Megastore: Providing Scalable, Highly Available Storage for Interactive Services
Table of Contents
http://research.google.com/pubs/pub36971.html @ 2011
1. ABSTRACT
- Megastore is a storage system developed to meet the re-quirements of today’s interactive online services. Megas-tore blends the scalability of a NoSQL datastore with the convenience of a traditional RDBMS in a novel way, and provides both strong consistency guarantees and high avail-ability. (只要是为了满足现在交互式在线服务的存储需求,融合了NoSQL扩展性以及RDBMS的方便性,同时提供了强一致性以及高可用性)
- We provide fully serializable ACID semantics within fine-grained partitions of data. This partitioning allows us to synchronously replicate each write across a wide area net-work with reasonable latency and support seamless failover between datacenters.(在一个数据区域上提供了完全的可串行化的ACID语义。在这个数据区域上面我们所有的写可以在WAN下面以非常小的延迟做同步replicate,同时支持datacenter之间的seamless failover)
2. INTRODUCTION
- We accomplish this by taking a middle ground in the RDBMS vs. NoSQL design space: we partition the data-store and replicate each partition separately, providing full ACID semantics within partitions, but only limited con-sistency guarantees across them. We provide traditional database features, such as secondary indexes, but only those features that can scale within user-tolerable latency limits, and only with the semantics that our partitioning scheme can support.
- 将数据进行partition,对于每个partition内部提供完全ACID语义的操作并且之间的replicate是强一致的,但是对于across partition仅仅是做到了有限的一致性(最终一致性?)
- 同时提供了一些传统的db特性比如二级索引,但是这个feature可能会带来比较高的延迟,并且对应的语义是partition scheme(分区方案)所支持的( 比如如果二级索引是跨partition的话,那么索引的更新是做不到原子的 )
- Contrary to conventional wisdom [24, 28], we were able to use Paxos to build a highly available system that pro-vides reasonable latencies for interactive applications while synchronously replicating writes across geographically dis-tributed datacenters. While many systems use Paxos solely for locking, master election, or replication of metadata and configurations, we believe that Megastore is the largest sys-tem deployed that uses Paxos to replicate primary user data across datacenters on every write.(mega使用paxos来完成低延迟下跨地域的同步复制来构建高可用性的系统。大部分的系统都是使用paxos来做locking,master选举或者是备份一些metadata或者是配置文件,而mega对每次写都用paxos做跨数据中心的复制)
3. TOWARD AVAILABILITY AND SCALE
- To do so, we have taken a two-pronged approach:
- for availability, we implemented a synchronous, fault-tolerant log replicator optimized for long distance-links;(对于availablity使用同步容错的log replicator,为了长距离链接进行了优化。 使用优化的Paxos )
- for scale, we partitioned data into a vast space of small databases, each with its own replicated log stored in a per-replica NoSQL datastore.(为了scale对于数据进行partition。各个partition有自己的replicated log,记录在自己所在的NoSQL datastore里面)
3.1. Replication
- For cloud storage to meet availability demands, service providers must replicate data over a wide geographic area.(对于云存储必须满足可用性的需求,服务提供商必须跨地域进行replication),We evaluated common strategies for wide-area replication:(下面几个常见的跨地域replication解决方案)
- Asynchronous Master/Slave 数据丢失风险,SPOF
- Synchronous Master/Slave 延迟大,SPOF
- Optimistic Replication 数据丢失风险并且不能够确定commit order,不能够做到ACID
- We decided to use Paxos, a proven, optimal, fault-tolerant consensus algorithm with no requirement for a distinguished master. (paxos不需要单独的master)
- We replicate a write-ahead log over a group of symmetric peers. Any node can initiate reads and writes. Each log append blocks on acknowledgments from a ma-jority of replicas, and replicas in the minority catch up as they are able—the algorithm’s inherent fault tolerance elim-inates the need for a distinguished “failed” state. (每个群组都有一个WAL,在群组里面所有的节点都可以发起read/write,只要大部分节点ack那么说明数据就写入了WAL返回成功,对于小部分没有ack的节点之后有办法跟上数据而不会造成不一致)
- A novel extension to Paxos, detailed in Section 4.4.1, allows local reads at any up-to-date replica. Another extension permits single-roundtrip writes.(对于paxos进行了一些扩展,允许在任何一个up-to-date的节点上面进行local read,并且write只需要single-roundtrip)
