Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
Table of Contents
- http://mesos.apache.org/
- https://www.cs.berkeley.edu/~alig/papers/mesos.pdf @ 2010
- http://mesos.berkeley.edu/tr-mesos.pdf @ 2010
1. Abstract
To support the sophisticated schedulers of today’s frame-works, Mesos introduces a distributed two-level schedul-ing mechanism called resource offers. Mesos decides how many resources to offer each framework, while frameworks decide which resources to accept and which computations to run on them. 双层调度结构: 1)mesos决定分配多少资源给framework 2)framework决定是否接受这些资源.
2. Introduction
Sharing a clus-ter between frameworks is desirable for two reasons: it improves utilization through statistical multiplexing, and it lets applications share datasets that may be too expen-sive to replicate. 多个framework共享一个cluster两个原因是 1)通过统计上的多路服用来提高利用率 2)在多个cluster之间replicate数据代价太高. 这也就要多资源调度器需要适配不同的frameworks
The main challenge Mesos must address is that differ-ent frameworks have different scheduling needs. Each framework has scheduling preferences specific to its pro-gramming model, based on the dependencies between its tasks, the location of its data, its communication pat-tern, and domain-specific optimizations. Furthermore, frameworks’ scheduling policies are rapidly evolving. Therefore, designing a generic sched-uler to support all current and future frameworks is hard, if not infeasible. Instead, Mesos takes a different ap-proach: giving frameworks control over their scheduling. mesos最大的挑战就是满足不同frameworks的调度需求, 而这些调度需求差异比较大. 所以干脆mesos就不管这些, 只是告诉framework提供多少资源, 然后由framework来决定是否接受.
Mesos lets frameworks choose which resources to use through a distributed scheduling mechanism called re-source offers. Mesos decides how many resources to offer each framework, based on an organizational pol- icy such as fair sharing, but frameworks decide which resources to accept and which computations to run on them. "resource-offers"是mesos根据不同策略为每个framework定义的.
3. Target Environment
4. Architecture
4.1. Design Philosophy
Because cluster frameworks are both highly diverse and rapidly evolving, our overriding design phi-losophy has been to define a minimal interface that en-ables efficient resource sharing, and otherwise push con-trol to the frameworks. 因为frameworks差异太大并且变化太快, 所以mesos设计目标是定义最小接口来高效地完成资源共享, 然后将资源控制交给framework本身完成.
Pushing control to the frame-works has two benefits. 交给framework做资源控制有几个好处
- First, it allows frameworks to implement diverse approaches to various problems in the cluster (e.g., dealing with faults), and to evolve these so-lutions independently. framework可以更加灵活利用资源
- Second, it keeps Mesos simple and minimizes the rate of change required of the system, which makes it easier to make Mesos scalable and robust. mesos可以更加简单
4.2. Overview
下面是mesos架构图
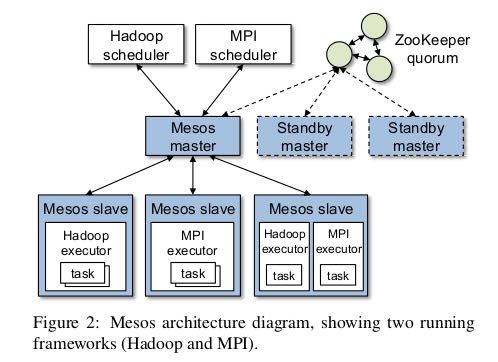
- master 用来记录所有可用资源 (1 instance)
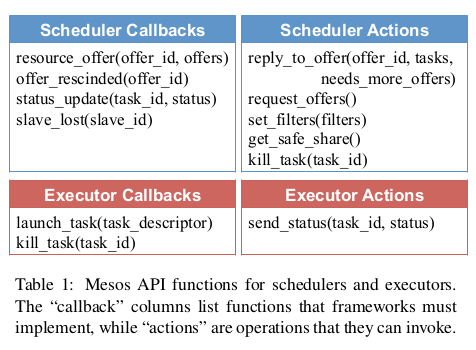
- scheduler 用来接收master提供的resource-offers并且决定是否接受 (1 instance per framework)
- slave 用来接收master传递过来的scheduler的决定, 并且通知对应的executor. (per node)
- executor 用来执行framework的tasks (n instances per frameworks)
下面是一次resource offer的示例
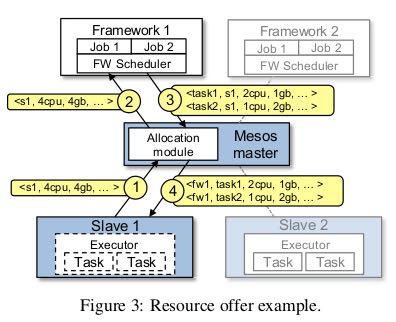
The key aspect of Mesos that lets frameworks achieve placement goals is the fact that they can reject resources. In particular, we have found that a simple policy called delay scheduling, in which frameworks wait for a limited time to acquire preferred nodes, yields nearly op-timal data locality. 能够让framework达到placement效果的关键, 是mesos允许framework拒绝使用resource-offer. 这种调度策略成为延迟调度, 即等待一段时间来确保资源列表里面有preferred nodes, 这样来产生接近最优的数据本地性.
