each com-putation by building an interval map of low watermark values for the computation. If any interval is missing, then the low watermark corresponds to the last known value for the missing interval until it reports a new value. The authority then broadcasts low watermark values for all computations in the system. # 中央节点收到每个计算节点汇报的LW之后,需要确保computation节点所有实例都汇报了(也就是说所有的key interval都必须存在), 然后选择最小的timestamp作为这个computation的LW. 一旦计算完成会广播给系统中所有的计算节点。
Interested consumer computations subscribe to low watermark values for each of their sender computations, and thus compute the low watermark of their input as the minimum over these val-ues. The reason that these minima are computed by the workers, rather than the central authority, is one of consistency: the central authority’s low watermark values should always be at least as con-servative as those of the workers. Accordingly, by having workers compute the minima of their respective inputs, the authority’s low watermark never leads the workers’, and this property is preserved. # 每个计算节点可以自己算出LW然后汇报. 这样中央节点在汇总的时候就不必在计算senders的LW.
To maintain consistency at the central authority, we attach se-quencers to all low watermark updates. In a similar manner to our single-writer scheme for local updates to key interval state, these sequencers ensure that only the latest owner of a given key interval can update its low watermark value. For scalability, the authority can be sharded across multiple machines, with one or more compu-tations on each worker. Empirically, this can scale to 500,000 key intervals with no loss in performance. # 为了维护中央节点的一致性,所有的LW更新也必须带上sequencers,确保最新的worker发起的更新才被计入. 同时考虑到性能,这个中心节点完全可以做sharding, 一个中心节点仅仅对应部分computation, 这样可以很容易扩展到500K个key区间(500k个计算节点实例)
Given a global summary of work in the system, we are able to optionally strip away outliers and offer heuristic low watermark values for pipelines that are more interested in speed than accu-racy. For example, we can compute a 99% low watermark that corresponds to the progress of 99% of the record timestamps in the system. A windowing consumer that is only interested in approxi-mate results could then use these low watermark values to operate with lower latency, having eliminated its need to wait on stragglers. #LW计算需要所有节点都汇报才能计算出来,为了避免straggler引起的LW计算延迟,可以设置一个下限比如99%超过这个比例的节点汇报LW的话就可以使用这个LW.
In summary, our implementation of low watermarks does not re-quire any sort of strict time ordering on streams in the system. Low watermarks reflect both in-flight and persisted state. By establish-ing a global source of truth for low watermark values, we prevent logical inconsistencies, like low watermarks moving backwards.
9. EVALUATION
9.1. Output Latency
A critical metric for the performance of streaming systems is latency. The MillWheel framework supports low latency results, and it keeps latency low as the distributed system scales to more machines. To demonstrate the performance of MillWheel, we mea-sured record-delivery latency using a simple, single-stage MillWheel pipeline that buckets and sorts numbers. This resembles the many-to-many shuffle that occurs between successive computations that are keyed differently, and thus is a worst case of sorts for record delivery in MillWheel. Figure 13 shows the latency distribution for records when running over 200 CPUs. Median record delay is 3.6 milliseconds and 95th-percentile latency is 30 milliseconds, which easily fulfills the requirements for many streaming systems at Google (even 95th percentile is within human reaction time). # 实验的计算过程是单阶段实时排序,扩展到200CPUs. 中位延迟是3.6ms, 95%延迟是在30ms一下. 这个计算过程是idempotent的.
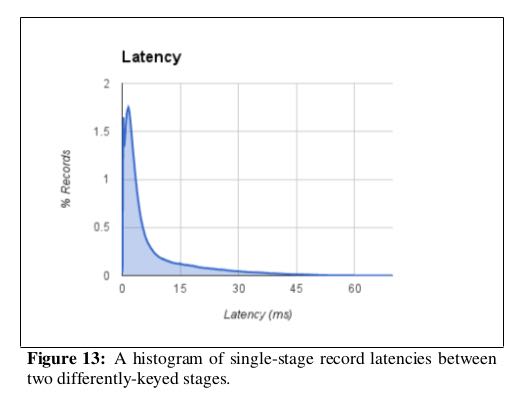
This test was performed with strong productions and exactly-once disabled. With both of these features enabled, median latency jumps up to 33.7 milliseconds and 95th-percentile latency to 93.8 milliseconds. This is a succinct demonstration of how idempotent computations can decrease their latency by disabling these two fea-tures. # 因为上面计算是幂等的,所以我们可以关闭SP和exactly-once-delivery语义,然后中位延迟上升到33.7ms, 95%延迟在93.8ms一下。
To verify that MillWheel’s latency profile scales well with the system’s resource footprint, we ran the single-stage latency exper-iment with setups ranging in size from 20 CPUs to 2000 CPUs, scaling input proportionally. Figure 14 shows that median latency stays roughly constant, regardless of system size. 99th-percentile latency does get significantly worse (though still on the order of 100ms). However, tail latency is expected to degrade with scale –more machines mean that there are more opportunities for things to go wrong. # 下图是验证规模扩展对延迟的影响,测试从20CPUs到2000CPUs. 可以看到中位延迟和95%延迟变化不是特别大,但是99%延迟也就是tail-latency迅速增长。
9.2. Watermark Lag
While some computations (like spike detection in Zeitgeist) do not need timers, many computations (like dip detection) use timers to wait for the low watermark to advance before outputting aggre- gates. For these computations, the low watermark’s lag behind real time bounds the freshness of these aggregates. Since the low wa-termark propagates from injectors through the computation graph, we expect the lag of a computation’s low watermark to be propor-tional to its maximum pipeline distance from an injector. We ran a simple three-stage MillWheel pipeline on 200 CPUs, and polledeach computation’s low watermark value once per second. In Fig-ure 15, we can see that the first stage’s watermark lagged real time by 1.8 seconds, however, for subsequent stages, the lag increased per stage by less than 200ms. Reducing watermark lag is an active area of development. # 一部分计算依赖于LW触发定时器,所以LW计算延迟也非常关键。这里实验构造了一个简单的3阶段计算过程在200CPUs上运行,然后下图是延迟情况
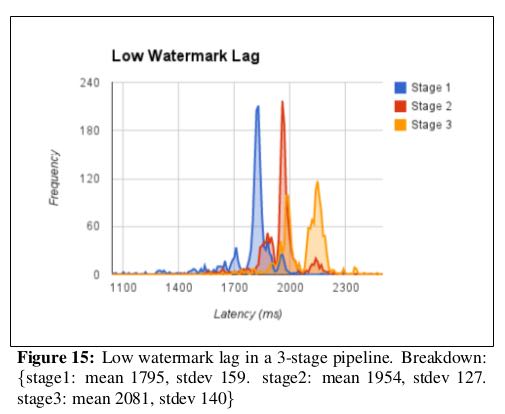
从injector到第一阶段的LW延迟在1.8s, 之后每个阶段之间段延迟在200ms.