- Even with fault tolerance from Paxos, there are limita-tions to using a single log. With replicas spread over a wide area, communication latencies limit overall through-put. Moreover, progress is impeded when no replica is cur-rent or a majority fail to acknowledge writes. In a traditional SQL database hosting thousands or millions of users, us-ing a synchronously replicated log would risk interruptions of widespread impact . So to improve availability and throughput we use multiple replicated logs, each governing its own partition of the data set.(但是使用single log还是存在局限性。一方面因为跨地域进行replication那么延迟相当高 我理解如果只有一个WAL的话,为了确保满足ACID性质那么所有的write必须是order的,这样所有的write都集中在一个WAL会导致latency非常高 ,另外更重要的因素是如果没有足够的replica使用或者是大部分节点都failed to ack write的话,那么所有的write都会被block住,整个progress就停止了。所以为了提高可用性以及吞吐我们必须使用multiple replicated logs,每个partition都有各自的replicated log)
3.2. Partitioning and Locality
- To scale throughput and localize outages, we partition our data into a collection of entity groups, each indepen-dently and synchronously replicated over a wide area. The underlying data is stored in a scalable NoSQL datastore in each datacenter (see Figure 1) 划分的每个单元称为entity group. 后面简称EG #note: 所谓的entity group就是单位实体,在这个单位实体内所有的数据都是关联的,好比一个用户的blog,如果我们按照用户来划分entity group的话,那么这个blog里面所有的文章以及tag等数据形成一个entity group
- Entities within an entity group are mutated with single-phase ACID transactions (for which the commit record is replicated via Paxos).(在一个EG里面操作满足ACID,操作使用paxos来进行同步复制)
- Operations across entity groups could rely on expensive two-phase commits, but typically leverage Megastore’s efficient asynchronous messaging. (如果是跨EG的话那么需要使用两阶段提交,但是通过mega自带的异步消息队列完成)
- A transac-tion in a sending entity group places one or more messages in a queue; transactions in receiving entity groups atomically consume those messages and apply ensuing mutations.(一个EG发起的事务可能会包含多个mutation,接收EG会atomically读取这些mutation然后apply them)
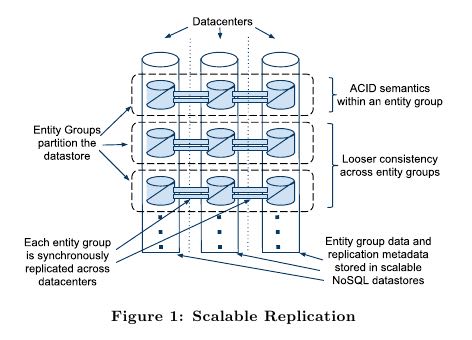
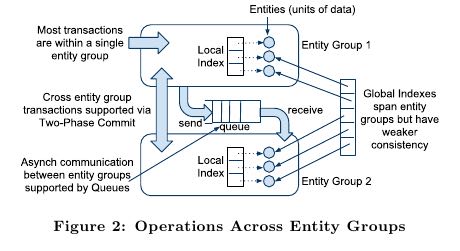
- Indexes local to an entity group obey ACID semantics; those across entity groups have looser consistency. See Fig-ure 2 for the various operations on and between entity groups.(对于index也是一样,如果是local的话那么满足ACID语义,但是如果跨EG的话那么就只有更加松散一致性( 可以认为是最终一致性? )
- We use Google’s Bigtable for scalable fault-tolerant storage within a single datacenter, allowing us to support arbitrary read and write throughput by spreading operations across multiple rows.(底层使用bigtable来作为一个datacenter的存储)
- We minimize latency and maximize throughput by let-ting applications control the placement of data: through the selection of Bigtable instances and specification of locality within an instance.(允许应用程序控制data placement来减小延迟和增大吞吐,包括选择bigtable的实例以及如何组织数据提高locality) #note: 要求客户端来决定如何放置entity group
- To minimize latency, applications try to keep data near users and replicas near each other. They assign each entity group to the region or continent from which it is accessed most. Within that region they assign a triplet or quintuplet of replicas to datacenters with isolated failure domains.(为了减少延迟将数据放在离user更近的位置)
- For low latency, cache efficiency, and throughput, the data for an entity group are held in contiguous ranges of Bigtable rows. Our schema language lets applications control the placement of hierarchical data, storing data that is accessed together in nearby rows or denormalized into the same row.(schema language可以控制将一些有层级关系的数据进行连续存储或者是放在同一个row里面)
4. A TOUR OF MEGASTORE
4.1. API Design Philosophy
- Normalized relational schemas rely on joins at query time to service user operations. This is not the right model for Megastore applications for several reasons:(不推荐在mega内部使用normalized relational schema这种方案)
- High-volume interactive workloads benefit more from predictable performance than from an expressive query language.(大部分查询都是已知访问模式的)
- Reads dominate writes in our target applications, so it pays to move work from read time to write time.