4.3. Resource Allocation
- Mesos delegates allocation decisions to a pluggable allo-cation module, so that organizations can tailor allocation to their needs. 可插拔模块来做资源分配
- In normal operation, Mesos takes advan-tage of the fine-grained nature of tasks to only reallocate resources when tasks finish. 通常在task结束的时候做资源重分配
- Therefore, the allocation module only needs to decide which frameworks to offer free resources to, and how many resources to offer to them. AM只需决定资源分配给哪个fm以及分配多少
- However, our architec-ture also supports long tasks by allowing allocation mod-ules to specifically designate a set of resources on each node for use by long tasks. 但是mesos也支持分配资源给long-run task.
- Finally, we give allocation modules the power to revoke (kill) tasks if resources are not becoming free quickly enough. 并且给予AM权利来撤回资源
Dominant Resource Fairness (DRF)
DRF是资源分配算法, 特性是尽可能地使每个framework所使用的关键资源比例相当.
For example, if a cluster contains 100 CPUs and 100 GB of RAM, and framework F1 needs 4 CPUs and 1 GB RAM per task while F2 needs 1 CPU and 8 GB RAM per task, then DRF gives F1 20 tasks (80 CPUs and 20 GB) and gives F2 10 tasks (10 CPUs and 80 GB). This makes F1 ’s share of CPU equal to F2 ’s share of RAM, while fully utilizing one resource (RAM). 这个例子里面集群资源CPU:RAM = 1:1, 而F1的CPU:RAM = 4:1, 而F2的比例是1:8. 所以f1的cpu是关键资源, 而f2的mem是关键资源. 因为要让cpu(f1)/cpu(f2) == mem(f2)/mem(f1).
DRF is a natural generalization of max/min fair-ness. DRF satisfies the above mentioned properties and performs scheduling in O(log n) time for n frame-works. #可以在O(lgN)完成N个framworks资源分配
Supporting Long Tasks
If long tasks are placed arbitrarily throughout the cluster, however, some nodes may become filled with them, preventing other frame-works from accessing local data. To address this prob-lem, Mesos allows allocation modules to bound the to-tal resources on each node that can run long tasks. The amount of long task resources still available on the node is reported to frameworks in resource offers. 长任务可能会长时间占用资源造成其他framework没有办法访问local data. 为了解决这个问题可以限制long tasks的资源总量.
When a framework launches a task, it marks it as either long or short. Short tasks can use any resources, but long tasks can only use up to the amount specified in the offer. Of course, a framework may launch a long task with-out marking it as such. In this case, Mesos will eventu-ally revoke it. framework启动任务的时候需要表明这个是long/short task. 但是如果没有标记的话, framework对于长时间的task占据资源也可能收回.
Revocation
Before killing a task, Mesos gives its framework a grace period to clean it up. Mesos asks the respective executor to kill the task, but kills the entire executor and all its tasks if it does not respond to the request. We leave it up to the allocation module to implement the policy for revoking tasks, but describe two related mechanisms here. 资源回首之前会通知scheduler来清理, 并且告诉executor来kill task. 如果executor不响应的话那么就一起kill.
to decide when to trigger revocation, alloca-tion modules must know which frameworks would use more resources if they were offered them. Frameworks indicate their interest in offers through an API call. 其他framework需要更多资源的时候才应该触发revocation. 所以mesos应该提供API来为framework提供这种功能.
While killing a task has a low impact on many frameworks (e.g., MapReduce or stateless web servers), it is harmful for frameworks with interdependent tasks (e.g., MPI). We allow these frameworks to avoid be-ing killed by letting allocation modules expose a guar-anteed allocation to each framework – a quantity of resources that the framework may hold without losing tasks. Frameworks read their guaranteed allocations through an API call. Allocation modules are responsible for ensuring that the guaranteed allocations they provide can all be met concurrently. 为了尽可能地不kill task, 可以为每个framework分配"保险资源".