9.3. Framework-Level Caching
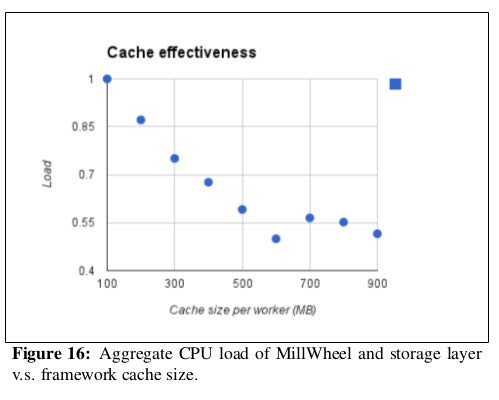
Due to its high rate of checkpointing, MillWheel generates sig-nificant amounts of traffic to the storage layer. When using a stor-age system such as Bigtable, reads incur a higher cost than writes, and MillWheel alleviates this with a framework-level cache. A common use case for MillWheel is to buffer data in storage until the low watermark has passed a window boundary and then to fetch the data for aggregation. This usage pattern is hostile to the LRU caches commonly found in storage systems, as the most recently modified row is the one least likely to be fetched soon. MillWheel knows how this data is likely to be used and can provide a bet-ter cache-eviction policy. In Figure 16 we measure the combined CPU usage of the MillWheel workers and the storage layer, relative to maximum cache size (for corporate-secrecy reasons, CPU usage has been normalized). Increasing available cache linearly improves CPU usage (after 550MB most data is cached, so further increases were not helpful). In this experiment, MillWheel’s cache was able to decrease CPU usage by a factor of two. # 使用框架级别的Cache来缓存之前处理过的数据结果,这样可以减少BigTable等data store的读取压力
9.4. Real-world Deployments
MillWheel powers a diquote set of internal Google systems. It performs streaming joins for a variety of Ads customers, many of whom require low latency updates to customer-visible dashboards. Billing pipelines depend on MillWheel’s exactly-once guarantees. Beyond Zeitgeist, MillWheel powers a generalized anomaly-detection service that is used as a turnkey solution by many different teams. Other deployments include network switch and cluster health moni-toring. MillWheel also powers user-facing tools like image panorama generation and image processing for Google Street View. # 广告流式join, 计费系统,异常检测,网络集群健康监控,一些面向用户产品比如google street view中的图像全息生成和图像处理。
There are problems that MillWheel is poorly suited for. Mono-lithic operations that are inherently resistant to checkpointing are poor candidates for inclusion in computation code, since the sys-tem’s stability depends on dynamic load balancing. If the load bal-ancer encounters a hot spot that coincides with such an operation, it must choose to either interrupt the operation, forcing it to restart, or wait until it finishes. The former wastes resources, and the latter risks overloading a machine. As a distributed system, MillWheel does not perform well on problems that are not easily parallelized between different keys. If 90% of a pipeline’s traffic is assigned a single key, then one machine must handle 90% of the overall system load for that stream, which is clearly inadvisable. Compu-tation authors are advised to avoid keys that are high-traffic enough to bottleneck on a single machine (such as a customer’s language or user-agent string), or build a two-phase aggregator. # monolithic操作一般内部不太适合做checkpoint,最好不要用MW. 同样MW会自动对hot-spot key进行LB, 可是如果某一个key过热的话那么LB也无济于事,那么最好使用两阶段聚合。
If a computation is performing an aggregation based on low wa-termark timers, MillWheel’s performance degrades if data delays hold back low watermarks for large amounts of time. This can result in hours of skew over buffered records in the system. Often-times memory usage is proportional to skew, because an application depends on low watermarks to flush this buffered data. To prevent memory usage from growing without bound, an effective remedy is to limit the total skew in the system, by waiting to inject newer records until the low watermarks have advanced. # 使用LW定时器的时候,如果输入数据延迟到来的话会让LW一直不动,造成的结果就是所有计算节点需要一直buffer数据(因为LW触发计算,计算完成之后,这部分buffered数据才可以释放)。一个有效的解决办法是injector插入新的记录让LW增长。