- Storing and querying hierarchical data is straightfor-ward in key-value stores like Bigtable. (Bigtable这种访问方式更加简单)
- With this in mind, we designed a data model and schema language to offer fine-grained control over physical locality. Hierarchical layouts and declarative denormalization help eliminate the need for most joins. Queries specify scans or lookups against particular tables and indexes.( megastore可以帮助user来完成denormalization避免大部分的join,对于其他必须需要join的操作提供了二级索引以及一些辅助的算法 )
4.2. Data Model

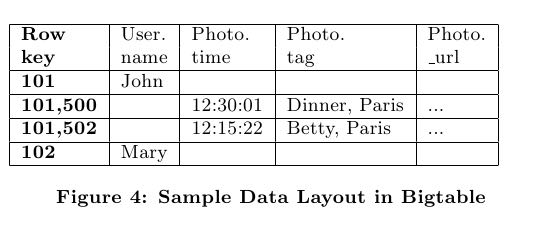
- As in an RDBMS, the data model is de-clared in a schema and is strongly typed. Each schema has a set of tables, each containing a set of entities, which in turn contain a set of properties. Properties are named and typed values. The types can be strings, various flavors of numbers, or Google’s Protocol Buffers. They can be re-quired, optional, or repeated (allowing a list of values in a single property). All entities in a table have the same set of allowable properties. A sequence of properties is used to form the primary key of the entity, and the primary keys must be unique within the table. Figure 3 shows an example schema for a simple photo storage application. (datamodel和RDBMS非常类似,schema也是由很多table来组成,每个table包含很多entity,而每个entity包含很多property。对于property有类型包括字符串,整数以及protobuf本身,并且本身可以是required,optional以及repeated的。多个property组成primary key,而primary key的内容也是由这些property value组合起来的。比如上面就是(user_id, photo_id) )
- Megastore tables are either entity group root tables or child tables. Each child table must declare a single distin-guished foreign key referencing a root table, illustrated by the ENTITY GROUP KEY annotation in Figure 3. Thus each child entity references a particular entity in its root table (called the root entity). An entity group consists of a root entity along with all entities in child tables that reference it. A Megastore instance can have several root tables, resulting in different classes of entity groups.(tables分为root table和child table,root table存在PRIMARY KEY,而child table必须使用一个foreign key来引用root table。这样对于每一个root table entry来说,可能会存在很多child entry来引用它。这里root table entry也叫做root entity)
4.2.1. Pre-Joining with Keys
- Each entity is mapped into a single Bigtable row; the primary key values are concatenated to form the Bigtable row key, and each remaining property occupies its own Bigtable column.(每一个entity占据了bigtable的一行,rowkey使用primary key拼接而成,而剩余的property则对应到bigtable的column)
- The IN TABLE User direc-tive instructs Megastore to colocate these two tables into the same Bigtable, and the key ordering ensures that Photo entities are stored adjacent to the corresponding User. This mechanism can be applied recursively to speed queries along arbitrary join depths. Thus, users can force hierarchical lay-out by manipulating the key order. (IN TABLE可以用来将child table entry紧跟在对应的root table entry之后,放置在同一个table里面,对相关数据的访问会非常有利)
- Schemas declare keys to be sorted ascending or descend-ing, or to avert sorting altogether: the SCATTER attribute in-structs Megastore to prepend a two-byte hash to each key. Encoding monotonically increasing keys this way prevents hotspots in large data sets that span Bigtable servers.(schema可以用来表示是否按照key来进行排序,或者是进行scatter,所谓scatter就是不要放key过于集中地存放,可以通过在key前面添加2个字节的hashcode来打散)
4.2.2. Indexes
#note: 索引这个部分主要突出了数据如何存放并且使之能够有效地进行存取
- Secondary indexes can be declared on any list of entity properties, as well as fields within protocol buffers. We dis-tinguish between two high-level classes of indexes: local and global (see Figure 2). (可以在任何的property包括pb的field上面建立二级索引,local和global index的一致性是不同的)
- A local index is treated as separate indexes for each entity group. It is used to find data within an entity group. The index entries are stored in the entity group and are updated atomically and consistently with the primary entity data.