For now, we have kept the semantics of guaranteed allocations simple: if a frame-work is below its guaranteed allocation, none of its tasks should be killed, and if it is above, any of its tasks may be killed. However, if this model is found to be too simple, it is also possible to let frameworks specify priorities for their tasks, so that the allocation module can try to kill only low-priority tasks. 如果framework资源使用低于保险资源的话, 那么不应该kill它的task. 如果超过的话可以kill any one, or kill lowest priority one.
4.4. Isolation
Mesos provides performance isolation between frame-work executors running on the same slave by leveraging existing OS isolation mechanisms. Since these mecha-nisms are platform-dependent, we support multiple iso-lation mechanisms through pluggable isolation modules. 使用OS提供的隔离机制. 因为这些机制都是平台相关的, 所以通过可插拔模块来做. 在Linux上使用LXC来限制内存, CPU, 带宽.
In the future, it would also be attrac-tive to use virtual machines as containers. However, we have not yet done this because current VM technologies add non-negligible overhead in data-intensive workloads and have limited support for dynamic reconfiguration. 没有使用vm原因是因为overhead太高并且不支持动态修改配置
4.5. Making Resource Offers Scalable and Robust
First, because some frameworks will always reject cer-tain resources, Mesos lets them short-circuit the rejection process and avoid communication by providing filters to the master. We support two types of filters: “only offer nodes from list L” and “only offer nodes with at least R resources free”. A resource that fails a filter is treated ex-actly like a rejected resource. By default, any resources rejected during an offer have a temporary 5-second filter placed on them, to minimize the programming burden on developers who do not wish to manually set filters. 通过filter来解决频繁通知framework零碎的可用资源. 并且如果framework一次拒绝某个offer那么在接下来的5s内还会再次拒绝
Second, because a framework may take time to re-spond to an offer, Mesos counts resources offered to a framework towards its share of the cluster for the purpose of allocation. This is a strong incentive for frameworks to respond to offers quickly and to filter out resources that they cannot use, so that they can get offers for more suitable resources faster.
Third, if a framework has not responded to an offer for a sufficiently long time, Mesos rescinds the offer and re-offers the resources to other frameworks. 如果framework长时间不响应的话.
4.6. Fault Tolerance
5. Mesos Behavior
5.1. Framework Incentives
Short tasks: A framework is incentivized to use short tasks for two reasons. First, it will be able to allocate any slots; in contrast frameworks with long tasks are re-stricted to a subset of slots. Second, using small tasks minimizes the wasted work if the framework loses a task, either due to revocation or simply due to failures. 尽可能短任务. 一方面可能很容易分配资源, 另外一方面task被killed也会损失太多.
No minimum allocation: The ability of a framework to use resources as soon as it allocates them–instead of waiting to reach a given minimum allocation–would al-low the framework to start (and complete) its jobs earlier.
Scale down: The ability to scale down allows a frame-work to grab opportunistically the available resources, as it can later release them with little negative impact.
不要等到完全获得资源再开始启动任务. 这样可以充分利用资源.
Do not accept unknown resources: Frameworks are incentivized not to accept resources that they cannot use because most allocation policies will account for all the resources that a framework owns when deciding which framework to offer resources to next. 如果framework不理解某个资源的话, 那么不要接受它, 而将它留给其他framework.
5.2. Limitations of Distributed Scheduling
Fragmentation: When tasks have heterogeneous re-source demands, a distributed collection of frameworks may not be able to optimize bin packing as well as a cen-tralized scheduler. To accommodate frameworks with large per-task resource requirements, allocation modules can support a minimum offer size on each slave, and ab-stain from offering resources on that slave until this min-imum amount is free. 相对于中央调度器的资源碎片问题. 解决办法可以是为每个slave定义minimum offer size.
Interdependent framework constraints: It’s possible to construct scenarios where, because of esoteric inter- dependencies between frameworks’ performance, only a single global allocation of the cluster resources performs well. We argue such scenarios are rare in practice. In the model discussed in this section, where frameworks only have preferences over placement, we showed that allocations approximate those of optimal schedulers. # framework之间的相互资源限制造成必须使用中央调度器才能够有好的性能. 但是这种情况非常少见.
6. Implementation
- 10000 loc in C++, running on Linux, Solaris, Mac OS X
- use SWIG to generate interface bindings for Java, Ruby, Python
- libprocess # an actor-based programming model using efficient asyn-chronous I/O mechanisms