- A global index spans entity groups. It is used to find entities without knowing in advance the entity groups that contain them. Global index scans can read data owned by many entity groups but are not guaranteed to reflect all recent updates.
- By adding the STORING clause to an in-dex, applications can store additional properties from the primary table for faster access at read time.(STROING可以用来在做denormalization,在二级索引里面直接存放某些字段减少一次查询)
- Megastore provides the ability to index repeated proper-ties and protocol buffer sub-fields. Repeated indexes are a efficient alternative to child tables.(对于repeated字段也可以进行索引,对于每个repeated value都对应一个entry)
- Inline indexes provide a way to denormalize data from source entities into a related target entity: index entries from the source entities appear as a virtual repeated column in the target entry. (所谓的inline index就是将index内容denormalization到target entity里面,作为column存放,
- 好比之前PhotosBytTime可以inline到User里面,在User里面的column可以使用"2012-11-20 00:00:00"
- An inline index can be created on any table that has a foreign key referencing another table by using the first primary key of the target entity as the first components of the index, and physically locating the data in the same Bigtable as the target.(创建inline index的前提是要求index的foreign key的开头部分必须和target entity的primary key相同)
- Inline indexes are useful for extracting slices of informa-tion from child entities and storing the data in the parent for fast access. Coupled with repeated indexes, they can also be used to implement many-to-many relationships more ef-ficiently than by maintaining a many-to-many link table.(配合repeated index可以有效地实现many-to-many link table)
4.2.3. Mapping to Bigtable
- The Bigtable column name is a concatenation of the Mega-store table name and the property name, allowing entities from different Megastore tables to be mapped into the same Bigtable row without collision. (column name使用了table name和property name的组合,这样如何映射到一行的话不会出现冲突)
- Within the Bigtable row for a root entity, we store the transaction and replication metadata for the entity group, including the transaction log. Storing all metadata in a single Bigtable row allows us to update it atomically through a single Bigtable transaction. (对于每个root entity会记录所有关于这个entity group的transaction log,因为一个entity group只有一个root entity。同时所有关于这个entity group的metadata信息也都是放在同一个row上面的,这样可以通过bigtable row transaction来完成更新)
- Each index entry is represented as a single Bigtable row; the row key of the cell is constructed using the indexed property values concatenated with the primary key of the indexed entity. Indexing repeated fields produces one index entry per repeated element.(对于index的row key使用的是index property values + primary key of indexed entity.
4.3. Transactions and Concurrency Control
- Each Megastore entity group functions as a mini-database that provides serializable ACID semantics. A transaction writes its mutations into the entity group’s write-ahead log, then the mutations are applied to the data.(每个EG都类似小型的数据库满足ACID,每个transaction都先写WAL然后修改数据)
- Bigtable provides the ability to store multiple values in the same row/column pair with different timestamps. We use this feature to implement multiversion concurrency control (MVCC): when mutations within a transaction are applied, the values are written at the timestamp of their transaction. Readers use the timestamp of the last fully applied trans-action to avoid seeing partial updates. Readers and writers don’t block each other, and reads are isolated from writes for the duration of a transaction. 使用MVCC来做并发控制
- Megastore provides current, snapshot, and inconsistent reads 提供下面三种读方式:
- Current and snapshot reads are always done within the scope of a single entity group.
- When starting a current read, the transaction system first ensures that all previously committed writes are applied; then the application reads at the timestamp of the latest committed transaction.(发起current read回去最近已经transaction已经ack并且mutation apply的transaction,然后以这个事务timestamp为准读取数据)
- For a snapshot read, the system picks up the timestamp of the last known fully applied transaction and reads from there, even if some committed transactions have not yet been applied(如果发起snapshot read的话那么会使用历史上某个已经提交的事务对应的timestamp来进行读取,即使当前还存在一些事务正在提交)
- Megastore also provides inconsistent reads, which ignore the state of the log and read the latest values directly. This is useful for operations that have more aggressive latency re-quirements and can tolerate stale or partially applied data(只是读取最新的值但是各个值之间可能不一致)
- A write transaction always begins with a current read to determine the next available log position. The commit operation gathers mutations into a log entry, assigns it a timestamp higher than any previous one, and appends it to the log using Paxos. The protocol uses optimistic con-currency: though multiple writers might be attempting to write to the same log position, only one will win. The rest will notice the victorious write, abort, and retry their op-erations. Advisory locking is available to reduce the effects of contention. Batching writes through session affinity to a particular front-end server can avoid contention altogether(对于write trasnaction的话必须使用current read读取最新的log position,然后将所有的mutation放在一个log entry里面使用一个更大的timestamp,然后使用paxos来追加。但是可能会出现冲突,如果发现冲突失败的话那么需要重试这个操作。使用advisory lock能够减少这种冲突,或者是在提交修改时候就单独通过和这个session绑定的server来做提交 )
- The complete transaction lifecycle is as follows:
- Read: Obtain the timestamp and log position of the last committed transaction.
- Application logic: Read from Bigtable and gather writes into a log entry.
- Commit: Use Paxos to achieve consensus for append ing that entry to the log.
- Apply: Write mutations to the entities and indexes in Bigtable.
- Clean up: Delete data that is no longer required.
- The write operation can return to the client at any point after Commit, though it makes a best-effort attempt to wait for the nearest replica to apply.
4.3.1. Queues
- Queues provide transactional messaging between entity groups. They can be used for cross-group operations, to batch multiple updates into a single transaction, or to de-fer work. A transaction on an entity group can atomically send or receive multiple messages in addition to updatingits entities. Each message has a single sending and receiving entity group; if they differ, delivery is asynchronous.(Queue主要用来在EG之间传递事务消息的,能够将多个mutation进行聚合成为single transaction以及延迟操作,这样对于发送者和接收者都可以原子地发送和读取transaction或者是多个消息。对于每个message有sender和receiver entity group,如果是不同的EG的话那么消息传递是异步的)
- Queues offer a way to perform operations that affect many entity groups. For example, consider a calendar application in which each calendar has a distinct entity group, and we want to send an invitation to a group of calendars. A sin-gle transaction can atomically send invitation queue mes-sages to many distinct calendars. Each calendar receiving the message will process the invitation in its own transaction which updates the invitee’s state and deletes the message.(对于日历来说,每个日历就是单独的EG。如果需要跨calendar发送invitation的话,那么inviter会将这个invitation作为一个transaction发送给其他日历,其他日历接受到了这个transaction之后的话就会更新并且删除消息)
4.3.2. Two-Phase Commit
- Megastore supports two-phase commit for atomic updates across entity groups. Since these transactions have much higher latency and increase the risk of contention, we gener-ally discourage applications from using the feature in favor of queues. Nevertheless, they can be useful in simplifying application code for unique secondary key enforcement.(跨EG的操作也可以实现原子更新通过使用两阶段提交,但是延迟会非常高并且容易出现冲突)
4.4. Other Features
- We have built a tight integration with Bigtable’s full-text index in which updates and searches participate in Megas-tore’s transactions and multiversion concurrency. A full-text index declared in a Megastore schema can index a table’s text or other application-generated attributes.
- Synchronous replication is sufficient defense against the most common corruptions and accidents, but backups can be invaluable in cases of programmer or operator error. Megas-tore’s integrated backup system supports periodic full snap-shots as well as incremental backup of transaction logs. The restore process can bring back an entity group’s state to any point in time, optionally omitting selected log entries (as after accidental deletes). The backup system complies with legal and common sense principles for expiring deleted data.(内置backup systems能够定期地做snapshot或者是增量地backup transaction log)
- Applications have the option of encrypting data at rest, including the transaction logs. Encryption uses a distinct key per entity group. We avoid granting the same operators access to both the encryption keys and the encrypted data.(针对每个EG一个encrypt key来进行加密)
5. REPLICATION
This section details the heart of our synchronous replica-tion scheme: a low-latency implementation of Paxos.
6. EXPERIENCE
- But the most effective bug-finding tool was our network simulator: the pseudo-random test framework. It is capable of exploring the space of all possible orderings and delays of communications between simulated nodes or threads, and deterministically reproducing the same behav-ior given the same seed. Bugs were exposed by finding a problematic sequence of events triggering an assertion fail-ure (or incorrect result), often with enough log and trace information to diagnose the problem, which was then added to the suite of unit tests. While an exhaustive search of the scheduling state space is impossible, the pseudo-random simulation explores more than is practical by other means. Through running thousands of simulated hours of operation each night, the tests have found many surprising problems (伪随机测试框架可以用来枚举所有节点以及线程之间的通信顺序以及之间的延迟)
- The term “high availability” usually signifies the ability to mask faults to make a collection of systems more reli-able than the individual systems. While fault tolerance is a highly desired goal, it comes with it its own pitfalls: it often hides persistent underlying problems. We have a saying in the group: “Fault tolerance is fault masking”. Too often, the resilience of our system coupled with insufficient vigi-lance in tracking the underlying faults leads to unexpected problems: small transient errors on top of persistent uncor-rected problems cause significantly larger problems.
#note: high availability有时候会掩盖很多系统本身出现的问题,不过这点也可以这么理解,所谓的fault不仅仅包含machine failure也还包含code bug。但是HA有时候会让我们忽略到code bug,而这些bug往往会导致更大的问题
7. RELATED WORK
- Recently, there has been increasing interest in NoSQL data storage systems to meet the demand of large web ap-plications. Representative work includes Bigtable, Cas-sandra, and Yahoo PNUTS. In these systems, scal-ability is achieved by sacrificing one or more properties of traditional RDBMS systems, e.g., transactions, schema sup-port, query capability. 都通过牺牲一些传统的RDBMS的特性来达到扩展性比如事务,schema,以及query能力(复杂的SQL查询以及运算等) These systems often reduce the scope of transactions to the granularity of single key access and thus place a significant hurdle to building appli-cations (事务粒度仅仅是到了row级别,这样为应用程序造成了一定的负担)Some systems extend the scope of transac-tions to multiple rows within a single table, for example the Amazon SimpleDB uses the concept of domain as the transactional unit. (而另外一些系统级别则放宽到了多列比如Amazon SimpleDB使用domain来作为事务单元) Yet such efforts are still limited because transactions cannot cross tables or scale arbitrarily.(但是依然不能够跨表来完成事务) More-over, most current scalable data storage systems lack the rich data model of an RDBMS, which increases the burden on developers. (更重要的是缺乏丰富的data model以及query能力给开发人员造成的负担)
- Data replication across geographically distributed data-centers is an indispensable means of improving availability in state-of-the-art storage systems. (使用跨地域地方来进行data replication是必要的手段) Most prevailing data storage systems use asynchronous replication schemes with a weaker consistency model. For example, Cassandra, HBase, CouchDB, and Dynamo use an eventual consistency model and PNUTS uses “timeline” consistency (使用timeline一致性?) Until recently, few have used Paxos to achieve synchronous replication. SCALARIS is one example that uses the Paxos commit protocol to implement replication for a distrib-uted hash table. Keyspace also uses Paxos to imple-ment replication on a generic key-value store.(这几个系统都使用paxos实现了数据上的replication)
8. CONCLUSION
<大规模分布式存储系统>: Megastore主要创新点包括:1) 提出实体组的数据模型。通过实体组划分数据,实体组内部维持关系数据库的ACID特性,实体组之间维持类似NoSQL的弱一致性,有效地融合了SQL和NoSQL两者的优势。另外实体组的定义方式也在很大程度上规避了影响性能和可扩展性的Join操作。 2) 通过Paxos协议同时保证高可靠性和高可用性,既把数据强同步到多个机房,又做到发生故障时自动切换不影响读写服务。另外通过协调者和优化Paxos协议使得读写操作都比较高效。当然Megastore也有一些问题,其中一些问题来源于bigtable比如单副本服务,SSD支持较弱导致Megastore在线实时服务能力上有一定的改进空间,整体架构过于复杂,协调者对读写服务和运维复杂度的影响。